
บทนำเชิงปฏิบัติเกี่ยวกับการตรวจสอบความถูกต้องของแบบจำลองและการทำให้เป็นมาตรฐานในการเรียนรู้เชิงลึกโดยใช้ TensorFlow
เผยแพร่แล้ว: 2020-10-28สารบัญ
บทนำ
แนวปฏิบัติของเครื่องจักรในการดูดซึมข้อมูลผ่านกระบวนทัศน์ของอัลกอริธึมการเรียนรู้ภายใต้การดูแลได้ปฏิวัติงานหลายอย่าง เช่น การสร้างลำดับ การประมวลผลภาษาธรรมชาติ และแม้แต่คอมพิวเตอร์วิทัศน์ วิธีนี้ใช้ชุดข้อมูลซึ่งมีชุดคุณลักษณะอินพุตและชุดป้ายกำกับที่เกี่ยวข้อง จากนั้นเครื่องจะใช้ข้อมูลนี้ในรูปแบบของคุณสมบัติและป้ายกำกับเพื่อเรียนรู้การกระจายและรูปแบบของข้อมูลเพื่อคาดการณ์ทางสถิติเกี่ยวกับอินพุตที่มองไม่เห็น
ขั้นตอนสำคัญยิ่งในการออกแบบโมเดลการเรียนรู้เชิงลึกคือการประเมินประสิทธิภาพของโมเดล โดยเฉพาะอย่างยิ่งในจุดข้อมูลใหม่และที่มองไม่เห็น เป้าหมายหลักคือการพัฒนาแบบจำลองที่มีลักษณะทั่วไปมากกว่าข้อมูลที่ได้รับการฝึกอบรม เราต้องการโมเดลที่สามารถคาดการณ์ได้ดีและเชื่อถือได้ในโลกแห่งความเป็นจริง แนวคิดสำคัญที่ช่วยเราในเรื่องนี้คือการตรวจสอบแบบจำลองและการทำให้เป็นมาตรฐานซึ่งเราจะกล่าวถึงในวันนี้
การตรวจสอบแบบจำลอง
การสร้างโมเดลแมชชีนเลิร์นนิงมักจะต้องแยกข้อมูลที่มีอยู่ออกเป็นสามชุด: การฝึก การตรวจสอบ และชุดทดสอบ ข้อมูลการฝึกอบรมถูกใช้โดยแบบจำลองเพื่อเรียนรู้นิสัยใจคอและลักษณะของการแจกแจง
จุดโฟกัสที่ควรทราบคือประสิทธิภาพที่น่าพอใจของโมเดลในชุดการฝึกไม่ได้หมายความว่าโมเดลจะสรุปข้อมูลใหม่ที่มีประสิทธิภาพใกล้เคียงกัน เนื่องจากโมเดลมี อคติ กับชุดการฝึก แนวคิดของการตรวจสอบความถูกต้องและชุดทดสอบจึงใช้เพื่อรายงานว่าแบบจำลองสรุปจุดข้อมูลใหม่ได้ดีเพียงใด
ขั้นตอนมาตรฐานคือการใช้ข้อมูลการฝึกอบรมเพื่อให้พอดีกับแบบจำลอง ประเมินประสิทธิภาพของแบบจำลองโดยใช้ข้อมูลการตรวจสอบความถูกต้อง และสุดท้ายจะใช้ข้อมูลการทดสอบเพื่อประเมินว่าแบบจำลองจะทำงานได้ดีเพียงใดกับตัวอย่างใหม่อย่างแท้จริง
ชุดตรวจสอบความถูกต้องใช้เพื่อปรับแต่งไฮเปอร์พารามิเตอร์ (จำนวนเลเยอร์ที่ซ่อนอยู่ อัตราการเรียนรู้ อัตราการออกกลางคัน ฯลฯ) เพื่อให้โมเดลสามารถสรุปผลได้ดี ปริศนาทั่วไปที่มือใหม่หัดเรียนรู้ของเครื่องต้องเผชิญคือการทำความเข้าใจความจำเป็นในการตรวจสอบและชุดทดสอบที่แยกจากกัน

ความต้องการชุดที่แตกต่างกันสองชุดสามารถเข้าใจได้ด้วยสัญชาตญาณต่อไปนี้: สำหรับโครงข่ายประสาทเทียมระดับลึกทุกเครือข่ายที่จำเป็นต้องได้รับการออกแบบ มีพารามิเตอร์ไฮเปอร์พารามิเตอร์หลายตัวที่จำเป็นต้องปรับเพื่อให้ได้ประสิทธิภาพที่น่าพอใจ
สามารถฝึกแบบจำลองได้หลายแบบโดยใช้ไฮเปอร์พารามิเตอร์ตัวใดตัวหนึ่ง จากนั้นจึงเลือกแบบจำลองที่มีตัวชี้วัดประสิทธิภาพที่ดีที่สุดตามประสิทธิภาพของแบบจำลองนั้นในชุดการตรวจสอบ ทุกครั้งที่ปรับแต่งไฮเปอร์พารามิเตอร์เพื่อประสิทธิภาพที่ดีขึ้นในชุดตรวจสอบ ข้อมูลบางส่วน รั่วไหล/ป้อน เข้าในแบบจำลอง ดังนั้น น้ำหนักสุดท้ายของโครงข่ายประสาทเทียมอาจ มีอคติ ต่อชุดการตรวจสอบความถูกต้อง
หลังจากการปรับไฮเปอร์พารามิเตอร์แต่ละครั้ง โมเดลของเรายังคงทำงานได้ดีในชุดการตรวจสอบความถูกต้อง เนื่องจากนั่นคือสิ่งที่เราปรับให้เหมาะสมที่สุด นี่คือเหตุผลที่การทดสอบการตรวจสอบความถูกต้องไม่สามารถระบุถึงความสามารถทั่วไปของแบบจำลองได้อย่างแม่นยำ เพื่อเอาชนะข้อเสียนี้ ชุดทดสอบจึงเริ่มมีผล
การแสดงความสามารถการวางนัยทั่วไปของแบบจำลองที่แม่นยำที่สุดนั้นมาจากประสิทธิภาพในชุดทดสอบ เนื่องจากเราไม่ได้ปรับแบบจำลองให้เหมาะสมเพื่อประสิทธิภาพที่ดีขึ้นในชุดนี้ และด้วยเหตุนี้ สิ่งนี้จะบ่งบอกถึงการประเมินความสามารถของแบบจำลองในทางปฏิบัติในทางปฏิบัติมากที่สุด
ต้องอ่าน: เทคนิคการเรียนรู้เชิงลึกยอดนิยมที่คุณควรรู้
การใช้กลยุทธ์การตรวจสอบความถูกต้องโดยใช้ TensorFlow 2.0
TensorFlow 2.0 นำเสนอโซลูชันที่ง่ายมากในการติดตามประสิทธิภาพของแบบจำลองของเราในการทดสอบการตรวจสอบความถูกต้องที่แยกไว้ต่างหาก เราสามารถส่งผ่าน อาร์กิวเมนต์คีย์เวิร์ด validation_split ใน เมธอด model.fit() ได้
คีย์เวิร์ด validation_split รับ อินพุตเป็นตัวเลขลอยตัวระหว่าง 0 & 1 ซึ่งแสดงถึงเศษส่วนของข้อมูลการฝึกที่จะใช้เป็นข้อมูลการตรวจสอบ ดังนั้น การส่งผ่านค่า 0.1 ในคีย์เวิร์ดหมายถึงการสำรอง 10% ของข้อมูลการฝึกอบรมเพื่อตรวจสอบความถูกต้อง
การใช้งานจริงของการแยกการตรวจสอบความถูกต้องสามารถแสดงให้เห็นได้อย่างง่ายดายโดยใช้ ชุดข้อมูลเบาหวาน จาก sklearn ชุดข้อมูลมี 442 อินสแตนซ์ที่มี 10 ตัวแปรพื้นฐาน (อายุ เพศ BMI ฯลฯ) เป็นคุณสมบัติการฝึกอบรมและการวัดความก้าวหน้าของโรคหลังจากหนึ่งปีเป็นป้ายกำกับ
เรานำเข้าชุดข้อมูลโดยใช้ TensorFlow และ sklearn:

ขั้นตอนพื้นฐานหลังจากการประมวลผลข้อมูลล่วงหน้าคือการสร้างโครงข่ายประสาทเทียมแบบ feedforward ที่มีเลเยอร์หนาแน่น:

ที่นี่ เรามีโครงข่ายประสาทเทียมที่มีเลเยอร์ที่ซ่อนอยู่หกชั้นพร้อม การเปิดใช้งาน relu และอีกหนึ่งชั้นเอาต์พุตพร้อม การ เปิดใช้งาน เชิงเส้น
จากนั้นเราคอมไพล์โมเดลด้วย Adam Optimizer และ หมายถึง ฟังก์ชันการสูญเสีย ข้อผิดพลาดกำลังสอง


จาก นั้นใช้เมธอด model.fit() เพื่อฝึกโมเดลสำหรับ 100 ยุคด้วย validation_split 15%

เราอาจพล็อตการสูญเสียของแบบจำลองตามที่สังเกตได้จากทั้งข้อมูลการฝึกอบรมและข้อมูลการตรวจสอบ:
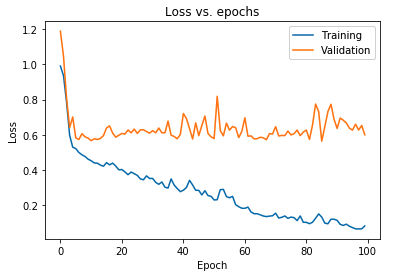
พล็อตที่แสดงด้านบนแสดงให้เห็นว่าการสูญเสียการตรวจสอบเพิ่มขึ้นอย่างต่อเนื่องหลังจาก 10 ยุคในขณะที่การสูญเสียการฝึกยังคงลดลง แนวโน้มนี้เป็นตัวอย่างในหนังสือเรียนเกี่ยวกับปัญหาที่สำคัญอย่างเหลือเชื่อในการเรียนรู้ของเครื่องซึ่งเรียกว่า การใส่ มาก เกินไป
มีการวิจัยเชิงน้ำเชื้อจำนวนมากเพื่อแก้ไขปัญหานี้ และการแก้ปัญหาเหล่านี้รวมกันเรียกว่า เทคนิคการทำให้เป็น มาตรฐาน ส่วนต่อไปนี้จะครอบคลุมแง่มุมของการทำให้เป็นมาตรฐานและขั้นตอนในการทำให้โมเดลการเรียนรู้เชิงลึกเป็นมาตรฐาน
การปรับโมเดลของเราให้เป็นมาตรฐาน
ในส่วนที่แล้ว เราสังเกตแนวโน้มการสนทนาในแผนภาพการสูญเสียของชุดการฝึกและการตรวจสอบความถูกต้อง โดยที่แผนภาพฟังก์ชันต้นทุนของชุดหลังดูเหมือนว่าจะเพิ่มขึ้น และของชุดเดิมยังคงลดลงอย่างต่อเนื่อง และด้วยเหตุนี้จึงทำให้เกิดช่องว่าง (ช่อง ว่างทั่วไป ) ดูข้อมูลเพิ่มเติมเกี่ยวกับการทำให้เป็นมาตรฐานในการเรียนรู้ของเครื่อง
ความจริงที่ว่ามีช่องว่างดังกล่าวระหว่างแผนการสูญเสียทั้งสองเป็นสัญลักษณ์ว่าแบบจำลองไม่สามารถสรุปได้ดีในชุดการตรวจสอบความถูกต้อง ( ข้อมูลที่มองไม่เห็น) และด้วยเหตุนี้มูลค่าต้นทุน/การสูญเสียที่เกิดขึ้นกับชุดข้อมูลนั้นก็จะสูงอย่างหลีกเลี่ยงไม่ได้เช่นกัน
ลักษณะเฉพาะนี้เกิดขึ้นเนื่องจากน้ำหนักและอคติของแบบจำลองที่ได้รับการฝึกอบรมได้รับการปรับร่วมกันเพื่อเรียนรู้การกระจายของข้อมูลการฝึกอบรมเป็นอย่างดี ซึ่งทำให้ไม่สามารถคาดการณ์ป้ายกำกับของคุณลักษณะใหม่และที่มองไม่เห็นซึ่งนำไปสู่การสูญเสียการตรวจสอบที่เพิ่มขึ้น
เหตุผลก็คือการกำหนดค่าแบบจำลองที่ซับซ้อนจะทำให้เกิดความผิดปกติดังกล่าว เนื่องจากพารามิเตอร์ของแบบจำลองมีความแข็งแกร่งสูงสำหรับข้อมูลการฝึกอบรม ดังนั้น การลดความซับซ้อนหรือลดขนาดความจุ/ความซับซ้อนของโมเดลจะลดผลกระทบจากการใส่มากเกินไป วิธีหนึ่งในการบรรลุเป้าหมายนี้คือการใช้ dropouts ในรูปแบบการเรียนรู้เชิงลึกซึ่งเราจะกล่าวถึงในหัวข้อถัดไป
การทำความเข้าใจและการนำ Dropouts ไปใช้ใน TensorFlow
การรับรู้หลักเบื้องหลังการใช้ dropouts คือการสุ่มดร็อปยูนิตที่ซ่อนอยู่และมองเห็นได้ เพื่อให้ได้โมเดลที่ซับซ้อนน้อยกว่า ซึ่งจำกัดพารามิเตอร์ของโมเดลไม่ให้เพิ่มขึ้น และทำให้โมเดลมีความทนทานมากขึ้นสำหรับประสิทธิภาพในชุดข้อมูลทั่วไป
แนวทางปฏิบัติที่ได้รับการยอมรับเมื่อเร็วๆ นี้เป็นแนวทางที่มีประสิทธิภาพซึ่งผู้ปฏิบัติงานแมชชีนเลิร์นนิงใช้เพื่อกระตุ้นการปรับให้สม่ำเสมอในรูปแบบการเรียนรู้เชิงลึก ดรอปเอาต์สามารถดำเนินการได้อย่างง่ายดายโดยใช้ Keras API บน TensorFlow โดยนำเข้า เลเยอร์การดรอปเอาต์และส่ง อาร์กิวเมนต์ อัตรา ในนั้นเพื่อระบุส่วนของหน่วยที่ต้องดร อป
โดยทั่วไปเลเยอร์ dropout เหล่านี้จะซ้อนกันทันทีหลังจากแต่ละ ชั้น หนาแน่น เพื่อสร้างกระแสน้ำสลับกันของ สถาปัตยกรรมเลเยอร์ ที่เลื่อนออกอย่าง หนาแน่น
เราสามารถปรับเปลี่ยนโครงข่ายประสาทเทียม feedforward ที่กำหนดไว้ก่อนหน้านี้ให้รวม 6 ชั้น dropout หนึ่งชั้นสำหรับแต่ละชั้นที่ซ่อนอยู่:


ในที่นี้ อัตราการ ออก กลางคัน _ ถูกตั้งค่าเป็น 0.2 ซึ่งหมายความว่า 20% ของโหนดจะลดลงขณะฝึกโมเดล เรารวบรวมและฝึกโมเดลด้วยเครื่องมือเพิ่มประสิทธิภาพ ฟังก์ชันการสูญเสีย ตัวชี้วัด และจำนวนยุคเดียวกันเพื่อการเปรียบเทียบที่ยุติธรรม
ผลกระทบหลักของการทำให้โมเดลเป็นมาตรฐานโดยใช้การดรอปเอาต์สามารถตีความได้โดยการพล็อตกราฟการสูญเสียของโมเดลที่ได้รับในชุดการฝึกและการตรวจสอบอีกครั้ง:
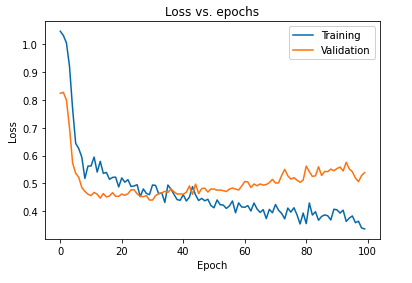
เห็นได้ชัดจากแผนภาพข้างต้นว่าช่องว่างทั่วไปที่ได้รับหลังจากการทำให้แบบจำลองเป็นมาตรฐานนั้นน้อยกว่ามาก ซึ่งทำให้แบบจำลองมีความไวต่อข้อมูลการฝึกมากเกินไปน้อยลง
อ่านเพิ่มเติม: แนวคิดโครงการการเรียนรู้เชิงลึก
บทสรุป
แง่มุมของการตรวจสอบความถูกต้องของแบบจำลองและการทำให้เป็นมาตรฐานเป็นส่วนสำคัญของการออกแบบเวิร์กโฟลว์ในการสร้างโซลูชันแมชชีนเลิร์นนิง มีการวิจัยจำนวนมากเพื่อจำลองการเรียนรู้ภายใต้การดูแล และบทช่วยสอนแบบลงมือปฏิบัตินี้จะให้ข้อมูลเชิงลึกโดยย่อเกี่ยวกับแนวทางปฏิบัติและเทคนิคที่ได้รับการยอมรับมากที่สุดในขณะที่ประกอบอัลกอริธึมการเรียนรู้ใดๆ
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับเทคนิค การ เรียนรู้เชิงลึก แมชชีนเลิร์นนิง ให้ดูใบรับรอง PG ของ IIIT-B & upGrad ในการเรียนรู้ของเครื่องและการเรียนรู้เชิงลึกซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมอย่างเข้มงวดมากกว่า 240 ชั่วโมง กรณีศึกษามากกว่า 5 กรณี & การมอบหมาย สถานะศิษย์เก่า IIIT-B & ความช่วยเหลืองานกับบริษัทชั้นนำ