
Анализ данных с использованием Python [Все, что вам нужно знать]
Опубликовано: 2020-09-02Для тех, кто хочет начать работу с анализом данных, первым языком, который приходит на ум, является R или Python. И причина, по которой разработчики сейчас более склонны к Python, заключается в его широкой адаптируемости в общей области разработки программного обеспечения. Следовательно, анализ данных с использованием python — один из самых распространенных терминов для тех, кто начинает свой путь в науке о данных.
Оглавление
Почему анализ данных?
Теперь сначала, почему анализ данных? Что ж, это первый шаг к пониманию того, с каким типом данных вы работаете. Это шаг, на котором вы находите ценные закономерности в данных, которые в противном случае вы могли бы не увидеть. В целом, он обеспечивает интуитивное понимание набора данных.
Здесь нам нужно провести границу между анализом данных и предварительной обработкой данных. Предварительная обработка данных связана с моделированием вашего набора данных, чтобы убедиться, что он готов к обучению. Анализ данных заключается в понимании набора данных, что является предварительным шагом для предварительной обработки данных. При анализе данных мы пытаемся смоделировать данные, чтобы лучше их просмотреть и, следовательно, получить представление об имеющемся наборе данных.
Почему питон?
Второй вопрос: почему Python? Ну, мы уже говорили, что Python — широко адаптированный язык. Да, это не единственный выбор, когда дело доходит до анализа данных, но он довольно хороший. Другая причина в том, что он используется больше! Python прост и имеет большое сообщество разработчиков, которые помогут вам в анализе данных с использованием Python . Более того, анализ данных с использованием Python весьма приятен из-за большого количества творческих библиотек, которые он предлагает для анализа и визуализации данных.
В Python базовой библиотекой для анализа данных является Pandas. Это библиотека высокого уровня, построенная на основе библиотеки NumPy, которая предназначена для научных вычислений и численного анализа. Pandas упрощает работу с данными, предлагая свою структуру данных, известную как DataFrame. DataFrame помогает читать и хранить ваш набор данных. Он предоставляет базовые функции для чтения и записи набора данных, а также для просмотра метаданных и функций запросов для извлечения всех полезных сведений из набора данных.
Важно отметить, что визуализация данных является значительной частью общего анализа данных. Потому что это помогает лучше понять данные не только вам самим, но и тем, кому вы предоставляете информацию. Мы будем обсуждать две наиболее часто используемые библиотеки для визуализации: Matplotlib и Seaborn. Matplotlib — это базовая библиотека для любых визуализаций в Python. Seaborn также создан на основе Matplotlib, который предлагает одни из самых креативных функций визуализации данных.
Настройка среды
Первый шаг — настроить среду. При выполнении анализа данных с использованием python важно иметь подходящую среду для сохранения всей вашей работы. Анализ данных с использованием Python — это не просто сценарий, это будет ваше взаимодействие с набором данных, и для этого вам потребуется подходящее место для работы.
В python эта услуга предоставляется дистрибутивом Anaconda. Ведущим рабочим местом Anaconda является ноутбук Jupyter. Итак, почему Юпитер? Ну, это позволяет вам иметь визуализации прямо в вашем ноутбуке. Он также имеет некоторые волшебные функции, которые позволяют вам видеть вывод напрямую, не указывая явно, где вы хотите.
Библиотеки Pandas и Matplotlib поставляются предустановленными, поэтому для их использования не требуется дополнительная настройка.
Вот краткий обзор того, как обойти анализ данных с помощью Python :
- Загрузка набора данных
- Просмотр метаданных набора данных с помощью Pandas
- Визуализация данных с использованием Matplotlib
- Сбор информации о данных
Импорт необходимых библиотек
Прежде чем мы начнем смотреть код для шагов, просто импортируйте необходимые библиотеки с псевдотегами, например, с именем, которым мы будем называть их для всей программы.
импортировать numpy как np
импортировать панд как pd
# для визуализации данных
импортировать matplotlib.pyplot как plt
импортировать Seaborn как sns
Теперь мы рассмотрим каждый шаг и обсудим, какие функции доступны и как их использовать.
Во-первых, чтение наборов данных. Панды предоставляют некоторые основные функции для загрузки набора данных в его основную структуру данных: DataFrame. Мы можем использовать его следующим образом.
data_df = pd.read_csv('heart.csv')
Результатом любой функции чтения будет DataFrame. Помимо считывателей CSV, панды предоставляют считыватели практически для всех типов данных. От HTML до JSON и Excel.
Кроме того, если у вас нет данных как таковых и вы хотите создать свой набор данных, вы можете легко использовать объектные функции Pandas Series и DataFrame.
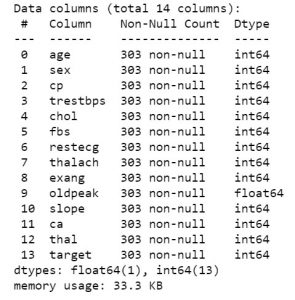
Итак, когда у вас есть данные, давайте перейдем к просмотру того, о чем эти данные. Чтобы получить первое представление данных, вы можете использовать такие функции, как df.info или df.describe, чтобы узнать структуру вашего набора данных.
data_df.info()
data_df.describe()
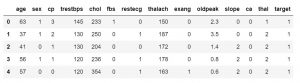
Как только вы узнаете, какие функции содержит ваш набор данных, вы можете посмотреть на их значения. Вы можете использовать функцию df.head(), чтобы получить первые 5 образцов.
data_df.head()
#или
data_df.head(3)
Вы также можете указать количество выборок, чтобы переопределить значение по умолчанию, равное 5. Вы также можете использовать функцию df.tail() для получения последних 5 значений набора данных.
data_df.хвост()
Это просто для того, чтобы получить общее представление о том, как могут выглядеть ваши данные. Когда все будет готово, вы можете приступить к основным задачам визуализации данных, используя Matplotlib. Введите следующий код, чтобы сделать график интерактивным и просмотреть его в самой записной книжке.
%matplotlib встроенный
Мы увидим функциональные возможности 5 лучших визуализаций в matplotlib. Прежде чем углубиться в это, мы должны знать некоторые другие функции, которые управляют нашими графиками. Такие функции, как:
- Ярлыки: xlabel(), ylabel(). Они предназначены для меток оси x и оси y.
- Легенда: используется для создания легенды сюжета.
- Название: Чтобы присвоить название вашему сюжету
- И, наконец, функция show для просмотра графика.
Оформить заказ: зарплата аналитика данных в Индии
Визуализации
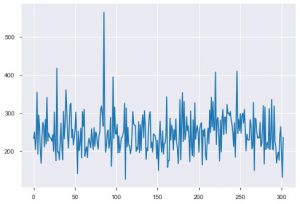
Давайте теперь посмотрим на визуализации. Начнем с основного сюжета. plt.plot() используется для создания простого линейного графика для ваших данных. Функция требует принудительно два параметра, а это данные по оси x и данные по оси y. При желании вы можете указать стили, имя и цвет графика. Вот как это выглядит в коде.
plt.plot(data_df['хол'])
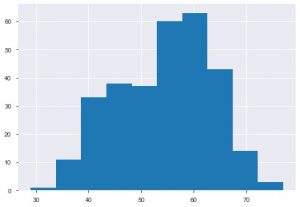
Второй график — гистограмма. Гистограмма поможет вам просмотреть частоту или распределение определенной функции. Это поможет вам увидеть, как величины соотносятся друг с другом. Plt.hist() — это базовая функция для создания гистограммы ваших данных. Вы можете указать параметр bins, чтобы управлять числом на графике. Вам нужно только передать данные одной оси, если вы хотите одномерный анализ.
plt.hist(data_df['возраст'])
Еще один сюжет, который вы часто видели, — это барный сюжет. Это помогает в анализе и сравнении различных функций. В отличие от гистограмм, гистограммы используются для работы с категориальными данными.

Вы можете напрямую применить график к DataFrame или указать параметры внутри функции plt.bar(). Вот как мы это используем.
df = pd.DataFrame (np.random.rand (15, 5), столбцы = ['t1', 't2', 't3', 't4', 't5'])
df.plot.bar ()
Вы также можете использовать гистограмму по горизонтали, используя функцию barh().
Еще один полезный график — коробочная диаграмма. Это помогает понять распределение значений внутри каждой функции. Вы можете использовать функцию plt.boxplot(), чтобы указать данные, на основе которых вы хотите создать коробчатую диаграмму. График особенно полезен, когда вам нужно быстро просмотреть дисперсию в наборе данных или асимметрию. Вот как вы можете его использовать.
plt.boxplot (data_df ['хол'])
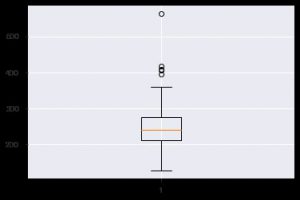
Всякий раз, когда вы работаете со статистическими данными, вы обязательно увидите точечную диаграмму. Диаграмма рассеивания помогает наблюдать взаимосвязь между двумя функциями. Для графика требуются числовые значения как для данных по оси X, так и для оси Y. Вы можете просто указать эти два значения в функции plt.scatter() или можете напрямую применить их к DataFrame, указав имена столбцов в атрибутах x и y. Вот как вы можете это использовать:
plt.scatter(data_df['возраст'], data_df['хол'])
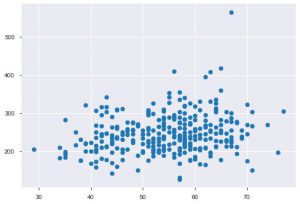
Сейчас самое время познакомить вас с функциями Seaborn. Точечная диаграмма в seaborn более интуитивно понятна, чем matplotlib, потому что она также по умолчанию предоставляет линию регрессии на графике, чтобы лучше визуализировать график. Вы можете использовать функцию sns.lmplot(), чтобы построить этот график.
sns.lmplot('возраст', 'хол', данные=data_df)
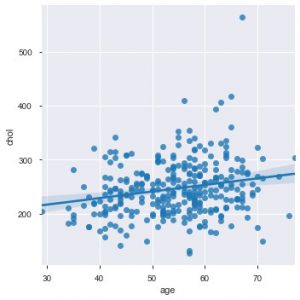
Как вы можете видеть на графике выше, линия регрессии помогает лучше понять распределение.
Еще одно улучшение с использованием Seaborn — это график роя. Он используется для построения категориального графика рассеяния. Одним из преимуществ роевого графика перед аналогичным полосовым графиком является то, что он использует только непересекающиеся точки. Таким образом, это более чистый сюжет и, следовательно, дает лучшее понимание.
sns.swarmplot(data_df['возраст'], data_df['хол'])
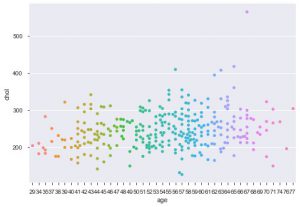
Итак, это разные типы графиков в Matplotlib и Seaborn. Это лишь верхушка айсберга, и существуют сотни других способов графического представления данных для извлечения из них творческих идей.
Теперь, когда вы знаете графики, давайте посмотрим, как проводить фактический анализ данных с помощью python . Мы хотели бы взглянуть на еще несколько графиков и посмотреть, что они показывают нам об анализе данных с использованием python .
Давайте начнем.
После загрузки данных первое, что делает любой аналитик данных, — это создает профиль pandas. Теперь это также можно рассматривать как ярлык, но если вы хотите увидеть все отношения, подсчеты и гистограммы переменных в наборе данных, вы можете использовать профилирование pandas. Его очень легко сгенерировать, просто скачайте модуль pandas-profiling и введите следующий код:
импортировать pandas_profiling
профиль = pandas_profiling.ProfileReport (data_df)
профиль
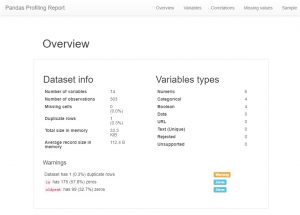
Как вы могли видеть, существует огромное количество метаданных, а также информации об отдельных функциях. Это может привести к большому пониманию.
Второе, что мы можем сделать, это создать тепловую карту. Что делает тепловая карта, так это то, что она показывает корреляцию каждой функции с другой. И если мы находим значение с более высокой корреляцией, это означает, что эти две функции очень похожи друг на друга. Итак, мы можем отказаться от одного из признаков, и все равно модель будет работать нормально.
sns.heatmap(data_df.corr(), annot = True , cmap='Апельсины')
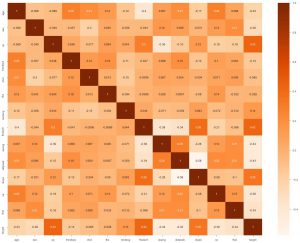
Здесь мы видим, что ни один из них не является тесно связанным, поэтому мы можем сказать инженеру модели, что нам потребуются все функции в качестве входных данных.
Мы можем видеть, каково распределение по возрасту, потому что мы имеем дело с набором данных о сердечных заболеваниях, давайте посмотрим на распределение, чтобы мы могли использовать дистплот морского происхождения.
sns.distplot (data_df ['возраст'], цвет = 'голубой')
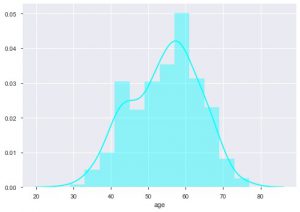
Из графика можно сказать, что большинство людей, страдающих сердечными заболеваниями, находятся в возрасте от 50 до 60 лет. Таким же образом мы можем увидеть и некоторые другие важные характеристики, такие как артериальное давление в состоянии покоя, которое обозначается tresbps. Мы можем построить блочную диаграмму, чтобы увидеть распределение по сравнению с целевым значением, то есть 0 и 1.
sns.boxplot (data_df ['цель'], data_df ['trestbps'], палитра = 'сумерки')
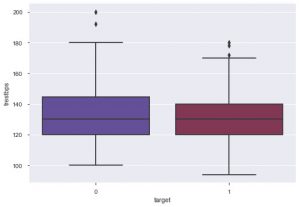
Из графика можно сделать вывод, что если у человека более низкое значение tres bps, то вероятность того, что он будет страдать от сердечно-сосудистых заболеваний, ниже, чем у людей с более высоким значением tres bps.
Точно так же мы можем видеть связь с уровнем холестерина. Мы видим, что у людей с более низким уровнем холестерина меньше шансов страдать сердечными заболеваниями.
Вы можете задокументировать все эти идеи и предоставить их инженеру по машинному обучению, который затем сможет использовать их для создания эффективной модели.
Заключение
Итак, вот как вы можете выполнять анализ данных с помощью python . Это только первый шаг на пути к науке о данных. Чтобы узнать больше об извлечении творческих идей из данных и общей науке о данных, посетите курсы, предлагаемые upGrad, здесь . Вы найдете ряд полезных курсов, которые помогут эффективно проводить анализ данных с использованием Python.
Изучите курсы по науке о данных в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.
Как мне приступить к изучению Python для анализа данных?
Если вы находитесь на пути к изучению Python для анализа данных, то вы находитесь в правильном месте. Вам нужен пошаговый подход, чтобы сделать процесс обучения проще для чего угодно. Вот как выглядит процесс:
1. Четко определите цель изучения Python и то, как вы сможете использовать его в своей области.
2. Загрузите необходимый терминал Python и установите его в своей системе.
3. Начните изучать основы Python, посещая различные курсы и знакомясь с различными библиотеками Python.
4. Ознакомьтесь с регулярными выражениями, используемыми в Python.
5. Получите глубокие знания о различных библиотеках Python, таких как Pandas, NumPy, Matplotlib и SciPy.
6. Начните изучать концепции анализа данных и то, как вы можете интегрировать Python вместе с ним.
7. Теперь вам просто нужно продолжать практиковать различные инструменты и методы, чтобы стать лучше в Python для анализа данных. Выполняя этот пошаговый подход, вы обнаружите, что довольно легко выучить Python и улучшить его для работы с анализом данных.
Как Python используется для анализа данных?
Известно, что Python является очень важным ресурсом для анализа данных. Python по-разному помогает выполнять анализ данных. Но перед этим вам нужно подготовить данные для анализа, выполнить статистический анализ, создать визуализацию данных, которая могла бы дать некоторую информацию, предсказать будущие тенденции на основе доступных данных и многое другое.
Python оказался важнейшим элементом анализа данных, поскольку он помогает:
1. Импорт наборов данных
2.Очистка и подготовка данных для проведения анализа
3. Управление фреймом данных Pandas
4. Обобщение наборов данных
5. Разработка модели машинного обучения для анализа данных с помощью Python
Могу ли я выучить Python за месяц?
Да, вы определенно можете это сделать, если вы владеете любыми другими языками программирования, такими как Java, C, C++ и т. д. Если ваша база ясна, вам будет довольно легко выучить Python даже за один месяц. Кроме того, если вы приложите усилия и дисциплинированно будете следовать пошаговому подходу, вы сможете выучить Python за месяц, даже если у вас нет предварительных знаний о других языках программирования. Вам просто нужно составить расписание и посвятить себя изучению Python в течение месяца.