
Go e o Desafio para a Inteligência Artificial Geral
Publicados: 2018-02-15Este artigo tem como objetivo explorar a conexão entre o jogo 'Go' e a inteligência artificial. O objetivo é responder às perguntas – O que torna o jogo de Go especial? Por que dominar o jogo de Go foi difícil para um computador? Por que um programa de computador foi capaz de vencer um grande mestre de xadrez em 1997? Por que demorou quase duas décadas para quebrar o Go?
“Os cavalheiros não devem perder tempo com jogos triviais – eles devem estudar Go”
– Confúcio
Na verdade, especialistas em inteligência artificial pensavam que os computadores só seriam capazes de vencer um campeão mundial de Go em 2027. Graças à DeepMind, uma empresa de inteligência artificial sob o guarda-chuva do Google, essa tarefa formidável foi alcançada uma década antes. Este artigo falará sobre as tecnologias usadas pela DeepMind para vencer o campeão mundial de Go. Por fim, este post discute como essa tecnologia pode ser usada para resolver alguns problemas complexos do mundo real.
Índice
Vá – O que é?
Go é um jogo de tabuleiro de estratégia chinês de 3000 anos, que manteve sua popularidade ao longo dos tempos. Jogado por dezenas de milhões de pessoas em todo o mundo, Go é um jogo de tabuleiro para dois jogadores com regras simples e estratégia intuitiva. Diferentes tamanhos de tabuleiro estão em uso para jogar este jogo; profissionais usam uma prancha 19×19.

O jogo começa com um tabuleiro vazio. Cada jogador então se reveza para colocar as pedras pretas e brancas (o preto vai primeiro) no tabuleiro, na interseção das linhas (ao contrário do xadrez, onde você coloca as peças nas casas). Um jogador pode capturar as pedras do oponente cercando-o por todos os lados. Para cada pedra capturada, alguns pontos são concedidos ao jogador. O objetivo do jogo é ocupar o máximo de território no tabuleiro, além de capturar as pedras de seus oponentes.
Go é sobre criação, ao contrário de Chess, que é sobre destruição. Go requer liberdade, criatividade, intuição, equilíbrio, estratégia e profundidade intelectual para dominar o jogo. Jogar Go envolve os dois lados do cérebro. De fato, as varreduras cerebrais dos jogadores de Go revelaram que o Go ajuda no desenvolvimento do cérebro, melhorando as conexões entre os dois hemisférios cerebrais.
Redes neurais para leigos: um guia completo
Go e o desafio da inteligência artificial (IA)
Os computadores foram capazes de dominar o Tic-Tac-Toe em 1952 . Deep Blue foi capaz de vencer o grande mestre de xadrez Garry Kasparov em 1997 . O programa de computador conseguiu vencer o campeão mundial em Jeopardy (um popular jogo americano) em 2001 . O AlphaGo da DeepMind foi capaz de derrotar um campeão mundial de Go em 2016 . Por que é considerado um desafio para um programa de computador dominar o jogo Go?
O xadrez é jogado em um tabuleiro de 8×8, enquanto o Go usa um tabuleiro de tamanho 19×19. Na abertura de um jogo de xadrez, um jogador terá 20 movimentos possíveis. Em uma abertura de Go, um jogador pode ter 361 movimentos possíveis. O número de posições possíveis no tabuleiro de Go é igual a 10 elevado a 170; mais do que o número de átomos em nosso universo! O número potencial de posições no tabuleiro torna Go googol vezes (10 elevado a 100) mais complexo que o xadrez.
No xadrez, para cada passo, um jogador se depara com uma escolha de 35 movimentos. Em média, um jogador de Go terá 250 movimentos possíveis em cada etapa. No xadrez, em qualquer posição, é relativamente fácil para um computador fazer uma busca de força bruta e escolher o melhor movimento possível que maximize as chances de ganhar. Uma busca de força bruta não é possível no caso de Go, pois o número potencial de movimentos legais permitidos para cada etapa é enorme.
Para um computador dominar o xadrez, torna-se mais fácil à medida que o jogo avança porque as peças são removidas do tabuleiro. Em Go, torna-se mais difícil para o programa de computador à medida que as pedras são adicionadas ao tabuleiro à medida que o jogo avança. Normalmente, uma partida de Go dura 3 vezes mais do que uma partida de xadrez.
Por todas essas razões, um programa de computador Go de ponta só conseguiu alcançar o campeão mundial Go em 2016, após uma enorme explosão de novas técnicas de aprendizado de máquina. Os cientistas que trabalham na DeepMind conseguiram criar um programa de computador chamado AlphaGo que derrotou o campeão mundial Lee Seedol . Não foi fácil cumprir a tarefa. Os pesquisadores da DeepMind apresentaram muitas inovações no processo de criação do AlphaGo.
“As regras de Go são tão elegantes, orgânicas e rigorosamente lógicas que, se formas de vida inteligentes existem em outro lugar do universo, elas quase certamente jogam Go.”
– Eduardo Laskar
Redes neurais: aplicações no mundo real
Como funciona o AlphaGo
AlphaGo é um algoritmo de uso geral, o que significa que pode ser usado para resolver outras tarefas também. Por exemplo, Deep Blue da IBM é projetado especificamente para jogar xadrez. As regras do xadrez, juntamente com o conhecimento acumulado de séculos de jogo, são programadas no cérebro do programa. Deep Blue não pode ser usado nem para jogos triviais como Tic-Tac-Toe. Ele pode fazer apenas uma coisa específica, na qual é muito bom, ou seja, jogar xadrez. AlphaGo pode aprender a jogar outros jogos além do Go. Esses algoritmos de propósito geral constituem um novo campo de pesquisa, chamado Inteligência Artificial Geral.
AlphaGo usa métodos de última geração – Deep Neural Networks (DNN), Reinforcement Learning (RL), Monte Carlo Tree Search (MCTS), Deep Q Networks (DQN) (uma nova técnica introduzida e popularizada pela DeepMind que combina redes com aprendizado por reforço), para citar alguns. Em seguida, combina todos esses métodos de forma inovadora para alcançar o domínio do nível sobre-humano no jogo de Go.
Vamos primeiro olhar para cada peça individual deste quebra-cabeça antes de entrar em como essas peças são amarradas para realizar a tarefa em mãos.
Redes neurais profundas
As DNNs são uma técnica para realizar aprendizado de máquina, vagamente inspirada no funcionamento do cérebro humano. A arquitetura de uma DNN consiste em camadas de neurônios. DNN pode reconhecer padrões em dados sem ser explicitamente programado para isso.
Ele mapeia as entradas para as saídas sem que ninguém o programe especificamente para o mesmo. Como exemplo, vamos supor que alimentamos a rede com muitas fotos de gatos e cachorros. Ao mesmo tempo, também estamos treinando o sistema informando (na forma de rótulos) se uma determinada imagem é de um gato ou de um cachorro (isso é chamado de aprendizado supervisionado). Um DNN aprenderá a reconhecer o padrão das fotos para diferenciar com sucesso um gato e um cachorro. O principal objetivo do treinamento é que, quando uma DNN vê uma nova imagem de um cachorro ou de um gato, seja capaz de classificá-la corretamente, ou seja, prever se é um gato ou um cachorro.
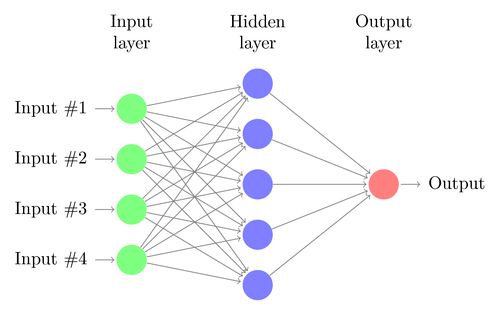
Vamos entender a arquitetura de um DNN simples. O número de neurônios na camada de entrada corresponde ao tamanho da entrada. Vamos supor que nossas fotos de cães e gatos sejam uma imagem 28×28. Cada linha e coluna terá 28 pixels cada, o que perfaz um total de 784 pixels para cada imagem. Nesse caso, a camada de entrada será composta por 784 neurônios, um para cada pixel. O número de neurônios na camada de saída dependerá do número de classes nas quais a saída precisa ser classificada. Neste caso, a camada de saída será composta por dois neurônios – um correspondendo a 'gato' e o outro a 'cachorro'.
Fique de olho na próxima grande novidade: aprendizado de máquina
Haverá muitas camadas de neurônios entre as camadas de entrada e saída (que é a origem do uso do termo 'Deep' em 'Deep Neural Network'). Estas são chamadas de “camadas ocultas”. O número de camadas ocultas e o número de neurônios em cada camada não são fixos. Na verdade, alterar esses valores é exatamente o que leva à otimização do desempenho. Esses valores são chamados de hiperparâmetros e precisam ser ajustados de acordo com o problema em questão. Os experimentos em torno das redes neurais envolvem em grande parte descobrir o número ideal de hiperparâmetros.
A fase de treinamento de DNNs consistirá em um passe para frente e um passe para trás. Primeiro, todas as conexões entre os neurônios são inicializadas com pesos aleatórios. Durante a passagem direta, a rede é alimentada com uma única imagem. As entradas (dados de pixel da imagem) são combinadas com os parâmetros da rede (pesos, bias e funções de ativação) e alimentadas através de camadas ocultas, até a saída, que retorna uma probabilidade de uma foto pertencente a cada das aulas.
Em seguida, essa probabilidade é comparada com o rótulo da classe real e um “erro” é calculado. Nesse ponto, a passagem para trás é executada – essas informações de erro são passadas de volta pela rede por meio de uma técnica chamada “back-propagation”. Durante as fases iniciais de treinamento, esse erro será alto e um bom mecanismo de treinamento reduzirá gradualmente esse erro.
As DNNs são treinadas dessa maneira com uma passagem para frente e para trás até que os pesos parem de mudar (isso é conhecido como convergência). Então as DNNs poderão prever e classificar as imagens com alto grau de precisão, ou seja, se a imagem tem um gato ou um cachorro.

A pesquisa nos deu muitas arquiteturas de redes neurais profundas diferentes. Para problemas de Visão Computacional (ou seja, problemas envolvendo imagens), as Redes Neurais de Convolução (CNNs) tradicionalmente têm dado bons resultados. Para questões que envolvem uma sequência – reconhecimento de fala ou tradução de idioma – as Redes Neurais Recorrentes (RNN) fornecem excelentes resultados.
Um guia para iniciantes para compreensão de linguagem natural
No caso do AlphaGo, o processo foi o seguinte: primeiro, a Rede Neural de Convolução (CNN) foi treinada em milhões de imagens de cargos de diretoria. Em seguida, a rede foi informada sobre o movimento subsequente realizado pelos especialistas humanos em cada caso durante a fase de treinamento da rede. Da mesma forma como mencionado anteriormente, o valor real foi comparado com a saída e algum tipo de métrica de “erro” foi encontrado.
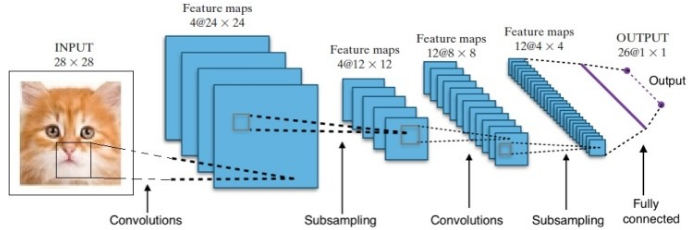
No final do treinamento, o DNN produzirá os próximos movimentos junto com as probabilidades que provavelmente serão jogadas por um jogador humano experiente. Este tipo de rede só pode surgir com um passo que é jogado por um jogador especialista humano. A DeepMind conseguiu atingir uma precisão de 60% na previsão do movimento que o humano faria. No entanto, para vencer um especialista humano em Go, isso não é suficiente. A saída da DNN é processada posteriormente pela Deep Reinforcement Network, uma abordagem concebida pela DeepMind, que combina redes neurais profundas e aprendizado por reforço.
Aprendizado por Reforço Profundo
A aprendizagem por reforço (RL) não é um conceito novo. O prêmio Nobel Ivan Pavlov experimentou o condicionamento clássico em cães e descobriu os princípios do aprendizado por reforço em 1902. A RL também é um dos métodos com os quais os humanos aprendem novas habilidades. Você já se perguntou como os golfinhos nos shows são treinados para saltar a alturas tão grandes fora da água? É com a ajuda de RL. Primeiro, a corda que é usada para preparar os golfinhos é submersa na piscina. Sempre que o golfinho cruza o cabo de cima, é recompensado com comida. Quando não cruza a corda a recompensa é retirada. Lentamente, o golfinho aprenderá que é pago sempre que passar a corda de cima. A altura da corda é aumentada gradualmente para treinar o golfinho. 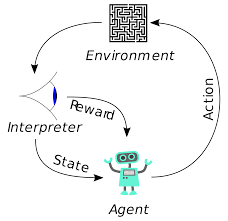
Geração de linguagem natural: principais coisas que você precisa saber
Os agentes no aprendizado por reforço também são treinados usando o mesmo princípio. O agente irá agir e interagir com o ambiente. A ação tomada pelo agente faz com que o ambiente mude. Além disso, o agente recebeu feedback sobre o ambiente. O agente é recompensado ou não, dependendo de sua ação e do objetivo em questão. O ponto importante é que esse objetivo em questão não é explicitamente declarado para o agente. Com tempo suficiente, o agente aprenderá a maximizar as recompensas futuras.

Combinando isso com DNNs, a DeepMind inventou Deep Reinforcement Learning (DRL) ou Deep Q Networks (DQN), onde Q significa o máximo de recompensas futuras obtidas. DQNs foram aplicados pela primeira vez aos jogos Atari . DQN aprendeu a jogar diferentes tipos de jogos Atari imediatamente. A descoberta foi que nenhuma programação explícita era necessária para representar diferentes tipos de jogos Atari. Um único programa foi inteligente o suficiente para aprender sobre todos os diferentes ambientes do jogo e, por meio do autojogo, conseguiu dominar muitos deles.
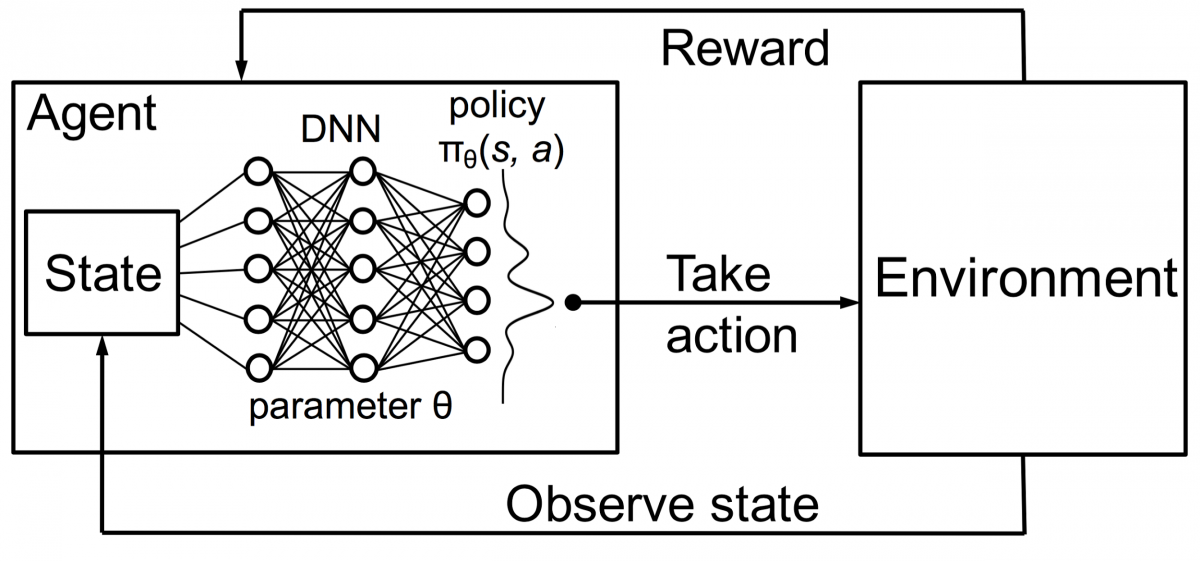
Em 2014, o DQN superou os métodos anteriores de aprendizado de máquina em 43 dos 49 jogos (agora foi testado em mais de 70 jogos). De fato, em mais da metade dos jogos, ele teve um desempenho superior a 75% do nível de um jogador humano profissional. Em certos jogos, o DQN até apresentou estratégias surpreendentemente perspicazes que lhe permitiram atingir a pontuação máxima alcançável - por exemplo, em Breakout , ele aprendeu a cavar primeiro um túnel em uma extremidade da parede de tijolos, para que a bola quicasse nas costas e derrube os tijolos por trás.
Política e Redes de Valor
Existem dois tipos principais de redes dentro do AlphaGo:
Um dos objetivos dos DQNs do AlphaGo é ir além do jogo de especialista humano e imitar novos movimentos inovadores, jogando contra si mesmo milhões de vezes e, assim, melhorando os pesos de forma incremental. Este DQN teve uma taxa de vitória de 80% contra DNNs comuns. A DeepMind decidiu combinar essas duas redes neurais (DNN e DQN) para formar o primeiro tipo de rede – uma 'Policy Network'. Resumidamente, o trabalho de uma rede de políticas é reduzir a amplitude da busca pelo próximo movimento e apresentar alguns bons movimentos que valem a pena ser explorados.
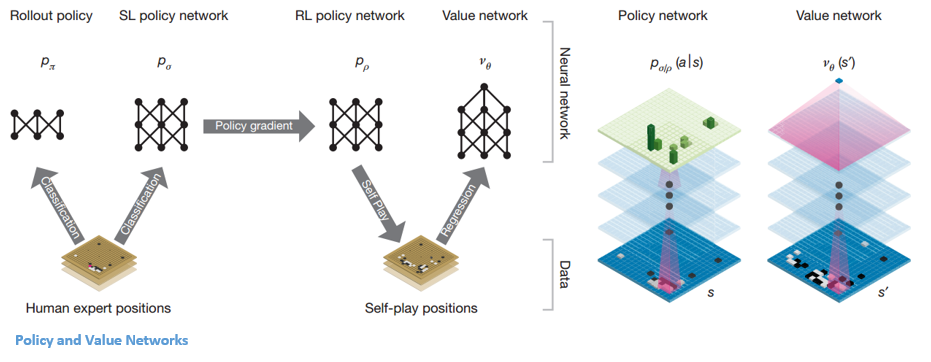 Uma vez que a rede de políticas é congelada, ela joga contra si mesma milhões de vezes. Esses jogos geram um novo conjunto de dados Go, composto pelas várias posições do tabuleiro e os resultados dos jogos. Este conjunto de dados é usado para criar uma função de avaliação. O segundo tipo de função – a 'Rede de Valor' é usada para prever o resultado do jogo. Ele aprende a tomar várias posições no tabuleiro como entradas e a prever o resultado do jogo e a medida dele.
Uma vez que a rede de políticas é congelada, ela joga contra si mesma milhões de vezes. Esses jogos geram um novo conjunto de dados Go, composto pelas várias posições do tabuleiro e os resultados dos jogos. Este conjunto de dados é usado para criar uma função de avaliação. O segundo tipo de função – a 'Rede de Valor' é usada para prever o resultado do jogo. Ele aprende a tomar várias posições no tabuleiro como entradas e a prever o resultado do jogo e a medida dele.
Combinando a Política e as Redes de Valor
Depois de todo esse treinamento, a DeepMind finalmente acabou com duas redes neurais – Policy e Value Networks. A rede de políticas toma a posição do conselho como entrada e produz a distribuição de probabilidade como a probabilidade de cada um dos movimentos nessa posição. A rede de valor novamente assume a posição do tabuleiro como entrada e emite um único número real entre 0 e 1. Se a saída da rede for zero, significa que o branco está vencendo completamente e 1 indica uma vitória completa para o jogador com o preto pedras.
A rede de políticas avalia as posições atuais e a rede de valor avalia os movimentos futuros. A divisão de tarefas nessas duas redes pela DeepMind foi um dos principais motivos do sucesso do AlphaGo.
Combinando Redes de Políticas e Valores com Pesquisa em Árvore de Monte Carlo (MCTS) e Rollouts
As redes neurais por si só não serão suficientes. Para vencer o jogo de Go, é necessário um pouco mais de estratégia. Este plano é alcançado com a ajuda do MCTS. O Monte Carlo Tree Search também ajuda a unir as duas redes neurais de uma maneira inovadora. As redes neurais auxiliam na busca eficiente da próxima melhor jogada.
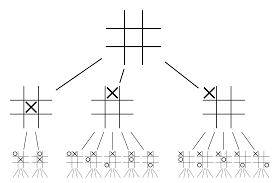
Vamos tentar construir um exemplo que o ajudará a visualizar tudo isso muito melhor. Imagine que o jogo está em uma nova posição, que não foi encontrada antes. Em tal situação, uma rede de políticas é chamada para avaliar a situação atual e possíveis caminhos futuros; bem como a conveniência dos caminhos e o valor de cada movimento pelas redes de Valor, apoiados por rollouts de Monte Carlo.
A rede de políticas encontra todos os movimentos “bons” possíveis e as redes de valor avaliam cada um de seus resultados. Nos lançamentos de Monte Carlo, alguns milhares de jogos aleatórios são jogados a partir das posições reconhecidas pela rede de políticas. Experimentos foram feitos para determinar a importância relativa das redes de valor em relação aos lançamentos de Monte Carlo. Como resultado dessa experimentação, a DeepMind atribuiu 80% de ponderação às redes Value e 20% de ponderação à função de avaliação de lançamento de Monte Carlo.
A rede de políticas reduz a largura da pesquisa de 200 movimentos possíveis para os 4 ou 5 melhores movimentos. A rede de políticas expande a árvore a partir dessas 4 ou 5 etapas que precisam ser consideradas. A rede de valor ajuda a reduzir a profundidade da busca na árvore, retornando instantaneamente o resultado do jogo a partir dessa posição. Finalmente, o movimento com o maior valor de Q é selecionado, ou seja, o passo com o máximo benefício.
“ O jogo é jogado principalmente através da intuição e do sentimento, e por causa de sua beleza, sutileza e profundidade intelectual, capturou a imaginação humana por séculos.”
– Demis Hassabis
Aplicação do AlphaGo a problemas do mundo real
A visão da DeepMind, de seu site, é muito reveladora – “Resolva inteligência. Use esse conhecimento para tornar o mundo um lugar melhor”. O objetivo final deste algoritmo é torná-lo de uso geral para que possa ser usado para resolver problemas complexos do mundo real. O AlphaGo da DeepMind é um passo significativo na busca pela AGI. A DeepMind usou sua tecnologia com sucesso para resolver problemas do mundo real – vejamos alguns exemplos:
Redução no consumo de energia
A IA da DeepMind foi utilizada com sucesso para reduzir o custo de refrigeração do data center do Google em 40%. Em qualquer ambiente de consumo de energia em grande escala, esta melhoria é um passo fenomenal em frente. Uma das principais fontes de consumo de energia para um data center é o resfriamento. Muito calor gerado pela execução dos servidores precisa ser removido para mantê-lo operacional. Isso é realizado por equipamentos industriais de grande escala, como bombas, resfriadores e torres de resfriamento. Como o ambiente do data center é muito dinâmico, é um desafio operar com eficiência energética ideal. A IA do DeepMind foi usada para resolver esse problema.
Primeiro, eles continuaram usando dados históricos, que foram coletados por milhares de sensores dentro do data center. Usando esses dados, eles treinaram um conjunto de DNNs na Eficácia de Uso de Energia (PUE) futura média. Como este é um algoritmo de uso geral, está previsto que ele seja aplicado a outros desafios também, no ambiente de data center.
As possíveis aplicações desta tecnologia incluem obter mais energia da mesma unidade de entrada, reduzir o uso de energia e água na fabricação de semicondutores, etc. A DeepMind anunciou em seu blog que esse conhecimento seria compartilhado em uma publicação futura para que outros data centers, operadores e, em última análise, o meio ambiente podem se beneficiar muito com este passo significativo.
Planejamento de radioterapia para câncer de cabeça e pescoço
A DeepMind colaborou com o departamento de radioterapia do NHS Foundation Trust do University College London Hospital, líder mundial em tratamento de câncer.
Como Big Data e Machine Learning estão se unindo contra o câncer
Um em cada 75 homens e uma em cada 150 mulheres são diagnosticados com câncer bucal durante a vida. Devido à natureza sensível das estruturas e órgãos na área da cabeça e pescoço, os radiologistas precisam ter extremo cuidado ao tratá-los.
Antes de administrar a radioterapia, é necessário preparar um mapa detalhado com as áreas a serem tratadas e as áreas a serem evitadas. Isso é conhecido como segmentação. Este mapa segmentado é alimentado na máquina de radiografia, que então terá como alvo as células cancerígenas sem prejudicar as células saudáveis.
No caso do câncer da região da cabeça ou pescoço, este é um trabalho árduo para os radiologistas, pois envolve órgãos muito sensíveis. Demora cerca de quatro horas para os radiologistas criarem um mapa segmentado para esta área. A DeepMind, por meio de seus algoritmos, visa reduzir o tempo necessário para a geração dos mapas segmentados, de quatro para uma hora. Isso liberará significativamente o tempo do radiologista. Mais importante, este algoritmo de segmentação pode ser utilizado para outras partes do corpo.
Para resumir, o AlphaGo venceu com sucesso o 18 vezes campeão mundial de Go, Lee Seedol, quatro vezes em um torneio melhor de cinco em 2016. Em 2017, ele até venceu um time dos melhores jogadores do mundo. Ele usa uma combinação de DNN e DQN como uma rede de políticas para criar a próxima melhor jogada e uma DNN como uma rede de valor para avaliar o resultado do jogo. A pesquisa em árvore de Monte Carlo é usada junto com as redes de política e valor para reduzir a largura e a profundidade da pesquisa – elas são usadas para melhorar a função de avaliação. O objetivo final deste algoritmo não é resolver jogos de tabuleiro, mas inventar um algoritmo de Inteligência Artificial Geral. O AlphaGo é, sem dúvida, um grande passo à frente nessa direção.
A diferença entre Data Science, Machine Learning e Big Data!
Claro, houve outros efeitos. À medida que as notícias do AlphaGo Vs Lee Seedol se tornaram virais, a demanda por placas Go aumentou dez vezes. Muitas lojas relataram casos de placas Go esgotadas e tornou-se um desafio comprar uma placa Go.
Felizmente, acabei de encontrar um e encomendei para mim e meu filho. Você está planejando comprar a prancha e aprender Go?
Aprenda cursos de ML das melhores universidades do mundo. Ganhe Masters, Executive PGP ou Advanced Certificate Programs para acelerar sua carreira.
Quais são as limitações do aprendizado por reforço profundo?
A DL esquece o conhecimento adquirido anteriormente quando novos dados ou informações são introduzidos, portanto, não o desafia. O excesso de reforço às vezes pode resultar em um excesso de estados, diminuindo a eficácia. Devido à complexidade dos modelos de dados, o treinamento é extremamente caro. O aprendizado profundo também exige o uso de GPUs caras e centenas de estações de trabalho. Como resultado, torna-se menos econômico de usar.
Quais são os contras de usar o Monte Carlo Tree Search?
Embora o MCTS seja um algoritmo simples de executar, ele apresenta algumas desvantagens. Quando a árvore cresce após algumas iterações, é necessária muita memória. Quando aplicado a jogos baseados em turnos, pode haver um único ramo ou caminho que leva a uma derrota contra o oponente em condições específicas. Como resultado, é um pouco menos confiável. Após muitas iterações, o Monte Carlo Tree Search leva muito tempo para determinar o caminho mais eficaz.
Como o AlphaZero é diferente do AlphaGo Zero?
As versões anteriores do AlphaGo incorporaram um pequeno número de recursos projetados à mão, mas o AlphaGo Zero apenas usa as pedras pretas e brancas da placa Go como entrada. Versões anteriores do AlphaGo contavam com uma rede de políticas para escolher o próximo movimento e uma rede de valor para estimar o vencedor do jogo de cada posição. Eles são incorporados ao AlphaGo Zero, permitindo treinamento e avaliação mais eficientes. Todas essas diferenças contribuem para o melhor desempenho e generalização do sistema. O ajuste algorítmico, por outro lado, torna o sistema muito mais poderoso e eficiente.