
Utilisation du réseau neuronal convolutif pour la classification des images
Publié: 2020-08-14La classification des images fait peau neuve. Merci à CNN.
Les réseaux de neurones convolutifs (CNN) sont l'épine dorsale de la classification des images, un phénomène d'apprentissage en profondeur qui prend une image et lui attribue une classe et une étiquette qui la rend unique. La classification d'images à l'aide de CNN constitue une partie importante des expériences d'apprentissage automatique.
En plus de l'utilisation de CNN et de ses capacités induites, il est désormais largement utilisé pour une gamme d'applications, allant du marquage d'images Facebook aux recommandations de produits Amazon et aux images de soins de santé aux voitures automatiques. La raison pour laquelle CNN est si populaire est qu'il nécessite très peu de prétraitement, ce qui signifie qu'il peut lire des images 2D en appliquant des filtres que d'autres algorithmes conventionnels ne peuvent pas. Nous approfondirons le processus de fonctionnement de la classification des images à l'aide de CNN .
Table des matières
Comment fonctionne CNN ?
Les CNN sont équipés d'une couche d'entrée, d'une couche de sortie et de couches cachées, qui aident toutes à traiter et à classer les images. Les couches cachées comprennent des couches convolutionnelles, des couches ReLU, des couches de regroupement et des couches entièrement connectées, qui jouent toutes un rôle crucial. En savoir plus sur les réseaux de neurones convolutifs.
Voyons comment fonctionne la classification d'images à l'aide de CNN :
Imaginez que l'image d'entrée soit celle d'un éléphant. Cette image, avec des pixels, est d'abord entrée dans les couches convolutionnelles. S'il s'agit d'une image en noir et blanc, l'image est interprétée comme un calque 2D, chaque pixel se voyant attribuer une valeur comprise entre '0' et '255', '0' étant entièrement noir et '255' entièrement blanc. Si, d'autre part, il s'agit d'une image couleur, cela devient un tableau 3D, avec une couche bleue, verte et rouge, avec chaque valeur de couleur comprise entre 0 et 255.

La lecture de la matrice commence alors, pour laquelle le logiciel sélectionne une image plus petite, appelée 'filtre' (ou noyau). La profondeur du filtre est la même que la profondeur de l'entrée. Le filtre produit alors un mouvement de convolution avec l'image d'entrée, se déplaçant le long de l'image d'une unité.
Il multiplie ensuite les valeurs avec les valeurs d'origine de l'image. Tous les chiffres multipliés sont additionnés et un seul nombre est généré. Le processus est répété avec l'image entière et une matrice est obtenue, plus petite que l'image d'entrée d'origine.
Le tableau final est appelé la carte des fonctionnalités d'une carte d'activation. La convolution d'une image permet d'effectuer des opérations telles que la détection des contours, la netteté et le flou, en appliquant différents filtres. Il suffit de spécifier des aspects tels que la taille du filtre, le nombre de filtres et/ou l'architecture du réseau.
D'un point de vue humain, cette action s'apparente à l'identification des couleurs simples et des limites d'une image. Cependant, pour classer l'image et reconnaître les caractéristiques qui en font, disons, celle d'un éléphant et non d'un chat, des caractéristiques uniques telles que les grandes oreilles et la trompe de l'éléphant doivent être identifiées. C'est là qu'interviennent les couches non linéaires et de regroupement.
La couche non linéaire (ReLU) suit la couche de convolution, où une fonction d'activation est appliquée aux cartes de caractéristiques pour augmenter la non-linéarité de l'image. La couche ReLU supprime toutes les valeurs négatives et augmente la précision de l'image. Bien qu'il existe d'autres opérations comme tanh ou sigmoïde, ReLU est la plus populaire car elle peut entraîner le réseau beaucoup plus rapidement.
L'étape suivante consiste à créer plusieurs images du même objet afin que le réseau puisse toujours reconnaître cette image, quelle que soit sa taille ou son emplacement. Par exemple, dans l'image de l'éléphant, le réseau doit reconnaître l'éléphant, qu'il marche, qu'il soit immobile ou qu'il coure. Il doit y avoir une flexibilité d'image, et c'est là que la couche de regroupement entre en jeu.
Il fonctionne avec les mesures de l'image (hauteur et largeur) pour réduire progressivement la taille de l'image d'entrée afin que les objets de l'image puissent être repérés et identifiés où qu'ils se trouvent.
La mise en commun permet également de contrôler le "surajustement" lorsqu'il y a trop d'informations sans possibilité d'en ajouter de nouvelles. L'exemple le plus courant de regroupement est peut-être le regroupement maximal, où l'image est divisée en une série de zones qui ne se chevauchent pas.
La mise en commun maximale consiste à identifier la valeur maximale dans chaque zone afin que toutes les informations supplémentaires soient exclues et que l'image devienne plus petite. Cette action permet également de tenir compte des distorsions de l'image.
Vient maintenant la couche entièrement connectée qui ajoute un réseau de neurones artificiels pour utiliser CNN. Ce réseau artificiel combine différentes fonctionnalités et permet de prédire les classes d'images avec une plus grande précision. A ce stade, le gradient de la fonction d'erreur est calculé sur le poids du réseau de neurones. Les pondérations et les détecteurs de caractéristiques sont ajustés pour optimiser les performances, et ce processus est répété à plusieurs reprises.
Voici à quoi ressemble l'architecture CNN :
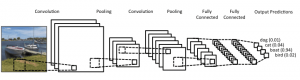
La source
Tirer parti des ensembles de données pour CNN Application-MNIST
Plusieurs ensembles de données peuvent être utilisés pour appliquer efficacement CNN. Les trois plus populaires indispensables à la classification d'images à l'aide de CNN sont MNIST, CIFAR-10 et ImageNet. Regardons d'abord MNIST.
1. MNIST
MNIST est l'acronyme de l'ensemble de données Modified National Institute of Standards and Technology et comprend 60 000 petites images carrées en niveaux de gris 28 × 28 de chiffres manuscrits simples entre 0 et 9. MNIST est un ensemble de données populaire et bien compris qui est, pour le plus grand partie, 'résolu.' Il peut être utilisé dans la vision par ordinateur et l'apprentissage en profondeur pour pratiquer, développer et évaluer la classification d'images à l'aide de CNN . Entre autres choses, cela comprend des étapes pour évaluer les performances du modèle, explorer les améliorations possibles et l'utiliser pour prédire de nouvelles données.
Son USP est qu'il dispose déjà d'un ensemble de données d'entraînement et de test bien défini que nous pouvons utiliser. Cet ensemble d'entraînement peut en outre être divisé en un ensemble de données d'entraînement et de validation si l'on a besoin d'évaluer les performances d'un modèle d'exécution d'entraînement. Ses performances dans l'ensemble d'entraînement et de validation à chaque exécution peuvent être enregistrées sous forme de courbes d'apprentissage pour mieux comprendre dans quelle mesure le modèle apprend le problème.
Keras, l'une des principales API de réseau de neurones, prend cela en charge en stipulant l'argument "validation_data " au modèle. Fonction Fit() lors de l'entraînement du modèle, qui renvoie finalement un objet qui mentionne les performances du modèle pour la perte et les métriques à chaque exécution d'entraînement. Heureusement, MNIST est équipé de Keras par défaut, et les fichiers d'entraînement et de test peuvent être chargés en quelques lignes de code seulement.
Fait intéressant, un article de Yann LeCun, professeur au Courant Institute of Mathematical Sciences de l'Université de New York et de Corinna Cortes, chercheuse scientifique chez Google Labs à New York, souligne que la base de données spéciale 3 (SD-3) du MNIST a été initialement attribuée en tant que ensemble d'entraînement. La base de données spéciale 1 (SD-1) a été désignée comme ensemble de test.

Cependant, ils pensent que le SD-3 est beaucoup plus facile à identifier et à reconnaître que le SD-1 car le SD-3 a été recueilli auprès d'employés travaillant au Bureau du recensement, tandis que le SD-1 provenait d'élèves du secondaire. Étant donné que les conclusions précises des expériences d'apprentissage exigent que le résultat soit indépendant de l'ensemble d'apprentissage et du test, il a été jugé nécessaire de développer une nouvelle base de données en manquant les ensembles de données.
Lors de l'utilisation du jeu de données, il est recommandé de le diviser en mini-lots, de le stocker dans des variables partagées et d'y accéder en fonction de l'index du mini-lot. Vous pourriez vous interroger sur le besoin de variables partagées, mais cela est lié à l'utilisation du GPU. Ce qui se passe, c'est que lors de la copie de données dans la mémoire GPU, si vous copiez chaque mini-lot séparément au fur et à mesure des besoins, le code GPU ralentira et ne sera pas beaucoup plus rapide que le code CPU. Si vous avez vos données dans des variables partagées Theano, il y a de fortes chances de copier toutes les données sur le GPU en une seule fois lorsque les variables partagées sont construites.
Plus tard, le GPU peut utiliser le minibatch en accédant à ces variables partagées sans avoir besoin de copier les informations de la mémoire du CPU. De plus, comme les points de données sont généralement des nombres réels et des entiers d'étiquettes, il serait bon d'utiliser différentes variables pour ceux-ci ainsi que pour l'ensemble de validation, un ensemble d'apprentissage et un ensemble de test, afin de faciliter la lecture du code.
Le code ci-dessous vous montre comment stocker des données et accéder à un minibatch :
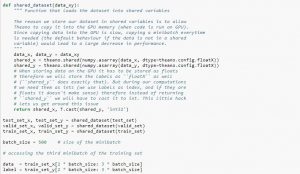
La source
2. Ensemble de données CIFAR-10
CIFAR signifie l'Institut canadien de recherches avancées, et l'ensemble de données CIFAR-10 a été développé par des chercheurs de l'institut CIFAR, avec l'ensemble de données CIFAR-100. L'ensemble de données CIFAR-10 se compose de 60 000 images couleur de 32 × 32 pixels d'objets appartenant à dix classes telles que des chats, des navires, des oiseaux, des grenouilles, etc. Ces images sont beaucoup plus petites qu'une photographie moyenne et sont destinées à des fins de vision par ordinateur.
CIFAR est un ensemble de données simple et bien compris qui est précis à 80 % dans la classification des images à l'aide du processus CNN et à 90 % dans l'ensemble de données de test. En outre, jusqu'à 1 000 images réparties sur un lot de test et cinq lots de formation.
L'ensemble de données CIFAR-10 se compose de 1 000 images sélectionnées au hasard dans chaque classe, mais certains lots peuvent contenir plus d'images d'une classe que d'une autre. Cependant, les lots de formation contiennent exactement 5 000 images de chaque classe. L'ensemble de données CIFAR-10 est préféré pour sa facilité d'utilisation comme point de départ pour résoudre les problèmes de classification d'images CNN .
La conception de son harnais de test est modulaire et peut être développée avec cinq éléments qui incluent le chargement de l'ensemble de données, la définition du modèle, la préparation de l'ensemble de données, ainsi que l'évaluation et la présentation des résultats. L'exemple ci-dessous montre l'ensemble de données CIFAR-10 utilisant l'API Keras avec les neuf premières images de l'ensemble de données d'apprentissage :
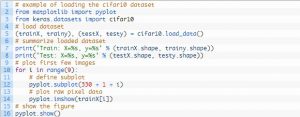
La source
L'exécution de l'exemple charge le jeu de données CIFAR-10 et imprime leur forme.
3. Image Net
ImageNet vise à catégoriser et à étiqueter les images en près de 22 000 catégories basées sur des mots et des phrases prédéfinis. Pour ce faire, il suit la hiérarchie WordNet, où chaque mot ou phrase est un synonyme ou un synset (en bref). Dans ImageNet, toutes les images sont organisées selon ces synsets, pour avoir plus d'un millier d'images par synset.
Cependant, lorsque ImageNet est mentionné dans la vision par ordinateur et l'apprentissage en profondeur, il s'agit en réalité du défi de reconnaissance à grande échelle ImageNet ou ILSVRC. L'objectif ici est de catégoriser une image en 1 000 catégories différentes en utilisant plus de 100 000 images de test puisque l'ensemble de données d'entraînement contient environ 1,2 million d'images.
Le plus grand défi ici est peut-être que les images dans ImageNet mesurent 224 × 224, et donc le traitement d'une si grande quantité de données nécessite une capacité massive de CPU, de GPU et de RAM. Cela pourrait s'avérer impossible pour un ordinateur portable moyen, alors comment surmonter ce problème ?
Une façon de faire est d'utiliser Imagenette, un jeu de données extrait d'ImageNet qui ne nécessite pas trop de ressources. Cet ensemble de données a deux dossiers nommés 'train' (formation) et 'Val' (validation) avec des dossiers individuels pour chaque classe. Toutes ces classes ont le même ID que l'ensemble de données d'origine, chacune des classes ayant environ 1 000 images, de sorte que l'ensemble est assez équilibré.
Une autre option consiste à utiliser l'apprentissage par transfert, une méthode qui utilise des poids pré-formés sur de grands ensembles de données. C'est un moyen très efficace de classification d'images à l'aide de CNN car nous pouvons l'utiliser pour produire des modèles qui fonctionnent bien pour nous. Le seul aspect qu'une classification d'images utilisant le modèle CNN devrait pouvoir faire est de classer les images appartenant à la même classe et de distinguer celles qui sont différentes. C'est là que nous pouvons utiliser les poids pré-formés. L'avantage ici est que nous pouvons utiliser différentes méthodes selon le type d'ensemble de données avec lequel nous travaillons.
Lisez aussi: Les 7 types de réseaux de neurones artificiels que les ingénieurs ML doivent connaître
Résumé
En résumé, la classification des images à l'aide de CNN a rendu le processus plus facile, plus précis et moins lourd. Si vous souhaitez approfondir l'apprentissage automatique, upGrad propose une gamme de cours qui vous aideront à le maîtriser comme un pro !
upGrad propose divers cours en ligne avec un large éventail de sous-catégories ; visitez le site officiel pour plus d'informations.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le diplôme PG en apprentissage automatique et IA de IIIT-B & upGrad, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT- Statut B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Que sont les réseaux de neurones convolutifs ?
Les réseaux de neurones convolutifs (CNN), ou convnets, sont une catégorie de réseaux de neurones artificiels profonds et à anticipation, le plus souvent appliqués à l'analyse d'images visuelles. La conception des CNN est vaguement inspirée de l'organisation du cortex visuel des mammifères, bien qu'ils aient également été appliqués à l'audio, à la parole et à d'autres domaines. Les CNN utilisent une variante de perceptrons multicouches conçus pour nécessiter un prétraitement minimal. Cela les rend moins sujets aux erreurs et plus portables pour un ensemble diversifié de problèmes, mais sacrifie la capacité d'effectuer des transformations non linéaires sur leurs entrées.
Pourquoi les réseaux de neurones convolutifs sont-ils bons pour la classification d'images ?
La grande limitation de CNN est qu'il est incapable de saisir le contexte d'une image. Il est également incapable de faire des visages et de faire de la couleur. Plus de limites de CNN : les techniques d'apprentissage utilisées dans les réseaux de neurones ne sont pas suffisantes pour reproduire des fonctions cognitives supérieures telles que la reconnaissance d'objets, l'apprentissage, la conscience spatiale et la capacité de transférer l'expérience. L'architecture des réseaux de neurones n'est pas suffisamment flexible pour surmonter ces limitations.