
Verwenden von Convolutional Neural Network zur Bildklassifizierung
Veröffentlicht: 2020-08-14Die Bildklassifizierung wird überarbeitet. Danke an CNN.
Convolutional Neural Networks (CNNs) sind das Rückgrat der Bildklassifizierung, eines Deep-Learning-Phänomens, das ein Bild nimmt und ihm eine Klasse und ein Etikett zuweist, die es einzigartig machen. Die Bildklassifizierung mit CNN bildet einen wesentlichen Bestandteil von Experimenten zum maschinellen Lernen.
Zusammen mit der Verwendung von CNN und seinen induzierten Fähigkeiten wird es heute für eine Reihe von Anwendungen eingesetzt – von der Facebook-Bildkennzeichnung über Amazon-Produktempfehlungen und Gesundheitsbilder bis hin zu Automatikautos. Der Grund, warum CNN so beliebt ist, ist, dass es sehr wenig Vorverarbeitung erfordert, was bedeutet, dass es 2D-Bilder lesen kann, indem es Filter anwendet, die andere herkömmliche Algorithmen nicht können. Wir werden tiefer in den Prozess eintauchen, wie die Bildklassifizierung mit CNN funktioniert.
Inhaltsverzeichnis
Wie funktioniert CNN?
CNNs sind mit einer Eingabeschicht, einer Ausgabeschicht und verborgenen Schichten ausgestattet, die alle dabei helfen, Bilder zu verarbeiten und zu klassifizieren. Die verborgenen Schichten umfassen Faltungsschichten, ReLU-Schichten, Pooling-Schichten und vollständig verbundene Schichten, die alle eine entscheidende Rolle spielen. Erfahren Sie mehr über Convolutional Neural Networks.
Schauen wir uns an, wie die Bildklassifizierung mit CNN funktioniert:
Stellen Sie sich vor, das Eingabebild ist das eines Elefanten. Dieses Bild mit Pixeln wird zuerst in die Faltungsschichten eingegeben. Wenn es sich um ein Schwarz-Weiß-Bild handelt, wird das Bild als 2D-Ebene interpretiert, wobei jedem Pixel ein Wert zwischen „0“ und „255“ zugewiesen wird, wobei „0“ vollständig schwarz und „255“ vollständig weiß ist. Handelt es sich dagegen um ein Farbbild, wird daraus ein 3D-Array mit einem blauen, grünen und roten Layer, wobei jeder Farbwert zwischen 0 und 255 liegt.

Dann beginnt das Lesen der Matrix, für die die Software ein kleineres Bild auswählt, das als „Filter“ (oder Kernel) bekannt ist. Die Tiefe des Filters entspricht der Tiefe der Eingabe. Der Filter erzeugt dann zusammen mit dem Eingangsbild eine Faltungsbewegung, die sich um 1 Einheit entlang des Bildes bewegt.
Anschließend multipliziert er die Werte mit den ursprünglichen Bildwerten. Alle multiplizierten Zahlen werden zusammengezählt und eine einzelne Zahl wird erzeugt. Der Vorgang wird zusammen mit dem gesamten Bild wiederholt, und es wird eine Matrix erhalten, die kleiner als das ursprüngliche Eingabebild ist.
Das letzte Array wird als Merkmalskarte einer Aktivierungskarte bezeichnet. Die Faltung eines Bildes hilft bei der Durchführung von Vorgängen wie Kantenerkennung, Schärfen und Weichzeichnen, indem verschiedene Filter angewendet werden. Es müssen lediglich Aspekte wie die Größe des Filters, die Anzahl der Filter und/oder die Architektur des Netzwerks festgelegt werden.
Aus menschlicher Sicht ähnelt diese Aktion dem Identifizieren der einfachen Farben und Grenzen eines Bildes. Um das Bild jedoch zu klassifizieren und die Merkmale zu erkennen, die es beispielsweise zu einem Elefanten und nicht zu einer Katze machen, müssen einzigartige Merkmale wie große Ohren und Rüssel des Elefanten identifiziert werden. Hier kommen die nichtlinearen und Pooling-Layer ins Spiel.
Die nichtlineare Schicht (ReLU) folgt der Faltungsschicht, wo eine Aktivierungsfunktion auf die Merkmalskarten angewendet wird, um die Nichtlinearität des Bildes zu erhöhen. Die ReLU-Schicht entfernt alle negativen Werte und erhöht die Genauigkeit des Bildes. Obwohl es andere Operationen wie Tanh oder Sigmoid gibt, ist ReLU die beliebteste, da sie das Netzwerk viel schneller trainieren kann.
Der nächste Schritt besteht darin, mehrere Bilder desselben Objekts zu erstellen, damit das Netzwerk dieses Bild immer erkennen kann, unabhängig von seiner Größe oder Position. Auf dem Elefantenbild muss das Netzwerk beispielsweise den Elefanten erkennen, ob er geht, stillsteht oder läuft. Image-Flexibilität muss vorhanden sein, und hier kommt die Pooling-Schicht ins Spiel.
Es arbeitet mit den Abmessungen des Bildes (Höhe und Breite), um die Größe des Eingabebildes schrittweise zu reduzieren, sodass die Objekte im Bild erkannt und identifiziert werden können, wo immer sie sich befinden.
Pooling hilft auch, „Overfitting“ zu kontrollieren, wenn zu viele Informationen ohne Spielraum für neue vorhanden sind. Das vielleicht häufigste Beispiel für Pooling ist Max Pooling, bei dem das Bild in eine Reihe nicht überlappender Bereiche unterteilt wird.
Beim Max-Pooling geht es darum, den Maximalwert in jedem Bereich zu identifizieren, sodass alle zusätzlichen Informationen ausgeschlossen werden und das Bild kleiner wird. Diese Aktion trägt auch dazu bei, Verzerrungen im Bild zu berücksichtigen.
Jetzt kommt die vollständig verbundene Schicht, die ein künstliches neuronales Netzwerk für die Verwendung von CNN hinzufügt. Dieses künstliche Netzwerk kombiniert verschiedene Merkmale und hilft, die Bildklassen genauer vorherzusagen. An dieser Stelle wird der Gradient der Fehlerfunktion bezüglich der Gewichtung des neuronalen Netzes berechnet. Die Gewichte und Merkmalsdetektoren werden angepasst, um die Leistung zu optimieren, und dieser Prozess wird wiederholt wiederholt.
So sieht die CNN-Architektur aus:
Quelle
Nutzung von Datensätzen für CNN Application-MNIST
Mehrere Datensätze können verwendet werden, um CNN effektiv anzuwenden. Die drei beliebtesten, die für die Bildklassifizierung mit CNN von entscheidender Bedeutung sind, sind MNIST, CIFAR-10 und ImageNet. Schauen wir uns zuerst MNIST an.
1. MNIST
MNIST ist ein Akronym für den modifizierten Datensatz des National Institute of Standards and Technology und umfasst 60.000 kleine, quadratische 28×28-Graustufenbilder mit einzelnen, handgeschriebenen Ziffern zwischen 0 und 9. MNIST ist ein beliebter und gut verstandener Datensatz, das heißt, für die Größeren Teil, 'gelöst.' Es kann in Computer Vision und Deep Learning verwendet werden, um die Bildklassifizierung mit CNN zu üben, zu entwickeln und zu bewerten . Dazu gehören unter anderem Schritte zur Bewertung der Leistung des Modells, zur Untersuchung möglicher Verbesserungen und zur Vorhersage neuer Daten.
Sein Alleinstellungsmerkmal ist, dass es bereits über einen gut definierten Zug- und Testdatensatz verfügt, den wir verwenden können. Dieser Trainingssatz kann weiter in einen Trainings- und Validierungsdatensatz unterteilt werden, wenn die Leistung eines Trainingslaufmodells bewertet werden muss. Seine Leistung im Zug- und Validierungssatz bei jedem Durchlauf kann als Lernkurven aufgezeichnet werden, um einen besseren Einblick darüber zu erhalten, wie gut das Modell das Problem lernt.
Keras, eine der führenden APIs für neuronale Netzwerke, unterstützt dies, indem es das Argument „validation_data “ an das Modell angibt. Fit()-Funktion beim Trainieren des Modells, die schließlich ein Objekt zurückgibt, das die Modellleistung für den Verlust und die Metriken bei jedem Trainingslauf erwähnt. Glücklicherweise ist MNIST standardmäßig mit Keras ausgestattet, und die Trainings- und Testdateien können mit nur wenigen Codezeilen geladen werden.
Interessanterweise weist ein Artikel von Yann LeCun, Professor am The Courant Institute of Mathematical Sciences an der New York University, und Corinna Cortes, Research Scientist bei Google Labs in New York, darauf hin, dass die Special Database 3 (SD-3) von MNIST ursprünglich als a Trainingsset. Die Spezialdatenbank 1 (SD-1) wurde als Testsatz bezeichnet.

Sie glauben jedoch, dass SD-3 viel einfacher zu identifizieren und zu erkennen ist als SD-1, da SD-3 von Mitarbeitern des Census Bureau gesammelt wurde, während SD-1 von Schülern der Oberstufe stammte. Da genaue Schlussfolgerungen aus Lernexperimenten erfordern, dass das Ergebnis unabhängig von Trainingssatz und Test sein muss, wurde es als notwendig erachtet, eine neue Datenbank zu entwickeln, indem die Datensätze fehlen.
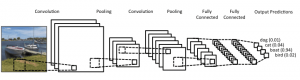
Bei der Verwendung des Datensatzes wird empfohlen, ihn in Minibatches aufzuteilen, in gemeinsam genutzten Variablen zu speichern und basierend auf dem Minibatch-Index darauf zuzugreifen. Sie wundern sich vielleicht über die Notwendigkeit gemeinsam genutzter Variablen, aber dies hängt mit der Verwendung der GPU zusammen. Was passiert ist, dass beim Kopieren von Daten in den GPU-Speicher, wenn Sie jeden Minibatch nach Bedarf separat kopieren, der GPU-Code langsamer wird und nicht viel schneller als der CPU-Code ist. Wenn Sie Ihre Daten in gemeinsam genutzten Theano-Variablen haben, besteht eine gute Chance, die gesamten Daten auf einmal auf die GPU zu kopieren, wenn die gemeinsam genutzten Variablen erstellt werden.
Später kann die GPU den Minibatch verwenden, indem sie auf diese gemeinsam genutzten Variablen zugreift, ohne Informationen aus dem CPU-Speicher kopieren zu müssen. Da die Datenpunkte normalerweise reelle Zahlen sind und ganze Zahlen bezeichnen, wäre es außerdem gut, unterschiedliche Variablen für diese sowie für das Validierungsset, ein Trainingsset und das Testset zu verwenden, um den Code leichter lesbar zu machen.
Der folgende Code zeigt Ihnen, wie Sie Daten speichern und auf einen Minibatch zugreifen:
Quelle
2. CIFAR-10-Datensatz
CIFAR steht für Canadian Institute for Advanced Research, und der CIFAR-10-Datensatz wurde von Forschern des CIFAR-Instituts zusammen mit dem CIFAR-100-Datensatz entwickelt. Der CIFAR-10-Datensatz besteht aus 60.000 32×32-Pixel-Farbbildern von Objekten, die zu zehn Klassen gehören, wie Katzen, Schiffe, Vögel, Frösche usw. Diese Bilder sind viel kleiner als ein durchschnittliches Foto und sind für Computer-Vision-Zwecke bestimmt.
CIFAR ist ein gut verstandener, unkomplizierter Datensatz, der bei der Bildklassifizierung mit dem CNN- Prozess zu 80 % und beim Testdatensatz zu 90 % genau ist. Außerdem können bis zu 1.000 Bilder über einen Teststapel und fünf Trainingsstapel verteilt werden.
Der CIFAR-10-Datensatz besteht aus 1.000 zufällig ausgewählten Bildern aus jeder Klasse, aber einige Stapel enthalten möglicherweise mehr Bilder aus einer Klasse als aus einer anderen. Die Trainingsstapel enthalten jedoch genau 5.000 Bilder aus jeder Klasse. Der CIFAR-10-Datensatz wird aufgrund seiner Benutzerfreundlichkeit als Ausgangspunkt für die Lösung von Problemen mit der Bildklassifizierung CNN unter Verwendung bevorzugt.
Das Design seines Testrahmens ist modular und kann mit fünf Elementen entwickelt werden, die das Laden des Datensatzes, die Modelldefinition, die Datensatzvorbereitung sowie die Auswertung und Ergebnispräsentation umfassen. Das folgende Beispiel zeigt den CIFAR-10-Datensatz unter Verwendung der Keras-API mit den ersten neun Bildern im Trainingsdatensatz:
Quelle
Das Ausführen des Beispiels lädt den CIFAR-10-Datensatz und druckt seine Form.
3. ImageNet
ImageNet zielt darauf ab, Bilder basierend auf vordefinierten Wörtern und Sätzen in fast 22.000 Kategorien zu kategorisieren und zu kennzeichnen. Dazu folgt es der WordNet-Hierarchie, in der jedes Wort oder jede Phrase ein Synonym oder Synset (kurz) ist. In ImageNet sind alle Bilder nach diesen Synsets organisiert, um über tausend Bilder pro Synset zu haben.
Wenn jedoch in Computer Vision und Deep Learning auf ImageNet verwiesen wird, ist eigentlich die ImageNet Large Scale Recognition Challenge oder ILSVRC gemeint. Das Ziel ist hier, ein Bild anhand von über 100.000 Testbildern in 1.000 verschiedene Kategorien einzuordnen, da der Trainingsdatensatz rund 1,2 Millionen Bilder enthält.
Die vielleicht größte Herausforderung besteht hier darin, dass die Bilder in ImageNet 224 × 224 messen und die Verarbeitung einer so großen Datenmenge daher eine enorme CPU-, GPU- und RAM-Kapazität erfordert. Dies könnte sich für einen durchschnittlichen Laptop als unmöglich erweisen, also wie überwindet man dieses Problem?
Eine Möglichkeit hierfür ist die Verwendung von Imagenette, einem aus ImageNet extrahierten Datensatz, der nicht zu viele Ressourcen benötigt. Dieser Datensatz hat zwei Ordner mit den Namen „train“ (Training) und „Val“ (Validierung) mit individuellen Ordnern für jede Klasse. Alle diese Klassen haben dieselbe ID wie der ursprüngliche Datensatz, wobei jede der Klassen etwa 1.000 Bilder hat, sodass die gesamte Einrichtung ziemlich ausgewogen ist.
Eine weitere Option ist die Verwendung von Transfer Learning, einer Methode, die vorab trainierte Gewichtungen für große Datensätze verwendet. Dies ist eine sehr effektive Art der Bildklassifizierung mit CNN, da wir damit Modelle erstellen können, die für uns gut funktionieren. Der einzige Aspekt, den eine Bildklassifizierung unter Verwendung des CNN -Modells leisten können sollte, ist, Bilder zu klassifizieren, die zu derselben Klasse gehören, und zwischen solchen zu unterscheiden, die unterschiedlich sind. Hier können wir auf die vortrainierten Gewichte zurückgreifen. Der Vorteil hier ist, dass wir je nach Art des Datensatzes, mit dem wir arbeiten, unterschiedliche Methoden verwenden können.
Lesen Sie auch: Die 7 Arten von künstlichen neuronalen Netzen, die ML-Ingenieure kennen müssen
Zusammenfassen
Zusammenfassend lässt sich sagen, dass die Bildklassifizierung mit CNN den Prozess einfacher, genauer und weniger prozessintensiv gemacht hat. Wenn Sie tiefer in maschinelles Lernen eintauchen möchten, bietet upGrad eine Reihe von Kursen, die Ihnen helfen, es wie ein Profi zu meistern!
upGrad bietet verschiedene Kurse online mit einer Vielzahl von Unterkategorien an; Besuchen Sie die offizielle Website für weitere Informationen.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet, IIIT- B-Alumni-Status, mehr als 5 praktische, praktische Abschlussprojekte und Jobunterstützung bei Top-Unternehmen.
Was sind Convolutional Neural Networks?
Convolutional Neural Networks (CNNs) oder Convnets sind eine Kategorie von Deep-Feed-Forward-künstlichen neuronalen Netzwerken, die am häufigsten zur Analyse visueller Bilder verwendet werden. Das Design von CNNs ist lose von der Organisation des visuellen Kortex von Säugetieren inspiriert, obwohl sie auch auf Audio, Sprache und andere Bereiche angewendet wurden. CNNs verwenden eine Variation von mehrschichtigen Perceptrons, die so konzipiert sind, dass sie eine minimale Vorverarbeitung erfordern. Dies macht sie weniger fehleranfällig und besser auf eine Vielzahl von Problemen übertragbar, opfert jedoch die Fähigkeit, nichtlineare Transformationen an ihren Eingaben durchzuführen.
Warum sind Convolutional Neural Networks gut für die Bildklassifizierung?
Die große Einschränkung von CNN besteht darin, dass es den Kontext in einem Bild nicht erfassen kann. Es ist auch nicht in der Lage, Gesichter zu machen und Farbe zu machen. Weitere Einschränkungen von CNN: Die in neuronalen Netzen verwendeten Lerntechniken reichen nicht aus, um höhere kognitive Funktionen wie Objekterkennung, Lernen, räumliches Bewusstsein und die Fähigkeit zur Übertragung von Erfahrungen zu reproduzieren. Die Architektur neuronaler Netze ist nicht flexibel genug, um diese Einschränkungen zu überwinden.