
使用卷积神经网络进行图像分类
已发表: 2020-08-14图像分类得到改造。 感谢美国有线电视新闻网。
卷积神经网络 (CNN) 是图像分类的支柱,这是一种深度学习现象,它获取图像并为其分配一个类别和一个标签,使其独一无二。 使用 CNN 进行图像分类是机器学习实验的重要组成部分。
连同使用 CNN 及其诱导功能,它现在被广泛用于一系列应用程序——从 Facebook 图片标签到亚马逊产品推荐和医疗保健图像到自动驾驶汽车。 CNN 如此受欢迎的原因是它只需要很少的预处理,这意味着它可以通过应用其他传统算法无法做到的过滤器来读取 2D 图像。 我们将深入研究使用 CNN 进行图像分类的过程。
目录
CNN 是如何运作的?
CNN配备了输入层、输出层和隐藏层,所有这些都有助于处理和分类图像。 隐藏层包括卷积层、ReLU 层、池化层和全连接层,它们都起着至关重要的作用。 了解有关卷积神经网络的更多信息。
让我们看看使用 CNN 进行图像分类的工作原理:
假设输入图像是大象的图像。 这个带有像素的图像首先被输入到卷积层中。 如果是黑白图片,则图像被解释为 2D 图层,每个像素都分配一个介于“0”和“255”之间的值,“0”是全黑,“255”是全白。 另一方面,如果它是一张彩色图片,这将成为一个 3D 数组,具有蓝色、绿色和红色层,每个颜色值介于 0 和 255 之间。

然后开始读取矩阵,软件为此选择一个较小的图像,称为“过滤器”(或内核)。 滤波器的深度与输入的深度相同。 然后,过滤器与输入图像一起产生卷积运动,沿图像向右移动 1 个单位。
然后它将这些值与原始图片值相乘。 所有相乘的数字相加,生成一个数字。 该过程与整个图像一起重复,得到一个矩阵,小于原始输入图像。
最终的数组称为激活图的特征图。 通过应用不同的过滤器,图像的卷积有助于执行边缘检测、锐化和模糊等操作。 只需指定过滤器的大小、过滤器的数量和/或网络架构等方面。
从人类的角度来看,这个动作类似于识别图像的简单颜色和边界。 但是,为了对图像进行分类并识别使其具有的特征,例如大象而不是猫的特征,需要识别大象的大耳朵和躯干等独特特征。 这就是非线性和池化层的用武之地。
非线性层 (ReLU) 位于卷积层之后,其中将激活函数应用于特征图以增加图像的非线性。 ReLU 层去除了所有的负值,提高了图像的准确性。 尽管还有其他操作,例如 tanh 或 sigmoid,但 ReLU 是最受欢迎的,因为它可以更快地训练网络。
下一步是创建同一对象的多个图像,以便网络始终可以识别该图像,无论其大小或位置如何。 例如,在大象图片中,网络必须识别大象,无论它是行走、静止还是奔跑。 必须有图像灵活性,这就是池化层的用武之地。
它与图像的测量值(高度和宽度)一起工作,以逐渐减小输入图像的大小,以便可以在图像中的任何位置发现和识别对象。
池化还有助于控制“过度拟合”,即信息过多而没有新信息的空间。 也许,池化最常见的例子是最大池化,其中图像被划分为一系列不重叠的区域。
最大池化就是识别每个区域的最大值,从而排除所有额外的信息,图像变得更小。 此操作也有助于解释图像中的失真。
现在是全连接层,它添加了一个人工神经网络以使用 CNN。 这种人工网络结合了不同的特征,有助于更准确地预测图像类别。 在这个阶段,关于神经网络的权重计算误差函数的梯度。 调整权重和特征检测器以优化性能,并重复此过程。
这是 CNN 架构的样子:
资源
利用 CNN 应用程序-MNIST 的数据集
可以使用几个数据集来有效地应用 CNN。 使用 CNN 进行图像分类的三个最受欢迎的方法是 MNIST、CIFAR-10 和 ImageNet。 我们先来看看 MNIST。
1. MNIST
MNIST 是 Modified National Institute of Standards and Technology 数据集的首字母缩写词,包含 60,000 个 0 到 9 之间单个手写数字的 28×28 正方形小灰度图像。MNIST 是一个流行且易于理解的数据集,即部分,“解决了。” 它可用于计算机视觉和深度学习,以使用 CNN 来练习、开发和评估图像分类。 除其他外,这包括评估模型性能、探索可能的改进以及使用它来预测新数据的步骤。
它的独特之处在于它已经有一个我们可以使用的定义明确的训练和测试数据集。 如果需要评估训练运行模型的性能,该训练集可以进一步分为训练和验证数据集。 它在每次运行的训练和验证集中的表现可以记录为学习曲线,以便更深入地了解模型对问题的学习效果。
Keras 是领先的神经网络 API 之一,它通过为模型规定“validation_data ”参数来支持这一点。 训练模型时的 Fit() 函数,最终返回一个对象,该对象提到模型性能的损失和每次训练运行的指标。 幸运的是,MNIST 默认配备了 Keras,只需几行代码即可加载训练和测试文件。

有趣的是,纽约大学 Courant 数学科学研究所教授 Yann LeCun 和纽约谷歌实验室研究科学家 Corinna Cortes 的一篇文章指出,MNIST 的特殊数据库 3 (SD-3) 最初被指定为训练集。 特殊数据库 1 (SD-1) 被指定为测试集。
但是,他们认为 SD-3 比 SD-1 更容易识别和识别,因为 SD-3 是从人口普查局的员工那里收集的,而 SD-1 是从高中生中获取的。 由于学习实验的准确结论要求结果必须独立于训练集和测试,因此认为有必要通过丢失数据集来开发新的数据库。
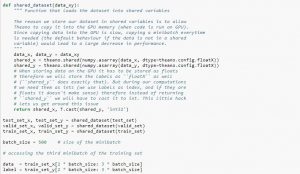
使用数据集时,建议将其分成minibatch,存储在共享变量中,根据minibatch索引访问。 您可能想知道是否需要共享变量,但这与使用 GPU 有关。 发生的情况是,当将数据复制到 GPU 内存中时,如果您在需要时单独复制每个 minibatch,GPU 代码将变慢并且不会比 CPU 代码快多少。 如果您将数据保存在 Theano 共享变量中,则很有可能在构建共享变量时一次性将整个数据复制到 GPU 上。
稍后,GPU 可以通过访问这些共享变量来使用 minibatch,而无需从 CPU 内存中复制信息。 此外,由于数据点通常是实数和标签整数,因此最好为这些以及验证集、训练集和测试集使用不同的变量,以使代码更易于阅读。
下面的代码向您展示了如何存储数据和访问小批量:
资源
2. CIFAR-10 数据集
CIFAR 代表加拿大高级研究所,CIFAR-10 数据集是由 CIFAR 研究所的研究人员与 CIFAR-100 数据集一起开发的。 CIFAR-10 数据集由 60,000 张 32×32 像素的彩色图像组成,这些图像属于猫、船、鸟、青蛙等十类物体。这些图像比普通照片小得多,旨在用于计算机视觉目的。
CIFAR 是一个很好理解、简单明了的数据集,在使用 CNN过程的图像分类中准确率为 80%,在测试数据集上准确率为 90%。 此外,多达 1,000 张图像分布在一个测试批次和五个训练批次中。
CIFAR-10 数据集由每个类别的 1,000 个随机选择的图像组成,但某些批次可能包含来自一个类别的图像多于另一个类别。 但是,训练批次正好包含来自每个类别的 5,000 张图像。 CIFAR-10 数据集因其易于使用而成为解决图像分类 CNN使用问题的起点。
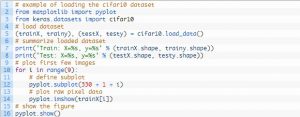
其测试工具的设计是模块化的,它可以由数据集加载、模型定义、数据集准备以及评估和结果呈现五个要素进行开发。 下面的示例显示了使用 Keras API 的 CIFAR-10 数据集以及训练数据集中的前九张图像:
资源
运行该示例会加载 CIFAR-10 数据集并打印它们的形状。
3. 图像网
ImageNet 旨在根据预定义的单词和短语将图像分类和标记为近 22,000 个类别。 为此,它遵循 WordNet 层次结构,其中每个单词或短语都是同义词或同义词集(简而言之)。 在 ImageNet 中,所有图像都根据这些同义词集进行组织,每个同义词集有超过一千张图像。
然而,当在计算机视觉和深度学习中提到 ImageNet 时,实际上指的是 ImageNet 大规模识别挑战赛或 ILSVRC。 这里的目标是使用超过 100,000 张测试图像将图像分类为 1,000 个不同的类别,因为训练数据集包含大约 120 万张图像。
也许这里最大的挑战是 ImageNet 中的图像尺寸为 224×224,因此处理如此大量的数据需要大量的 CPU、GPU 和 RAM 容量。 这对于普通笔记本电脑来说可能是不可能的,那么如何克服这个问题呢?
一种方法是使用 Imagenette,它是从 ImageNet 中提取的不需要太多资源的数据集。 该数据集有两个文件夹,名为“train”(训练)和“Val”(验证),每个类都有单独的文件夹。 所有这些类都具有与原始数据集相同的 ID,每个类都有大约 1,000 张图像,因此整个设置非常平衡。
另一种选择是使用迁移学习,这是一种在大型数据集上使用预训练权重的方法。 这是使用 CNN进行图像分类的一种非常有效的方法,因为我们可以使用它来生成适合我们的模型。 使用 CNN模型的图像分类应该能够做的一个方面是对属于同一类的图像进行分类并区分不同的图像。 这是我们可以利用预训练权重的地方。 这里的优点是我们可以根据我们正在使用的数据集的类型使用不同的方法。
另请阅读:机器学习工程师需要知道的 7 种人工神经网络
加起来
总而言之,使用 CNN 进行图像分类使该过程更容易、更准确且处理量更少。 如果您想更深入地研究机器学习, upGrad有一系列课程可以帮助您像专业人士一样掌握它!
upGrad提供各种在线课程,包含广泛的子类别; 访问官方网站了解更多信息。
如果您有兴趣了解有关机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT- B 校友身份、5 个以上实用的实践顶点项目和顶级公司的工作协助。
什么是卷积神经网络?
卷积神经网络 (CNN) 或 convnets 是一类深度前馈人工神经网络,最常用于分析视觉图像。 CNN 的设计大致受到哺乳动物视觉皮层组织的启发,尽管它们也被应用于音频、语音和其他领域。 CNN 使用多层感知器的变体,旨在要求最少的预处理。 这使得它们更不容易出错并且更易于处理各种问题,但牺牲了对其输入执行非线性变换的能力。
为什么卷积神经网络适用于图像分类?
CNN 的一大局限是它无法掌握图像中的上下文。 它也不能做面孔和做颜色。 CNN 的更多局限性:神经网络中使用的学习技术不足以再现更高的认知功能,例如物体识别、学习、空间意识和传递经验的能力。 神经网络的架构不够灵活,无法克服这些限制。