
การวิเคราะห์ข้อมูลโดยใช้ Python [ทุกสิ่งที่คุณจำเป็นต้องรู้]
เผยแพร่แล้ว: 2020-09-02สำหรับใครก็ตามที่ต้องการเริ่มต้นการวิเคราะห์ข้อมูล ภาษาแรกที่นึกถึงคือ R หรือ Python และเหตุผลที่นักพัฒนาเริ่มสนใจ Python มากขึ้นก็เนื่องมาจากความสามารถในการปรับตัวที่กว้างขวางในด้านการพัฒนาซอฟต์แวร์ทั่วไป ดังนั้น การวิเคราะห์ข้อมูลโดยใช้ python จึงเป็นหนึ่งในคำศัพท์ที่ได้ยินบ่อยที่สุดสำหรับผู้ที่เริ่มต้นการเดินทางสู่ Data Science
สารบัญ
ทำไมต้องวิเคราะห์ข้อมูล?
ก่อนอื่น ทำไมต้องวิเคราะห์ข้อมูล? เป็นขั้นตอนแรกในการทราบว่าคุณกำลังใช้ข้อมูลประเภทใด เป็นขั้นตอนที่คุณพบรูปแบบอันมีค่าในข้อมูล ซึ่งคุณอาจมองไม่เห็นอย่างอื่น โดยรวมแล้ว มันให้ความเข้าใจโดยสัญชาตญาณของชุดข้อมูลในมือ
ที่นี่เราจำเป็นต้องวาดเส้นแบ่งระหว่างการวิเคราะห์ข้อมูลและการประมวลผลข้อมูลล่วงหน้า การประมวลผลข้อมูลล่วงหน้าเกี่ยวข้องกับการสร้างแบบจำลองชุดข้อมูลของคุณเพื่อให้แน่ใจว่าพร้อมสำหรับการฝึกอบรม การวิเคราะห์ข้อมูลคือการทำความเข้าใจชุดข้อมูล ซึ่งเป็นขั้นตอนเบื้องต้นสำหรับการประมวลผลข้อมูลล่วงหน้า ในการวิเคราะห์ข้อมูล เราพยายามสร้างแบบจำลองข้อมูลเพื่อดูดีขึ้น และด้วยเหตุนี้ เราจึงเรียนรู้ข้อมูลเชิงลึกเกี่ยวกับชุดข้อมูลในมือ
ทำไมต้องไพทอน?
คำถามที่สองคือ ทำไมต้อง Python เราได้กล่าวไปแล้วว่า Python เป็นภาษาที่มีการดัดแปลงอย่างกว้างขวาง ใช่ นี่ไม่ใช่ทางเลือกเดียวในการวิเคราะห์ข้อมูล แต่เป็นตัวเลือกที่ดีทีเดียว อีกเหตุผลหนึ่งคือมันถูกใช้มากขึ้น! Python นั้นใช้งานง่ายและมีชุมชนนักพัฒนาจำนวนมากที่จะช่วยคุณเกี่ยวกับ การวิเคราะห์ข้อมูลโดยใช้ python ยิ่งกว่านั้น การวิเคราะห์ข้อมูลโดยใช้ Python นั้นค่อนข้างสนุก เนื่องจากมีไลบรารีสร้างสรรค์จำนวนมากที่มีให้สำหรับการวิเคราะห์ข้อมูลและการแสดงภาพ
ใน Python ไลบรารีพื้นฐานสำหรับการวิเคราะห์ข้อมูลคือ Pandas เป็นไลบรารีระดับสูงที่สร้างขึ้นบนไลบรารี NumPy ซึ่งใช้สำหรับการคำนวณทางวิทยาศาสตร์และการวิเคราะห์เชิงตัวเลข Pandas ช่วยให้ทำงานกับข้อมูลได้ง่ายขึ้นด้วยการนำเสนอโครงสร้างข้อมูลที่เรียกว่า DataFrame DataFrame ช่วยในการอ่านและจัดเก็บชุดข้อมูลของคุณ มีฟังก์ชันพื้นฐานสำหรับการอ่านและเขียนชุดข้อมูล รวมถึงการดูเมตาดาต้าและฟังก์ชันการสืบค้นเพื่อดึงข้อมูลเชิงลึกทั้งหมดออกจากชุดข้อมูล
สิ่งสำคัญคือต้องสังเกตว่าการแสดงภาพข้อมูลเป็นส่วนสำคัญของการวิเคราะห์ข้อมูลโดยรวม เพราะไม่เพียงช่วยให้เข้าใจข้อมูลได้ดีขึ้นเท่านั้น แต่ยังรวมถึงผู้ที่คุณกำลังให้ข้อมูลเชิงลึกอีกด้วย เราจะพูดถึงสองไลบรารี่ที่ใช้มากที่สุดสำหรับการสร้างภาพข้อมูล: Matplotlib และ Seaborn Matplotlib เป็นไลบรารีพื้นฐานสำหรับการสร้างภาพข้อมูลใน Python Seaborn ถูกสร้างขึ้นบน Matplotlib ซึ่งมีฟังก์ชันการสร้างภาพข้อมูลที่สร้างสรรค์ที่สุดบางส่วน
ตั้งค่าสภาพแวดล้อม
ขั้นตอนแรกคือการตั้งค่าสภาพแวดล้อมของคุณ ในขณะที่ทำการ วิเคราะห์ข้อมูลโดยใช้ python สิ่งสำคัญคือต้องมีสภาพแวดล้อมที่เหมาะสมสำหรับการรักษางานทั้งหมดของคุณ การวิเคราะห์ข้อมูลโดยใช้ python จะไม่ใช่แค่สคริปต์ แต่จะเป็นการโต้ตอบระหว่างตัวคุณเองกับชุดข้อมูล และสำหรับสิ่งนั้น คุณจะต้องมีสถานที่ทำงานที่เหมาะสม
ใน python บริการดังกล่าวมีให้โดย Anaconda Distribution สถานที่ทำงานชั้นนำของ Anaconda คือสมุดบันทึก Jupyter แล้วทำไมต้อง Jupyter? มันช่วยให้คุณมีการแสดงภาพโดยตรงในโน้ตบุ๊กของคุณ นอกจากนี้ยังมีฟังก์ชันมหัศจรรย์บางอย่างที่ให้คุณเห็นผลลัพธ์ได้โดยตรงโดยไม่ต้องระบุตำแหน่งที่คุณต้องการอย่างชัดเจน
ไลบรารี, Pandas และ Matplotlib ได้รับการติดตั้งไว้ล่วงหน้า ดังนั้นจึงไม่มีการตั้งค่าเพิ่มเติมที่จำเป็นสำหรับการใช้งาน
นี่คือบทสรุปเกี่ยวกับวิธีการ วิเคราะห์ข้อมูลโดยใช้ Python :
- กำลังโหลดชุดข้อมูล
- การดูข้อมูลเมตาของชุดข้อมูลโดยใช้ Pandas
- การสร้างภาพข้อมูลโดยใช้ Matplotlib
- การรวบรวมข้อมูลเชิงลึกเกี่ยวกับข้อมูล
นำเข้าไลบรารีที่จำเป็น
ก่อนที่เราจะเริ่มดูโค้ดสำหรับขั้นตอนต่างๆ เพียงนำเข้าไลบรารีที่จำเป็นด้วยแท็กหลอก เช่นเดียวกับชื่อที่เราจะเรียกมันสำหรับโปรแกรมทั้งหมด
นำเข้า numpy เป็น np
นำเข้า แพนด้า เป็น pd
#สำหรับการแสดงข้อมูล
นำเข้า matplotlib.pyplot เป็น plt
นำเข้า seaborn เป็น sns
ตอนนี้เราจะดูแต่ละขั้นตอนและหารือเกี่ยวกับฟังก์ชันที่พร้อมใช้งานและวิธีใช้งาน
ขั้นแรกให้อ่านชุดข้อมูล Pandas มีฟังก์ชันพื้นฐานสำหรับการโหลดชุดข้อมูลลงในโครงสร้างข้อมูลหลัก: DataFrame เราสามารถใช้งานได้ดังนี้
data_df = pd.read_csv('heart.csv')
ผลลัพธ์ของฟังก์ชันการอ่านจะเป็น DataFrame นอกจากโปรแกรมอ่าน CSV แล้ว แพนด้ายังให้ข้อมูลเกือบทุกประเภทแก่ผู้อ่าน จาก HTML เป็น JSON และ excel
นอกจากนี้ หากคุณไม่มีข้อมูลใดๆ และต้องการสร้างชุดข้อมูล คุณสามารถใช้ฟังก์ชันอ็อบเจ็กต์ Series และ DataFrame ของ Pandas ได้อย่างง่ายดาย
ดังนั้น เมื่อคุณมีข้อมูลในมือแล้ว ให้เราไปดูว่าข้อมูลนั้นเกี่ยวกับอะไร ในการรับมุมมองข้อมูลครั้งแรก คุณสามารถใช้ฟังก์ชันเช่น df.info หรือ df.describe เพื่อทราบโครงสร้างของชุดข้อมูลของคุณ
data_df.info()
data_df.describe()
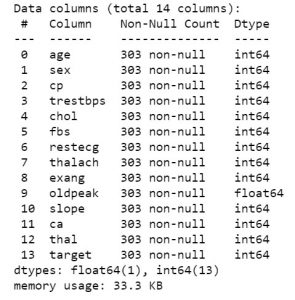
เมื่อคุณรู้ว่าชุดข้อมูลของคุณมีคุณลักษณะใดบ้าง คุณอาจต้องการดูค่าของคุณสมบัติเหล่านั้น คุณสามารถใช้ฟังก์ชัน df.head() เพื่อรับ 5 ตัวอย่างแรก
data_df.head()
#หรือ
data_df.head(3)
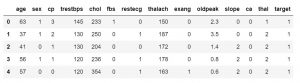
คุณยังสามารถระบุจำนวนตัวอย่างเพื่อแทนที่ค่าเริ่มต้นที่ 5 คุณยังสามารถใช้ฟังก์ชัน df.tail() เพื่อรับค่า 5 สุดท้ายของชุดข้อมูล
data_df.tail()
นี่เป็นเพียงเพื่อให้ได้ภาพรวมระดับสูงว่าข้อมูลของคุณจะเป็นอย่างไร เมื่อพร้อมแล้ว คุณสามารถเริ่มงานการสร้างภาพข้อมูลหลักได้โดยใช้ Matplotlib ป้อนโค้ดต่อไปนี้เพื่อทำให้การพล็อตเป็นแบบโต้ตอบและดูแบบเดียวกันในโน้ตบุ๊กของคุณเอง
%matplotlib แบบอินไลน์
เราจะเห็นฟังก์ชันการทำงานของการสร้างภาพข้อมูล 5 อันดับแรกใน matplotlib ก่อนจะพูดถึงเรื่องนี้ เราควรรู้จักหน้าที่อื่นๆ ที่ควบคุมแผนการของเราเสียก่อน ฟังก์ชั่นเช่น:
- ป้ายกำกับ: xlabel(), ylabel() ใช้สำหรับป้ายกำกับแกน x และแกน y
- ตำนาน: ใช้สำหรับสร้างตำนานสำหรับโครงเรื่อง
- ชื่อเรื่อง: การกำหนดชื่อเรื่องสำหรับโครงเรื่องของคุณ
- และสุดท้าย แสดงฟังก์ชันเพื่อดูโครงเรื่อง
ชำระเงิน: เงินเดือนนักวิเคราะห์ข้อมูลในอินเดีย
การสร้างภาพ
ให้เราดูการแสดงภาพตอนนี้ เราจะเริ่มด้วยโครงเรื่องพื้นฐาน plt.plot() ใช้เพื่อสร้างพล็อตเส้นอย่างง่ายสำหรับข้อมูลของคุณ ฟังก์ชันนี้ต้องใช้พารามิเตอร์สองตัวในการบังคับ ซึ่งเป็นข้อมูลแกน x และข้อมูลแกน y คุณอาจระบุรูปแบบและชื่อและสีของโครงเรื่องก็ได้ นี่คือลักษณะที่ปรากฏในโค้ด
plt.plot(data_df['chol'])
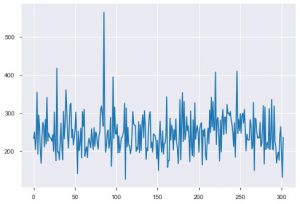
พล็อตที่สองคือฮิสโตแกรม ฮิสโตแกรมช่วยให้คุณดูความถี่หรือการกระจายของคุณลักษณะเฉพาะ ช่วยให้คุณเห็นว่าปริมาณมีความสัมพันธ์กันอย่างไร Plt.hist() เป็นฟังก์ชันพื้นฐานในการสร้างฮิสโตแกรมบนข้อมูลของคุณ คุณสามารถระบุพารามิเตอร์ bins เพื่อควบคุมตัวเลขบนโครงเรื่องได้ คุณต้องส่งข้อมูลแกนเดียวถ้าคุณต้องการการวิเคราะห์แบบไม่มีตัวแปร
plt.hist(data_df['age'])
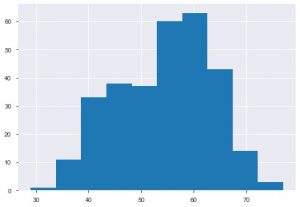

อีกแปลงที่คุณเห็นมากคือพล็อตบาร์ ช่วยในการวิเคราะห์และเปรียบเทียบคุณสมบัติต่างๆ กราฟแท่งจะใช้สำหรับการทำงานกับข้อมูลที่เป็นหมวดหมู่ต่างจากฮิสโตแกรม
คุณสามารถใช้พล็อตบน DataFrame โดยตรง หรือคุณสามารถระบุพารามิเตอร์ภายในฟังก์ชัน plt.bar() นี่คือวิธีที่เราใช้
df = pd.DataFrame(np.random.rand(15, 5), columns=['t1', 't2', 't3', 't4', 't5'])
df.plot.bar()
คุณยังสามารถใช้พล็อตแท่งในแนวนอนโดยใช้ฟังก์ชัน barh()
กราฟเชิงลึกอีกประการหนึ่งคือบ็อกซ์พล็อต ช่วยในการทำความเข้าใจการกระจายของค่าในแต่ละคุณลักษณะ คุณสามารถใช้ฟังก์ชัน plt.boxplot() เพื่อระบุข้อมูลที่คุณต้องการสร้าง boxplot พล็อตมีประโยชน์อย่างยิ่งเมื่อคุณต้องการดูการกระจายในชุดข้อมูลหรือความเบ้อย่างรวดเร็ว นี่คือวิธีที่คุณสามารถใช้
plt.boxplot(data_df['chol'])
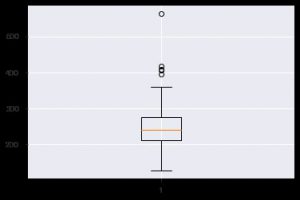
เมื่อใดก็ตามที่คุณทำงานกับข้อมูลทางสถิติ คุณจะเห็นพล็อตแบบกระจายแน่นอน พล็อตกระจายช่วยในการสังเกตความสัมพันธ์ระหว่างสองคุณลักษณะ พล็อตต้องใช้ค่าตัวเลขสำหรับทั้งข้อมูลแกน x และแกน y คุณสามารถระบุค่าสองค่าดังกล่าวในฟังก์ชัน plt.scatter() หรือนำไปใช้กับ DataFrame ได้โดยตรงโดยระบุชื่อคอลัมน์ในแอตทริบิวต์ x และ y นี่คือวิธีที่คุณสามารถใช้:
plt.scatter(data_df['age'], data_df['chol'])
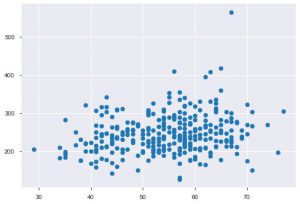
ตอนนี้เป็นเวลาที่เหมาะสมที่จะแนะนำคุณให้รู้จักกับฟังก์ชันของ Seaborn พล็อตแบบกระจายในทะเลมีสัญชาตญาณมากกว่า matplotlib เพราะมันยังให้เส้นการถดถอยในพล็อตโดยค่าเริ่มต้น เพื่อให้เห็นภาพพล็อตได้ดีขึ้น คุณสามารถใช้ฟังก์ชัน sns.lmplot() เพื่อสร้างพล็อตนั้นได้
sns.lmplot('อายุ', 'chol', data=data_df)
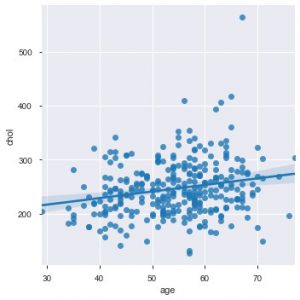
ดังที่คุณเห็นในแผนภาพด้านบน เส้นการถดถอยช่วยให้เข้าใจการกระจายได้ดียิ่งขึ้น
การปรับปรุงอีกประการหนึ่งโดยใช้ซีบอร์นคือพล็อตเรื่องฝูง มันถูกใช้เพื่อวาดพล็อตกระจายอย่างเด็ดขาด ข้อดีอย่างหนึ่งของแผนผังกลุ่มเหนือแผนภาพแถบที่คล้ายกันคือใช้เฉพาะจุดที่ไม่ทับซ้อนกันเท่านั้น ดังนั้นจึงเป็นพล็อตที่สะอาดกว่าและให้ข้อมูลเชิงลึกที่ดีขึ้น
sns.swarmplot(data_df['age'], data_df['chol'])
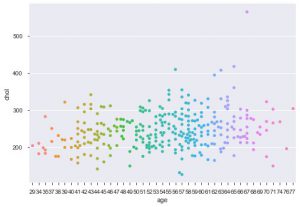
ดังนั้นนี่คือแปลงประเภทต่างๆ ใน Matplotlib และ Seaborn นี่เป็นเพียงส่วนเล็กสุดของภูเขาน้ำแข็ง และมีวิธีอื่นๆ อีกหลายร้อยวิธีในการวางแผนข้อมูลของคุณเพื่อดึงข้อมูลเชิงลึกที่สร้างสรรค์เกี่ยวกับเรื่องนี้
เมื่อคุณทราบแผนผังแล้ว ให้เรามาดูวิธีวิเคราะห์ข้อมูลจริง โดย ใช้ python เราจะดูพล็อตเพิ่มเติมและดูสิ่งที่พวกเขาแสดงให้เราเห็นเกี่ยวกับ การวิเคราะห์ข้อมูลโดยใช้ python
เริ่มกันเลย.
หลังจากโหลดข้อมูล สิ่งแรกที่นักวิเคราะห์ข้อมูลทำในตอนนี้คือสร้างโปรไฟล์แพนด้า ตอนนี้สามารถดูเป็นทางลัดได้ แต่ถ้าคุณต้องการดูความสัมพันธ์และการนับและฮิสโตแกรมทั้งหมดของตัวแปรในชุดข้อมูล คุณสามารถใช้การทำโปรไฟล์แพนด้าได้ สร้างได้ง่ายมาก เพียงดาวน์โหลดโมดูล pandas-profiling แล้วเจาะโค้ดต่อไปนี้:
นำเข้า pandas_profiling
โปรไฟล์ = pandas_profiling.ProfileReport(data_df)
ข้อมูลส่วนตัว
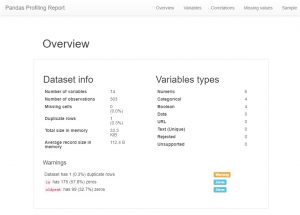
อย่างที่คุณเห็น มีข้อมูลเมตาดาต้าจำนวนมากและข้อมูลคุณลักษณะส่วนบุคคล สิ่งเหล่านี้อาจนำไปสู่ความเข้าใจที่ดี
สิ่งที่สองที่เราสามารถทำได้คือสร้างแผนที่ความหนาแน่น สิ่งที่แผนที่ความหนาแน่นทำคือ มันแสดงให้เห็นความสัมพันธ์ของแต่ละจุดสนใจกับอีกจุดหนึ่ง และหากเราพบค่าที่มีความสัมพันธ์กันสูงกว่า แสดงว่าคุณลักษณะทั้งสองมีความคล้ายคลึงกันอย่างใกล้ชิด ดังนั้น เราสามารถทิ้งคุณสมบัติอย่างใดอย่างหนึ่ง และถึงกระนั้น โมเดลก็จะทำงานได้ดี
sns.heatmap(data_df.corr(), annot = True , cmap='Oranges')
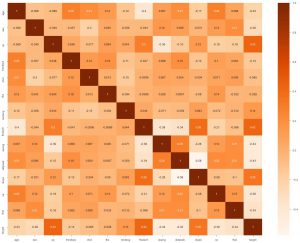
ในที่นี้เราจะเห็นว่าไม่มีสิ่งใดที่เกี่ยวข้องกันมาก ดังนั้นเราจึงสามารถบอกวิศวกรแบบจำลองว่าเราต้องการคุณลักษณะทั้งหมดเป็นข้อมูลป้อนเข้า
เราสามารถดูการแจกแจงอายุได้เนื่องจากเรากำลังรับมือกับชุดข้อมูลโรคหัวใจ มาดูการแจกแจงกัน เพื่อที่เราจะสามารถใช้ distplot ของ seaborn ได้
sns.distplot(data_df['age'], color = 'cyan')
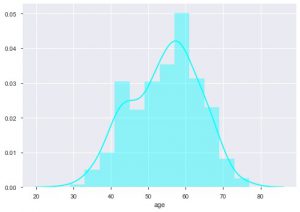
จากเนื้อเรื่อง คุณสามารถพูดได้ว่าคนส่วนใหญ่ที่เป็นโรคหัวใจมีอายุระหว่าง 50 ถึง 60 ปี ในทำนองเดียวกัน เรายังสามารถดูคุณสมบัติที่สำคัญอื่นๆ เช่น ความดันโลหิตขณะพัก ซึ่งแสดงโดย tresbps เราสามารถสร้างกล่องพล็อตเพื่อดูการแจกแจง โดยเปรียบเทียบกับค่าเป้าหมาย คือ 0 และ 1
sns.boxplot(data_df['target'], data_df['trestbps'], จานสี = 'twilight')
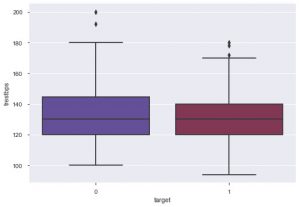
เราสามารถสรุปได้จากโครงเรื่องว่าถ้าบุคคลนั้นมี tres bps ต่ำกว่า โอกาสที่พวกเขาจะเป็นโรคหัวใจจะต่ำกว่าผู้ที่มีค่า tres bps สูงกว่า
ในทำนองเดียวกัน เราสามารถเห็นความสัมพันธ์กับระดับคอเลสเตอรอล เราเห็นคนที่มีระดับคอเลสเตอรอลน้อยกว่ามีโอกาสเป็นโรคหัวใจน้อยลง
คุณสามารถบันทึกข้อมูลเชิงลึกทั้งหมดเหล่านี้และมอบให้วิศวกรแมชชีนเลิร์นนิงซึ่งสามารถใช้ข้อมูลเดียวกันนี้เพื่อสร้างแบบจำลองที่มีประสิทธิภาพได้
บทสรุป
นี่คือวิธีที่คุณสามารถ วิเคราะห์ข้อมูลโดยใช้ python นี่เป็นเพียงก้าวแรกในการเดินทางของวิทยาศาสตร์ข้อมูล หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการดึงข้อมูลเชิงลึกที่สร้างสรรค์จากข้อมูลและวิทยาศาสตร์ข้อมูลโดยรวม ให้ไปที่หลักสูตรที่เปิดสอนโดย upGrad ที่ นี่ คุณจะพบกับหลักสูตรที่เป็นประโยชน์มากมาย ซึ่งจะแนะนำการวิเคราะห์ข้อมูลอย่างมีประสิทธิภาพโดยใช้ python
เรียนรู้ หลักสูตรวิทยาศาสตร์ข้อมูล จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม PG สำหรับผู้บริหาร โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
ฉันจะเรียนรู้ Python สำหรับ Data Analysis ได้อย่างไร
หากคุณอยู่บนเส้นทางสู่การเรียนรู้ Python สำหรับ Data Analysis แสดงว่าคุณมาถูกที่แล้ว คุณต้องมีวิธีการทีละขั้นตอนเพื่อทำให้กระบวนการเรียนรู้ง่ายขึ้นสำหรับทุกสิ่ง นี่คือลักษณะของกระบวนการ:
1. ทำความเข้าใจกับจุดประสงค์ของการเรียนรู้ Python ให้ชัดเจนและคุณจะใช้งาน Python ได้อย่างไรในสาขาของคุณ
2. ดาวน์โหลดเทอร์มินัล Python ที่จำเป็นและติดตั้งในระบบของคุณ
3. เริ่มเรียนรู้พื้นฐานของ Python ด้วยการเรียนหลักสูตรต่างๆ และทำความรู้จักกับไลบรารี Python ต่างๆ
4.ทำความคุ้นเคยกับนิพจน์ทั่วไปที่ใช้ใน Python
5. ไปหาความรู้เชิงลึกเกี่ยวกับไลบรารี Python ต่างๆ เช่น Pandas, NumPy, Matplotlib และ SciPy
6. เริ่มเรียนรู้แนวคิดการวิเคราะห์ข้อมูลและวิธีรวม Python เข้ากับมัน
7. ตอนนี้ คุณเพียงแค่ต้องฝึกฝนเครื่องมือและเทคนิคต่างๆ ต่อไปเพื่อพัฒนา Python สำหรับ Data Analysis ให้ดีขึ้น เมื่อทำตามขั้นตอนทีละขั้นตอนนี้ คุณจะพบว่าการเรียนรู้ Python เป็นเรื่องง่ายและทำงานได้ดีขึ้นสำหรับการทำงานกับ Data Analysis
Python ใช้สำหรับการวิเคราะห์ข้อมูลอย่างไร
เป็นที่ทราบกันดีว่า Python เป็นแหล่งข้อมูลที่สำคัญมากสำหรับการวิเคราะห์ข้อมูล Python ช่วยในการวิเคราะห์ข้อมูลในรูปแบบต่างๆ แต่ก่อนหน้านั้น คุณต้องเตรียมข้อมูลสำหรับการวิเคราะห์ ทำการวิเคราะห์ทางสถิติ สร้างการแสดงภาพข้อมูลที่สามารถให้ข้อมูลเชิงลึก คาดการณ์แนวโน้มในอนาคตตามข้อมูลที่มีอยู่ และอื่นๆ อีกมากมาย
พบว่า Python เป็นองค์ประกอบสำคัญของการวิเคราะห์ข้อมูล เนื่องจากช่วยในการ:
1. การนำเข้าชุดข้อมูล
2.ทำความสะอาดและเตรียมข้อมูลเพื่อทำการวิเคราะห์
3. จัดการกับ Pandas DataFrame
4. สรุปชุดข้อมูล
5. การพัฒนาโมเดล Machine Learning สำหรับการวิเคราะห์ข้อมูลด้วย Python
ฉันสามารถเรียนรู้ Python ในหนึ่งเดือนได้หรือไม่
ใช่ คุณสามารถทำให้สิ่งนี้เกิดขึ้นได้หากคุณเชี่ยวชาญในภาษาการเขียนโปรแกรมอื่นๆ เช่น Java, C, C++ เป็นต้น หากพื้นฐานของคุณชัดเจน คุณจะพบว่าการเรียนรู้ Python เป็นเรื่องง่ายแม้ในหนึ่งเดือน นอกจากนั้น หากคุณใช้ความพยายามและปฏิบัติตามแนวทางทีละขั้นตอนอย่างมีระเบียบวินัย คุณสามารถเรียนรู้ Python ได้ภายในหนึ่งเดือน แม้ว่าคุณจะไม่มีความรู้เกี่ยวกับภาษาโปรแกรมอื่นๆ มาก่อน คุณเพียงแค่ต้องกำหนดตารางเวลาและทุ่มเทให้กับการเรียนรู้ Python ในหนึ่งเดือน