
Idź i wyzwanie dla sztucznej inteligencji ogólnej
Opublikowany: 2018-02-15Ten artykuł ma na celu zbadanie związku między grą „Go” a sztuczną inteligencją. Celem jest odpowiedź na pytania – Co sprawia, że gra w Go jest wyjątkowa? Dlaczego opanowanie gry Go było trudne dla komputera? Dlaczego program komputerowy był w stanie pokonać arcymistrza szachowego w 1997 roku? Dlaczego złamanie Go zajęło blisko dwie dekady?
„Panowie nie powinni tracić czasu na trywialne zabawy – powinni uczyć się Go”
– Konfucjusz
W rzeczywistości eksperci od sztucznej inteligencji myśleli, że komputery będą w stanie pokonać mistrza świata w Go dopiero do 2027 roku. Dzięki DeepMind, firmie zajmującej się sztuczną inteligencją pod parasolem Google, to ogromne zadanie zostało zrealizowane dziesięć lat wcześniej. W tym artykule omówimy technologie wykorzystywane przez DeepMind do pokonania mistrza świata w Go. Na koniec w tym poście omówiono, w jaki sposób tę technologię można wykorzystać do rozwiązywania niektórych złożonych, rzeczywistych problemów.
Spis treści
Idź – co to jest?
Go to licząca 3000 lat chińska strategiczna gra planszowa, która od wieków utrzymuje swoją popularność. Gra w którą grają dziesiątki milionów ludzi na całym świecie, Go to dwuosobowa gra planszowa z prostymi zasadami i intuicyjną strategią. W tej grze używane są różne rozmiary plansz; profesjonaliści używają deski 19×19.

Gra zaczyna się od pustej planszy. Następnie każdy gracz na zmianę umieszcza czarne i białe kamienie (czarny idzie pierwszy) na planszy, na przecięciu linii (w przeciwieństwie do szachów, gdzie umieszcza się pionki w polach). Gracz może chwytać kamienie przeciwnika, otaczając go ze wszystkich stron. Za każdy złapany kamień gracz otrzymuje punkty. Celem gry jest zajęcie maksymalnego terytorium na planszy wraz z przejmowaniem kamieni przeciwników.
W Go chodzi o tworzenie, w przeciwieństwie do Chess, które dotyczy destrukcji. Go wymaga wolności, kreatywności, intuicji, równowagi, strategii i głębi intelektualnej, aby opanować grę. Gra w Go angażuje obie strony mózgu. W rzeczywistości skany mózgu graczy Go wykazały, że Go pomaga w rozwoju mózgu poprzez poprawę połączeń między obiema półkulami mózgu.
Sieci neuronowe dla manekinów: kompleksowy przewodnik
Idź i wyzwanie dla sztucznej inteligencji (AI)
Komputery były w stanie opanować kółko i krzyżyk w 1952 roku . Deep Blue był w stanie pokonać arcymistrza szachowego Garry'ego Kasparowa w 1997 roku . Program komputerowy był w stanie wygrać z mistrzem świata w Jeopardy (popularnej amerykańskiej grze) w 2001 roku . AlphaGo firmy DeepMind był w stanie pokonać mistrza świata w Go w 2016 roku . Dlaczego opanowanie gry w Go jest uważane za trudne dla programu komputerowego?
Szachy rozgrywane są na planszy 8×8, podczas gdy Go używa planszy o wymiarach 19×19. Na początku partii szachowej gracz będzie miał 20 możliwych ruchów. W otwarciu Go gracz może mieć 361 możliwych ruchów. Liczba możliwych pozycji na planszy Go jest równa 10 do potęgi 170; więcej niż liczba atomów w naszym wszechświecie! Potencjalna liczba pozycji na szachownicy sprawia, że czasy Googol (10 do potęgi 100) są bardziej złożone niż szachy.
W szachach na każdy krok gracz ma do wyboru 35 ruchów. Średnio gracz Go będzie miał 250 możliwych ruchów na każdym kroku. W szachach, na dowolnej pozycji, komputerowi stosunkowo łatwo jest przeprowadzić wyszukiwanie siłowe i wybrać najlepszy możliwy ruch, który maksymalizuje szanse na wygraną. Przeszukiwanie siłowe nie jest możliwe w przypadku Go, ponieważ potencjalna liczba dozwolonych ruchów w każdym kroku jest olbrzymia.
Aby komputer opanował szachy, staje się to łatwiejsze w miarę postępu gry, ponieważ pionki są usuwane z planszy. W Go staje się to trudniejsze dla programu komputerowego, ponieważ kamienie są dodawane do planszy w miarę postępu gry. Zazwyczaj gra w Go trwa 3 razy dłużej niż gra w szachy.
Z tych wszystkich powodów, najlepszy program komputerowy Go był w stanie dogonić mistrza świata Go dopiero w 2016 roku, po ogromnej eksplozji nowych technik uczenia maszynowego. Naukowcom pracującym w DeepMind udało się wymyślić program komputerowy o nazwie AlphaGo , który pokonał mistrza świata Lee Seedola . Wykonanie zadania nie było łatwe. Naukowcy z DeepMind opracowali wiele nowatorskich innowacji w procesie tworzenia AlphaGo.
„Reguły Go są tak eleganckie, organiczne i rygorystycznie logiczne, że jeśli inteligentne formy życia istnieją w innym miejscu we wszechświecie, prawie na pewno grają w Go”.
– Edward Laskar
Sieci neuronowe: zastosowania w świecie rzeczywistym
Jak działa AlphaGo
AlphaGo jest algorytmem ogólnego przeznaczenia, co oznacza, że można go wykorzystać również do rozwiązywania innych zadań. Na przykład Deep Blue od IBM jest specjalnie zaprojektowany do gry w szachy. Reguły szachów wraz z wiedzą zgromadzoną przez stulecia gry są zaprogramowane w mózgu programu. Deep Blue nie może być używany nawet do grania w trywialne gry, takie jak kółko i krzyżyk. Może robić tylko jedną konkretną rzecz, w której jest bardzo dobry, czyli grać w szachy. AlphaGo może nauczyć się grać w inne gry poza Go. Te algorytmy ogólnego przeznaczenia stanowią nową dziedzinę badań, zwaną sztuczną ogólną inteligencją.
AlphaGo wykorzystuje najnowocześniejsze metody – Deep Neural Networks (DNN), Reinforcement Learning (RL), Monte Carlo Tree Search (MCTS), Deep Q Networks (DQN) (nowatorska technika wprowadzona i spopularyzowana przez DeepMind, która łączy sieci z uczeniem przez wzmacnianie), żeby wymienić tylko kilka. Następnie łączy wszystkie te metody w innowacyjny sposób, aby osiągnąć mistrzostwo na poziomie nadludzkim w grze Go.
Przyjrzyjmy się najpierw poszczególnym elementom tej układanki, zanim przejdziemy do tego, jak te elementy są ze sobą połączone, aby wykonać zadanie.
Głębokie sieci neuronowe
DNN to technika uczenia maszynowego, luźno inspirowana funkcjonowaniem ludzkiego mózgu. Architektura DNN składa się z warstw neuronów. DNN może rozpoznawać wzorce w danych bez wyraźnego programowania.
Odwzorowuje wejścia na wyjścia bez konieczności programowania ich specjalnie w tym celu. Jako przykład załóżmy, że zasililiśmy sieć dużą ilością zdjęć kotów i psów. Jednocześnie szkolimy również system, informując go (w formie etykiet), czy dany obraz przedstawia kota czy psa (nazywa się to uczeniem nadzorowanym). DNN nauczy się rozpoznawać wzór ze zdjęć, aby skutecznie odróżnić kota od psa. Głównym celem szkolenia jest to, że kiedy DNN zobaczy nowy obraz psa lub kota, powinien być w stanie poprawnie go sklasyfikować, tj. przewidzieć, czy jest to kot, czy pies.
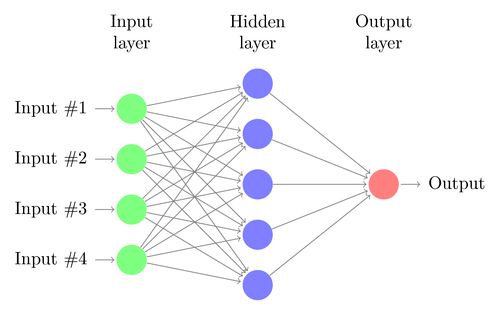
Pozwól nam zrozumieć architekturę prostego DNN. Liczba neuronów w warstwie wejściowej odpowiada wielkości wejścia. Załóżmy, że nasze zdjęcia kotów i psów mają wymiary 28×28. Każdy wiersz i kolumna będzie składać się z 28 pikseli, co daje łącznie 784 piksele dla każdego zdjęcia. W takim przypadku warstwa wejściowa będzie składać się z 784 neuronów, po jednym na każdy piksel. Liczba neuronów w warstwie wyjściowej będzie zależeć od liczby klas, do których należy zaklasyfikować dane wyjściowe. W tym przypadku warstwa wyjściowa będzie się składać z dwóch neuronów – jednego odpowiadającego „kot”, a drugiego „psa”.
Miej oko na następną wielką rzecz: uczenie maszynowe
Pomiędzy warstwą wejściową i wyjściową będzie wiele warstw neuronowych (co jest początkiem używania terminu „Głęboka” w „Głębokiej sieci neuronowej”). Są to tak zwane „ukryte warstwy”. Liczba warstw ukrytych i liczba neuronów w każdej warstwie nie jest stała. W rzeczywistości zmiana tych wartości jest dokładnie tym, co prowadzi do optymalizacji wydajności. Wartości te nazywane są hiperparametrami i należy je dostroić zgodnie z aktualnym problemem. Eksperymenty otaczające sieci neuronowe w dużej mierze polegają na ustaleniu optymalnej liczby hiperparametrów.
Faza szkolenia DNN będzie składać się z podania w przód i podania w tył. Po pierwsze, wszystkie połączenia między neuronami są inicjowane losowymi wagami. Podczas przejścia do przodu sieć jest zasilana pojedynczym obrazem. Dane wejściowe (dane pikselowe z obrazu) są łączone z parametrami sieci (wagi, odchylenia i funkcje aktywacji) i przekazywane dalej przez ukryte warstwy, aż do wyjścia, które zwraca prawdopodobieństwo przynależności zdjęcia do każdego zajęć.
Następnie prawdopodobieństwo to jest porównywane z rzeczywistą etykietą klasy i obliczany jest „błąd”. W tym momencie wykonywane jest przejście wsteczne – ta informacja o błędzie jest przekazywana z powrotem przez sieć za pomocą techniki zwanej „propagacją wsteczną”. W początkowych fazach treningu ten błąd będzie wysoki, a dobry mechanizm treningowy będzie go stopniowo zmniejszał.
DNN są szkolone w ten sposób z podaniem do przodu i do tyłu, aż wagi przestaną się zmieniać (jest to znane jako konwergencja). Wtedy DNN będą w stanie przewidzieć i sklasyfikować obrazy z dużą dokładnością, tzn. czy na zdjęciu jest kot czy pies.

Badania dały nam wiele różnych architektur głębokich sieci neuronowych. W przypadku problemów z widzeniem komputerowym (tj. problemów związanych z obrazami) konwolucyjne sieci neuronowe (CNN) tradycyjnie dawały dobre wyniki. W przypadku problemów związanych z sekwencją — rozpoznawaniem mowy lub tłumaczeniem języka — rekurencyjne sieci neuronowe (RNN) zapewniają doskonałe wyniki.
Przewodnik dla początkujących do zrozumienia języka naturalnego
W przypadku AlphaGo proces wyglądał następująco: po pierwsze, sieć neuronowa Convolution Neural Network (CNN) została przeszkolona na milionach obrazów pozycji planszy. Następnie sieć została poinformowana o kolejnym ruchu odgrywanym przez ekspertów w każdym przypadku podczas fazy szkoleniowej sieci. W ten sam sposób, jak wspomniano wcześniej, rzeczywista wartość została porównana z danymi wyjściowymi i znaleziono pewien rodzaj metryki „błędu”.
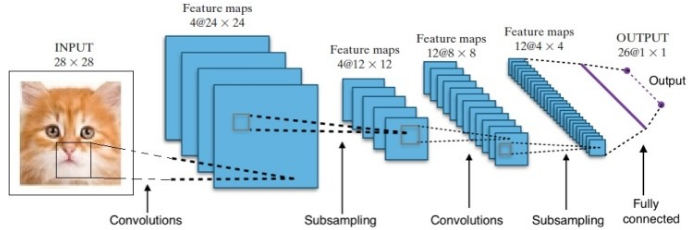
Pod koniec szkolenia DNN wypisze kolejne ruchy wraz z prawdopodobieństwami, które najprawdopodobniej zagra doświadczony ludzki gracz. Ten rodzaj sieci może wymyślić tylko krok, który gra człowiek-ekspert. DeepMind był w stanie osiągnąć dokładność 60% w przewidywaniu ruchu, który wykonałby człowiek. Jednak, aby pokonać w Go eksperta od ludzi, to nie wystarczy. Dane wyjściowe z DNN są dalej przetwarzane przez Deep Reinforcement Network, podejście opracowane przez DeepMind, które łączy głębokie sieci neuronowe i wzmacnianie uczenia.
Nauka głębokiego wzmacniania
Uczenie się przez wzmacnianie (RL) nie jest nową koncepcją. Laureat nagrody Nobla Iwan Pawłow eksperymentował z warunkowaniem klasycznym na psach i odkrył zasady uczenia się przez wzmacnianie w 1902 roku. RL jest również jedną z metod, za pomocą których ludzie uczą się nowych umiejętności. Czy kiedykolwiek zastanawiałeś się, jak delfiny na pokazach są szkolone, by skakać z wody na tak wielką wysokość? To z pomocą RL. Najpierw w basenie zanurzana jest lina, której używa się do przygotowania delfinów. Za każdym razem, gdy delfin przekroczy kabel od góry, jest nagradzany jedzeniem. Gdy nie przekroczy liny, nagroda zostaje wycofana. Powoli delfin dowie się, że płaci się mu za każdym razem, gdy minie sznur z góry. Wysokość liny jest stopniowo zwiększana, aby tresować delfina. 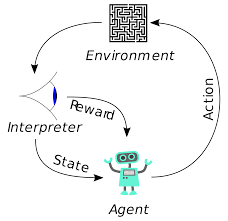
Generowanie języka naturalnego: najważniejsze rzeczy, które musisz wiedzieć
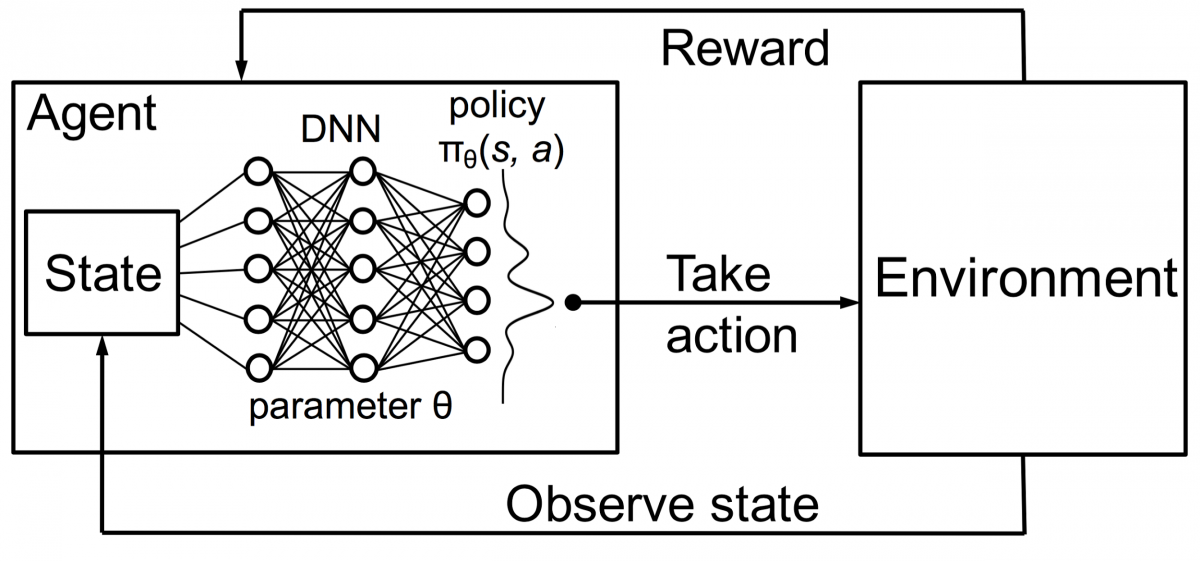
Agenci w uczeniu się przez wzmacnianie są również szkoleni przy użyciu tej samej zasady. Agent podejmie działania i wejdzie w interakcję z otoczeniem. Akcja podjęta przez agenta powoduje zmianę środowiska. Ponadto agent otrzymał informację zwrotną na temat środowiska. Agent jest nagradzany lub nie, w zależności od jego działania i celu. Ważne jest to, że ten cel nie jest wyraźnie określony dla agenta. Mając wystarczająco dużo czasu, agent nauczy się maksymalizować przyszłe nagrody.

Łącząc to z DNN, DeepMind wynalazł Deep Reinforcement Learning (DRL) lub Deep Q Networks (DQN), gdzie Q oznacza maksymalne przyszłe nagrody. DQN zostały po raz pierwszy zastosowane w grach na Atari . DQN nauczył się grać w różne rodzaje gier Atari zaraz po wyjęciu z pudełka. Przełomem było to, że nie było wymagane żadne wyraźne programowanie do reprezentowania różnych rodzajów gier na Atari. Pojedynczy program był wystarczająco inteligentny, aby poznać wszystkie różne środowiska gry, a poprzez samodzielną grę był w stanie opanować wiele z nich.
W 2014 r. DQN przewyższał poprzednie metody uczenia maszynowego w 43 z 49 gier (obecnie został przetestowany w ponad 70 grach). W rzeczywistości w ponad połowie gier osiągał ponad 75% poziomu profesjonalnego gracza. W niektórych grach DQN wymyślił nawet zaskakująco dalekowzroczne strategie, które pozwoliły mu osiągnąć maksymalny możliwy do uzyskania wynik — na przykład w Breakout nauczył się najpierw kopać tunel na jednym końcu ceglanej ściany, aby piłka odbijała się. z tyłu i wybijaj cegły od tyłu.
Polityki i sieci wartości
W AlphaGo istnieją dwa główne typy sieci:
Jednym z celów DQN AlphaGo jest wyjście poza ludzką grę ekspercką i naśladowanie nowych innowacyjnych ruchów, grając przeciwko sobie miliony razy, a tym samym stopniowo poprawiając wagę. Ten DQN miał 80% współczynnik wygranych w porównaniu z popularnymi DNN. DeepMind postanowił połączyć te dwie sieci neuronowe (DNN i DQN) w celu utworzenia pierwszego typu sieci – „Policy Network”. Krótko mówiąc, zadaniem sieci polityk jest zmniejszenie zakresu poszukiwań następnego ruchu i wymyślenie kilku dobrych posunięć, które warto zbadać dalej.
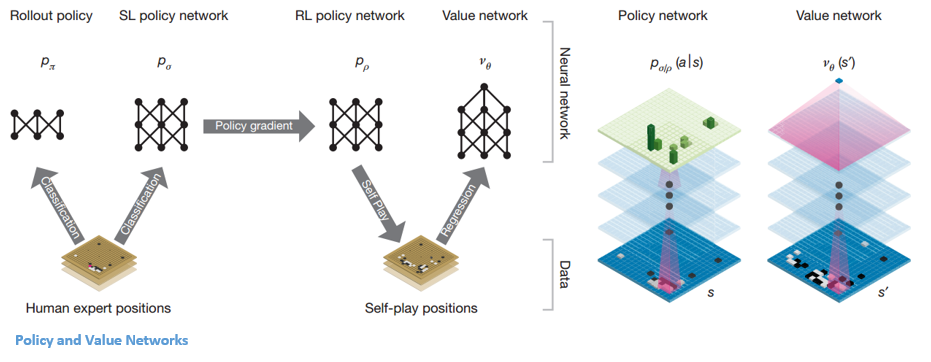 Gdy sieć polityczna zostanie zamrożona, gra przeciwko sobie miliony razy. Te gry generują nowy zestaw danych Go, składający się z różnych pozycji na planszy i wyników gier. Ten zestaw danych służy do tworzenia funkcji oceny. Drugi rodzaj funkcji – „Sieć wartości” służy do przewidywania wyniku gry. Uczy się przyjmować różne pozycje na planszy jako dane wejściowe i przewidywać wynik gry oraz jego miarę.
Gdy sieć polityczna zostanie zamrożona, gra przeciwko sobie miliony razy. Te gry generują nowy zestaw danych Go, składający się z różnych pozycji na planszy i wyników gier. Ten zestaw danych służy do tworzenia funkcji oceny. Drugi rodzaj funkcji – „Sieć wartości” służy do przewidywania wyniku gry. Uczy się przyjmować różne pozycje na planszy jako dane wejściowe i przewidywać wynik gry oraz jego miarę.
Łączenie polityki i sieci wartości
Po całym tym szkoleniu DeepMind w końcu stworzył dwie sieci neuronowe – Policy i Value Networks. Sieć polityczna przyjmuje pozycję tablicy jako dane wejściowe i wyprowadza rozkład prawdopodobieństwa jako prawdopodobieństwo każdego z ruchów w tej pozycji. Sieć wartości ponownie przyjmuje pozycję planszy jako wejście i wyprowadza pojedynczą liczbę rzeczywistą z zakresu od 0 do 1. Jeśli na wyjściu sieci jest zero, oznacza to, że biały wygrywa, a 1 oznacza całkowitą wygraną gracza z czarnym kamienie.
Sieć polityk ocenia aktualne pozycje, a sieć wartości ocenia przyszłe ruchy. Podział zadań na te dwie sieci przez DeepMind był jednym z głównych powodów sukcesu AlphaGo.
Łączenie sieci Policy i Value z Monte Carlo Tree Search (MCTS) i Rollouts
Same sieci neuronowe nie wystarczą. Aby wygrać grę w Go, wymagane jest trochę więcej strategii. Ten plan jest realizowany przy pomocy MCTS. Monte Carlo Tree Search pomaga również w innowacyjnym łączeniu dwóch sieci neuronowych. Sieci neuronowe pomagają w skutecznym poszukiwaniu następnego najlepszego ruchu.
Spróbujmy skonstruować przykład, który pomoże Ci to wszystko lepiej zwizualizować. Wyobraź sobie, że gra znajduje się w nowej pozycji, której wcześniej nie spotkałeś. W takiej sytuacji wzywa się sieć polityczną do oceny obecnej sytuacji i możliwych przyszłych ścieżek; a także atrakcyjność ścieżek i wartość każdego ruchu przez sieci Value, wspierane przez wdrożenia Monte Carlo.
Sieć polityk znajduje wszystkie możliwe „dobre” posunięcia, a sieci wartości oceniają każdy z ich wyników. W Monte Carlo rozgrywanych jest kilka tysięcy losowych gier z pozycji rozpoznawanych przez sieć polis. Przeprowadzono eksperymenty w celu określenia względnego znaczenia sieci wartości w porównaniu z wdrażaniem Monte Carlo. W wyniku tych eksperymentów DeepMind przypisał wagę 80% do sieci Value i 20% do funkcji oceny wdrożenia Monte Carlo.
Sieć zasad zmniejsza szerokość wyszukiwania z 200 nieparzystych możliwych ruchów do 4 lub 5 najlepszych ruchów. Sieć zasad rozwija drzewo z tych 4 lub 5 kroków, które wymagają rozważenia. Sieć wartości pomaga w zmniejszeniu głębokości przeszukiwania drzewa poprzez natychmiastowe zwracanie wyniku gry z tej pozycji. Na koniec wybierany jest ruch o najwyższej wartości Q, czyli krok z maksymalną korzyścią.
„ W grze opiera się przede wszystkim na intuicji i wyczuciu, a ze względu na swoje piękno, subtelność i intelektualną głębię od wieków zawładnęła ludzką wyobraźnią”.
– Demis Hassabis
Zastosowanie AlphaGo do rzeczywistych problemów
Wizja DeepMind z ich strony internetowej jest bardzo wymowna – „Rozwiąż inteligencję. Wykorzystaj tę wiedzę, aby uczynić świat lepszym miejscem”. Ostatecznym celem tego algorytmu jest uczynienie go uniwersalnym, aby można go było używać do rozwiązywania złożonych problemów w świecie rzeczywistym. AlphaGo firmy DeepMind to znaczący krok naprzód w poszukiwaniu AGI. DeepMind z powodzeniem wykorzystał swoją technologię do rozwiązywania rzeczywistych problemów – spójrzmy na kilka przykładów:
Zmniejszenie zużycia energii
Sztuczna inteligencja DeepMind została z powodzeniem wykorzystana do obniżenia kosztów chłodzenia centrum danych Google o 40%. W każdym środowisku zużywającym energię na dużą skalę ta poprawa jest fenomenalnym krokiem naprzód. Jednym z podstawowych źródeł zużycia energii w centrum danych jest chłodzenie. Dużo ciepła generowanego podczas pracy serwerów musi zostać usunięte, aby utrzymać je w działaniu. Jest to osiągane przez wielkoskalowe urządzenia przemysłowe, takie jak pompy, agregaty chłodnicze i wieże chłodnicze. Ponieważ środowisko centrum danych jest bardzo dynamiczne, działanie z optymalną efektywnością energetyczną jest trudne. Do rozwiązania tego problemu wykorzystano sztuczną inteligencję DeepMind.
Najpierw korzystali z danych historycznych, które zostały zebrane przez tysiące czujników w centrum danych. Korzystając z tych danych, przeszkolili zespół sieci DNN na temat średniej przyszłej efektywności wykorzystania energii (PUE). Ponieważ jest to algorytm ogólnego przeznaczenia, planuje się, że będzie on stosowany również do innych wyzwań w środowisku centrum danych.
Możliwe zastosowania tej technologii obejmują uzyskanie większej ilości energii z tej samej jednostki wejściowej, zmniejszenie zużycia energii i wody w produkcji półprzewodników itp. DeepMind ogłosił w swoim poście na blogu, że wiedza ta zostanie udostępniona w przyszłej publikacji, aby inne centra danych, przemysłowe operatorzy, a ostatecznie środowisko mogą odnieść znaczne korzyści z tego znaczącego kroku.
Planowanie radioterapii nowotworów głowy i szyi
DeepMind współpracował z wydziałem radioterapii w University College London Hospital, NHS Foundation Trust, światowym liderze w leczeniu raka.
Jak duże zbiory danych i uczenie maszynowe łączą się w walce z rakiem
U jednego na 75 mężczyzn i u jednej na 150 kobiet w życiu zdiagnozowano raka jamy ustnej. Ze względu na wrażliwy charakter struktur i narządów w okolicy głowy i szyi radiolodzy muszą zachować szczególną ostrożność podczas ich leczenia.
Przed zastosowaniem radioterapii należy sporządzić szczegółową mapę z obszarami do leczenia oraz obszarami, których należy unikać. Nazywa się to segmentacją. Ta podzielona na segmenty mapa jest wprowadzana do aparatu radiograficznego, który następnie namierza komórki rakowe bez uszkadzania zdrowych komórek.
W przypadku raka głowy lub szyi jest to żmudna praca dla radiologów, ponieważ obejmuje bardzo wrażliwe narządy. Stworzenie mapy segmentowej dla tego obszaru zajmuje radiologom około czterech godzin. DeepMind, poprzez swoje algorytmy, dąży do skrócenia czasu potrzebnego do wygenerowania map segmentowanych z czterech do jednej godziny. To znacznie uwolni czas radiologa. Co ważniejsze, ten algorytm segmentacji można wykorzystać do innych części ciała.
Podsumowując, AlphaGo z sukcesem pokonał osiemnastokrotnego mistrza świata w Go, Lee Seedola, czterokrotnie w turnieju do pięciu zwycięstw w 2016 r. W 2017 r. pokonał nawet drużynę najlepszych graczy na świecie. Wykorzystuje kombinację DNN i DQN jako sieć polityki do wymyślania następnego najlepszego ruchu, a jedną DNN jako sieć wartości do oceny wyniku gry. Wyszukiwanie drzewa Monte Carlo jest używane wraz z sieciami polityk i wartości, aby zmniejszyć szerokość i głębokość wyszukiwania – są one wykorzystywane do poprawy funkcji oceny. Ostatecznym celem tego algorytmu nie jest rozwiązywanie gier planszowych, ale wynalezienie algorytmu sztucznej inteligencji ogólnej. AlphaGo to niewątpliwie duży krok naprzód w tym kierunku.
Różnica między Data Science, Machine Learning i Big Data!
Oczywiście były inne efekty. Gdy wieści o AlphaGo Vs Lee Seedol stały się popularne, popyt na tablice Go wzrósł dziesięciokrotnie. Wiele sklepów zgłosiło przypadki wyczerpania zapasów tablic Go, a zakup tablicy Go stał się trudny.
Na szczęście znalazłem jeden i zamówiłem go dla siebie i mojego dziecka. Planujesz kupić deskę i nauczyć się Go?
Ucz się kursów ML z najlepszych światowych uniwersytetów. Zdobywaj programy Masters, Executive PGP lub Advanced Certificate Programy, aby przyspieszyć swoją karierę.
Jakie są ograniczenia uczenia się przez głębokie wzmocnienie?
DL zapomina o zdobytej wcześniej wiedzy, gdy wprowadza nowe dane lub informacje, więc nie kwestionuje tego. Zbyt duże wzmocnienie może czasami skutkować nadmiarem stanów, obniżając skuteczność. Ze względu na złożoność modeli danych szkolenie jest niezwykle kosztowne. Głębokie uczenie wymaga również użycia drogich procesorów graficznych i setek stacji roboczych. W rezultacie staje się mniej ekonomiczny w użyciu.
Jakie są wady korzystania z wyszukiwania drzewa Monte Carlo?
Chociaż MCTS jest prostym algorytmem do wykonania, ma pewne wady. Gdy drzewo rozrasta się po kilku iteracjach, wymagana jest duża ilość pamięci. W przypadku gier turowych może istnieć pojedyncza gałąź lub ścieżka, która w określonych warunkach prowadzi do przegranej z przeciwnikiem. W rezultacie jest trochę mniej niezawodny. Po wielu iteracjach wyszukiwanie drzew metodą Monte Carlo zajmuje dużo czasu, aby określić najbardziej efektywną ścieżkę.
Czym różni się AlphaZero od AlphaGo Zero?
Poprzednie wersje AlphaGo zawierały niewielką liczbę ręcznie zaprojektowanych funkcji, ale AlphaGo Zero używa tylko czarno-białych kamieni z tablicy Go jako danych wejściowych. Wcześniejsze wersje AlphaGo opierały się na sieci polityk, aby wybrać następny ruch i sieci wartości, aby oszacować zwycięzcę gry z każdej pozycji. Są one połączone w AlphaGo Zero, co pozwala na bardziej efektywne szkolenie i ocenę. Wszystkie te różnice przyczyniają się do poprawy wydajności i uogólnienia systemu. Z drugiej strony, dostosowanie algorytmiczne sprawia, że system jest znacznie bardziej wydajny i wydajny.