
Analiza datelor folosind Python [Tot ce trebuie să știți]
Publicat: 2020-09-02Pentru oricine dorește să înceapă cu analiza datelor, primul limbaj care îi vine în minte este R sau Python. Iar motivul pentru care dezvoltatorii sunt acum mai înclinați către Python se datorează adaptabilității sale mari în domeniul dezvoltării software generice. Prin urmare, analiza datelor folosind python este unul dintre cei mai auziți termeni pentru cineva care își începe călătoria în știința datelor.
Cuprins
De ce analiza datelor?
Acum, mai întâi, de ce analiza datelor? Ei bine, este primul pas pentru a ști cu ce tip de date lucrați. Este pasul în care găsiți modele valoroase în date, pe care s-ar putea să nu le vedeți altfel. În general, oferă o înțelegere intuitivă a setului de date în mână.
Aici trebuie să trasăm o linie între analiza datelor și preprocesarea datelor. Preprocesarea datelor se ocupă de modelarea setului de date pentru a vă asigura că este pregătit pentru instruire. Analiza datelor este de a înțelege setul de date, care este un pas prealabil pentru preprocesarea datelor. În analiza datelor, încercăm să modelăm datele pentru a le vizualiza mai bine și, prin urmare, să aflăm informații despre setul de date în mână.
De ce Python?
A doua întrebare este, de ce Python? Ei bine, am afirmat deja că Python este un limbaj larg adaptat. Da, nu este singura alegere când vine vorba de analiza datelor, dar este una destul de bună. Un alt motiv este că este folosit mai mult! Python este ușor și are o comunitate mare de dezvoltatori care să vă ajute în ceea ce privește analiza datelor folosind python . Mai mult, analiza datelor folosind Python este destul de plăcută datorită numărului mare de biblioteci creative pe care le oferă pentru analiza și vizualizarea datelor.
În Python, biblioteca de bază pentru analiza datelor este Pandas. Este o bibliotecă de nivel înalt, construită pe biblioteca NumPy, care este pentru calcul științific și analiză numerică. Pandas facilitează lucrul cu date, oferind structura de date, cunoscută sub numele de DataFrame. DataFrame ajută la citirea și stocarea setului de date. Acesta oferă funcțiile de bază pentru citirea și scrierea setului de date, precum și vizualizarea metadatelor și funcțiile de interogare pentru a extrage fiecare informație din setul de date.
Este important de reținut că vizualizarea datelor este o parte considerabilă a analizei generale a datelor. Pentru că nu numai că vă ajută să înțelegeți mai bine datele, ci și celor cărora le oferiți informații. Am discuta despre cele două biblioteci cele mai utilizate pentru vizualizare: Matplotlib și Seaborn. Matplotlib este biblioteca de bază pentru orice vizualizări în Python. Seaborn este, de asemenea, realizat pe lângă Matplotlib, care oferă unele dintre cele mai creative funcții de vizualizare a datelor.
Configurați Mediul
Primul pas este să vă configurați mediul. În timpul analizei datelor folosind python , este important să aveți un mediu adecvat pentru a vă păstra toată munca. Analiza datelor folosind python nu va fi doar un script, ci va fi o interacțiune a dvs. cu setul de date și, pentru aceasta, aveți nevoie de un loc adecvat pentru a lucra.
În python, acel serviciu este furnizat de Anaconda Distribution. Locul de muncă principal al Anaconda este notebook-ul Jupyter. Deci, acum de ce Jupyter? Ei bine, vă permite să aveți vizualizările direct în blocnotes. Are, de asemenea, câteva funcții magice care vă permit să vedeți rezultatul direct, fără a indica în mod explicit unde doriți.
Bibliotecile, Pandas și Matplotlib, vin preinstalate și, prin urmare, nu este necesară o configurare suplimentară pentru utilizarea lor.
Iată rezumatul modului de a face o analiză a datelor folosind Python :
- Încărcarea setului de date
- Vizualizarea metadatelor setului de date folosind Pandas
- Vizualizări de date folosind Matplotlib
- Colectarea de informații despre date
Importați bibliotecile necesare
Înainte de a începe să privim codul pentru pași, doar importați bibliotecile necesare cu pseudoetichete, ca și cu numele pe care le-am numi pentru întregul program.
import numpy ca np
importa panda ca pd
# pentru vizualizarea datelor
import matplotlib.pyplot ca plt
import seaborn ca sns
Acum ne-am uita la fiecare pas și am discuta ce funcții sunt disponibile și cum să le folosim.
În primul rând, citind seturi de date. Pandas oferă câteva funcții de bază pentru încărcarea setului de date în structura sa de bază de date: DataFrame. Îl putem folosi după cum urmează.
data_df = pd.read_csv('heart.csv')
Ieșirea oricărei funcții de citire va fi un DataFrame. În afară de cititoarele CSV, panda oferă cititoare pentru aproape toate tipurile de date. De la HTML la JSON și excel.
În afară de aceasta, dacă nu aveți date ca atare și doriți să vă creați setul de date, puteți utiliza cu ușurință funcțiile obiectelor Pandas' Series și DataFrame.
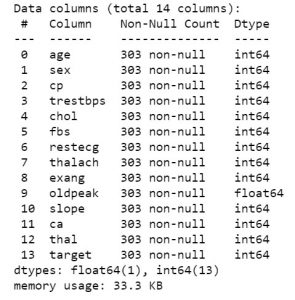
Deci, odată ce aveți datele în mână, să trecem la vizualizarea despre ce este vorba. Pentru a obține prima vizualizare a datelor, puteți utiliza funcții precum df.info sau df.describe pentru a cunoaște structura setului de date.
data_df.info()
data_df.describe()
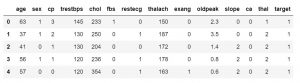
Odată ce știți ce caracteristici conține setul dvs. de date, poate doriți să vă uitați la valorile acestora. Puteți folosi funcția df.head() pentru a obține primele 5 mostre.
data_df.head()
#sau
data_df.head(3)
De asemenea, puteți specifica numărul de mostre pentru a înlocui valoarea implicită de 5. Puteți utiliza și funcția df.tail() pentru a obține ultimele 5 valori ale setului de date.
data_df.tail()
Aceasta este doar pentru a obține o imagine de ansamblu la nivel înalt a cum ar putea arăta datele dvs. Odată gata, puteți începe principalele sarcini de vizualizare a datelor, folosind Matplotlib. Introduceți următorul cod pentru a face plotarea interactivă și vizualizați același lucru în blocnotes.
%matplotlib inline
Am vedea funcționalitățile primelor 5 vizualizări în matplotlib. Înainte de a intra în el, ar trebui să cunoaștem câteva alte funcții care ne controlează parcelele. Funcțiile ca:
- Etichete: xlabel(), ylabel(). Sunt pentru etichetele pe axa x și pe axa y.
- Legendă: Este folosit pentru a crea legenda pentru intriga.
- Titlu: pentru a atribui un titlu pentru parcela dvs
- Și, în sfârșit, afișați funcția pentru a vizualiza complot.
Checkout: Salariu de analist de date în India
Vizualizări
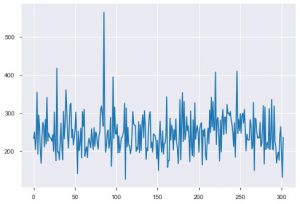
Să vedem vizualizările acum. Am începe cu intriga de bază. plt.plot() este folosit pentru a genera un grafic simplu pentru datele dvs. Funcția necesită doi parametri în compulsion, iar aceștia sunt datele pe axa x și datele pe axa y. Opțional, puteți furniza stilurile și numele și culoarea intrării. Iată cum arată în cod.
plt.plot(data_df['chol'])
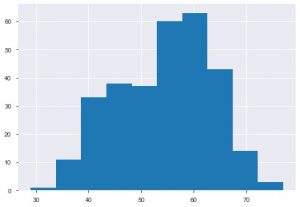
Al doilea complot este Histograma. O histogramă vă ajută să vizualizați frecvența sau distribuția unei anumite caracteristici. Vă ajută să vedeți cum se leagă cantitățile între ele. Plt.hist() este funcția de bază pentru a crea o histogramă pe datele dvs. Puteți menționa parametrul bins pentru a controla numărul de pe parcelă. Trebuie doar să transmiteți o singură axă de date dacă doriți o analiză univariată.
plt.hist(data_df['vârsta'])
Un alt complot pe care l-ai vedea mult este cel al barului. Ajută la analiza și compararea diferitelor caracteristici. Spre deosebire de histograme, diagramele cu bare sunt folosite pentru a lucra cu date categorice.

Puteți aplica direct graficul pe DataFrame sau puteți specifica parametrii în interiorul funcției plt.bar(). Iată cum îl folosim.
df = pd.DataFrame(np.random.rand(15, 5), columns=['t1', 't2', 't3', 't4', 't5'])
df.plot.bar()
De asemenea, puteți utiliza graficul cu bare pe orizontală folosind funcția barh().
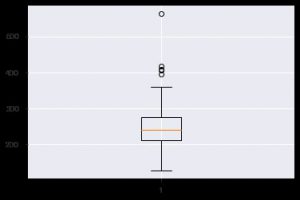
Un alt grafic perspicac este boxplot. Ajută la înțelegerea distribuției valorilor în cadrul fiecărei caracteristici. Puteți utiliza funcția plt.boxplot() pentru a specifica datele pe care doriți să generați un boxplot. Graficul este util în special atunci când trebuie să vizualizați rapid dispersia în setul de date sau asimetria. Iată cum îl puteți folosi.
plt.boxplot(data_df['chol'])
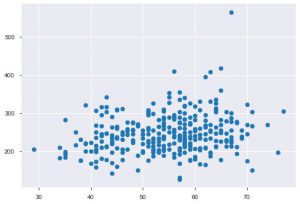
Ori de câte ori lucrați cu date statistice, veți vedea cu siguranță un grafic de dispersie. Un grafic de dispersie ajută la observarea relației dintre două caracteristici. Graficul necesită valori numerice atât pentru datele de pe axa x, cât și pentru axa y. Puteți furniza pur și simplu acele două valori în funcția plt.scatter() sau puteți aplica direct pe DataFrame prin specificarea numelor de coloane în atributele x și y. Iată cum îl puteți folosi:
plt.scatter(data_df['vârsta'], data_df['chol'])
Acum este momentul potrivit pentru a vă prezenta funcțiile Seaborn. Graficul de dispersie în seaborn este mai intuitiv decât matplotlib, deoarece, de asemenea, oferă implicit o linie de regresie în grafic, pentru a vizualiza mai bine graficul. Puteți utiliza funcția sns.lmplot() pentru a realiza acea diagramă.
sns.lmplot('age', 'chol', data=data_df)
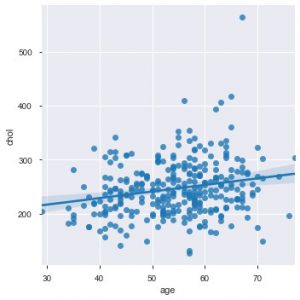
După cum puteți vedea în graficul de mai sus, linia de regresie ajută la înțelegerea distribuției și mai bine.
O altă îmbunătățire folosind seaborn este parcela roiului. Este folosit pentru a desena o diagramă de dispersie categorială. Unul dintre avantajele diagramei roii față de diagrama cu bandă similară este că folosește numai punctele care nu se suprapun. Deci, este o parcelă mai curată și, prin urmare, oferă o perspectivă mai bună.
sns.swarmplot(data_df['vârsta'], data_df['chol'])
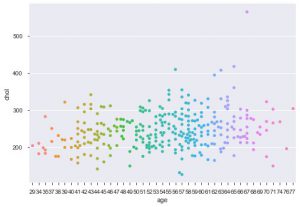
Deci, acestea sunt diferitele tipuri de parcele din Matplotlib și Seaborn. Acesta este doar vârful aisbergului și există sute de alte moduri diferite de a vă reprezenta datele pentru a extrage informații creative despre acestea.
Acum că cunoașteți diagramele, permiteți-ne să vedem cum să facem analiza reală a datelor folosind python . Ne-am uita la mai multe diagrame și am vedea ce ne arată acestea despre analiza datelor folosind python .
Să începem.
După încărcarea datelor, primul lucru pe care îl face orice analist de date acum este să creeze un profil panda. Acum, aceasta poate fi văzută și ca o comandă rapidă, dar dacă doriți să vedeți toate relațiile și numărările și histogramele variabilelor din setul de date, puteți utiliza profilarea panda. Este foarte ușor de generat, trebuie doar să descărcați modulul de profilare a panda și să introduceți următorul cod:
import pandas_profiling
profile = pandas_profiling.ProfileReport(data_df)
profil
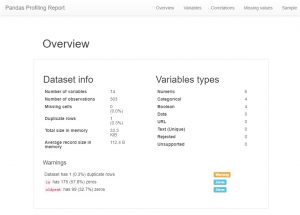
După cum ați putea vedea, există o cantitate imensă de informații despre metadate și, de asemenea, informații despre caracteristicile individuale. Acestea ar putea duce la o mare înțelegere.
Al doilea lucru pe care îl putem face este să generăm o hartă termică. Acum ceea ce face o hartă termică este că arată corelația fiecărei caracteristici cu cealaltă. Și dacă găsim valoare cu o corelație mai mare, asta înseamnă că cele două caracteristici seamănă foarte mult. Deci, putem renunța la una dintre caracteristici și, totuși, modelul va funcționa bine.
sns.heatmap(data_df.corr(), annot = True , cmap='Portocale')
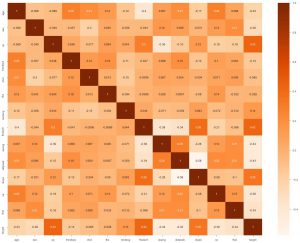
Aici putem vedea că niciuna nu este foarte înrudită, așa că putem spune inginerului de model că am avea nevoie de toate caracteristicile ca intrare.
Putem vedea care este distribuția pe vârstă, deoarece avem de-a face cu setul de date despre bolile de inimă, să vedem distribuția, astfel încât să putem folosi diagrama de distplot a nașterii pe mare.
sns.distplot(data_df['age'], color = 'cyan')
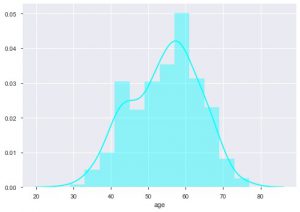
Din intrigă, puteți spune că majoritatea persoanelor care suferă de boli de inimă au vârste cuprinse între 50 și 60 de ani. În același mod, putem vedea și alte caracteristici importante, cum ar fi tensiunea arterială în repaus, care este notă cu tresbps. Putem face un box plot pentru a vedea distribuția, în comparație cu valoarea țintă, adică 0 și 1.
sns.boxplot(data_df['target'], data_df['testbps'], palette = 'twilight')
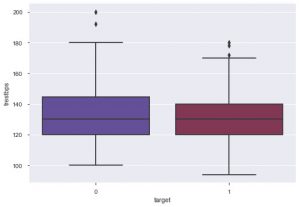
Din diagramă putem concluziona că, dacă persoana are trei bps mai mici, atunci șansele ca acesta să sufere de boli de inimă sunt mai mici decât cele cu o valoare mai mare a tres bps.
În același mod, putem vedea și relația cu nivelul de colesterol. Vedem că oamenii cu niveluri mai mici de colesterol au șanse mai mici de a suferi boli de inimă.
Puteți documenta toate aceste informații și le puteți furniza inginerului de învățare automată, care le poate folosi apoi pentru a realiza un model eficient.
Concluzie
Deci, așa puteți face analiza datelor folosind python . Acesta este doar primul pas în călătoria științei datelor. Pentru a afla mai multe despre extragerea de informații creative din date și din știința generală a datelor, mergeți la cursurile oferite de upGrad aici . Veți găsi un spectru de cursuri utile care vor ghida eficient analiza datelor folosind python.
Învață cursuri de știință a datelor de la cele mai bune universități din lume. Câștigă programe Executive PG, programe avansate de certificat sau programe de master pentru a-ți accelera cariera.
Cum ar trebui să învăț Python pentru analiza datelor?
Dacă sunteți pe cale să învățați Python pentru analiza datelor, atunci sunteți în locul potrivit. Trebuie să aveți o abordare pas cu pas pentru a simplifica procesul de învățare pentru orice. Iată cum arată procesul:
1. Înțelegeți scopul de a învăța Python și cum îl veți putea folosi în domeniul dvs.
2.Descărcați terminalul Python necesar și instalați-l în sistemul dvs.
3. Începeți să învățați elementele de bază ale Python, urmând diferite cursuri și cunoașterea diferitelor biblioteci Python.
4. Familiarizați-vă cu expresiile regulate folosite în Python.
5. Dobândiți cunoștințe aprofundate despre diferite biblioteci Python, cum ar fi Pandas, NumPy, Matplotlib și SciPy.
6. Începeți să învățați conceptele de analiză a datelor și cum puteți integra Python împreună cu acesta.
7. Acum, trebuie doar să continuați să exersați diferite instrumente și tehnici pentru a vă îmbunătăți în Python pentru analiza datelor. Trecând prin această abordare pas cu pas, veți găsi destul de ușor să învățați Python și să vă îmbunătățiți pentru a lucra cu Analiza datelor.
Cum este utilizat Python pentru analiza datelor?
Python este cunoscut a fi o resursă foarte importantă pentru analiza datelor. Python ajută în diferite moduri la efectuarea analizei datelor. Dar înainte de asta, trebuie să pregătiți datele pentru analiză, să efectuați analize statistice, să creați vizualizări de date care ar putea oferi o perspectivă, să preziceți tendințele viitoare pe baza datelor disponibile și multe altele.
Python este considerat a fi un element crucial al analizei datelor, deoarece ajută la:
1. Importul seturi de date
2. Curățarea și pregătirea datelor pentru efectuarea analizei
3. Manipularea Pandas DataFrame
4. Rezumarea seturilor de date
5. Dezvoltarea unui model de Machine Learning pentru analiza datelor cu Python
Pot învăța Python într-o lună?
Da, puteți face acest lucru să se întâmple dacă sunteți competent cu orice alte limbaje de programare precum Java, C, C++ etc. Dacă baza dvs. este clară, veți găsi destul de ușor să învățați Python chiar și într-o singură lună. În afară de asta, dacă depuneți efort și urmați o abordare pas cu pas într-un mod disciplinat, puteți învăța Python într-o lună chiar și atunci când nu aveți cunoștințe anterioare despre alte limbaje de programare. Trebuie doar să stabilești un program și să fii dedicat învățării Python într-o lună.