
Go și provocarea pentru inteligența generală artificială
Publicat: 2018-02-15Acest articol își propune să exploreze legătura dintre jocul „Go” și inteligența artificială. Obiectivul este de a răspunde la întrebările – Ce face jocul Go, special? De ce a fost dificil să stăpânească jocul Go pentru un computer? De ce a fost un program de calculator capabil să învingă un mare maestru de șah în 1997? De ce a durat aproape două decenii pentru a sparge Go?
„Domnilor nu ar trebui să-și piardă timpul cu jocuri banale – ar trebui să studieze Go”
– Confucius
De fapt, expertii în inteligența artificială au crezut că computerele vor putea învinge un campion mondial la Go abia până în 2027. Datorită DeepMind, o companie de inteligență artificială sub umbrela Google, această sarcină formidabilă a fost îndeplinită cu un deceniu mai devreme. Acest articol va vorbi despre tehnologiile folosite de DeepMind pentru a-l învinge pe campionul mondial Go. În cele din urmă, această postare discută despre modul în care această tehnologie poate fi utilizată pentru a rezolva unele probleme complexe, din lumea reală.
Cuprins
Du-te – Ce este?
Go este un joc de masă chinezesc de strategie vechi de 3000 de ani, care și-a păstrat popularitatea de-a lungul veacurilor. Jucat de zeci de milioane de oameni din întreaga lume, Go este un joc de masă pentru doi jucători, cu reguli simple și strategie intuitivă. Pentru a juca acest joc sunt utilizate diferite dimensiuni de tablă; profesioniștii folosesc o tablă 19×19.

Jocul începe cu o tablă goală. Apoi fiecare jucător, pe rând, plasează pietrele alb-negru (negrul este primul) pe tablă, la intersecția liniilor (spre deosebire de șah, unde plasezi piesele în pătrate). Un jucător poate captura pietrele adversarului înconjurându-l din toate părțile. Pentru fiecare piatră capturată, jucătorului i se acordă câteva puncte. Obiectivul jocului este de a ocupa un teritoriu maxim pe tablă împreună cu capturarea pietrelor adversarilor tăi.
Go este despre creație, spre deosebire de șah, care este despre distrugere. Go necesită libertate, creativitate, intuiție, echilibru, strategie și profunzime intelectuală pentru a stăpâni jocul. Jocul Go implică ambele părți ale creierului. De fapt, scanările creierului jucătorilor Go au dezvăluit că Go ajută la dezvoltarea creierului prin îmbunătățirea conexiunilor dintre ambele emisfere ale creierului.
Rețele neuronale pentru manechini: un ghid cuprinzător
Go și provocarea pentru inteligența artificială (AI)
Calculatoarele au reușit să stăpânească Tic-Tac-Toe în 1952 . Deep Blue a reușit să-l învingă pe marele maestru de șah Garry Kasparov în 1997 . Programul pentru computer a reușit să câștige împotriva campionului mondial în Jeopardy (un joc popular american) în 2001 . AlphaGo de la DeepMind a reușit să învingă un campion mondial la Go în 2016 . De ce este considerat o provocare pentru un program de calculator să stăpânească jocul Go?
Șahul se joacă pe o tablă de 8×8, în timp ce Go folosește o tablă de dimensiune 19×19. În deschiderea unui joc de șah, un jucător va avea 20 de mutări posibile. Într-o deschidere Go, un jucător poate avea 361 de mișcări posibile. Numărul de poziții posibile de la bordul Go este egal cu 10 la puterea 170; mai mult decât numărul de atomi din universul nostru! Numărul potențial de poziții pe tablă face ca timpii Googol (10 la puterea 100) să fie mai complexi decât șahul.
La șah, pentru fiecare pas, un jucător se confruntă cu o alegere de 35 de mutări. În medie, un jucător Go va avea 250 de mișcări posibile la fiecare pas. În șah, la orice poziție dată, este relativ ușor pentru un computer să facă căutare cu forță brută și să aleagă cea mai bună mișcare posibilă care maximizează șansele de câștig. O căutare cu forță brută nu este posibilă în cazul Go, deoarece numărul potențial de mișcări legale permise pentru fiecare pas este uriaș.
Pentru ca un computer să stăpânească șahul, devine mai ușor pe măsură ce jocul progresează, deoarece piesele sunt îndepărtate de pe tablă. În Go, devine mai dificil pentru programul de calculator, deoarece pietrele sunt adăugate pe tablă pe măsură ce jocul progresează. De obicei, un joc Go va dura de 3 ori mai mult decât un joc de șah.
Din toate aceste motive, un program de calculator Go de top a reușit să-l ajungă din urmă pe campionul mondial Go abia în 2016, după o explozie uriașă de noi tehnici de învățare automată. Oamenii de știință care lucrează la DeepMind au reușit să vină cu un program de calculator numit AlphaGo care l-a învins pe campionul mondial Lee Seedol . Realizarea sarcinii nu a fost ușoară. Cercetătorii de la DeepMind au venit cu multe inovații noi în procesul de creare a AlphaGo.
„Regulile Go-ului sunt atât de elegante, organice și riguros de logice încât, dacă există forme de viață inteligente în altă parte a universului, aproape sigur că ele joacă Go.”
– Edward Laskar
Rețele neuronale: aplicații în lumea reală
Cum funcționează AlphaGo
AlphaGo este un algoritm de uz general, ceea ce înseamnă că poate fi folosit și pentru rezolvarea altor sarcini. De exemplu, Deep Blue de la IBM este conceput special pentru a juca șah. Regulile de șah împreună cu cunoștințele acumulate din secole de joc sunt programate în creierul programului. Deep Blue nu poate fi folosit nici măcar pentru a juca jocuri banale precum Tic-Tac-Toe. Poate face un singur lucru anume, la care este foarte bun, adică să joace șah. AlphaGo poate învăța să joace și alte jocuri în afară de Go. Acești algoritmi cu scop general constituie un domeniu nou de cercetare, numit Inteligență Generală Artificială.
AlphaGo folosește metode de ultimă generație – Deep Neural Networks (DNN), Reinforcement Learning (RL), Monte Carlo Tree Search (MCTS), Deep Q Networks (DQN) (o tehnică nouă introdusă și popularizată de DeepMind care combină neuronale). rețele cu învățare prin întărire), pentru a numi câteva. Apoi combină toate aceste metode în mod inovator pentru a obține o stăpânire la nivel supraomenesc în jocul Go.
Să ne uităm mai întâi la fiecare piesă individuală a acestui puzzle înainte de a analiza modul în care aceste piese sunt legate între ele pentru a îndeplini sarcina în cauză.
Rețele neuronale profunde
DNN-urile sunt o tehnică de învățare automată, inspirată vag de funcționarea creierului uman. Arhitectura unui DNN constă din straturi de neuroni. DNN poate recunoaște modele în date fără a fi programat în mod explicit pentru aceasta.
Mapează intrările la ieșiri fără ca cineva să le programeze în mod special pentru aceeași. De exemplu, să presupunem că am alimentat rețeaua cu o mulțime de fotografii cu pisici și câini. În același timp, antrenăm și sistemul, spunându-i (sub formă de etichete) dacă o anumită imagine este a unei pisici sau a unui câine (aceasta se numește învățare supravegheată). Un DNN va învăța să recunoască modelul din fotografii pentru a diferenția cu succes între o pisică și un câine. Obiectivul principal al antrenamentului este ca atunci când un DNN vede o nouă imagine fie a unui câine, fie a unei pisici, să fie capabil să o clasifice corect, adică să prezică dacă este o pisică sau un câine.
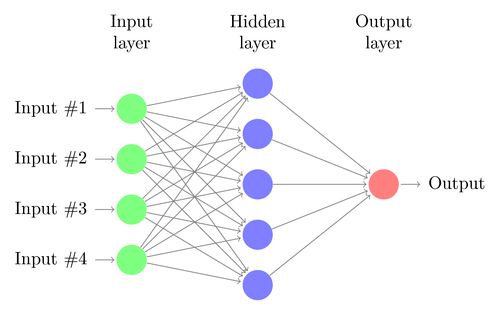
Să înțelegem arhitectura unui simplu DNN. Numărul de neuroni din stratul de intrare corespunde mărimii intrării. Să presupunem că fotografiile noastre cu pisici și câini sunt o imagine de 28×28. Fiecare rând și coloană va fi formată din 28 de pixeli fiecare, ceea ce face un total de 784 de pixeli pentru fiecare imagine. Într-un astfel de caz, stratul de intrare va cuprinde 784 de neuroni, câte unul pentru fiecare pixel. Numărul de neuroni din stratul de ieșire va depinde de numărul de clase în care trebuie clasificată ieșirea. În acest caz, stratul de ieșire va consta din doi neuroni – unul corespunzând „pisica”, celălalt „câine”.
Fiți cu ochii pe următorul lucru important: învățarea automată
Vor exista multe straturi de neuroni între straturile de intrare și de ieșire (care este originea utilizării termenului „Deep” în „Deep Neural Network”). Acestea se numesc „straturi ascunse”. Numărul de straturi ascunse și numărul de neuroni din fiecare strat nu este fix. De fapt, schimbarea acestor valori este exact ceea ce duce la optimizarea performanței. Aceste valori sunt numite hiper-parametri și trebuie reglate în funcție de problema în cauză. Experimentele din jurul rețelelor neuronale implică în mare măsură aflarea numărului optim de hiperparametri.
Faza de antrenament a DNN-urilor va consta dintr-o trecere înainte și o trecere înapoi. În primul rând, toate conexiunile dintre neuroni sunt inițializate cu greutăți aleatorii. În timpul trecerii înainte, rețeaua este alimentată cu o singură imagine. Intrările (date de pixeli din imagine) sunt combinate cu parametrii rețelei (greutăți, părtiniri și funcții de activare) și sunt transmise prin straturi ascunse, până la ieșire, care returnează o probabilitate ca o fotografie să aparțină fiecăruia. a claselor.
Apoi, această probabilitate este comparată cu eticheta reală a clasei și se calculează o „eroare”. În acest moment, se efectuează trecerea înapoi - această informație de eroare este transmisă înapoi prin rețea printr-o tehnică numită „propagare înapoi”. În fazele inițiale de antrenament, această eroare va fi mare, iar un mecanism de antrenament bun va reduce treptat această eroare.
DNN-urile sunt antrenate în acest fel cu o trecere înainte și înapoi până când greutățile nu se mai schimbă (acest lucru este cunoscut sub numele de convergență). Atunci DNN-urile vor putea prezice și clasifica imaginile cu un grad ridicat de acuratețe, adică dacă poza are o pisică sau un câine.

Cercetările ne-au oferit multe arhitecturi diferite de rețele neuronale profunde. Pentru problemele de computer Vision (adică problemele care implică imagini), rețelele neuronale de convoluție (CNN) au dat în mod tradițional rezultate bune. Pentru problemele care implică o secvență – recunoașterea vorbirii sau traducerea limbii – rețelele neuronale recurente (RNN) oferă rezultate excelente.
Un ghid pentru începători pentru înțelegerea limbajului natural
În cazul AlphaGo, procesul a fost următorul: în primul rând, Rețeaua Neurală Convoluție (CNN) a fost instruită pe milioane de imagini ale pozițiilor de bord. În continuare, rețeaua a fost informată despre mișcarea ulterioară jucată de experții umani în fiecare caz în timpul fazei de pregătire a rețelei. În aceeași manieră ca cea menționată mai devreme, valoarea reală a fost comparată cu rezultatul și a fost găsită un fel de metrică de „eroare”.
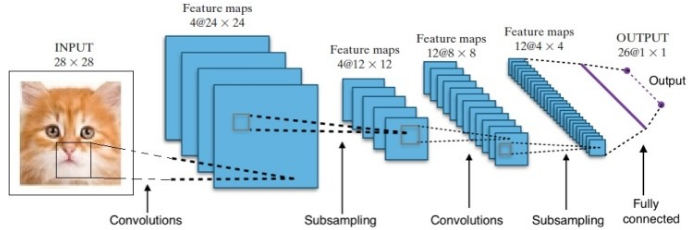
La sfârșitul antrenamentului, DNN va scoate următoarele mișcări împreună cu probabilitățile care probabil vor fi jucate de un jucător uman expert. Acest tip de rețea poate veni doar cu un pas care este jucat de un jucător expert uman. DeepMind a reușit să atingă o precizie de 60% în prezicerea mișcării pe care o va face omul. Cu toate acestea, pentru a învinge un expert uman la Go, acest lucru nu este suficient. Ieșirea de la DNN este procesată în continuare de Deep Reinforcement Network, o abordare concepută de DeepMind, care combină rețelele neuronale profunde și învățarea prin consolidare.
Învățare prin consolidare profundă
Învățarea prin întărire (RL) nu este un concept nou. Laureatul premiului Nobel Ivan Pavlov a experimentat condiționarea clasică pe câini și a descoperit principiile învățării prin întărire în 1902. RL este, de asemenea, una dintre metodele prin care oamenii învață noi abilități. Te-ai întrebat vreodată cum sunt dresați Delfinii din spectacole să sară la înălțimi atât de mari din apă? Este cu ajutorul lui RL. În primul rând, frânghia care este folosită pentru pregătirea delfinilor este scufundată în piscină. Ori de câte ori delfinul traversează cablul de sus, este răsplătit cu mâncare. Când nu trece frânghia, recompensa este retrasă. Încet-încet delfinul va învăța că se plătește ori de câte ori trece de snur de sus. Înălțimea frânghiei crește treptat pentru a antrena delfinul. 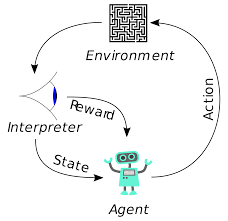
Generarea limbajului natural: cele mai importante lucruri pe care trebuie să le știți
Agenții din învățarea prin întărire sunt, de asemenea, instruiți folosind același principiu. Agentul va lua măsuri și va interacționa cu mediul. Acțiunea întreprinsă de agent determină schimbarea mediului. Mai mult, agentul a primit feedback despre mediu. Agentul este fie recompensat, fie nu, în funcție de acțiunea sa și de obiectivul vizat. Punctul important este că acest obiectiv la îndemână nu este declarat în mod explicit pentru agent. Având suficient timp, agentul va învăța cum să maximizeze recompensele viitoare.

Combinând acest lucru cu DNN-urile, DeepMind a inventat Deep Reinforcement Learning (DRL) sau Deep Q Networks (DQN), unde Q reprezintă recompensele viitoare maxime obținute. DQN-urile au fost aplicate pentru prima dată la jocurile Atari . DQN a învățat cum să joace diferite tipuri de jocuri Atari imediat scoase din cutie. Descoperirea a fost că nu a fost necesară nicio programare explicită pentru reprezentarea diferitelor tipuri de jocuri Atari. Un singur program a fost suficient de inteligent pentru a afla despre toate mediile diferite ale jocului și, prin joc propriu, a putut să stăpânească multe dintre ele.
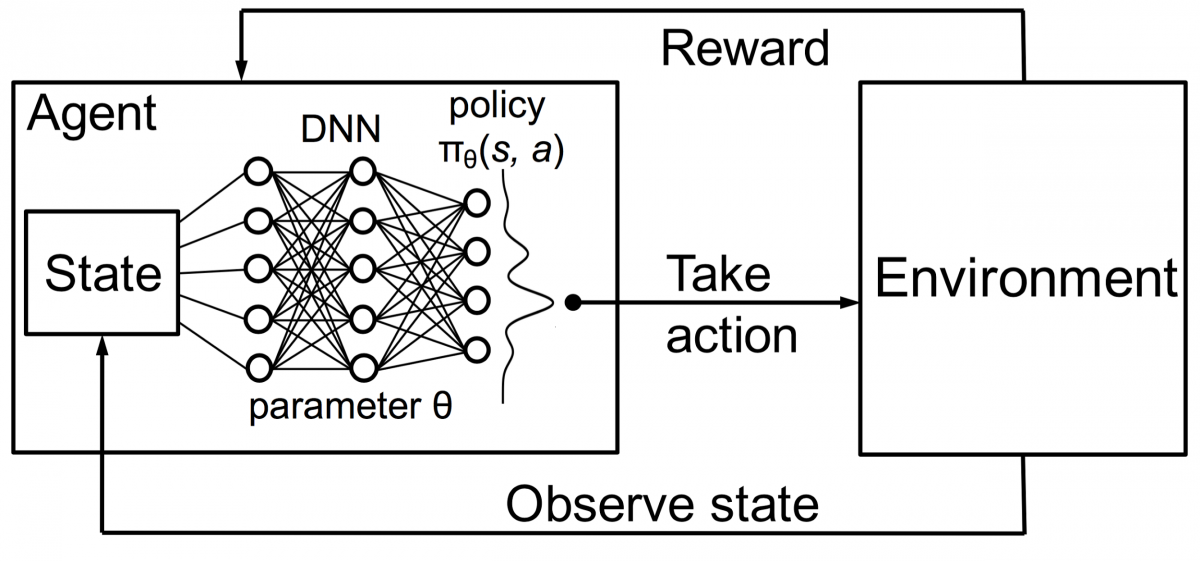
În 2014, DQN a depășit metodele anterioare de învățare automată în 43 din cele 49 de jocuri (acum a fost testat pe mai mult de 70 de jocuri). De fapt, în mai mult de jumătate din jocuri, a avut performanțe la peste 75% din nivelul unui jucător uman profesionist. În anumite jocuri, DQN a venit chiar cu strategii surprinzător de lungimioare care i-au permis să obțină scorul maxim atins - de exemplu, în Breakout , a învățat să sape mai întâi un tunel la un capăt al zidului de cărămidă, astfel încât mingea să sară. în jurul spatelui și elimină cărămizile din spate.
Politici și rețele de valori
Există două tipuri principale de rețele în AlphaGo:
Unul dintre obiectivele DQN-urilor AlphaGo este să depășească jocul de experți uman și să imite noile mișcări inovatoare, jucând împotriva ei de milioane de ori și, prin urmare, îmbunătățind progresiv greutățile. Acest DQN a avut o rată de câștig de 80% față de DNN-urile obișnuite. DeepMind a decis să combine aceste două rețele neuronale (DNN și DQN) pentru a forma primul tip de rețea – o „Rețea de politici”. Pe scurt, sarcina unei rețele de politici este de a reduce amploarea căutării următoarei mișcări și de a veni cu câteva mișcări bune care merită explorate în continuare.
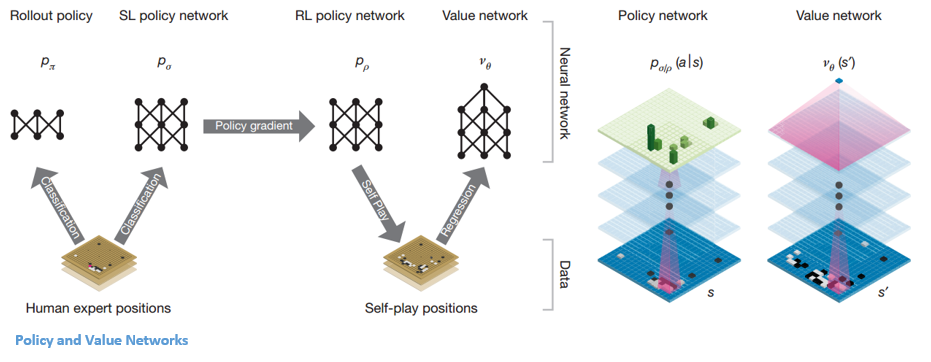 Odată ce rețeaua de politici este înghețată, se joacă împotriva sa de milioane de ori. Aceste jocuri generează un nou set de date Go, constând din diferitele poziții pe tablă și din rezultatele jocurilor. Acest set de date este utilizat pentru a crea o funcție de evaluare. Al doilea tip de funcție – „Rețeaua de valori” este folosită pentru a prezice rezultatul jocului. Învață să ia diverse poziții de tablă ca intrări și să prezică rezultatul jocului și măsura acestuia.
Odată ce rețeaua de politici este înghețată, se joacă împotriva sa de milioane de ori. Aceste jocuri generează un nou set de date Go, constând din diferitele poziții pe tablă și din rezultatele jocurilor. Acest set de date este utilizat pentru a crea o funcție de evaluare. Al doilea tip de funcție – „Rețeaua de valori” este folosită pentru a prezice rezultatul jocului. Învață să ia diverse poziții de tablă ca intrări și să prezică rezultatul jocului și măsura acestuia.
Combinarea rețelelor de politici și valori
După toată această pregătire, DeepMind a ajuns în sfârșit cu două rețele neuronale – Policy and Value Networks. Rețeaua de politici ia poziția consiliului de administrație ca intrare și emite distribuția probabilității ca probabilitatea fiecărei mișcări în acea poziție. Rețeaua de valori preia din nou poziția tablei ca intrare și scoate un singur număr real între 0 și 1. Dacă ieșirea rețelei este zero, înseamnă că albul câștigă complet și 1 indică un câștig complet pentru jucătorul cu negru. pietre.
Rețeaua de politici evaluează pozițiile curente, iar rețeaua de valori evaluează mișcările viitoare. Împărțirea sarcinilor în aceste două rețele de către DeepMind a fost unul dintre motivele majore din spatele succesului AlphaGo.
Combinarea rețelelor de politici și valori cu Monte Carlo Tree Search (MCTS) și lansări
Rețelele neuronale în sine nu vor fi suficiente. Pentru a câștiga jocul Go, este nevoie de mai multă strategie. Acest plan este realizat cu ajutorul MCTS. Monte Carlo Tree Search ajută, de asemenea, la unirea celor două rețele neuronale într-un mod inovator. Rețelele neuronale ajută la căutarea eficientă a următoarei mișcări bune.
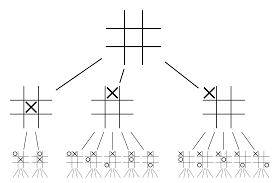
Să încercăm să construim un exemplu care vă va ajuta să vizualizați toate acestea mult mai bine. Imaginează-ți că jocul se află într-o poziție nouă, una care nu a mai fost întâlnită înainte. Într-o astfel de situație, o rețea de politici este chemată să evalueze situația actuală și posibilele căi viitoare; precum și dezirabilitatea căilor și valoarea fiecărei mișcări de către rețelele Value, susținute de lansările Monte Carlo.
Rețeaua de politici găsește toate mișcările „bune” posibile și rețelele de valori evaluează fiecare dintre rezultatele lor. În lansările Monte Carlo, câteva mii de jocuri aleatorii sunt jucate din pozițiile recunoscute de rețeaua de politici. Au fost făcute experimente pentru a determina importanța relativă a rețelelor de valoare față de lansările Monte Carlo. Ca rezultat al acestei experimente, DeepMind a atribuit o pondere de 80% rețelelor Value și o pondere de 20% funcției de evaluare a lansării Monte Carlo.
Rețeaua de politici reduce lățimea căutării de la 200 de mișcări posibile la cele 4 sau 5 cele mai bune. Rețeaua de politici extinde arborele din acești 4 sau 5 pași care necesită luare în considerare. Rețeaua de valori ajută la reducerea adâncimii căutării arborelui, returnând instantaneu rezultatul jocului din acea poziție. În cele din urmă, este selectată mutarea cu cea mai mare valoare Q, adică pasul cu beneficiu maxim.
„ Jocul se joacă în primul rând prin intuiție și simțire și, datorită frumuseții, subtilității și profunzimii intelectuale, a captat imaginația umană de secole.”
– Demis Hassabis
Aplicarea AlphaGo la problemele din lumea reală
Viziunea DeepMind, de pe site-ul lor, este foarte grăitoare – „Rezolvați inteligența. Folosiți aceste cunoștințe pentru a face lumea un loc mai bun”. Scopul final al acestui algoritm este de a-l face cu scop general, astfel încât să poată fi utilizat pentru a rezolva probleme complexe din lumea reală. AlphaGo de la DeepMind este un pas semnificativ înainte în căutarea AGI. DeepMind și-a folosit tehnologia cu succes pentru a rezolva problemele din lumea reală – să ne uităm la câteva exemple:
Reducerea consumului de energie
Inteligența artificială a DeepMind a fost utilizată cu succes pentru a reduce costul de răcire a centrului de date Google cu 40%. În orice mediu consumator de energie la scară largă, această îmbunătățire este un pas înainte fenomenal. Una dintre sursele primare de consum de energie pentru un centru de date este răcirea. O mulțime de căldură generată de rularea serverelor trebuie îndepărtată pentru a-l menține operațional. Acest lucru este realizat de echipamente industriale la scară largă, cum ar fi pompe, răcitoare și turnuri de răcire. Întrucât mediul centrului de date este foarte dinamic, este o provocare să funcționeze la o eficiență energetică optimă. AI-ul DeepMind a fost folosit pentru a rezolva această problemă.
În primul rând, au continuat folosind date istorice, care au fost colectate de mii de senzori din centrul de date. Folosind aceste date, ei au antrenat un ansamblu de DNN-uri în ceea ce privește eficiența medie a consumului de energie în viitor (PUE). Deoarece acesta este un algoritm de uz general, este planificat ca acesta să fie aplicat și altor provocări, în mediul centrului de date.
Posibilele aplicații ale acestei tehnologii includ obținerea mai multă energie de la aceeași unitate de intrare, reducerea energiei de fabricare a semiconductoarelor și a consumului de apă etc. DeepMind a anunțat în postarea pe blog că aceste cunoștințe vor fi împărtășite într-o viitoare publicație, astfel încât alte centre de date, industriale operatorii și în cele din urmă mediul pot beneficia foarte mult de pe urma acestui pas semnificativ.
Planificarea radioterapiei pentru cancerele capului și gâtului
DeepMind a colaborat cu departamentul de radioterapie de la University College London Hospital NHS Foundation Trust, un lider mondial în tratamentul cancerului.
Cum se unesc Big Data și Machine Learning împotriva cancerului
Unul din 75 de bărbați și una din 150 de femei sunt diagnosticați cu cancer oral în timpul vieții. Datorită naturii sensibile a structurilor și organelor din zona capului și gâtului, radiologii trebuie să aibă grijă extremă în timp ce le tratează.
Înainte de administrarea radioterapiei, trebuie pregătită o hartă detaliată cu zonele de tratat și zonele care trebuie evitate. Acest lucru este cunoscut sub numele de segmentare. Această hartă segmentată este introdusă în aparatul de radiografie, care va viza apoi celulele canceroase fără a dăuna celulelor sănătoase.
În cazul cancerului din regiunea capului sau gâtului, aceasta este o muncă migăloasă pentru radiologi, deoarece implică organe foarte sensibile. Este nevoie de aproximativ patru ore pentru ca radiologii să creeze o hartă segmentată pentru această zonă. DeepMind, prin algoritmii săi, își propune să reducă timpul necesar pentru generarea hărților segmentate, de la patru la o oră. Acest lucru va elibera semnificativ timpul radiologului. Mai important, acest algoritm de segmentare poate fi utilizat pentru alte părți ale corpului.
Pentru a rezuma, AlphaGo l-a învins cu succes pe de 18 ori campion mondial la Go, Lee Seedol, de patru ori într-un turneu cel mai bun din cinci în 2016. În 2017, a învins chiar și o echipă a celor mai buni jucători ai lumii. Folosește o combinație de DNN și DQN ca rețea de politici pentru a veni cu următoarea cea mai bună mișcare și un DNN ca rețea de valoare pentru a evalua rezultatul jocului. Căutarea arborescentă Monte Carlo este utilizată împreună cu rețelele de politici și valori pentru a reduce lățimea și adâncimea căutării – acestea sunt folosite pentru a îmbunătăți funcția de evaluare. Scopul final al acestui algoritm nu este de a rezolva jocuri de societate, ci de a inventa un algoritm de Inteligență Generală Artificială. AlphaGo este, fără îndoială, un mare pas înainte în această direcție.
Diferența dintre Data Science, Machine Learning și Big Data!
Desigur, au existat și alte efecte. Pe măsură ce vestea despre AlphaGo Vs Lee Seedol a devenit virală, cererea pentru plăci Go a crescut de zece ori. Multe magazine au raportat cazuri de epuizare a stocului de plăci Go și a devenit dificil să achiziționați o placă Go.
Din fericire, tocmai am găsit unul și l-am comandat pentru mine și copilul meu. Plănuiești să cumperi placa și să înveți Go?
Învață cursuri ML de la cele mai bune universități din lume. Câștigă programe de masterat, Executive PGP sau Advanced Certificate pentru a-ți accelera cariera.
Care sunt limitările învățării prin consolidare profundă?
DL uită de cunoștințele acumulate anterior atunci când sunt introduse date sau informații noi, așa că nu le contestă. Prea multă întărire poate duce uneori la un exces de stări, scăzând eficacitatea. Datorită complexității modelelor de date, instruirea este extrem de costisitoare. Învățarea profundă necesită, de asemenea, utilizarea de GPU-uri scumpe și sute de stații de lucru. Ca urmare, devine mai puțin economic de utilizat.
Care sunt dezavantajele utilizării Monte Carlo Tree Search?
Deși MCTS este un algoritm simplu de executat, are anumite dezavantaje. Când copacul crește după câteva iterații, este nevoie de multă memorie. Când este aplicat la jocurile pe rând, poate exista o singură ramură sau cale care duce la o pierdere împotriva adversarului în anumite condiții. Drept urmare, este puțin mai puțin de încredere. După multe iterații, Monte Carlo Tree Search durează mult pentru a determina calea cea mai eficientă.
Prin ce diferă AlphaZero de AlphaGo Zero?
Versiunile anterioare ale AlphaGo au încorporat un număr mic de caracteristici proiectate manual, dar AlphaGo Zero folosește doar pietrele alb-negru de pe placa Go ca intrare. Versiunile anterioare ale AlphaGo se bazau pe o rețea de politici pentru a alege următoarea mișcare și pe o rețea de valoare pentru a estima câștigătorul jocului din fiecare poziție. Acestea sunt îmbinate în AlphaGo Zero, permițând instruire și evaluare mai eficiente. Toate aceste diferențe contribuie la îmbunătățirea performanței și generalizarea sistemului. Ajustarea algoritmică, pe de altă parte, face sistemul mult mai puternic și mai eficient.