
ไปและท้าทายปัญญาประดิษฐ์ทั่วไป
เผยแพร่แล้ว: 2018-02-15บทความนี้มีจุดมุ่งหมายเพื่อสำรวจความเชื่อมโยงระหว่างเกม 'Go' กับปัญญาประดิษฐ์ วัตถุประสงค์คือการตอบคำถาม – อะไรทำให้เกม Go พิเศษ? เหตุใดการควบคุมเกม Go จึงยากสำหรับคอมพิวเตอร์ เหตุใดโปรแกรมคอมพิวเตอร์จึงสามารถเอาชนะปรมาจารย์หมากรุกในปี 1997 ได้? เหตุใดจึงใช้เวลาเกือบสองทศวรรษในการถอดรหัส Go?
“สุภาพบุรุษไม่ควรเสียเวลากับเกมเล็กๆ น้อยๆ พวกเขาควรศึกษาโก”
– ขงจื๊อ
อันที่จริง ผู้เชี่ยวชาญด้านปัญญาประดิษฐ์คิดว่าคอมพิวเตอร์จะสามารถเอาชนะแชมป์โลก Go ได้ภายในปี 2570 ต้องขอบคุณ DeepMind บริษัทปัญญาประดิษฐ์ภายใต้การดูแลของ Google งานที่น่าเกรงขามนี้ประสบความสำเร็จเมื่อสิบปีก่อน บทความนี้จะพูดถึงเทคโนโลยีที่ DeepMind ใช้เพื่อเอาชนะแชมป์ Go Go ของโลก สุดท้ายนี้ โพสต์นี้จะกล่าวถึงวิธีที่เทคโนโลยีนี้สามารถใช้เพื่อแก้ไขปัญหาที่ซับซ้อนในโลกแห่งความเป็นจริง
สารบัญ
ไป - มันคืออะไร?
Go เป็นเกมกระดานกลยุทธ์ของจีนที่มีอายุกว่า 3,000 ปี ซึ่งยังคงได้รับความนิยมมาโดยตลอด มีผู้เล่นหลายสิบล้านคนทั่วโลก Go เป็นเกมกระดานสำหรับผู้เล่นสองคนที่มีกฎง่ายๆ และกลยุทธ์ที่ใช้งานง่าย ขนาดกระดานที่แตกต่างกันใช้สำหรับเล่นเกมนี้ ผู้เชี่ยวชาญใช้กระดาน 19×19

เกมเริ่มต้นด้วยกระดานเปล่า จากนั้นผู้เล่นแต่ละคนผลัดกันวางหินขาวดำ (สีดำมาก่อน) บนกระดานที่จุดตัดของเส้น (ต่างจากหมากรุกที่คุณวางชิ้นส่วนในช่องสี่เหลี่ยม) ผู้เล่นสามารถจับก้อนหินของฝ่ายตรงข้ามโดยล้อมรอบมันจากทุกด้าน สำหรับหินที่จับได้แต่ละก้อน ผู้เล่นจะได้รับคะแนนบางส่วน วัตถุประสงค์ของเกมคือการครอบครองอาณาเขตสูงสุดบนกระดานพร้อมกับจับก้อนหินของฝ่ายตรงข้าม
Go เป็นเรื่องเกี่ยวกับการสร้างซึ่งแตกต่างจาก Chess ซึ่งเกี่ยวกับการทำลายล้าง Go ต้องการอิสระ ความคิดสร้างสรรค์ สัญชาตญาณ ความสมดุล กลยุทธ์ และความรอบรู้ในการเล่นเกม การเล่นโกะเกี่ยวข้องกับสมองทั้งสองข้าง อันที่จริงการสแกนสมองของผู้เล่น Go เปิดเผยว่า Go ช่วยในการพัฒนาสมองโดยการปรับปรุงการเชื่อมต่อระหว่างซีกโลกทั้งสอง
Neural Networks for Dummies: คู่มือที่ครอบคลุม
ไปและท้าทายปัญญาประดิษฐ์ (AI)
คอมพิวเตอร์สามารถใช้ Tic-Tac-Toe ได้ ใน ปี 1952 Deep Blue สามารถเอาชนะ Garry Kasparov ปรมาจารย์ หมากรุก ได้ ใน ปี 1997 โปรแกรมคอมพิวเตอร์สามารถเอาชนะแชมป์โลกใน Jeopardy (เกมยอดนิยมของอเมริกา) ใน ปี 2544 . AlphaGo ของ DeepMind สามารถเอาชนะแชมป์โลก Go ได้ ใน ปี 2559 เหตุใดจึงถือว่าท้าทายสำหรับโปรแกรมคอมพิวเตอร์ในการควบคุมเกม Go
หมากรุกเล่นบนกระดาน 8 × 8 ในขณะที่ Go ใช้กระดานขนาด 19 × 19 ในการเปิดเกมหมากรุก ผู้เล่นจะมีท่าที่เป็นไปได้ 20 ท่า ในการเปิด Go ผู้เล่นสามารถมี 361 ท่าที่เป็นไปได้ จำนวนตำแหน่งกระดาน Go ที่เป็นไปได้เท่ากับ 10 ยกกำลัง 170; มากกว่าจำนวนอะตอมในจักรวาลของเรา! จำนวนตำแหน่งกระดานที่เป็นไปได้ทำให้ Go googol ครั้ง (10 ยกกำลัง 100) ซับซ้อนกว่าหมากรุก
ในหมากรุก ในแต่ละขั้นตอน ผู้เล่นต้องเผชิญกับทางเลือก 35 ท่า โดยเฉลี่ยแล้ว ผู้เล่น Go จะสามารถเคลื่อนที่ได้ 250 ครั้งในแต่ละขั้นตอน ในหมากรุก ในตำแหน่งใดก็ตาม มันค่อนข้างง่ายสำหรับคอมพิวเตอร์ในการค้นหากำลังเดรัจฉานและเลือกท่าที่ดีที่สุดเท่าที่จะเป็นไปได้ซึ่งเพิ่มโอกาสในการชนะ การค้นหากำลังเดรัจฉานเป็นไปไม่ได้ในกรณีของ Go เนื่องจากจำนวนการเคลื่อนไหวทางกฎหมายที่เป็นไปได้ที่อนุญาตสำหรับแต่ละขั้นตอนนั้นมหาศาล
สำหรับคอมพิวเตอร์ที่จะเชี่ยวชาญหมากรุก มันจะง่ายขึ้นในขณะที่เกมดำเนินไปเพราะชิ้นส่วนต่างๆ จะถูกลบออกจากกระดาน ใน Go โปรแกรมคอมพิวเตอร์จะยากขึ้นเนื่องจากมีการเพิ่มหินลงในกระดานเมื่อเกมดำเนินไป โดยปกติ เกม Go จะยาวนานกว่าเกมหมากรุก 3 เท่า
ด้วยเหตุผลทั้งหมดนี้ โปรแกรม Go สำหรับคอมพิวเตอร์อันดับต้นๆ จึงสามารถไล่ตามแชมป์โลก Go ได้ในปี 2016 เท่านั้น หลังจากเกิดการระเบิดครั้งใหญ่ของเทคนิคการเรียนรู้ด้วยเครื่องใหม่ นักวิทยาศาสตร์ที่ทำงานที่ DeepMind สามารถสร้างโปรแกรมคอมพิวเตอร์ชื่อ AlphaGo ซึ่งเอาชนะ Lee Seedol แชมป์โลก ได้ การบรรลุภารกิจไม่ใช่เรื่องง่าย นักวิจัยที่ DeepMind ได้คิดค้นนวัตกรรมใหม่ๆ มากมายในกระบวนการสร้าง AlphaGo
“กฎของ Go นั้นงดงาม เป็นธรรมชาติ และมีเหตุผลอย่างเข้มงวดว่าถ้ารูปแบบชีวิตที่ชาญฉลาดมีอยู่ที่อื่นในจักรวาล พวกมันเกือบจะเล่น Go อย่างแน่นอน”
– เอ็ดเวิร์ด ลาสการ์
Neural Networks: แอปพลิเคชั่นในโลกแห่งความจริง
AlphaGo ทำงานอย่างไร
AlphaGo เป็นอัลกอริธึมสำหรับใช้งานทั่วไป ซึ่งหมายความว่าสามารถใช้เพื่อแก้ปัญหาอื่นๆ ได้เช่นกัน ตัวอย่างเช่น Deep Blue จาก IBM ได้รับการออกแบบมาโดยเฉพาะสำหรับการเล่นหมากรุก กฎของหมากรุกร่วมกับความรู้ที่สั่งสมมาหลายศตวรรษของการเล่นเกมนั้นถูกตั้งโปรแกรมไว้ในสมองของโปรแกรม ไม่สามารถใช้ Deep Blue ได้แม้กระทั่งการเล่นเกมเล็กๆ น้อยๆ เช่น Tic-Tac-Toe มันทำได้เพียงสิ่งเดียวเท่านั้น ซึ่งมันเก่งมาก นั่นคือ เล่นหมากรุก AlphaGo สามารถเรียนรู้การเล่นเกมอื่นๆ ได้ ยกเว้น Go อัลกอริธึมวัตถุประสงค์ทั่วไปเหล่านี้เป็นสาขาใหม่ของการวิจัยที่เรียกว่าปัญญาประดิษฐ์ทั่วไป
AlphaGo ใช้วิธีล้ำสมัย – Deep Neural Networks (DNN), Reinforcement Learning (RL), Monte Carlo Tree Search (MCTS), Deep Q Networks (DQN) (เทคนิคใหม่ที่ได้รับการแนะนำและเผยแพร่โดย DeepMind ซึ่งรวมเอาประสาท เครือข่ายที่มีการเสริมกำลังการเรียนรู้) เป็นต้น จากนั้นจึงรวมวิธีการทั้งหมดเหล่านี้เข้าด้วยกันอย่างสร้างสรรค์เพื่อให้ได้มาซึ่งความเชี่ยวชาญระดับยอดมนุษย์ในเกมโก
อันดับแรก มาดูแต่ละชิ้นส่วนของจิ๊กซอว์นี้ก่อนที่จะพิจารณาว่าชิ้นส่วนเหล่านี้เชื่อมโยงกันอย่างไรเพื่อให้งานสำเร็จลุล่วง
โครงข่ายประสาทลึก
DNN เป็นเทคนิคในการเรียนรู้ของเครื่อง โดยได้รับแรงบันดาลใจจากการทำงานของสมองมนุษย์ สถาปัตยกรรมของ DNN ประกอบด้วยชั้นของเซลล์ประสาท DNN สามารถจดจำรูปแบบในข้อมูลได้โดยไม่ต้องตั้งโปรแกรมไว้อย่างชัดเจน
มันจับคู่อินพุตกับเอาต์พุตโดยไม่มีใครตั้งโปรแกรมให้เหมือนกัน ตัวอย่างเช่น สมมติว่าเราได้ป้อนเครือข่ายด้วยภาพถ่ายแมวและสุนัขจำนวนมาก ในขณะเดียวกัน เรายังฝึกระบบด้วยการบอก (ในรูปแบบฉลาก) ว่าภาพใดภาพหนึ่งเป็นแมวหรือสุนัข (เรียกว่าการเรียนรู้ภายใต้การดูแล) DNN จะเรียนรู้ที่จะจดจำรูปแบบจากภาพถ่ายเพื่อแยกความแตกต่างระหว่างแมวกับสุนัขได้สำเร็จ วัตถุประสงค์หลักของการฝึกคือเมื่อ DNN เห็นภาพใหม่ของสุนัขหรือแมว ควรจะจำแนกประเภทได้อย่างถูกต้อง กล่าวคือ ทำนายว่านี่คือแมวหรือสุนัข
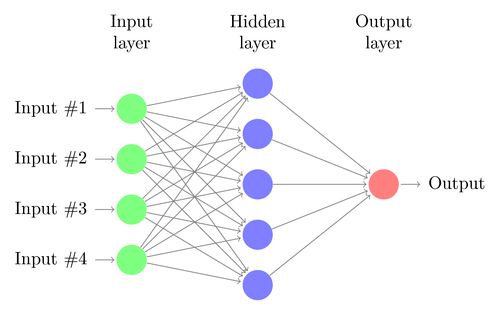
ให้เราเข้าใจสถาปัตยกรรมของ DNN อย่างง่าย จำนวนเซลล์ประสาทในเลเยอร์อินพุตสอดคล้องกับขนาดของอินพุต สมมติว่าภาพถ่ายแมวและสุนัขของเราเป็นภาพขนาด 28×28 แต่ละแถวและคอลัมน์จะประกอบด้วย 28 พิกเซลแต่ละภาพ ซึ่งทำให้แต่ละภาพมีทั้งหมด 784 พิกเซล ในกรณีเช่นนี้ เลเยอร์อินพุตจะประกอบด้วยเซลล์ประสาท 784 เซลล์ หนึ่งเซลล์สำหรับแต่ละพิกเซล จำนวนเซลล์ประสาทในเลเยอร์เอาต์พุตจะขึ้นอยู่กับจำนวนคลาสที่ต้องการจัดประเภทเอาต์พุต ในกรณีนี้ เลเยอร์เอาต์พุตจะประกอบด้วยเซลล์ประสาทสองเซลล์ เซลล์หนึ่งตรงกับ "แมว" และอีกเซลล์หนึ่งคือ "สุนัข"
จับตาดูสิ่งที่ยิ่งใหญ่ต่อไป: การเรียนรู้ของเครื่อง
จะมีเซลล์ประสาทหลายชั้นอยู่ระหว่างชั้นอินพุตและเอาต์พุต (ซึ่งเป็นที่มาของการใช้คำว่า 'ลึก' ใน 'โครงข่ายประสาทลึก') สิ่งเหล่านี้เรียกว่า "เลเยอร์ที่ซ่อนอยู่" จำนวนเลเยอร์ที่ซ่อนอยู่และจำนวนเซลล์ประสาทในแต่ละเลเยอร์ไม่คงที่ อันที่จริง การเปลี่ยนแปลงค่าเหล่านี้เป็นสิ่งที่นำไปสู่การเพิ่มประสิทธิภาพการทำงานอย่างแท้จริง ค่าเหล่านี้เรียกว่าไฮเปอร์พารามิเตอร์ และต้องปรับตามปัญหาที่มีอยู่ การทดลองรอบๆ โครงข่ายประสาทเทียมส่วนใหญ่เกี่ยวข้องกับการค้นหาจำนวนไฮเปอร์พารามิเตอร์ที่เหมาะสมที่สุด
ขั้นตอนการฝึกอบรมของ DNN จะประกอบด้วยการส่งต่อและการส่งต่อ ขั้นแรก การเชื่อมต่อทั้งหมดระหว่างเซลล์ประสาทจะเริ่มต้นด้วยน้ำหนักแบบสุ่ม ในระหว่างการส่งต่อ เครือข่ายจะถูกป้อนด้วยภาพเดียว อินพุต (ข้อมูลพิกเซลจากภาพ) ถูกรวมเข้ากับพารามิเตอร์ของเครือข่าย (น้ำหนัก ความเอนเอียง และฟังก์ชันการเปิดใช้งาน) และส่งต่อฟีดผ่านเลเยอร์ที่ซ่อนอยู่ ไปจนถึงเอาต์พุต ซึ่งส่งคืนความน่าจะเป็นของภาพถ่ายที่เป็นของแต่ละคน ของชั้นเรียน
จากนั้น ความน่าจะเป็นนี้จะถูกเปรียบเทียบกับป้ายกำกับคลาสจริง และคำนวณ "ข้อผิดพลาด" ณ จุดนี้ มีการดำเนินการย้อนกลับ - ข้อมูลข้อผิดพลาดนี้จะถูกส่งกลับผ่านเครือข่ายโดยใช้เทคนิคที่เรียกว่า "back-propagation" ในช่วงเริ่มต้นของการฝึก ข้อผิดพลาดนี้จะสูง และกลไกการฝึกที่ดีจะค่อยๆ ลดข้อผิดพลาดนี้ลง
DNN ได้รับการฝึกฝนในลักษณะนี้ด้วยการส่งต่อและถอยหลังจนกว่าตุ้มน้ำหนักจะหยุดเปลี่ยนแปลง (เรียกว่าการบรรจบกัน) จากนั้น DNN จะสามารถทำนายและจำแนกรูปภาพได้อย่างแม่นยำในระดับสูง เช่น รูปภาพนั้นมีแมวหรือสุนัข

การวิจัยทำให้เรามีสถาปัตยกรรมเครือข่าย Deep Neural ที่แตกต่างกันมากมาย สำหรับปัญหา Computer Vision (เช่น ปัญหาเกี่ยวกับภาพ) Convolution Neural Networks (CNNs) มักจะให้ผลลัพธ์ที่ดี สำหรับปัญหาที่เกี่ยวข้องกับลำดับ – การรู้จำคำพูดหรือการแปลภาษา – Recurrent Neural Networks (RNN) ให้ผลลัพธ์ที่ยอดเยี่ยม
คู่มือสำหรับผู้เริ่มต้นเพื่อทำความเข้าใจภาษาธรรมชาติ
ในกรณีของ AlphaGo กระบวนการมีดังนี้: ขั้นแรก Convolution Neural Network (CNN) ได้รับการฝึกอบรมเกี่ยวกับภาพตำแหน่งบอร์ดหลายล้านภาพ ถัดไป เครือข่ายได้รับแจ้งเกี่ยวกับการเคลื่อนไหวที่ตามมาของผู้เชี่ยวชาญที่เป็นมนุษย์ในแต่ละกรณีในระหว่างขั้นตอนการฝึกอบรมของเครือข่าย ในลักษณะเดียวกับที่กล่าวไว้ก่อนหน้านี้ ค่าจริงถูกเปรียบเทียบกับผลลัพธ์ และพบตัววัด "ข้อผิดพลาด" บางประเภท
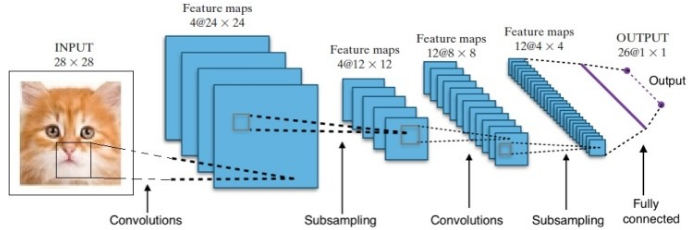
ในตอนท้ายของการฝึกอบรม DNN จะแสดงการเคลื่อนไหวต่อไปพร้อมกับความน่าจะเป็นที่ผู้เล่นที่เชี่ยวชาญซึ่งมีแนวโน้มว่าจะเล่น เครือข่ายประเภทนี้สามารถเกิดขึ้นได้เฉพาะขั้นตอนที่เล่นโดยผู้เล่นผู้เชี่ยวชาญที่เป็นมนุษย์ DeepMind สามารถบรรลุความแม่นยำ 60% ในการทำนายการเคลื่อนไหวที่มนุษย์จะทำ อย่างไรก็ตาม การจะเอาชนะผู้เชี่ยวชาญที่เป็นมนุษย์ของ Go นั้นไม่เพียงพอ ผลลัพธ์จาก DNN จะถูกประมวลผลเพิ่มเติมโดย Deep Reinforcement Network ซึ่งเป็นแนวทางที่ DeepMind คิดขึ้น ซึ่งรวมเครือข่ายประสาทลึกและการเรียนรู้แบบเสริมกำลัง
การเรียนรู้การเสริมแรงอย่างล้ำลึก
การเรียนรู้การเสริมแรง (RL) ไม่ใช่แนวคิดใหม่ Ivan Pavlov ผู้ได้รับรางวัลโนเบลได้ทดลองการปรับสภาพสุนัขแบบคลาสสิกและค้นพบหลักการของการเรียนรู้แบบเสริมแรงในปี 1902 นอกจากนี้ RL ยังเป็นหนึ่งในวิธีการที่มนุษย์เรียนรู้ทักษะใหม่ๆ เคยสงสัยหรือไม่ว่าปลาโลมาในการแสดงได้รับการฝึกฝนให้กระโดดขึ้นจากน้ำได้สูงมาก? ด้วยความช่วยเหลือของ RL ขั้นแรก ให้นำเชือกที่ใช้สำหรับเตรียมโลมาจุ่มลงในสระ เมื่อใดก็ตามที่โลมาข้ามสายเคเบิลจากด้านบน มันก็จะได้รับรางวัลเป็นอาหาร เมื่อมันไม่ข้ามเชือกรางวัลจะถูกถอนออก โลมาจะเรียนรู้อย่างช้าๆ ว่าจ่ายเมื่อผ่านสายไฟจากด้านบน ความสูงของเชือกค่อยๆเพิ่มขึ้นเพื่อฝึกปลาโลมา 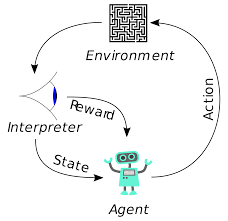
การสร้างภาษาธรรมชาติ: เรื่องเด่นที่คุณต้องรู้
ตัวแทนในการเรียนรู้แบบเสริมกำลังได้รับการฝึกฝนโดยใช้หลักการเดียวกัน ตัวแทนจะดำเนินการและโต้ตอบกับสิ่งแวดล้อม การดำเนินการโดยตัวแทนทำให้สภาพแวดล้อมเปลี่ยนแปลง นอกจากนี้ ตัวแทนยังได้รับคำติชมเกี่ยวกับสิ่งแวดล้อมอีกด้วย ตัวแทนจะได้รับรางวัลหรือไม่ขึ้นอยู่กับการกระทำและวัตถุประสงค์ที่มีอยู่ ประเด็นสำคัญคือ วัตถุประสงค์ในมือนี้ไม่ได้ระบุไว้อย่างชัดเจนสำหรับตัวแทน เมื่อให้เวลาเพียงพอ ตัวแทนจะได้เรียนรู้วิธีเพิ่มผลตอบแทนสูงสุดในอนาคต

เมื่อรวมสิ่งนี้เข้ากับ DNN แล้ว DeepMind ได้ประดิษฐ์ Deep Reinforcement Learning (DRL) หรือ Deep Q Networks (DQN) โดยที่ Q หมายถึงรางวัลสูงสุดในอนาคตที่ได้รับ DQN ถูกนำไปใช้กับ เกม Atari เป็นครั้งแรก DQN เรียนรู้วิธีเล่นเกม Atari ประเภทต่างๆ ได้ตั้งแต่แกะกล่อง ความก้าวหน้าคือไม่จำเป็นต้องมีการเขียนโปรแกรมที่ชัดเจนเพื่อเป็นตัวแทนของเกม Atari ประเภทต่างๆ โปรแกรมเดียวฉลาดพอที่จะเรียนรู้เกี่ยวกับสภาพแวดล้อมต่าง ๆ ทั้งหมดของเกม และผ่านการเล่นด้วยตนเอง สามารถควบคุมสภาพแวดล้อมต่างๆ ได้มากมาย
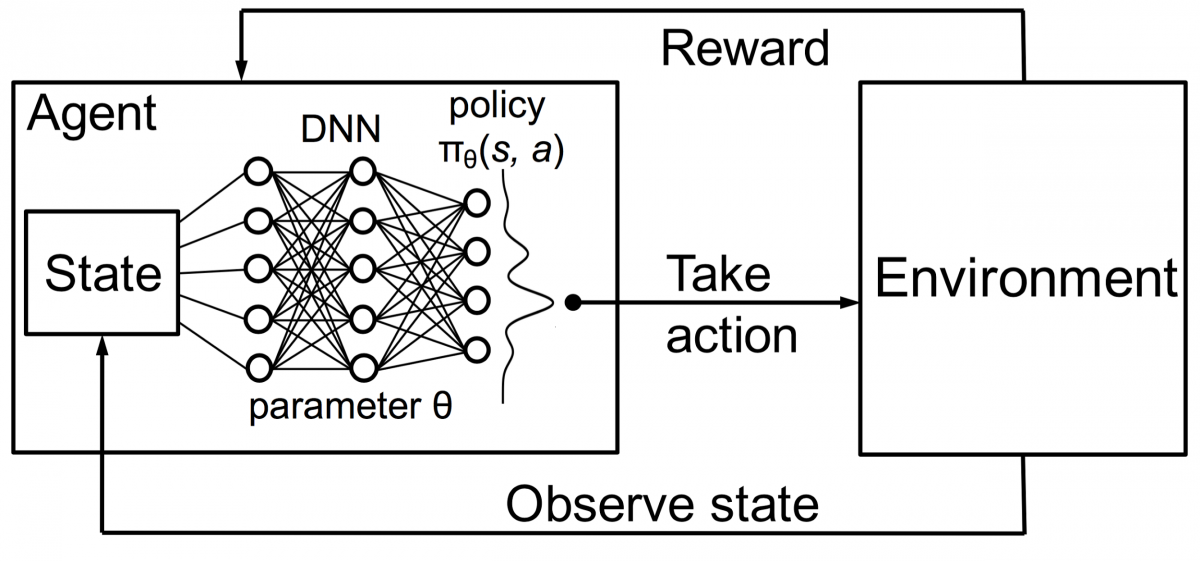
ในปี 2014 DQN มีประสิทธิภาพเหนือกว่าวิธีการเรียนรู้ของเครื่องก่อนหน้านี้ใน 43 เกมจากทั้งหมด 49 เกม (ตอนนี้ได้รับการทดสอบในเกมมากกว่า 70 เกม) ที่จริงแล้ว มากกว่าครึ่งของเกม มันเล่นได้มากกว่า 75% ของระดับผู้เล่นที่เป็นมนุษย์มืออาชีพ ในบางเกม DQN ถึงกับคิดกลยุทธ์ที่มองการณ์ไกลอย่างน่าประหลาดใจ ซึ่งช่วยให้บรรลุคะแนนสูงสุดที่ทำได้—เช่น ใน Breakout เขาเรียนรู้ที่จะขุดอุโมงค์ที่ปลายด้านหนึ่งของกำแพงอิฐก่อน เพื่อให้ลูกบอลกระดอน รอบด้านหลังและเคาะอิฐจากด้านหลัง
นโยบายและเครือข่ายมูลค่า
มีสองประเภทหลักของเครือข่ายภายใน AlphaGo:
หนึ่งในวัตถุประสงค์ของ DQN ของ AlphaGo คือการก้าวไปไกลกว่าการเล่นแบบผู้เชี่ยวชาญของมนุษย์ และเลียนแบบการเคลื่อนไหวที่เป็นนวัตกรรมใหม่ โดยการเล่นกับตัวเองหลายล้านครั้ง และปรับปรุงน้ำหนักแบบค่อยเป็นค่อยไป DQN นี้มีอัตราการชนะ 80% เมื่อเทียบกับ DNN ทั่วไป DeepMind ตัดสินใจรวมเครือข่ายประสาทเทียมทั้งสองนี้ (DNN และ DQN) เข้าด้วยกันเพื่อสร้างเครือข่ายประเภทแรก นั่นคือ 'Policy Network' โดยสังเขป งานของเครือข่ายนโยบายคือการลดความกว้างของการค้นหาการเคลื่อนไหวครั้งต่อไป และหาการเคลื่อนไหวที่ดีสองสามอย่างซึ่งควรค่าแก่การสำรวจเพิ่มเติม
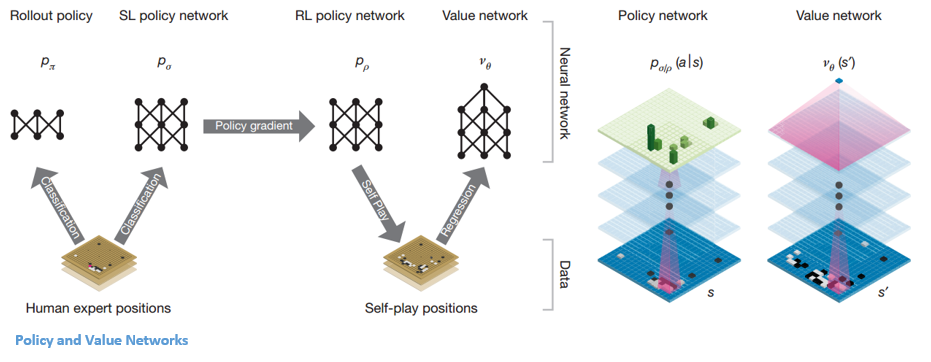 เมื่อเครือข่ายนโยบายถูกระงับ เครือข่ายจะเล่นกับตัวเองหลายล้านครั้ง เกมเหล่านี้สร้างชุดข้อมูล Go ใหม่ ซึ่งประกอบด้วยตำแหน่งกระดานต่างๆ และผลลัพธ์ของเกม ชุดข้อมูลนี้ใช้เพื่อสร้างฟังก์ชันการประเมิน ฟังก์ชันประเภทที่สอง – 'Value Network' ใช้เพื่อทำนายผลของเกม เรียนรู้ที่จะใช้ตำแหน่งกระดานต่างๆเป็นอินพุตและทำนายผลของเกมและการวัดผล
เมื่อเครือข่ายนโยบายถูกระงับ เครือข่ายจะเล่นกับตัวเองหลายล้านครั้ง เกมเหล่านี้สร้างชุดข้อมูล Go ใหม่ ซึ่งประกอบด้วยตำแหน่งกระดานต่างๆ และผลลัพธ์ของเกม ชุดข้อมูลนี้ใช้เพื่อสร้างฟังก์ชันการประเมิน ฟังก์ชันประเภทที่สอง – 'Value Network' ใช้เพื่อทำนายผลของเกม เรียนรู้ที่จะใช้ตำแหน่งกระดานต่างๆเป็นอินพุตและทำนายผลของเกมและการวัดผล
การรวมนโยบายและเครือข่ายมูลค่า
หลังจากการฝึกอบรมทั้งหมดนี้ ในที่สุด DeepMind ก็จบลงด้วยโครงข่ายประสาทเทียมสองเครือข่าย – เครือข่ายนโยบายและเครือข่ายคุณค่า เครือข่ายนโยบายใช้ตำแหน่งของคณะกรรมการเป็นอินพุตและส่งออกการแจกแจงความน่าจะเป็นตามความน่าจะเป็นของแต่ละการเคลื่อนไหวในตำแหน่งนั้น เครือข่ายมูลค่าใช้ตำแหน่งของกระดานอีกครั้งเป็นอินพุตและเอาต์พุตจำนวนจริงเดียวระหว่าง 0 ถึง 1 หากเอาต์พุตของเครือข่ายเป็นศูนย์หมายความว่าสีขาวชนะอย่างสมบูรณ์และ 1 หมายถึงชนะอย่างสมบูรณ์สำหรับผู้เล่นที่มีสีดำ หิน
เครือข่ายนโยบายประเมินตำแหน่งปัจจุบัน และเครือข่ายมูลค่าประเมินการเคลื่อนไหวในอนาคต การแบ่งงานออกเป็นสองเครือข่ายโดย DeepMind เป็นหนึ่งในสาเหตุหลักที่อยู่เบื้องหลังความสำเร็จของ AlphaGo
การรวมเครือข่ายนโยบายและมูลค่าเข้ากับ Monte Carlo Tree Search (MCTS) และการเปิดตัว
โครงข่ายประสาทด้วยตัวเองจะไม่เพียงพอ ในการชนะเกมโก จำเป็นต้องมีกลยุทธ์เพิ่มเติม แผนนี้สำเร็จได้ด้วยความช่วยเหลือของ MCTS Monte Carlo Tree Search ยังช่วยในการเชื่อมโครงข่ายประสาทเทียมทั้งสองเข้าด้วยกันด้วยวิธีที่สร้างสรรค์ โครงข่ายประสาทเทียมช่วยในการค้นหาการเคลื่อนไหวที่ดีที่สุดต่อไปอย่างมีประสิทธิภาพ
มาลองสร้างตัวอย่างกันซึ่งจะช่วยให้คุณเห็นภาพทั้งหมดนี้ได้ดีขึ้นมาก ลองนึกภาพว่าเกมอยู่ในตำแหน่งใหม่ที่ไม่เคยเจอมาก่อน ในสถานการณ์เช่นนี้ เครือข่ายนโยบายจะถูกเรียกใช้เพื่อประเมินสถานการณ์ปัจจุบันและเส้นทางในอนาคตที่เป็นไปได้ เช่นเดียวกับความพึงปรารถนาของเส้นทางและมูลค่าของการเคลื่อนไหวแต่ละครั้งโดยเครือข่าย Value ซึ่งสนับสนุนโดยการเปิดตัวของ Monte Carlo
เครือข่ายนโยบายค้นหาการเคลื่อนไหวที่ "ดี" ที่เป็นไปได้ทั้งหมดและเครือข่ายมูลค่าประเมินผลลัพธ์แต่ละรายการ ในการเปิดตัว Monte Carlo มีการเล่นเกมสุ่มสองสามพันเกมจากตำแหน่งที่เครือข่ายนโยบายยอมรับ ทำการทดลองเพื่อกำหนดความสำคัญสัมพัทธ์ของเครือข่ายคุณค่ากับการเปิดตัว Monte Carlo จากการทดลองนี้ DeepMind กำหนดน้ำหนัก 80% ให้กับเครือข่าย Value และให้น้ำหนัก 20% ให้กับฟังก์ชันการประเมินการเปิดตัว Monte Carlo
เครือข่ายนโยบายลดความกว้างของการค้นหาจากการย้ายที่เป็นไปได้ 200 แบบคี่เป็นการเคลื่อนไหวที่ดีที่สุด 4 หรือ 5 เครือข่ายนโยบายขยายแผนผังจาก 4 หรือ 5 ขั้นตอนที่ต้องพิจารณา เครือข่ายมูลค่าช่วยลดความลึกของการค้นหาต้นไม้โดยส่งคืนผลลัพธ์ของเกมจากตำแหน่งนั้นทันที สุดท้าย การย้ายที่มีค่า Q สูงสุดคือ ขั้นตอนที่มีประโยชน์สูงสุด
“ เกมนี้เล่นโดยใช้สัญชาตญาณและความรู้สึกเป็นหลัก และด้วยความงาม ความละเอียดอ่อน และความลึกซึ้งทางปัญญา เกมนี้จึงจับจินตนาการของมนุษย์มานานหลายศตวรรษ”
– เดมิส ฮาสซาบีส
การประยุกต์ใช้ AlphaGo กับปัญหาในโลกแห่งความเป็นจริง
วิสัยทัศน์ของ DeepMind จากเว็บไซต์ของพวกเขาบอกได้ชัดเจน – “แก้ปัญหาปัญญา ใช้ความรู้นี้เพื่อทำให้โลกนี้น่าอยู่ขึ้น” เป้าหมายสุดท้ายของอัลกอริธึมนี้คือการทำให้เป็นวัตถุประสงค์ทั่วไป เพื่อให้สามารถใช้เพื่อแก้ปัญหาที่ซับซ้อนในโลกแห่งความเป็นจริงได้ AlphaGo ของ DeepMind เป็นก้าวสำคัญในการแสวงหา AGI DeepMind ใช้เทคโนโลยีของตนอย่างประสบความสำเร็จในการแก้ปัญหาในโลกแห่งความเป็นจริง มาดูตัวอย่างกัน:
ลดการใช้พลังงาน
AI ของ DeepMind ประสบความสำเร็จในการลดต้นทุนการทำความเย็นศูนย์ข้อมูลของ Google ลง 40% ในสภาพแวดล้อมที่สิ้นเปลืองพลังงานขนาดใหญ่ การปรับปรุงนี้เป็นก้าวที่มหัศจรรย์ แหล่งพลังงานหลักประการหนึ่งสำหรับศูนย์ข้อมูลคือการทำความเย็น ความร้อนจำนวนมากที่เกิดจากการใช้งานเซิร์ฟเวอร์จำเป็นต้องถูกลบออกเพื่อให้เซิร์ฟเวอร์ทำงานต่อไปได้ สำเร็จได้ด้วยอุปกรณ์อุตสาหกรรมขนาดใหญ่ เช่น ปั๊ม เครื่องทำความเย็น และคูลลิ่งทาวเวอร์ เนื่องจากสภาพแวดล้อมของศูนย์ข้อมูลเป็นแบบไดนามิกมาก การดำเนินการอย่างมีประสิทธิภาพด้านพลังงานที่เหมาะสมจึงเป็นเรื่องที่ท้าทาย AI ของ DeepMind ถูกใช้เพื่อแก้ไขปัญหานี้
อย่างแรก พวกเขาดำเนินการโดยใช้ข้อมูลในอดีต ซึ่งรวบรวมโดยเซ็นเซอร์หลายพันตัวภายในศูนย์ข้อมูล เมื่อใช้ข้อมูลนี้ พวกเขาได้ฝึกกลุ่ม DNN เกี่ยวกับประสิทธิภาพการใช้พลังงานโดยเฉลี่ยในอนาคต (PUE) ในอนาคต เนื่องจากอัลกอริธึมนี้เป็นอัลกอริธึมสำหรับใช้งานทั่วไป จึงมีการวางแผนว่าจะนำไปใช้กับความท้าทายอื่นๆ ด้วยในสภาพแวดล้อมของศูนย์ข้อมูล
การใช้งานที่เป็นไปได้ของเทคโนโลยีนี้รวมถึงการได้รับพลังงานมากขึ้นจากหน่วยอินพุตเดียวกัน ลดพลังงานในการผลิตเซมิคอนดักเตอร์และการใช้น้ำ ฯลฯ DeepMind ประกาศในบล็อกโพสต์ว่าความรู้นี้จะถูกแบ่งปันในสิ่งพิมพ์ในอนาคตเพื่อให้ศูนย์ข้อมูลอื่น ๆ อุตสาหกรรม ผู้ปฏิบัติงานและสิ่งแวดล้อมจะได้รับประโยชน์อย่างมากจากขั้นตอนสำคัญนี้
การวางแผนรังสีรักษาสำหรับมะเร็งศีรษะและลำคอ
DeepMind ได้ร่วมมือกับแผนกรังสีบำบัดที่ NHS Foundation Trust ของโรงพยาบาล University College London ซึ่งเป็นผู้นำระดับโลกในด้านการรักษาโรคมะเร็ง
บิ๊กดาต้าและแมชชีนเลิร์นนิงร่วมกันต่อต้านมะเร็งได้อย่างไร
ผู้ชายหนึ่งใน 75 คนและผู้หญิง 1 ใน 150 คนได้รับการวินิจฉัยว่าเป็นมะเร็งช่องปากในช่วงชีวิตของพวกเขา เนื่องจากลักษณะที่ละเอียดอ่อนของโครงสร้างและอวัยวะในบริเวณศีรษะและลำคอ นักรังสีวิทยาจึงต้องระมัดระวังเป็นพิเศษในขณะที่ทำการรักษา
ก่อนการให้รังสีรักษา จำเป็นต้องเตรียมแผนที่โดยละเอียดพร้อมบริเวณที่จะทำการรักษาและพื้นที่ที่ควรหลีกเลี่ยง สิ่งนี้เรียกว่าการแบ่งส่วน แผนที่ที่แบ่งส่วนนี้จะถูกป้อนเข้าไปในเครื่องถ่ายภาพรังสี ซึ่งจะกำหนดเป้าหมายเซลล์มะเร็งโดยไม่ทำอันตรายต่อเซลล์ปกติ
ในกรณีของมะเร็งที่ศีรษะหรือคอ งานนี้เป็นงานหนักสำหรับนักรังสีวิทยาเนื่องจากเกี่ยวข้องกับอวัยวะที่บอบบางมาก นักรังสีวิทยาใช้เวลาประมาณสี่ชั่วโมงในการสร้างแผนที่แบบแบ่งส่วนสำหรับพื้นที่นี้ DeepMind ใช้อัลกอริธึมเพื่อลดเวลาที่ใช้ในการสร้างแผนที่แบบแบ่งกลุ่มจากสี่เป็นหนึ่งชั่วโมง วิธีนี้จะช่วยให้เวลาของนักรังสีวิทยาว่างมากขึ้น ที่สำคัญกว่านั้น อัลกอริธึมการแบ่งส่วนนี้สามารถใช้กับส่วนอื่นๆ ของร่างกายได้
สรุปแล้ว AlphaGo ประสบความสำเร็จในการเอาชนะลี ซีดอล แชมป์โลก 18 สมัยได้สำเร็จถึงสี่ครั้งในการแข่งขันแบบ Best-of-Five ในปี 2016 และในปี 2017 ก็สามารถเอาชนะทีมผู้เล่นที่เก่งที่สุดในโลกได้อีกด้วย ใช้การรวมกันของ DNN และ DQN เป็นเครือข่ายนโยบายเพื่อหาแนวทางที่ดีที่สุดถัดไป และใช้ DNN หนึ่งเครือข่ายเป็นเครือข่ายที่มีคุณค่าในการประเมินผลลัพธ์ของเกม การค้นหาแบบทรีมอนติคาร์โลจะใช้ร่วมกับทั้งเครือข่ายนโยบายและค่าเพื่อลดความกว้างและความลึกของการค้นหา ซึ่งใช้เพื่อปรับปรุงฟังก์ชันการประเมิน เป้าหมายสูงสุดของอัลกอริธึมนี้ไม่ใช่เพื่อแก้เกมกระดาน แต่เพื่อประดิษฐ์อัลกอริธึมปัญญาประดิษฐ์ทั่วไป AlphaGo ก้าวไปข้างหน้าอย่างไม่ต้องสงสัย
ความแตกต่างระหว่าง Data Science, Machine Learning และ Big Data!
แน่นอนว่ายังมีเอฟเฟกต์อื่นๆ เมื่อข่าวของ AlphaGo กับ Lee Seedol กลายเป็นกระแสไวรัล ความต้องการกระดาน Go ก็เพิ่มขึ้นเป็นสิบเท่า ร้านค้าหลายแห่งรายงานว่ากระดาน Go หมดสต็อก และการซื้อกระดาน Go กลายเป็นเรื่องท้าทาย
โชคดีที่ฉันเพิ่งพบและสั่งซื้อให้ตัวเองและลูกของฉัน คุณวางแผนที่จะซื้อกระดานและเรียนรู้ Go หรือไม่?
เรียนรู้หลักสูตร ML จากมหาวิทยาลัยชั้นนำของโลก รับ Masters, Executive PGP หรือ Advanced Certificate Programs เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
อะไรคือข้อจำกัดของการเรียนรู้การเสริมแรงเชิงลึก?
DL ลืมความรู้ที่ได้รับก่อนหน้านี้เมื่อมีการแนะนำข้อมูลหรือข้อมูลใหม่ ดังนั้นจึงไม่ท้าทาย การเสริมแรงมากเกินไปบางครั้งอาจส่งผลให้เกิดสภาวะที่มากเกินไป ทำให้ประสิทธิภาพลดลง เนื่องจากแบบจำลองข้อมูลมีความซับซ้อน การฝึกอบรมจึงมีค่าใช้จ่ายสูง การเรียนรู้เชิงลึกยังจำเป็นต้องใช้ GPU ราคาแพงและเวิร์กสเตชันหลายร้อยเครื่อง ส่งผลให้ประหยัดในการใช้งาน
อะไรคือข้อเสียของการใช้ Monte Carlo Tree Search?
แม้ว่า MCTS จะเป็นอัลกอริธึมที่ใช้งานง่าย แต่ก็มีข้อเสียอยู่บ้าง เมื่อต้นไม้โตขึ้นหลังจากทำซ้ำไม่กี่ครั้ง จำเป็นต้องใช้หน่วยความจำจำนวนมาก เมื่อนำไปใช้กับเกมผลัดกันเล่น อาจมีสาขาหรือเส้นทางเดียวที่นำไปสู่การแพ้ต่อคู่ต่อสู้ในเงื่อนไขเฉพาะ ส่งผลให้พึ่งพาได้น้อยลง หลังจากการทำซ้ำหลายครั้ง Monte Carlo Tree Search ใช้เวลานานในการกำหนดเส้นทางที่มีประสิทธิภาพสูงสุด
AlphaZero แตกต่างจาก AlphaGo Zero อย่างไร
AlphaGo เวอร์ชันก่อนหน้าได้รวมเอาคุณลักษณะที่ออกแบบด้วยมือจำนวนเล็กน้อย แต่ AlphaGo Zero ใช้หินขาวดำจากกระดาน Go เป็นข้อมูลเข้า AlphaGo เวอร์ชันก่อนหน้าอาศัยเครือข่ายนโยบายเพื่อเลือกการย้ายครั้งต่อไปและเครือข่ายมูลค่าเพื่อประเมินผู้ชนะของเกมจากแต่ละตำแหน่ง สิ่งเหล่านี้รวมอยู่ใน AlphaGo Zero ทำให้การฝึกอบรมและการประเมินมีประสิทธิภาพมากขึ้น ความแตกต่างทั้งหมดนี้ส่งผลให้ระบบมีการปรับปรุงประสิทธิภาพและลักษณะทั่วไป ในทางกลับกัน การปรับอัลกอริทึมทำให้ระบบมีประสิทธิภาพและประสิทธิผลมากขึ้น