
Análise de dados usando Python [tudo o que você precisa saber]
Publicados: 2020-09-02Para quem quer começar com análise de dados, a primeira linguagem que vem à mente é R ou Python. E a razão pela qual os desenvolvedores estão agora mais inclinados para o Python é devido à sua ampla adaptabilidade no campo genérico de Desenvolvimento de Software. Portanto, a análise de dados usando python é um dos termos mais ouvidos para quem está iniciando sua jornada em Data Science.
Índice
Por que Análise de Dados?
Agora, primeiro, por que Análise de Dados? Bem, é o primeiro passo para saber com que tipo de dados você está trabalhando. É a etapa em que você encontra padrões valiosos nos dados, que talvez não veja de outra forma. No geral, ele fornece uma compreensão intuitiva do conjunto de dados em mãos.
Aqui precisamos traçar uma linha entre a análise de dados e o pré-processamento de dados. O pré-processamento de dados lida com a modelagem do conjunto de dados para garantir que ele esteja pronto para o treinamento. A análise de dados é entender o conjunto de dados, que é uma pré-etapa para o pré-processamento de dados. Na análise de dados, tentamos modelar os dados para visualizá-los melhor e, assim, obter insights sobre o conjunto de dados em mãos.
Por que Python?
A segunda pergunta é: por que Python? Bem, já dissemos que Python é uma linguagem amplamente adaptada. Sim, não é a única escolha quando se trata de análise de dados, mas é muito boa. Outra razão é que é mais usado! Python é fácil e possui uma grande comunidade de desenvolvedores para ajudá-lo na análise de dados usando python . Além disso, a análise de dados usando Python é bastante agradável devido ao grande número de bibliotecas criativas que oferece para análise e visualização de dados.
Em Python, a biblioteca base para análise de dados é o Pandas. É uma biblioteca de alto nível, construída na biblioteca NumPy, que é para computação científica e análise numérica. Os Pandas facilitam o trabalho com dados oferecendo sua estrutura de dados, conhecida como DataFrame. DataFrame ajuda na leitura e armazenamento de seu conjunto de dados. Ele fornece as funções básicas para ler e gravar o conjunto de dados, bem como visualizar os metadados e funções de consulta para extrair todos os insights do conjunto de dados.
É importante notar que a visualização de dados é uma parte considerável da análise geral de dados. Porque não apenas ajuda a entender melhor os dados, mas também para aqueles a quem você está fornecendo os insights. Estaríamos discutindo as duas bibliotecas mais usadas para visualização: Matplotlib e Seaborn. Matplotlib é a biblioteca base para qualquer visualização em Python. Seaborn também é feito em cima do Matplotlib, que oferece algumas das funções de visualização de dados mais criativas.
Configurar ambiente
O primeiro passo é configurar seu ambiente. Ao realizar a análise de dados usando python , é importante ter um ambiente adequado para manter todo o seu trabalho. A análise de dados usando python não será apenas um script, mas uma interação sua com o conjunto de dados e, para isso, você precisa de um local apropriado para trabalhar.
Em python, esse serviço é fornecido pela Distribuição Anaconda. O principal local de trabalho do Anaconda é o notebook Jupyter. Então, agora por que Jupyter? Bem, ele permite que você tenha as visualizações diretamente dentro do seu notebook. Ele também possui algumas funções mágicas que permitem que você veja a saída diretamente sem declarar explicitamente onde deseja.
As bibliotecas, Pandas e Matplotlib, vêm pré-instaladas e, portanto, não há necessidade de configuração extra para usá-las.
Aqui está a sinopse de como contornar a análise de dados usando Python :
- Carregamento do conjunto de dados
- Visualizando os metadados do conjunto de dados usando Pandas
- Visualizações de dados usando Matplotlib
- Coletando insights sobre dados
Importar Bibliotecas Necessárias
Antes de começarmos a olhar o código para as etapas, basta importar as bibliotecas necessárias com pseudo tags, como no nome que as chamaríamos para todo o programa.
importar numpy como np
importar pandas como pd
# para visualizações de dados
importar matplotlib.pyplot como plt
importar seaborn como sns
Agora, examinaríamos cada etapa e discutiríamos quais funções estão disponíveis e como usá-las.
Primeiro, lendo conjuntos de dados. Pandas fornecem algumas funções básicas para carregar o conjunto de dados em sua estrutura de dados principal: DataFrame. Podemos usá-lo da seguinte forma.
data_df = pd.read_csv('heart.csv')
A saída de qualquer função de leitura será um DataFrame. Além dos leitores de CSV, os pandas fornecem leitores para quase todos os tipos de dados. De HTML a JSON e excel.
Além disso, se você não tiver nenhum dado como tal e quiser criar seu conjunto de dados, poderá usar facilmente as funções de objeto Pandas' Series e DataFrame.
Então, uma vez que você tenha os dados em mãos, vamos passar a ver do que se tratam os dados. Para obter a primeira visualização dos dados, você pode usar as funções como df.info ou df.describe para conhecer a estrutura do seu conjunto de dados.
data_df.info()
data_df.describe()
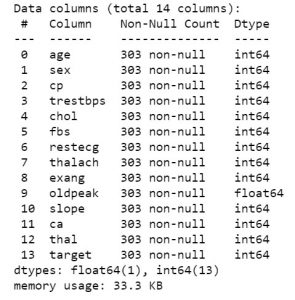
Depois de saber quais recursos seu conjunto de dados contém, convém examinar os valores deles. Você pode usar a função df.head() para obter as primeiras 5 amostras.
data_df.head()
#ou
data_df.head(3)
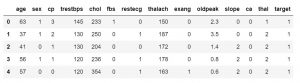
Você também pode especificar o número de amostras para substituir o valor padrão de 5. Você também pode usar a função df.tail() para obter os últimos 5 valores do conjunto de dados.
data_df.tail()
Isso é apenas para obter uma visão geral de alto nível de como seus dados podem parecer. Uma vez pronto, você pode iniciar as principais tarefas de visualização de dados, usando o Matplotlib. Insira o código a seguir para tornar a plotagem interativa e visualize o mesmo em seu próprio notebook.
%matplotlib em linha
Veríamos as funcionalidades das 5 principais visualizações no matplotlib. Antes de entrar nele, devemos conhecer algumas outras funções que controlam nossos gráficos. As funções como:
- Marcadores: xlabel(), ylabel(). Eles são para os rótulos do eixo x e do eixo y.
- Legenda: É usada para fazer a legenda do enredo.
- Título: Para atribuir um título ao seu enredo
- E, finalmente, mostre a função para visualizar o gráfico.
Checkout: Salário de Analista de Dados na Índia
Visualizações
Vamos ver as visualizações agora. Começaríamos com o enredo básico. O plt.plot() é usado para gerar um gráfico de linha simples para seus dados. A função requer dois parâmetros na compulsão, e estes são dados do eixo x e dados do eixo y. Opcionalmente, você pode fornecer os estilos, o nome e a cor da plotagem. Aqui está como fica no código.
plt.plot(data_df['chol'])
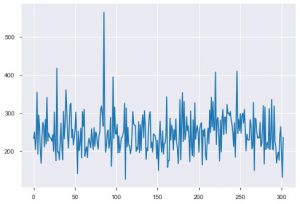
O segundo gráfico é o Histograma. Um histograma ajuda a visualizar a frequência ou distribuição de um determinado recurso. Ele ajuda você a visualizar como as quantidades se relacionam entre si. Plt.hist() é a função base para criar um histograma em seus dados. Você pode mencionar o parâmetro bins para controlar o número no gráfico. Você só precisa passar dados de um único eixo se quiser uma análise univariada.
plt.hist(data_df['idade'])
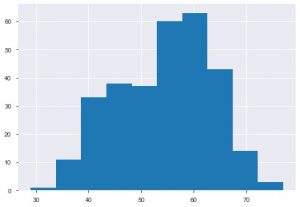

Outro gráfico que você veria muito é o gráfico de barras. Ele ajuda a analisar e comparar diferentes recursos. Ao contrário dos histogramas, os gráficos de barras são usados para trabalhar com dados categóricos.
Você pode aplicar o gráfico diretamente no DataFrame, ou pode especificar os parâmetros dentro da função plt.bar(). Aqui está como nós o usamos.
df = pd.DataFrame(np.random.rand(15, 5), columns=['t1', 't2', 't3', 't4', 't5'])
df.plot.bar()
Você também pode usar o gráfico de barras horizontalmente usando a função barh().
Outro gráfico perspicaz é o boxplot. Ajuda a entender a distribuição de valores dentro de cada recurso. Você pode usar a função plt.boxplot() para especificar os dados nos quais deseja gerar um boxplot. O gráfico é especialmente útil quando você precisa visualizar rapidamente a dispersão no conjunto de dados ou a assimetria. Aqui está como você pode usá-lo.
plt.boxplot(data_df['chol'])
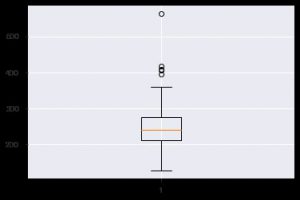
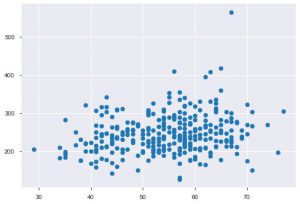
Sempre que você trabalha com dados estatísticos, você definitivamente verá um gráfico de dispersão. Um gráfico de dispersão ajuda a observar a relação entre dois recursos. O gráfico requer valores numéricos tanto para os dados do eixo x quanto para o eixo y. Você pode simplesmente fornecer esses dois valores na função plt.scatter() ou pode aplicar diretamente no DataFrame especificando nomes de coluna nos atributos xey. Aqui está como você pode usar isso:
plt.scatter(data_df['idade'], data_df['chol'])
Agora é um momento apropriado para apresentar as funções do Seaborn. O gráfico de dispersão no seaborn é mais intuitivo que o matplotlib porque também por padrão fornece uma linha de regressão no gráfico, para visualizar melhor o gráfico. Você pode usar a função sns.lmplot() para fazer esse gráfico.
sns.lmplot('age', 'chol', data=data_df)
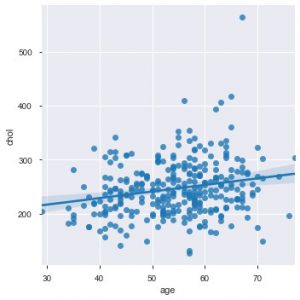
Como você pode ver no gráfico acima, a linha de regressão ajuda a entender ainda melhor a distribuição.
Outra melhoria usando seaborn é a trama de enxame. É usado para desenhar um gráfico de dispersão categórico. Uma das vantagens do gráfico de enxame sobre o gráfico de tiras semelhante é que ele usa apenas os pontos não sobrepostos. Portanto, é um enredo mais limpo e, portanto, fornece uma visão melhor.
sns.swarmplot(data_df['age'], data_df['chol'])
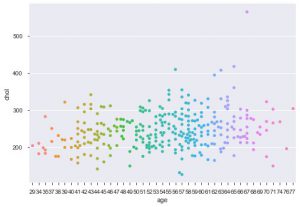
Então, esses são os diferentes tipos de parcelas em Matplotlib e Seaborn. Esta é apenas a ponta do iceberg, e existem centenas de outras maneiras diferentes de plotar seus dados para extrair insights criativos sobre eles.
Agora que você conhece os gráficos, vamos ver como fazer uma análise de dados real usando python . Daríamos uma olhada em mais alguns gráficos e veríamos o que eles nos mostram sobre análise de dados usando python .
Vamos começar.
Depois de carregar os dados, a primeira coisa que qualquer analista de dados faz agora é criar um perfil de pandas. Agora, isso também pode ser visto como um atalho, mas se você quiser ver todos os relacionamentos, contagens e histogramas das variáveis no conjunto de dados, poderá usar o perfil do pandas. É muito fácil de gerar, basta baixar o módulo pandas-profiling e digitar o seguinte código:
importar pandas_profiling
perfil = pandas_profiling.ProfileReport(data_df)
perfil
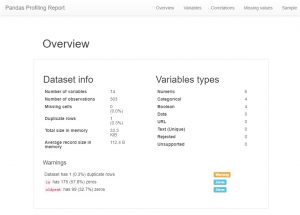
Como você poderá ver, há uma enorme quantidade de informações de metadados e também informações de recursos individuais. Estes podem levar a um grande entendimento.
A segunda coisa que podemos fazer é gerar um mapa de calor. Agora, o que um mapa de calor faz é mostrar a correlação de cada recurso com o outro. E se encontrarmos valor com uma correlação mais alta, isso significa que as duas características se assemelham muito. Assim, podemos descartar um dos recursos e, ainda assim, o modelo funcionará bem.
sns.heatmap(data_df.corr(), annot = True , cmap='Laranjas')
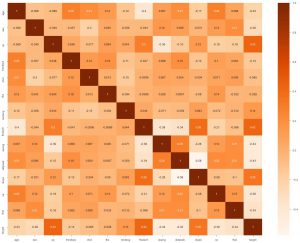
Aqui podemos ver que nenhum está altamente relacionado, então podemos dizer ao engenheiro de modelo que precisaríamos de todos os recursos como entrada.
Podemos ver qual é a distribuição de idade porque estamos lidando com o conjunto de dados de doenças cardíacas, vamos ver a distribuição, para que possamos usar o distplot de seaborn.
sns.distplot(data_df['age'], color = 'cyan')
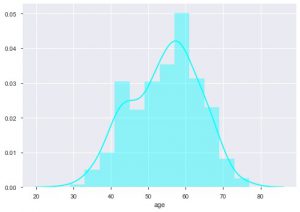
A partir do gráfico, pode-se dizer que a maioria das pessoas que sofrem de doenças cardíacas tem entre 50 e 60 anos. Da mesma forma, também podemos ver algumas outras características importantes como a pressão arterial de repouso, que é denotada por tresbps. Podemos fazer um gráfico de caixa para ver a distribuição, em comparação com o valor alvo, ou seja, 0 e 1.
sns.boxplot(data_df['target'], data_df['trestbps'], paleta = 'crepúsculo')
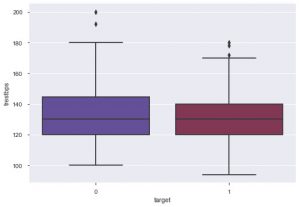
Podemos concluir pelo gráfico que se a pessoa tem tres bps mais baixa, então as chances dela sofrer de doença cardíaca são menores do que aquelas com um valor mais alto de tres bps.
Da mesma forma, também podemos ver a relação com os níveis de colesterol. Vemos pessoas com níveis mais baixos de colesterol terem menor chance de sofrer doenças cardíacas.
Você pode documentar todos esses insights e fornecê-los ao engenheiro de aprendizado de máquina, que pode usar o mesmo para criar um modelo eficiente.
Conclusão
Então, é assim que você pode fazer análise de dados usando python . Este é apenas o primeiro passo na jornada da ciência de dados. Para saber mais sobre como extrair insights criativos de dados e ciência de dados em geral, acesse os cursos oferecidos pelo upGrad aqui . Você encontrará uma variedade de cursos úteis que orientarão efetivamente a análise de dados usando python.
Aprenda cursos de ciência de dados das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.
Como devo aprender Python para Análise de Dados?
Se você está no caminho para aprender Python para Análise de Dados, está no lugar certo. Você precisa ter uma abordagem passo a passo para tornar o processo de aprendizado mais simples para qualquer coisa. Veja como fica o processo:
1. Seja claro com o propósito de aprender Python e como você poderá usá-lo em seu campo.
2. Faça o download do terminal Python necessário e instale-o em seu sistema.
3. Comece a aprender o básico de Python fazendo diferentes cursos e conhecendo diferentes bibliotecas Python.
4. Familiarize-se com as expressões regulares usadas em Python.
5. Adquira conhecimento profundo de diferentes bibliotecas Python, como Pandas, NumPy, Matplotlib e SciPy.
6. Comece a aprender os conceitos de análise de dados e como você pode integrar o Python com ele.
7. Agora, você só precisa continuar praticando diferentes ferramentas e técnicas para melhorar o Python para Análise de Dados. Ao seguir essa abordagem passo a passo, você achará muito fácil aprender Python e melhorar para trabalhar com Análise de Dados.
Como o Python é usado para análise de dados?
Python é conhecido por ser um recurso muito importante para análise de dados. O Python ajuda de diferentes maneiras para realizar a análise de dados. Mas antes disso, você precisa preparar os dados para análise, realizar análises estatísticas, criar visualizações de dados que possam fornecer alguns insights, prever as tendências futuras com base nos dados disponíveis e muito mais.
O Python é considerado um elemento crucial da análise de dados, pois ajuda em:
1. Importando conjuntos de dados
2.Limpar e preparar os dados para realizar a análise
3. Manipulando o DataFrame do Pandas
4. Resumindo os conjuntos de dados
5. Desenvolvendo um modelo de Machine Learning para análise de dados com Python
Posso aprender Python em um mês?
Sim, você pode definitivamente fazer isso acontecer se você for proficiente em qualquer outra linguagem de programação como Java, C, C++, etc. Se sua base for clara, você achará muito fácil aprender Python mesmo em um único mês. Fora isso, se você se esforçar e seguir uma abordagem passo a passo de forma disciplinada, poderá aprender Python em um mês mesmo sem ter conhecimento prévio de outras linguagens de programação. Você só precisa definir um cronograma e se dedicar a aprender Python em um mês.