
使用卷積神經網絡進行圖像分類
已發表: 2020-08-14圖像分類得到改造。 感謝美國有線電視新聞網。
卷積神經網絡 (CNN) 是圖像分類的支柱,這是一種深度學習現象,它獲取圖像並為其分配一個類別和一個標籤,使其獨一無二。 使用 CNN 進行圖像分類是機器學習實驗的重要組成部分。
連同使用 CNN 及其誘導功能,它現在被廣泛用於一系列應用程序——從 Facebook 圖片標籤到亞馬遜產品推薦和醫療保健圖像到自動駕駛汽車。 CNN 如此受歡迎的原因是它只需要很少的預處理,這意味著它可以通過應用其他傳統算法無法做到的過濾器來讀取 2D 圖像。 我們將深入研究使用 CNN 進行圖像分類的過程。
目錄
CNN 是如何運作的?
CNN配備了輸入層、輸出層和隱藏層,所有這些都有助於處理和分類圖像。 隱藏層包括卷積層、ReLU 層、池化層和全連接層,它們都起著至關重要的作用。 了解有關卷積神經網絡的更多信息。
讓我們看看使用 CNN 進行圖像分類的工作原理:
假設輸入圖像是大象的圖像。 這個帶有像素的圖像首先被輸入到卷積層中。 如果是黑白圖片,則圖像被解釋為 2D 圖層,每個像素都分配一個介於“0”和“255”之間的值,“0”是全黑,“255”是全白。 另一方面,如果它是一張彩色圖片,這將成為一個 3D 數組,具有藍色、綠色和紅色層,每個顏色值介於 0 和 255 之間。

然後開始讀取矩陣,軟件為此選擇一個較小的圖像,稱為“過濾器”(或內核)。 濾波器的深度與輸入的深度相同。 然後,過濾器與輸入圖像一起產生卷積運動,沿圖像向右移動 1 個單位。
然後它將這些值與原始圖片值相乘。 所有相乘的數字相加,生成一個數字。 該過程與整個圖像一起重複,得到一個矩陣,小於原始輸入圖像。
最終的數組稱為激活圖的特徵圖。 通過應用不同的過濾器,圖像的捲積有助於執行邊緣檢測、銳化和模糊等操作。 只需指定過濾器的大小、過濾器的數量和/或網絡架構等方面。
從人類的角度來看,這個動作類似於識別圖像的簡單顏色和邊界。 但是,為了對圖像進行分類並識別使其具有的特徵,例如大象而不是貓的特徵,需要識別大象的大耳朵和軀乾等獨特特徵。 這就是非線性和池化層的用武之地。
非線性層 (ReLU) 位於卷積層之後,其中將激活函數應用於特徵圖以增加圖像的非線性。 ReLU 層去除了所有的負值,提高了圖像的準確性。 儘管還有其他操作,例如 tanh 或 sigmoid,但 ReLU 是最受歡迎的,因為它可以更快地訓練網絡。
下一步是創建同一對象的多個圖像,以便網絡始終可以識別該圖像,無論其大小或位置如何。 例如,在大像圖片中,網絡必須識別大象,無論它是行走、靜止還是奔跑。 必須有圖像靈活性,這就是池化層的用武之地。
它與圖像的測量值(高度和寬度)一起工作,以逐漸減小輸入圖像的大小,以便可以在圖像中的任何位置發現和識別對象。
池化還有助於控制“過度擬合”,即信息過多而沒有新信息的空間。 也許,池化最常見的例子是最大池化,其中圖像被劃分為一系列不重疊的區域。
最大池化就是識別每個區域的最大值,從而排除所有額外的信息,圖像變得更小。 此操作也有助於解釋圖像中的失真。
現在是全連接層,它添加了一個人工神經網絡以使用 CNN。 這種人工網絡結合了不同的特徵,有助於更準確地預測圖像類別。 在這個階段,關於神經網絡的權重計算誤差函數的梯度。 調整權重和特徵檢測器以優化性能,並重複此過程。
這是 CNN 架構的樣子:
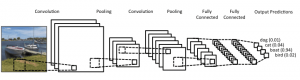
資源
利用 CNN 應用程序-MNIST 的數據集
可以使用幾個數據集來有效地應用 CNN。 使用 CNN 進行圖像分類的三個最受歡迎的方法是 MNIST、CIFAR-10 和 ImageNet。 我們先來看看 MNIST。
1. MNIST
MNIST 是 Modified National Institute of Standards and Technology 數據集的首字母縮寫詞,包含 60,000 個 0 到 9 之間單個手寫數字的 28×28 正方形小灰度圖像。MNIST 是一個流行且易於理解的數據集,即部分,“解決了。” 它可用於計算機視覺和深度學習,以使用 CNN 來練習、開發和評估圖像分類。 除其他外,這包括評估模型性能、探索可能的改進以及使用它來預測新數據的步驟。
它的獨特之處在於它已經有一個我們可以使用的定義明確的訓練和測試數據集。 如果需要評估訓練運行模型的性能,該訓練集可以進一步分為訓練和驗證數據集。 它在每次運行的訓練和驗證集中的表現可以記錄為學習曲線,以便更深入地了解模型對問題的學習效果。
Keras 是領先的神經網絡 API 之一,它通過為模型規定“validation_data ”參數來支持這一點。 訓練模型時的 Fit() 函數,最終返回一個對象,該對象提到模型性能的損失和每次訓練運行的指標。 幸運的是,MNIST 默認配備了 Keras,只需幾行代碼即可加載訓練和測試文件。

有趣的是,紐約大學 Courant 數學科學研究所教授 Yann LeCun 和紐約谷歌實驗室研究科學家 Corinna Cortes 的一篇文章指出,MNIST 的特殊數據庫 3 (SD-3) 最初被指定為訓練集。 特殊數據庫 1 (SD-1) 被指定為測試集。
但是,他們認為 SD-3 比 SD-1 更容易識別和識別,因為 SD-3 是從人口普查局的員工那裡收集的,而 SD-1 是從高中生中獲取的。 由於學習實驗的準確結論要求結果必須獨立於訓練集和測試,因此認為有必要通過丟失數據集來開發新的數據庫。
使用數據集時,建議將其分成minibatch,存儲在共享變量中,根據minibatch索引訪問。 您可能想知道是否需要共享變量,但這與使用 GPU 有關。 發生的情況是,當將數據複製到 GPU 內存中時,如果您在需要時單獨複製每個 minibatch,GPU 代碼將變慢並且不會比 CPU 代碼快多少。 如果您將數據保存在 Theano 共享變量中,則很有可能在構建共享變量時一次性將整個數據複製到 GPU 上。
稍後,GPU 可以通過訪問這些共享變量來使用 minibatch,而無需從 CPU 內存中復制信息。 此外,由於數據點通常是實數和標籤整數,因此最好為這些以及驗證集、訓練集和測試集使用不同的變量,以使代碼更易於閱讀。
下面的代碼向您展示瞭如何存儲數據和訪問小批量:
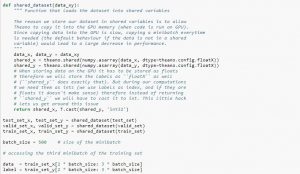
資源
2. CIFAR-10 數據集
CIFAR 代表加拿大高級研究所,CIFAR-10 數據集是由 CIFAR 研究所的研究人員與 CIFAR-100 數據集一起開發的。 CIFAR-10 數據集由 60,000 張 32×32 像素的彩色圖像組成,這些圖像屬於貓、船、鳥、青蛙等十類物體。這些圖像比普通照片小得多,旨在用於計算機視覺目的。
CIFAR 是一個很好理解、簡單明了的數據集,在使用 CNN過程的圖像分類中準確率為 80%,在測試數據集上準確率為 90%。 此外,多達 1,000 張圖像分佈在一個測試批次和五個訓練批次中。
CIFAR-10 數據集由每個類別的 1,000 個隨機選擇的圖像組成,但某些批次可能包含來自一個類別的圖像多於另一個類別。 但是,訓練批次正好包含來自每個類別的 5,000 張圖像。 CIFAR-10 數據集因其易於使用而成為解決圖像分類 CNN使用問題的起點。
其測試工具的設計是模塊化的,它可以由數據集加載、模型定義、數據集準備以及評估和結果呈現五個要素進行開發。 下面的示例顯示了使用 Keras API 的 CIFAR-10 數據集以及訓練數據集中的前九張圖像:
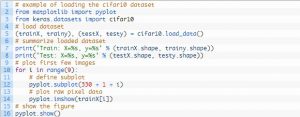
資源
運行該示例會加載 CIFAR-10 數據集並打印它們的形狀。
3. 圖像網
ImageNet 旨在根據預定義的單詞和短語將圖像分類和標記為近 22,000 個類別。 為此,它遵循 WordNet 層次結構,其中每個單詞或短語都是同義詞或同義詞集(簡而言之)。 在 ImageNet 中,所有圖像都根據這些同義詞集進行組織,每個同義詞集有超過一千張圖像。
然而,當在計算機視覺和深度學習中提到 ImageNet 時,實際上指的是 ImageNet 大規模識別挑戰賽或 ILSVRC。 這裡的目標是使用超過 100,000 張測試圖像將圖像分類為 1,000 個不同的類別,因為訓練數據集包含大約 120 萬張圖像。
也許這裡最大的挑戰是 ImageNet 中的圖像尺寸為 224×224,因此處理如此大量的數據需要大量的 CPU、GPU 和 RAM 容量。 這對於普通筆記本電腦來說可能是不可能的,那麼如何克服這個問題呢?
一種方法是使用 Imagenette,它是從 ImageNet 中提取的不需要太多資源的數據集。 該數據集有兩個文件夾,名為“train”(訓練)和“Val”(驗證),每個類都有單獨的文件夾。 所有這些類都具有與原始數據集相同的 ID,每個類都有大約 1,000 張圖像,因此整個設置非常平衡。
另一種選擇是使用遷移學習,這是一種在大型數據集上使用預訓練權重的方法。 這是使用 CNN進行圖像分類的一種非常有效的方法,因為我們可以使用它來生成適合我們的模型。 使用 CNN模型的圖像分類應該能夠做的一個方面是對屬於同一類的圖像進行分類並區分不同的圖像。 這是我們可以利用預訓練權重的地方。 這裡的優點是我們可以根據我們正在使用的數據集的類型使用不同的方法。
另請閱讀:機器學習工程師需要知道的 7 種人工神經網絡
加起來
總而言之,使用 CNN 進行圖像分類使該過程更容易、更準確且處理量更少。 如果您想更深入地研究機器學習, upGrad有一系列課程可以幫助您像專業人士一樣掌握它!
upGrad提供各種在線課程,包含廣泛的子類別; 訪問官方網站了解更多信息。
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT- B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。
什麼是卷積神經網絡?
卷積神經網絡 (CNN) 或 convnets 是一類深度前饋人工神經網絡,最常用於分析視覺圖像。 CNN 的設計大致受到哺乳動物視覺皮層組織的啟發,儘管它們也被應用於音頻、語音和其他領域。 CNN 使用多層感知器的變體,旨在要求最少的預處理。 這使得它們更不容易出錯並且更易於處理各種問題,但犧牲了對其輸入執行非線性變換的能力。
為什麼卷積神經網絡適用於圖像分類?
CNN 的一大局限是它無法掌握圖像中的上下文。 它也不能做面孔和做顏色。 CNN 的更多局限性:神經網絡中使用的學習技術不足以再現更高的認知功能,例如物體識別、學習、空間意識和傳遞經驗的能力。 神經網絡的架構不夠靈活,無法克服這些限制。