
Практическое введение в проверку модели и регуляризацию в глубоком обучении с использованием TensorFlow
Опубликовано: 2020-10-28Оглавление
Введение
Практика машин для усвоения информации с помощью парадигмы контролируемых алгоритмов обучения произвела революцию в нескольких задачах, таких как генерация последовательностей, обработка естественного языка и даже компьютерное зрение. Этот подход основан на использовании набора данных, который имеет набор входных признаков и соответствующий набор меток. Затем машина использует эту информацию, представленную в виде функций и меток, для изучения распределения и шаблонов данных, чтобы делать статистические прогнозы на невидимых входных данных.
Важнейшим шагом в разработке моделей глубокого обучения является оценка производительности модели, особенно на новых и невидимых точках данных. Основная цель состоит в том, чтобы разработать модели, которые обобщают данные, на которых они были обучены. Нам нужны модели, которые могут делать хорошие и надежные прогнозы в реальном мире. Важной концепцией, которая помогает нам в этом, является проверка модели и регуляризация, которую мы рассмотрим сегодня.
Проверка модели
Построение модели машинного обучения всегда сводится к разделению доступных данных на три набора: обучающий, проверочный и тестовый. Данные обучения используются моделью для изучения особенностей и характеристик распределения.
Здесь важно знать, что удовлетворительная производительность модели на обучающем наборе не означает, что модель также будет обобщать новые данные с аналогичной производительностью, это связано с тем, что модель стала предвзятой по отношению к обучающему набору. Таким образом, концепция проверки и тестового набора используется, чтобы сообщить, насколько хорошо модель обобщает новые точки данных.
Стандартная процедура заключается в использовании обучающих данных для подбора модели, оценке производительности модели с использованием данных проверки и, наконец, тестовых данных, используемых для оценки того, насколько хорошо модель будет работать на совершенно новых примерах.
Набор проверки используется для настройки гиперпараметров (количества скрытых слоев, скорости обучения, процента отсева и т. д.) , чтобы модель могла хорошо обобщаться. Распространенной загадкой, с которой сталкиваются новички в машинном обучении, является понимание необходимости отдельных наборов проверок и тестов.

Необходимость в двух различных наборах можно понять, следуя следующей интуиции: для каждой глубокой нейронной сети, которую необходимо спроектировать, существует множество гиперпараметров, которые необходимо настроить для достижения удовлетворительной производительности.
Можно обучить несколько моделей с использованием любого из гиперпараметров, а затем выбрать модель с наилучшей метрикой производительности на основе производительности этой модели в проверочном наборе. Теперь каждый раз, когда гиперпараметры настраиваются для повышения производительности в проверочном наборе, некоторая информация просачивается/вводится в модель, следовательно, окончательные веса нейронной сети могут быть смещены в сторону проверочного набора.
После каждой корректировки гиперпараметра наша модель продолжает хорошо работать на проверочном наборе, потому что именно для этого мы ее оптимизировали. По этой причине проверочный тест не может точно определить способность модели к обобщению. Чтобы преодолеть этот недостаток, в игру вступает тестовый набор.
Наиболее точное представление способности модели к обобщению дает производительность на тестовом наборе, поскольку мы не оптимизировали модель для лучшей производительности на этом наборе, и, следовательно, это будет указывать на наиболее прагматичную оценку способности модели.
Обязательно прочтите: лучшие методы глубокого обучения, о которых вы должны знать
Реализация стратегий проверки с использованием TensorFlow 2.0
TensorFlow 2.0 предоставляет чрезвычайно простое решение для отслеживания производительности нашей модели в отдельном проверочном тесте. Мы можем передать аргумент ключевого слова validation_split в методе model.fit() .
Ключевое слово validation_split принимает входные данные в виде числа с плавающей запятой от 0 до 1 , которое представляет долю данных обучения, которые будут использоваться в качестве данных проверки. Таким образом, передача значения 0,1 в ключевом слове означает резервирование 10% обучающих данных для проверки.
Практическая реализация разделения проверки может быть легко продемонстрирована с использованием набора данных о диабете от sklearn. Набор данных содержит 442 экземпляра с 10 исходными переменными (возраст, пол, ИМТ и т. д.) в качестве обучающих признаков и мерой прогрессирования заболевания через год в качестве метки.
Мы импортируем набор данных с помощью TensorFlow и sklearn:

Фундаментальным шагом после предварительной обработки данных является построение последовательной нейронной сети с прямой связью с плотными слоями:

Здесь у нас есть нейронная сеть с шестью скрытыми слоями с релю- активацией и одним выходным слоем с линейной активацией.

Затем мы компилируем модель с оптимизатором Адама и функцией потери среднеквадратичной ошибки .

Затем метод model.fit() используется для обучения модели в течение 100 эпох с validation_split , равным 15%.

Мы также можем построить график потери модели, наблюдаемый как для данных обучения, так и для данных проверки:
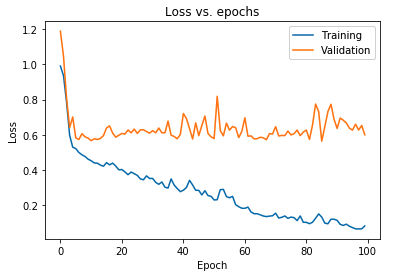
График, показанный выше, показывает, что потери при проверке постоянно увеличиваются после 10 эпох, в то время как потери при обучении продолжают уменьшаться. Эта тенденция является хрестоматийным примером невероятно важной проблемы в машинном обучении, которая называется переоснащением .
Для преодоления этой проблемы было проведено множество оригинальных исследований, и в совокупности эти решения называются методами регуляризации . В следующем разделе будет рассмотрен аспект регуляризации и процедура регуляризации любой модели глубокого обучения.
Регуляризация нашей модели
В предыдущем разделе мы наблюдали обратную тенденцию на графиках потерь обучающего и проверочного наборов, где график функции стоимости последнего набора, кажется, растет, а график первого набора продолжает уменьшаться и, следовательно, создает разрыв ( разрыв обобщения ). Узнайте больше о регуляризации в машинном обучении.
Тот факт, что существует такой разрыв между двумя графиками потерь, символизирует, что модель не может хорошо обобщить набор для проверки ( невидимые данные) , и, следовательно, значение затрат/убытков, понесенных в этом наборе данных, также будет неизбежно высоким.
Эта особенность возникает из-за того, что веса и смещения обученной модели настолько хорошо адаптируются к изучению распределения обучающих данных, что она не может предсказать метки новых и невидимых функций, что приводит к увеличению потерь при проверке.
Обоснование заключается в том, что настройка сложной модели приведет к возникновению таких аномалий, поскольку параметры модели растут, чтобы стать очень надежными для обучающих данных. Следовательно, упрощение или уменьшение емкости/сложности моделей уменьшит эффект переобучения. Один из способов добиться этого — использовать отсева в нашей модели глубокого обучения, которую мы рассмотрим в следующем разделе.
Понимание и реализация отсева в TensorFlow
Ключевой смысл использования отсева заключается в том, чтобы случайным образом отбрасывать скрытые и видимые единицы, чтобы получить менее сложную модель, которая ограничивает увеличение параметров модели и, следовательно, делает модель более надежной для производительности на обобщенном наборе данных.
Эта недавно принятая практика является мощным подходом, используемым практиками машинного обучения для создания эффекта регуляризации в любой модели глубокого обучения. Отсева можно легко реализовать с помощью Keras API поверх TensorFlow, импортировав слой отсева и передав в нем аргумент скорости , чтобы указать долю единиц, которые необходимо отбросить.
Эти выпадающие слои обычно укладываются сразу после каждого плотного слоя, чтобы создать чередующийся прилив архитектуры плотных выпадающих слоев.
Мы можем изменить нашу ранее определенную нейронную сеть с прямой связью, включив в нее шесть выпадающих слоев, по одному для каждого скрытого слоя:


Здесь скорость отсева _ была установлена на 0,2, что означает, что 20% узлов будут удалены при обучении модели. Мы компилируем и обучаем модель с тем же оптимизатором, функцией потерь, метриками и количеством эпох для проведения объективного сравнения.
Основное влияние регуляризации модели с использованием отсева можно интерпретировать, снова построив кривую потерь модели, полученную на обучающих и проверочных наборах:
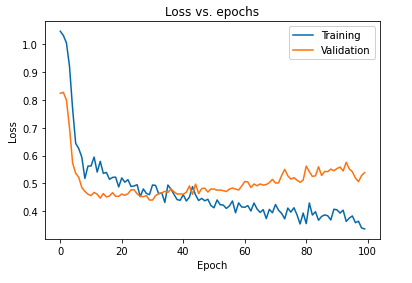
Из приведенного выше графика видно, что разрыв в обобщении, полученный после регуляризации модели, намного меньше, что делает модель менее восприимчивой к переобучению обучающих данных.
Читайте также: Идеи проекта глубокого обучения
Заключение
Аспект проверки и регуляризации модели является важной частью проектирования рабочего процесса создания любого решения для машинного обучения. Проводится много исследований, чтобы импровизировать контролируемое обучение, и это практическое руководство дает краткий обзор некоторых из наиболее распространенных практик и методов при сборке любого алгоритма обучения.
Если вам интересно узнать больше о методах глубокого обучения и машинном обучении, ознакомьтесь с сертификацией PG IIIT-B и upGrad в области машинного обучения и глубокого обучения, которая предназначена для работающих профессионалов и предлагает более 240 часов тщательного обучения, 5+ тематических исследований. и задания, статус выпускника IIIT-B и помощь в трудоустройстве в ведущих фирмах.