
Analisi dei dati utilizzando Python [tutto ciò che devi sapere]
Pubblicato: 2020-09-02Per chiunque voglia iniziare con l'analisi dei dati, il primo linguaggio che viene in mente è R o Python. E il motivo per cui gli sviluppatori sono ora più inclini a Python è dovuto alla sua ampia adattabilità nel campo generico dello sviluppo software. Quindi, l'analisi dei dati utilizzando Python è uno dei termini più ascoltati per qualcuno che inizia il proprio viaggio nella scienza dei dati.
Sommario
Perché l'analisi dei dati?
Ora prima, perché l'analisi dei dati? Bene, è il primo passo per sapere con quale tipo di dati stai lavorando. È il passaggio in cui trovi modelli preziosi nei dati, che altrimenti non potresti vedere. Nel complesso, fornisce una comprensione intuitiva del set di dati in mano.
Qui è necessario tracciare una linea di demarcazione tra l'analisi dei dati e la pre-elaborazione dei dati. La pre-elaborazione dei dati si occupa della modellazione del set di dati per assicurarsi che sia pronto per l'addestramento. L'analisi dei dati serve a comprendere il set di dati, che è una fase preliminare per la pre-elaborazione dei dati. Nell'analisi dei dati, proviamo a modellare i dati per visualizzarli meglio e, quindi, acquisire informazioni dettagliate sul set di dati in mano.
Perché Python?
La seconda domanda è, perché Python? Bene, abbiamo già affermato che Python è un linguaggio ampiamente adattato. Sì, non è l'unica scelta quando si tratta di analisi dei dati, ma è piuttosto buona. Un altro motivo è che viene utilizzato di più! Python è facile e ha una vasta comunità di sviluppatori per aiutarti per quanto riguarda l'analisi dei dati usando python . Inoltre, l'analisi dei dati utilizzando Python è piuttosto divertente grazie all'ampio numero di librerie creative che offre per l'analisi e la visualizzazione dei dati.
In Python, la libreria di base per l'analisi dei dati è Pandas. È una libreria di alto livello, costruita sulla libreria NumPy, che è per il calcolo scientifico e l'analisi numerica. Panda semplifica il lavoro con i dati offrendo la sua struttura dati, nota come DataFrame. DataFrame aiuta a leggere e archiviare il tuo set di dati. Fornisce le funzioni di base per la lettura e la scrittura del set di dati, nonché la visualizzazione dei metadati e le funzioni di query per estrarre tutte le informazioni dettagliate dal set di dati.
È importante notare che la visualizzazione dei dati è una parte considerevole dell'analisi complessiva dei dati. Perché non solo aiuta a comprendere meglio i dati a te stesso, ma anche a coloro a cui stai fornendo le informazioni. Discuteremmo le due librerie più utilizzate per la visualizzazione: Matplotlib e Seaborn. Matplotlib è la libreria di base per qualsiasi visualizzazione in Python. Seaborn si basa anche su Matplotlib, che offre alcune delle funzioni di visualizzazione dei dati più creative.
Impostare l'ambiente
Il primo passo è configurare il tuo ambiente. Durante l'esecuzione dell'analisi dei dati utilizzando python , è importante disporre di un ambiente adeguato per mantenere tutto il lavoro. L'analisi dei dati utilizzando Python non sarà solo uno script, ma sarà un'interazione di te stesso con il set di dati e, per questo, hai bisogno di un posto appropriato in cui lavorare.
In Python, quel servizio è fornito da Anaconda Distribution. Il posto di lavoro principale di Anaconda è il notebook Jupyter. Allora, ora perché Jupyter? Bene, ti consente di avere le visualizzazioni direttamente all'interno del tuo notebook. Ha anche alcune funzioni magiche che ti consentono di vedere l'output direttamente senza indicare esplicitamente dove lo desideri.
Le librerie, Pandas e Matplotlib, sono preinstallate e quindi non è richiesta alcuna configurazione aggiuntiva per usarle.
Ecco la sinossi di come aggirare l'analisi dei dati utilizzando Python :
- Caricamento del Dataset
- Visualizzazione dei metadati del set di dati utilizzando Pandas
- Visualizzazioni dei dati utilizzando Matplotlib
- Raccolta di approfondimenti sui dati
Importa le librerie necessarie
Prima di iniziare a esaminare il codice per i passaggi, importa semplicemente le librerie necessarie con pseudo tag, come nel nome che le chiameremmo per l'intero programma.
importa numpy come np
importa panda come pd
# per la visualizzazione dei dati
importa matplotlib.pyplot come plt
import seaborn come sns
Ora esamineremo ogni passaggio e discuteremo quali funzioni sono disponibili e come utilizzarle.
Innanzitutto, leggere i set di dati. I panda forniscono alcune funzioni di base per caricare il set di dati nella sua struttura dati principale: DataFrame. Possiamo usarlo come segue.
data_df = pd.read_csv('heart.csv')
L'output di qualsiasi funzione di lettura sarà un DataFrame. Oltre ai lettori CSV, i panda forniscono lettori per quasi tutti i tipi di dati. Da HTML a JSON ed Excel.
A parte questo, se non disponi di dati in quanto tali e desideri creare il tuo set di dati, puoi facilmente utilizzare le funzioni degli oggetti Pandas' Series e DataFrame.
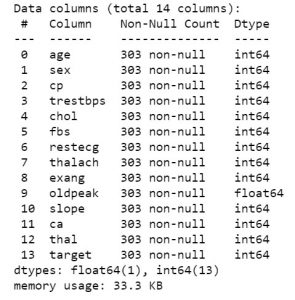
Quindi, una volta che hai i dati in mano, passiamo alla visualizzazione di cosa trattano i dati. Per ottenere la prima visualizzazione dei dati, puoi utilizzare le funzioni come df.info o df.describe per conoscere la struttura del tuo set di dati.
data_df.info()
data_df.descrivi()
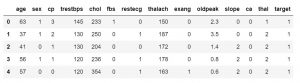
Una volta che sai quali funzionalità contiene il tuo set di dati, potresti voler esaminare i valori di quelle. È possibile utilizzare la funzione df.head() per ottenere i primi 5 campioni.
data_df.head()
#o
data_df.head(3)
Puoi anche specificare il numero di campioni per sovrascrivere il valore predefinito di 5. Puoi anche usare la funzione df.tail() per ottenere gli ultimi 5 valori del set di dati.
data_df.tail()
Questo è solo per ottenere una panoramica di alto livello di come potrebbero apparire i tuoi dati. Una volta pronto, puoi avviare le principali attività di visualizzazione dei dati, utilizzando Matplotlib. Inserisci il codice seguente per rendere interattiva la stampa e visualizzarla nel tuo quaderno stesso.
%matplotlib in linea
Vedremmo le funzionalità delle prime 5 visualizzazioni in matplotlib. Prima di entrare in esso, dovremmo conoscere alcune altre funzioni che controllano le nostre trame. Le funzioni come:
- Etichette: xlabel(), ylabel(). Sono per le etichette dell'asse x e dell'asse y.
- Legenda: serve per creare la legenda della trama.
- Titolo: per assegnare un titolo alla tua trama
- E infine, mostra la funzione per visualizzare la trama.
Checkout: stipendio per analista di dati in India
Visualizzazioni
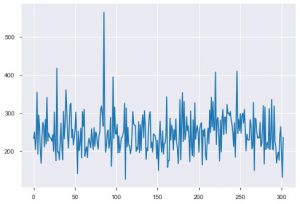
Vediamo ora le visualizzazioni. Partiamo dalla trama di base. plt.plot() viene utilizzato per generare un semplice grafico a linee per i dati. La funzione richiede due parametri obbligatori, e questi sono i dati dell'asse x e i dati dell'asse y. È possibile fornire facoltativamente gli stili, il nome e il colore della trama. Ecco come appare nel codice.
plt.plot(data_df['chol'])
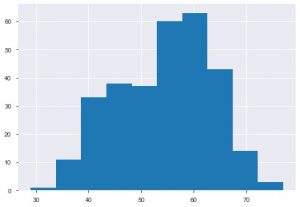
La seconda trama è l'istogramma. Un istogramma ti aiuta a visualizzare la frequenza o la distribuzione di una particolare caratteristica. Ti aiuta a vedere come le quantità si relazionano tra loro. Plt.hist() è la funzione di base per creare un istogramma sui dati. Puoi menzionare il parametro bins per controllare il numero sul grafico. È necessario passare solo i dati di un singolo asse se si desidera un'analisi univariata.
plt.hist(data_df['età'])

Un'altra trama che vedresti molto è la trama della barra. Aiuta ad analizzare e confrontare diverse caratteristiche. A differenza degli istogrammi, i grafici a barre vengono utilizzati per lavorare con dati categoriali.
È possibile applicare direttamente il grafico su DataFrame oppure specificare i parametri all'interno della funzione plt.bar(). Ecco come lo utilizziamo.
df = pd.DataFrame(np.random.rand(15, 5), columns=['t1', 't2', 't3', 't4', 't5'])
df.plot.bar()
Puoi anche usare il grafico a barre orizzontalmente usando la funzione barh().
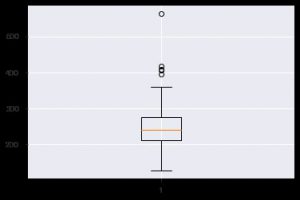
Un altro grafico perspicace è il boxplot. Aiuta a comprendere la distribuzione dei valori all'interno di ciascuna caratteristica. È possibile utilizzare la funzione plt.boxplot() per specificare i dati su cui si desidera generare un boxplot. Il grafico è particolarmente utile quando è necessario visualizzare rapidamente la dispersione nel set di dati o l'asimmetria. Ecco come puoi usarlo.
plt.boxplot(data_df['chol'])
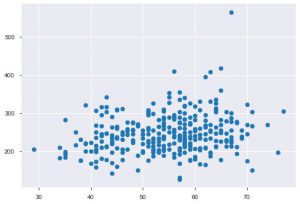
Ogni volta che lavori con dati statistici, vedresti sicuramente un grafico a dispersione. Un grafico a dispersione aiuta a osservare la relazione tra due caratteristiche. Il grafico richiede valori numerici sia per i dati dell'asse x che per l'asse y. Puoi semplicemente fornire questi due valori nella funzione plt.scatter() o applicare direttamente su DataFrame specificando i nomi delle colonne negli attributi xey. Ecco come puoi usarlo:
plt.scatter(data_df['age'], data_df['chol'])
Ora è il momento giusto per presentarvi le funzioni di Seaborn. Il grafico a dispersione in seaborn è più intuitivo rispetto a matplotlib perché per impostazione predefinita fornisce anche una linea di regressione nel grafico, per visualizzare meglio il grafico. Puoi usare la funzione sns.lplot() per creare quel grafico.
sns.lplot('age', 'chol', data=data_df)
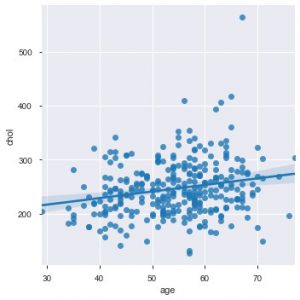
Come puoi vedere nel grafico sopra, la linea di regressione aiuta a capire ancora meglio la distribuzione.
Un altro miglioramento dell'utilizzo di Seaborn è la trama dello sciame. Viene utilizzato per disegnare un grafico a dispersione categoriale. Uno dei vantaggi della trama dello sciame rispetto alla trama della striscia simile è che utilizza solo i punti non sovrapposti. Quindi, è una trama più pulita e quindi fornisce una visione migliore.
sns.swarmplot(data_df['age'], data_df['chol'])
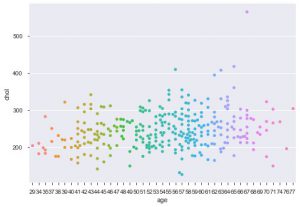
Quindi, questi sono i diversi tipi di trame in Matplotlib e Seaborn. Questa è solo la punta dell'iceberg e ci sono centinaia di altri modi diversi di tracciare i tuoi dati per estrarne informazioni creative.
Ora che conosci i grafici, vediamo come eseguire l'analisi dei dati effettivi utilizzando python . Daremo un'occhiata ad altri grafici e vedremo cosa ci mostrano sull'analisi dei dati usando python .
Iniziamo.
Dopo aver caricato i dati, la prima cosa che fa qualsiasi analista di dati ora è creare un profilo panda. Ora, questo può essere visto anche come una scorciatoia, ma se vuoi vedere tutte le relazioni, i conteggi e gli istogrammi delle variabili nel set di dati, puoi utilizzare la profilazione dei panda. È molto facile da generare, basta scaricare il modulo di profilazione panda e inserire il seguente codice:
import pandas_profiling
profilo = pandas_profiling.ProfileReport(data_df)
profilo
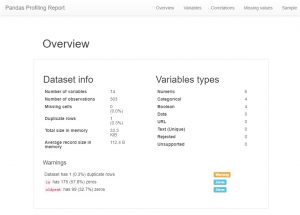
Come potresti vedere, c'è un'enorme quantità di informazioni sui metadati e anche informazioni sulle singole funzionalità. Questi potrebbero portare a una grande comprensione.
La seconda cosa che possiamo fare è generare una mappa di calore. Ora quello che fa una mappa di calore è mostrare la correlazione di ciascuna caratteristica con l'altra. E se troviamo valore con una correlazione più alta, significa che le due caratteristiche si assomigliano molto. Quindi, possiamo eliminare una delle funzionalità e, tuttavia, il modello funzionerà correttamente.
sns.heatmap(data_df.corr(), annot = True , cmap='Arance')
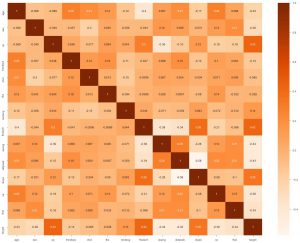
Qui possiamo vedere che nessuno è altamente correlato, quindi possiamo dire all'ingegnere del modello che avremmo bisogno di tutte le funzionalità come input.
Possiamo vedere qual è la distribuzione per età perché abbiamo a che fare con il set di dati sulle malattie cardiache, vediamo la distribuzione, quindi possiamo usare il distplot di Seaborn.
sns.distplot(data_df['età'], colore = 'ciano')
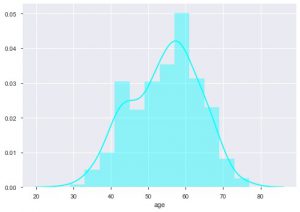
Dalla trama, puoi dire che la maggior parte delle persone che soffrono di malattie cardiache ha un'età compresa tra 50 e 60 anni. Allo stesso modo, possiamo anche visualizzare alcune altre caratteristiche importanti come la pressione sanguigna a riposo, che è indicata da tresbps. Possiamo fare un box plot per vedere la distribuzione, rispetto al valore target, cioè 0 e 1.
sns.boxplot(data_df['target'], data_df['trestbps'], palette = 'twilight')
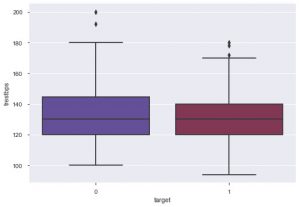
Possiamo concludere dal grafico che se la persona ha tres bps inferiori, le probabilità che soffra di malattie cardiache sono inferiori rispetto a quelle con un valore di tres bps più alto.
Allo stesso modo, possiamo anche vedere la relazione con i livelli di colesterolo. Vediamo che le persone con livelli di colesterolo inferiori hanno una minore possibilità di soffrire di malattie cardiache.
Puoi documentare tutte queste informazioni e fornirle all'ingegnere del machine learning che può quindi utilizzarle per creare un modello efficiente.
Conclusione
Quindi, ecco come puoi eseguire l'analisi dei dati usando python . Questo è solo il primo passo nel viaggio della scienza dei dati. Per saperne di più sull'estrazione di informazioni creative dai dati e sulla scienza dei dati in generale, vai ai corsi offerti da upGrad qui . Troverai uno spettro di corsi utili che guideranno efficacemente l'analisi dei dati utilizzando Python.
Impara i corsi di scienza dei dati dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.
Come devo imparare Python per l'analisi dei dati?
Se sei sulla strada per imparare Python per l'analisi dei dati, allora sei nel posto giusto. Devi avere un approccio passo dopo passo per rendere il processo di apprendimento più semplice per qualsiasi cosa. Ecco come appare il processo:
1. Chiarisci lo scopo di imparare Python e come sarai in grado di usarlo nel tuo campo.
2.Scarica il terminale Python richiesto e installalo nel tuo sistema.
3. Inizia ad apprendere le basi di Python frequentando diversi corsi e prendendo conoscenza delle diverse librerie Python.
4.Acquisisci familiarità con le espressioni regolari utilizzate in Python.
5. Cerca di acquisire una conoscenza approfondita di diverse librerie Python come Pandas, NumPy, Matplotlib e SciPy.
6. Inizia ad apprendere i concetti di analisi dei dati e come puoi integrare Python con esso.
7. Ora, devi solo continuare a praticare diversi strumenti e tecniche per migliorare in Python per l'analisi dei dati. Seguendo questo approccio passo-passo, troverai abbastanza facile imparare Python e migliorarlo per lavorare con l'analisi dei dati.
Come viene utilizzato Python per l'analisi dei dati?
Python è noto per essere una risorsa molto importante per l'analisi dei dati. Python aiuta in diversi modi per eseguire l'analisi dei dati. Ma prima, devi preparare i dati per l'analisi, eseguire analisi statistiche, creare visualizzazioni dei dati che potrebbero fornire informazioni dettagliate, prevedere le tendenze future in base ai dati disponibili e molto altro ancora.
Python risulta essere un elemento cruciale dell'analisi dei dati in quanto aiuta a:
1. Importazione di set di dati
2.Pulizia e preparazione dei dati per l'esecuzione dell'analisi
3. Manipolazione del DataFrame Pandas
4. Riepilogo dei set di dati
5. Sviluppo di un modello di Machine Learning per l'analisi dei dati con Python
Posso imparare Python in un mese?
Sì, puoi sicuramente farlo accadere se sei esperto con qualsiasi altro linguaggio di programmazione come Java, C, C++, ecc. Se la tua base è chiara, troverai abbastanza facile imparare Python anche in un solo mese. A parte questo, se ti impegni e segui un approccio passo dopo passo in modo disciplinato, puoi imparare Python in un mese anche quando non hai una conoscenza preliminare di altri linguaggi di programmazione. Devi solo impostare un programma e dedicarti all'apprendimento di Python in un mese.