
Introducere practică în validarea și regularizarea modelelor în Deep Learning folosind TensorFlow
Publicat: 2020-10-28Cuprins
Introducere
Practica mașinilor de a asimila informații prin paradigma algoritmilor de învățare supravegheată a revoluționat mai multe sarcini precum generarea de secvențe, procesarea limbajului natural și chiar viziunea computerizată. Această abordare se bazează pe utilizarea unui set de date care are un set de caracteristici de intrare și un set corespunzător de etichete. Mașina utilizează apoi aceste informații prezente sub formă de caracteristici și etichete pentru a afla distribuția și tiparele datelor pentru a face predicții statistice asupra intrărilor nevăzute.
Un pas esențial în proiectarea modelelor de învățare profundă este evaluarea performanței modelului, în special asupra punctelor de date noi și nevăzute. Scopul cheie este de a dezvolta modele care să se generalizeze dincolo de datele pe care au fost instruiți. Ne dorim modele care pot face predicții bune și de încredere în lumea reală. Un concept important care ne ajută în acest sens este validarea și regularizarea modelului pe care le vom acoperi astăzi.
Validarea modelului
Construirea unui model de învățare automată se rezumă întotdeauna la împărțirea datelor disponibile în trei seturi: instruire, validare și set de testare. Datele de antrenament sunt folosite de model pentru a afla particularitățile și caracteristicile distribuției.
Un punct focal de știut aici este că o performanță satisfăcătoare a modelului pe setul de antrenament nu înseamnă că modelul se va generaliza și pe date noi cu performanțe similare, aceasta deoarece modelul a devenit părtinitor față de setul de antrenament. Conceptul de validare și set de testare este, prin urmare, utilizat pentru a raporta cât de bine se generalizează modelul pe noi puncte de date.
Procedura standard este de a folosi datele de antrenament pentru a se potrivi cu modelul, de a evalua performanța modelului folosind datele de validare și, în final, datele de testare sunt utilizate pentru a afla cât de bine va funcționa modelul pe exemple de-a dreptul noi.
Setul de validare este folosit pentru a regla hiperparametrii (numărul de straturi ascunse, rata de învățare, rata abandonului etc.) astfel încât modelul să se poată generaliza bine. O dificultăți obișnuită cu care se confruntă novicii în învățarea automată este înțelegerea necesității de validare și seturi de testare separate.

Necesitatea a două seturi distincte poate fi înțeleasă prin următoarea intuiție: pentru fiecare rețea neuronală profundă care trebuie proiectată, există un număr mai mare de hiperparametri care trebuie ajustați pentru o performanță satisfăcătoare.
Mai multe modele pot fi antrenate folosind oricare dintre hiperparametri și apoi modelul cu cea mai bună măsură de performanță poate fi selectat pe baza performanței acelui model pe setul de validare. Acum, de fiecare dată când hiperparametrii sunt ajustați pentru o performanță mai bună pe setul de validare, unele informații sunt scurse/introduse în model, prin urmare, ponderile finale ale rețelei neuronale pot deveni părtinitoare față de setul de validare.
După fiecare ajustare a hiperparametrului, modelul nostru continuă să funcționeze bine pe setul de validare, deoarece pentru asta l-am optimizat. Acesta este motivul pentru care testul de validare nu poate denota cu acuratețe capacitatea de generalizare a modelului. Pentru a depăși acest dezavantaj, setul de testare intră în joc.
Cea mai exactă reprezentare a capacității de generalizare a unui model este dată de performanța pe setul de testare, deoarece nu am optimizat modelul pentru o performanță mai bună pe acest set și, prin urmare, aceasta va indica cea mai pragmatică estimare a capacității modelului.
Trebuie să citiți: Top tehnici de învățare profundă despre care ar trebui să știți
Implementarea strategiilor de validare folosind TensorFlow 2.0
TensorFlow 2.0 furnizează o soluție extrem de ușoară pentru a urmări performanța modelului nostru pe un test de validare separat. Putem trece argumentul cheie validation_split în metoda model.fit() .
Cuvântul cheie validation_split primește intrarea ca un număr flotant între 0 și 1, care reprezintă fracțiunea datelor de antrenament care urmează să fie utilizate ca date de validare. Deci, trecerea valorii de 0,1 în cuvântul cheie înseamnă rezervarea a 10% din datele de antrenament pentru validare.
Implementarea practică a diviziunii de validare poate fi demonstrată cu ușurință folosind setul de date pentru diabet de la sklearn. Setul de date are 442 de instanțe cu 10 variabile de bază (vârsta, sex, IMC etc.) ca caracteristici de antrenament și măsura progresiei bolii după un an ca etichetă.
Importăm setul de date folosind TensorFlow și sklearn:

Pasul fundamental după preprocesarea datelor este construirea unei rețele neuronale de tip feedforward secvenţial cu straturi dense:

Aici, avem o rețea neuronală cu șase straturi ascunse cu activare relu și un strat de ieșire cu activare liniară .
Compilăm apoi modelul cu optimizatorul Adam și cu funcția de pierdere a erorii pătrate medii .


Metoda model.fit() este apoi utilizată pentru a antrena modelul pentru 100 de epoci cu un validation_split de 15%.

De asemenea, putem reprezenta grafic pierderea modelului așa cum sa observat atât pentru datele de antrenament, cât și pentru datele de validare:
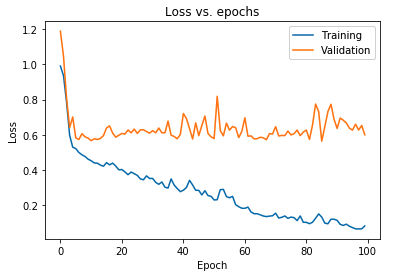
Graficul afișat mai sus arată că pierderea de validare crește continuu după 10 epoci, în timp ce pierderea de antrenament continuă să scadă. Această tendință este un exemplu de manual al unei probleme incredibil de semnificative în învățarea automată, care se numește supraadaptare .
Au fost efectuate o mulțime de cercetări fundamentale pentru a depăși această problemă și, în mod colectiv, aceste soluții sunt numite tehnici de regularizare . Următoarea secțiune va acoperi aspectul regularizării și procedura de regularizare a oricărui model de deep learning.
Regularizarea modelului nostru
În secțiunea anterioară am observat o tendință inversă în diagramele de pierdere ale seturilor de antrenament și validare în care diagrama funcției de cost a celui din urmă set pare să crească și cea a setului anterior continuă să scadă și, prin urmare, creând un decalaj ( decalaj de generalizare ). Aflați mai multe despre regularizarea în învățarea automată.
Faptul că există un astfel de decalaj între cele două diagrame de pierdere simbolizează că modelul nu se poate generaliza bine pe setul de validare ( date nevăzute) și, prin urmare, valoarea costului/pierderii suportată pe acel set de date ar fi, de asemenea, inevitabil mare.
Această particularitate se întâmplă deoarece ponderile și părtinirile modelului antrenat sunt co-adaptate pentru a învăța distribuția datelor de antrenament atât de bine, încât nu reușește să prezică etichetele caracteristicilor noi și nevăzute, ceea ce duce la o pierdere crescută de validare.
Motivul este că configurarea unui model complex va produce astfel de anomalii, deoarece parametrii modelelor devin foarte robusti pentru datele de antrenament. Prin urmare, simplificarea sau reducerea capacității/complexității modelelor va reduce efectul de supraadaptare. O modalitate de a realiza acest lucru este utilizarea abandonului în modelul nostru de învățare profundă, pe care îl vom acoperi în secțiunea următoare.
Înțelegerea și implementarea abandonurilor în TensorFlow
Percepția cheie din spatele utilizării abandonurilor este de a renunța aleatoriu a unităților ascunse și vizibile pentru a obține un model mai puțin complex, care restricționează creșterea parametrilor modelului și, prin urmare, făcând modelul mai robust pentru performanță pe un set de date generalizat.
Această practică recent acceptată este o abordare puternică folosită de practicienii învățării automate pentru a induce un efect de regularizare în orice model de învățare profundă. Renunțările pot fi implementate fără efort folosind API-ul Keras peste TensorFlow, importând stratul de abandon și trecând argumentul ratei în acesta pentru a specifica fracția de unități care trebuie renunțată.
Aceste straturi de abandon sunt, în general, stivuite imediat după fiecare strat dens pentru a produce o maree alternantă a unei arhitecturi de strat dens .
Putem modifica rețeaua neuronală de tip feedforward definită anterior pentru a include șase straturi de abandon , câte unul pentru fiecare strat ascuns:


Aici, rata abandonului _ a fost setată la 0,2, ceea ce înseamnă că 20% dintre noduri vor fi abandonate în timpul antrenării modelului. Compilăm și antrenăm modelul cu același optimizator, funcție de pierdere, metrici și numărul de epoci pentru a face o comparație corectă.
Impactul primar al regularizării modelului folosind abandonuri poate fi interpretat prin trasarea din nou a curbei de pierdere a modelului obținut pe seturile de instruire și validare:
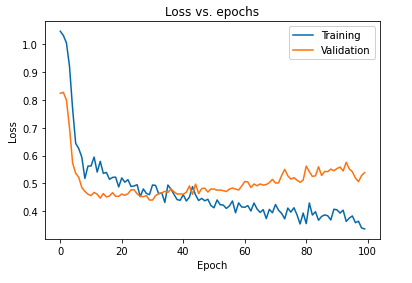
Din graficul de mai sus este evident că decalajul de generalizare obținut după regularizarea modelului este mult mai mic, ceea ce face ca modelul să fie mai puțin susceptibil la supraajustarea datelor de antrenament.
Citește și: Idei de proiecte de învățare profundă
Concluzie
Aspectul validării și regularizării modelului este o parte esențială a proiectării fluxului de lucru al construirii oricărei soluții de învățare automată. Se desfășoară o mulțime de cercetări pentru a improviza învățarea supravegheată, iar acest tutorial practic oferă o scurtă perspectivă asupra unora dintre cele mai acceptate practici și tehnici în timp ce asamblați orice algoritm de învățare.
Dacă sunteți interesat să aflați mai multe despre tehnicile de învățare profundă , învățarea automată, consultați Certificarea PG de la IIIT-B și upGrad în învățare automată și învățare profundă, care este concepută pentru profesioniști care lucrează și oferă peste 240 de ore de formare riguroasă, peste 5 studii de caz & misiuni, statutul de absolvenți IIIT-B și asistență la locul de muncă cu firme de top.