
Vai e la sfida all'intelligenza artificiale generale
Pubblicato: 2018-02-15Questo articolo si propone di esplorare la connessione tra il gioco "Go" e l'intelligenza artificiale. L'obiettivo è rispondere alle domande: cosa rende speciale il gioco di Go? Perché padroneggiare il gioco di Go è stato difficile per un computer? Perché un programma per computer è stato in grado di battere un grande maestro di scacchi nel 1997? Perché ci sono voluti quasi due decenni per decifrare Go?
“I signori non dovrebbero perdere tempo in giochi banali, dovrebbero studiare Go”
- Confucio
In effetti, gli esperti di intelligenza artificiale pensavano che i computer sarebbero stati in grado di battere un campione del mondo di Go solo entro il 2027. Grazie a DeepMind, una società di intelligenza artificiale sotto l'egida di Google, questo formidabile compito è stato raggiunto un decennio prima. Questo articolo parlerà delle tecnologie utilizzate da DeepMind per battere il campione del mondo di Go. Infine, questo post discute come questa tecnologia può essere utilizzata per risolvere alcuni problemi complessi del mondo reale.
Sommario
Vai – Che c'è?
Go è un gioco da tavolo di strategia cinese di 3000 anni fa, che ha mantenuto la sua popolarità nel corso dei secoli. Giocato da decine di milioni di persone in tutto il mondo, Go è un gioco da tavolo per due giocatori con regole semplici e strategia intuitiva. Per giocare a questo gioco sono in uso diverse dimensioni del tabellone; i professionisti usano una tavola 19×19.

Il gioco inizia con un tabellone vuoto. Ogni giocatore poi, a turno, posiziona le pietre bianche e nere (il nero va per primo) sul tabellone, all'intersezione delle linee (a differenza degli scacchi, dove metti i pezzi nelle caselle). Un giocatore può catturare le pietre dell'avversario circondandolo da tutti i lati. Per ogni pietra catturata, al giocatore vengono assegnati dei punti. L'obiettivo del gioco è occupare il massimo territorio sul tabellone insieme a catturare le pietre dei tuoi avversari.
Go riguarda la creazione, a differenza di Chess, che riguarda la distruzione. Go richiede libertà, creatività, intuizione, equilibrio, strategia e profondità intellettuale per padroneggiare il gioco. Giocare a Go coinvolge entrambi i lati del cervello. In effetti, le scansioni cerebrali dei giocatori di Go hanno rivelato che Go aiuta nello sviluppo del cervello migliorando le connessioni tra entrambi gli emisferi cerebrali.
Reti neurali per manichini: una guida completa
Vai e la sfida all'intelligenza artificiale (AI)
I computer sono stati in grado di padroneggiare Tris nel 1952 . Deep Blue è stato in grado di battere il grande maestro di scacchi Garry Kasparov nel 1997 . Il programma per computer è stato in grado di vincere contro il campione del mondo in Jeopardy (un popolare gioco americano) nel 2001 . AlphaGo di DeepMind è stato in grado di sconfiggere un campione del mondo di Go nel 2016 . Perché è considerato difficile per un programma per computer padroneggiare il gioco di Go?
Gli scacchi si giocano su una tavola 8×8 mentre Go usa una tavola di dimensioni 19×19. All'inizio di una partita di scacchi, un giocatore avrà 20 mosse possibili. In un'apertura Go, un giocatore può avere 361 mosse possibili. Il numero di posizioni possibili della plancia Go è pari a 10 alla potenza 170; più del numero di atomi nel nostro universo! Il numero potenziale di posizioni sulla scacchiera rende i tempi di Gogool (da 10 a 100) più complessi degli scacchi.
Negli scacchi, per ogni passo, un giocatore deve scegliere tra 35 mosse. In media, un giocatore Go avrà 250 mosse possibili ad ogni passaggio. Negli scacchi, in qualsiasi posizione, è relativamente facile per un computer eseguire la ricerca con la forza bruta e scegliere la migliore mossa possibile che massimizza le possibilità di vincita. Una ricerca con la forza bruta non è possibile nel caso di Go, poiché il numero potenziale di mosse legali consentite per ogni passaggio è enorme.
Per un computer padroneggiare gli scacchi, diventa più facile man mano che il gioco procede perché i pezzi vengono rimossi dal tabellone. In Go, diventa più difficile per il programma per computer poiché le pietre vengono aggiunte al tabellone man mano che il gioco procede. In genere, una partita Go durerà 3 volte più a lungo di una partita a scacchi.
Per tutti questi motivi, un programma Go di punta per computer è stato in grado di raggiungere il campione del mondo Go solo nel 2016, dopo un'enorme esplosione di nuove tecniche di apprendimento automatico. Gli scienziati che lavorano a DeepMind sono stati in grado di inventare un programma per computer chiamato AlphaGo che ha sconfitto il campione del mondo Lee Seedol . Raggiungere il compito non è stato facile. I ricercatori di DeepMind hanno escogitato molte nuove innovazioni nel processo di creazione di AlphaGo.
"Le regole di Go sono così eleganti, organiche e rigorosamente logiche che se esistono forme di vita intelligenti in altre parti dell'universo, quasi sicuramente giocano a Go".
– Edoardo Laskar
Reti neurali: applicazioni nel mondo reale
Come funziona AlphaGo
AlphaGo è un algoritmo generico, il che significa che può essere utilizzato anche per risolvere altri compiti. Ad esempio, Deep Blue di IBM è specificamente progettato per giocare a scacchi. Le regole degli scacchi insieme alle conoscenze accumulate in secoli di gioco sono programmate nel cervello del programma. Deep Blue non può essere utilizzato nemmeno per giocare a giochi banali come Tic-Tac-Toe. Può fare solo una cosa specifica, in cui è molto bravo, cioè giocare a scacchi. AlphaGo può imparare a giocare anche ad altri giochi oltre a Go. Questi algoritmi per scopi generici costituiscono un nuovo campo di ricerca, chiamato Intelligenza Generale Artificiale.
AlphaGo utilizza metodi all'avanguardia: Deep Neural Networks (DNN), Reinforcement Learning (RL), Monte Carlo Tree Search (MCTS), Deep Q Networks (DQN) (una nuova tecnica introdotta e resa popolare da DeepMind che combina reti con apprendimento per rinforzo), solo per citarne alcuni. Combina quindi tutti questi metodi in modo innovativo per ottenere la maestria di livello sovrumano nel gioco di Go.
Diamo prima un'occhiata a ogni singolo pezzo di questo puzzle prima di entrare nel modo in cui questi pezzi sono legati insieme per portare a termine il compito.
Reti neurali profonde
I DNN sono una tecnica per eseguire l'apprendimento automatico, vagamente ispirata al funzionamento del cervello umano. L'architettura di una DNN è costituita da strati di neuroni. DNN può riconoscere i modelli nei dati senza essere esplicitamente programmato per questo.
Mappa gli ingressi alle uscite senza che nessuno lo programmi specificamente per lo stesso. Ad esempio, supponiamo di aver alimentato la rete con molte foto di cani e gatti. Allo stesso tempo, stiamo anche addestrando il sistema dicendogli (sotto forma di etichette) se una particolare immagine è di un gatto o di un cane (questo è chiamato apprendimento supervisionato). Un DNN imparerà a riconoscere lo schema dalle foto per distinguere con successo tra un gatto e un cane. L'obiettivo principale della formazione è che quando un DNN vede una nuova immagine di un cane o di un gatto, dovrebbe essere in grado di classificarlo correttamente, cioè prevedere se si tratta di un gatto o di un cane.
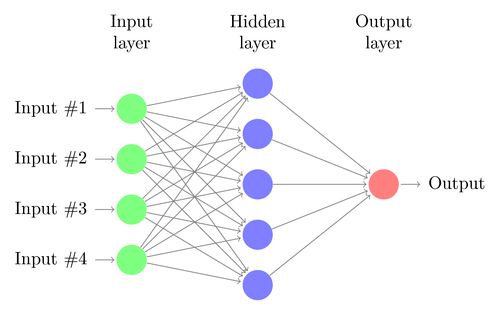
Cerchiamo di capire l'architettura di un semplice DNN. Il numero di neuroni nello strato di input corrisponde alla dimensione dell'input. Supponiamo che le nostre foto di cani e gatti siano un'immagine 28×28. Ciascuna riga e colonna sarà composta da 28 pixel ciascuna, per un totale di 784 pixel per ogni immagine. In tal caso lo strato di input comprenderà 784 neuroni, uno per ogni pixel. Il numero di neuroni nel livello di output dipenderà dal numero di classi in cui l'output deve essere classificato. In questo caso, lo strato di output sarà costituito da due neuroni: uno corrispondente a "gatto", l'altro a "cane".
Tieni d'occhio la prossima grande novità: l'apprendimento automatico
Ci saranno molti strati di neuroni tra gli strati di input e di output (che è l'origine dell'uso del termine "Deep" in "Deep Neural Network"). Questi sono chiamati "strati nascosti". Il numero di livelli nascosti e il numero di neuroni in ogni livello non è fisso. Infatti, la modifica di questi valori è proprio ciò che porta all'ottimizzazione delle prestazioni. Questi valori sono chiamati iperparametri e devono essere regolati in base al problema in questione. Gli esperimenti che circondano le reti neurali implicano in gran parte la scoperta del numero ottimale di iperparametri.
La fase di addestramento dei DNN consisterà in un passaggio in avanti e un passaggio all'indietro. Innanzitutto, tutte le connessioni tra i neuroni vengono inizializzate con pesi casuali. Durante il passaggio in avanti, la rete viene alimentata con una singola immagine. Gli input (dati pixel dell'immagine) vengono combinati con i parametri della rete (pesi, bias e funzioni di attivazione) e feed-forward attraverso livelli nascosti, fino all'output, che restituisce una probabilità di una foto appartenente a ciascuno delle classi.
Quindi, questa probabilità viene confrontata con l'etichetta di classe effettiva e viene calcolato un "errore". A questo punto, viene eseguito il passaggio all'indietro: questa informazione di errore viene ritrasmessa attraverso la rete attraverso una tecnica chiamata "back-propagation". Durante le fasi iniziali dell'allenamento, questo errore sarà elevato e un buon meccanismo di addestramento ridurrà gradualmente questo errore.
I DNN vengono addestrati in questo modo con un passaggio avanti e indietro fino a quando i pesi non smettono di cambiare (questo è noto come convergenza). Quindi i DNN saranno in grado di prevedere e classificare le immagini con un alto grado di accuratezza, ad esempio se l'immagine ha un gatto o un cane.

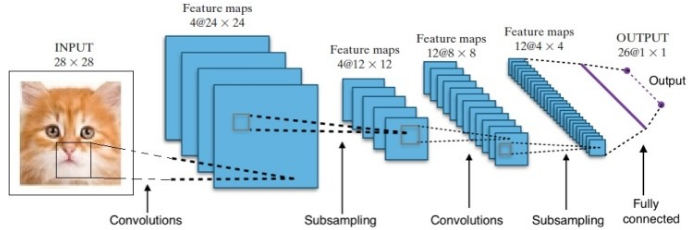
La ricerca ci ha fornito molte architetture di reti neurali profonde diverse. Per i problemi di Computer Vision (cioè problemi che coinvolgono le immagini), le Reti Neurali di Convoluzione (CNN) hanno tradizionalmente dato buoni risultati. Per i problemi che coinvolgono una sequenza – riconoscimento vocale o traduzione linguistica – le reti neurali ricorrenti (RNN) forniscono risultati eccellenti.
Una guida per principianti alla comprensione del linguaggio naturale
Nel caso di AlphaGo, il processo è stato il seguente: in primo luogo, la Convolution Neural Network (CNN) è stata addestrata su milioni di immagini di posizioni nel consiglio di amministrazione. Successivamente, la rete è stata informata della successiva mossa svolta dagli esperti umani in ciascun caso durante la fase di formazione della rete. Allo stesso modo come accennato in precedenza, il valore effettivo è stato confrontato con l'output ed è stata trovata una sorta di metrica di "errore".
Alla fine dell'allenamento, il DNN emetterà le mosse successive insieme alle probabilità che probabilmente saranno giocate da un giocatore umano esperto. Questo tipo di rete può venire fuori solo con un passaggio che viene interpretato da un giocatore esperto umano. DeepMind è stato in grado di ottenere una precisione del 60% nel prevedere la mossa che l'essere umano avrebbe fatto. Tuttavia, per battere un esperto umano a Go, questo non è sufficiente. L'output del DNN viene ulteriormente elaborato da Deep Reinforcement Network, un approccio ideato da DeepMind, che combina reti neurali profonde e apprendimento per rinforzo.
Apprendimento profondo per rinforzo
L'apprendimento per rinforzo (RL) non è un concetto nuovo. Il premio Nobel Ivan Pavlov ha sperimentato il condizionamento classico sui cani e ha scoperto i principi dell'apprendimento per rinforzo nel 1902. RL è anche uno dei metodi con cui gli esseri umani apprendono nuove abilità. Ti sei mai chiesto come vengono addestrati i delfini negli spettacoli a saltare a così grandi altezze fuori dall'acqua? È con l'aiuto di RL. Per prima cosa, la corda che serve per preparare i delfini viene immersa nella vasca. Ogni volta che il delfino attraversa il cavo dall'alto, viene ricompensato con del cibo. Quando non supera la corda la ricompensa viene ritirata. Lentamente il delfino imparerà che viene pagato ogni volta che passa la corda dall'alto. L'altezza della corda viene aumentata gradualmente per addestrare il delfino. 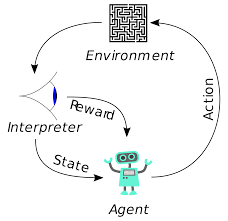
Generazione del linguaggio naturale: le cose principali che devi sapere
Anche gli agenti nell'apprendimento per rinforzo vengono addestrati utilizzando lo stesso principio. L'agente agirà e interagirà con l'ambiente. L'azione intrapresa dall'agente modifica l'ambiente. Inoltre, l'agente ha ricevuto un feedback sull'ambiente. L'agente viene ricompensato o meno, a seconda della sua azione e dell'obiettivo a portata di mano. Il punto importante è che questo obiettivo in questione non è esplicitamente dichiarato per l'agente. Dato un tempo sufficiente, l'agente imparerà come massimizzare le ricompense future.

Combinando questo con i DNN, DeepMind ha inventato Deep Reinforcement Learning (DRL) o Deep Q Networks (DQN) dove Q sta per i massimi premi futuri ottenuti. I DQN sono stati applicati per la prima volta ai giochi Atari . DQN ha imparato a giocare a diversi tipi di giochi Atari appena fuori dagli schemi. La svolta è stata che non era richiesta alcuna programmazione esplicita per rappresentare diversi tipi di giochi Atari. Un singolo programma è stato abbastanza intelligente da conoscere tutti i diversi ambienti del gioco e, attraverso il gioco autonomo, è stato in grado di padroneggiarne molti.
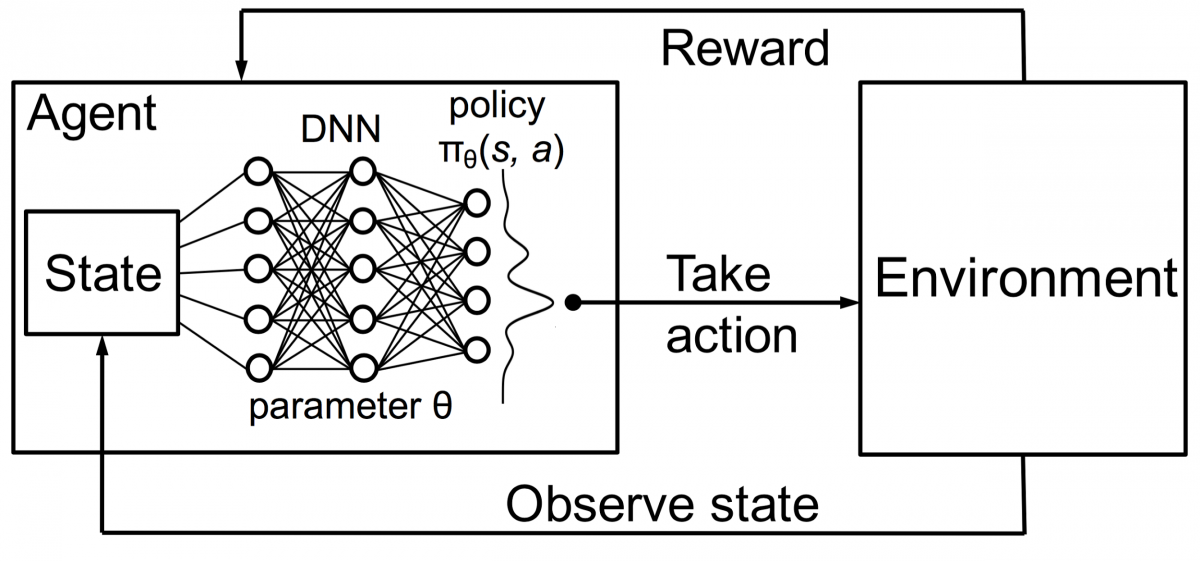
Nel 2014, DQN ha superato i precedenti metodi di apprendimento automatico in 43 dei 49 giochi (ora è stato testato su più di 70 giochi). Infatti, in più della metà delle partite, si è comportato a più del 75% del livello di un giocatore umano professionista. In alcuni giochi, DQN ha persino escogitato strategie sorprendentemente lungimiranti che gli hanno permesso di ottenere il punteggio massimo raggiungibile: ad esempio, in Breakout , ha imparato a scavare prima un tunnel a un'estremità del muro di mattoni, in modo che la palla rimbalzasse dietro e butta giù i mattoni da dietro.
Politica e reti di valore
Esistono due tipi principali di reti all'interno di AlphaGo:
Uno degli obiettivi dei DQN di AlphaGo è andare oltre il gioco degli esperti umani e imitare nuove mosse innovative, giocando contro se stesso milioni di volte e migliorando così in modo incrementale i pesi. Questo DQN ha avuto una percentuale di vincita dell'80% rispetto ai comuni DNN. DeepMind ha deciso di combinare queste due reti neurali (DNN e DQN) per formare il primo tipo di rete: una "rete politica". In breve, il compito di una rete politica è di ridurre l'ampiezza della ricerca della mossa successiva e di elaborare alcune buone mosse che valgano la pena esplorare ulteriormente.
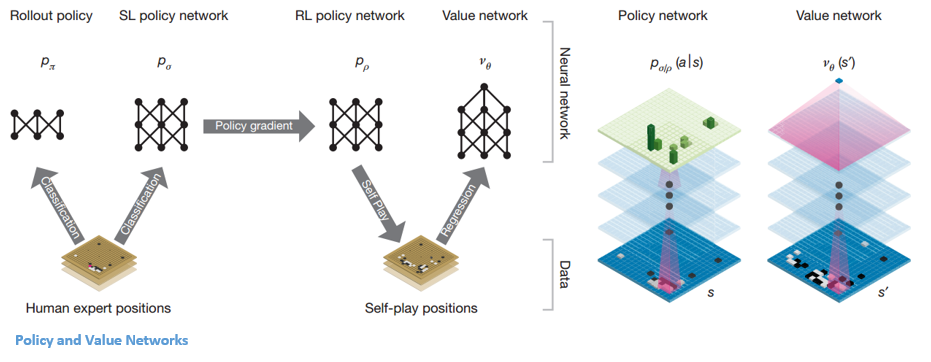 Una volta che la rete politica è congelata, gioca contro se stessa milioni di volte. Questi giochi generano un nuovo set di dati Go, costituito dalle varie posizioni del tabellone e dai risultati dei giochi. Questo set di dati viene utilizzato per creare una funzione di valutazione. Il secondo tipo di funzione, la "Rete del valore", viene utilizzata per prevedere l'esito del gioco. Impara a prendere varie posizioni del tabellone come input e prevedere l'esito del gioco e la sua misura.
Una volta che la rete politica è congelata, gioca contro se stessa milioni di volte. Questi giochi generano un nuovo set di dati Go, costituito dalle varie posizioni del tabellone e dai risultati dei giochi. Questo set di dati viene utilizzato per creare una funzione di valutazione. Il secondo tipo di funzione, la "Rete del valore", viene utilizzata per prevedere l'esito del gioco. Impara a prendere varie posizioni del tabellone come input e prevedere l'esito del gioco e la sua misura.
Combinare la politica e le reti del valore
Dopo tutta questa formazione, DeepMind ha finalmente ottenuto due reti neurali: Policy e Value Networks. La rete politica prende la posizione del board come input e restituisce la distribuzione di probabilità come probabilità di ciascuna delle mosse in quella posizione. La rete del valore prende nuovamente la posizione del tabellone come input ed emette un unico numero reale compreso tra 0 e 1. Se l'output della rete è zero, significa che il bianco sta vincendo completamente e 1 indica una vittoria completa per il giocatore con il nero pietre.
La rete delle politiche valuta le posizioni attuali e la rete del valore valuta le mosse future. La divisione dei compiti in queste due reti da parte di DeepMind è stata una delle ragioni principali del successo di AlphaGo.
Combinazione di policy e reti di valore con Monte Carlo Tree Search (MCTS) e rollout
Le reti neurali da sole non saranno sufficienti. Per vincere la partita di Go, è necessaria una strategia in più. Questo piano è realizzato con l'aiuto di MCTS. Monte Carlo Tree Search aiuta anche a unire le due reti neurali in modo innovativo. Le reti neurali aiutano in una ricerca efficiente della prossima mossa migliore.
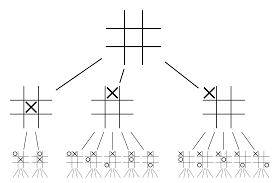
Proviamo a costruire un esempio che ti aiuterà a visualizzare tutto questo molto meglio. Immagina che il gioco sia in una nuova posizione, mai incontrata prima. In tale situazione, una rete politica è chiamata a valutare la situazione attuale ei possibili percorsi futuri; così come la desiderabilità dei percorsi e il valore di ogni mossa da parte delle reti Value, supportate dai rollout Monte Carlo.
La rete politica trova tutte le possibili mosse "buone" e le reti di valore valutano ciascuno dei loro risultati. Nei rollout di Monte Carlo, vengono giocate alcune migliaia di partite casuali dalle posizioni riconosciute dalla rete politica. Sono stati condotti esperimenti per determinare l'importanza relativa delle reti di valore rispetto alle implementazioni Monte Carlo. Come risultato di questa sperimentazione, DeepMind ha assegnato l'80% di ponderazione alle reti Value e il 20% di ponderazione alla funzione di valutazione del rollout Monte Carlo.
La rete politica riduce l'ampiezza della ricerca da 200 mosse possibili alle 4 o 5 mosse migliori. La rete delle politiche espande l'albero da questi 4 o 5 passaggi che devono essere presi in considerazione. La rete del valore aiuta a ridurre la profondità della ricerca dell'albero restituendo istantaneamente il risultato del gioco da quella posizione. Infine viene selezionata la mossa con il valore Q più alto, ovvero il passo con il massimo beneficio.
" Il gioco si gioca principalmente attraverso l'intuizione e il tatto, e per la sua bellezza, sottigliezza e profondità intellettuale ha catturato l'immaginazione umana per secoli."
– Demis Hassabis
Applicazione di AlphaGo ai problemi del mondo reale
La visione di DeepMind, dal loro sito Web, è molto eloquente: "Risolvi l'intelligenza. Usa questa conoscenza per rendere il mondo un posto migliore”. L'obiettivo finale di questo algoritmo è renderlo generico in modo che possa essere utilizzato per risolvere complessi problemi del mondo reale. AlphaGo di DeepMind è un significativo passo avanti nella ricerca di AGI. DeepMind ha utilizzato con successo la sua tecnologia per risolvere problemi del mondo reale: diamo un'occhiata ad alcuni esempi:
Riduzione dei consumi energetici
L'intelligenza artificiale di DeepMind è stata utilizzata con successo per ridurre del 40% i costi di raffreddamento del data center di Google. In qualsiasi ambiente che consuma energia su larga scala, questo miglioramento è un fenomenale passo avanti. Una delle principali fonti di consumo di energia per un data center è il raffreddamento. Molto calore generato dall'esecuzione dei server deve essere rimosso per mantenerlo operativo. Ciò è ottenuto da apparecchiature industriali su larga scala come pompe, refrigeratori e torri di raffreddamento. Poiché l'ambiente del data center è molto dinamico, è difficile operare con un'efficienza energetica ottimale. L'IA di DeepMind è stata utilizzata per affrontare questo problema.
In primo luogo, hanno proceduto utilizzando i dati storici, che sono stati raccolti da migliaia di sensori all'interno del data center. Utilizzando questi dati, hanno addestrato un insieme di DNN sull'efficacia media del consumo energetico (PUE) futura. Poiché si tratta di un algoritmo generico, si prevede che verrà applicato anche ad altre sfide, nell'ambiente del data center.
Le possibili applicazioni di questa tecnologia includono ottenere più energia dalla stessa unità di input, ridurre l'energia di produzione di semiconduttori e il consumo di acqua, ecc. DeepMind ha annunciato nel suo post sul blog che questa conoscenza sarebbe stata condivisa in una futura pubblicazione in modo che altri data center, gli operatori e, in definitiva, l'ambiente possono trarre grandi vantaggi da questo significativo passaggio.
Pianificazione della radioterapia per i tumori della testa e del collo
DeepMind ha collaborato con il dipartimento di radioterapia dell'NHS Foundation Trust dell'University College London Hospital, leader mondiale nel trattamento del cancro.
Come Big Data e Machine Learning si uniscono contro il cancro
A un uomo su 75 e a una donna su 150 viene diagnosticato un cancro orale nel corso della loro vita. A causa della natura sensibile delle strutture e degli organi nella zona della testa e del collo, i radiologi devono prestare la massima attenzione durante il trattamento.
Prima di somministrare la radioterapia, è necessario preparare una mappa dettagliata con le aree da trattare e le aree da evitare. Questo è noto come segmentazione. Questa mappa segmentata viene inserita nella macchina radiografica, che quindi prenderà di mira le cellule tumorali senza danneggiare le cellule sane.
In caso di cancro della regione della testa o del collo, questo è un lavoro scrupoloso per i radiologi poiché coinvolge organi molto sensibili. I radiologi impiegano circa quattro ore per creare una mappa segmentata per quest'area. DeepMind, attraverso i suoi algoritmi, punta a ridurre il tempo necessario per la generazione delle mappe segmentate, da quattro a un'ora. Ciò libererà notevolmente il tempo del radiologo. Ancora più importante, questo algoritmo di segmentazione può essere utilizzato per altre parti del corpo.
Per riassumere, AlphaGo ha battuto con successo il 18 volte campione del mondo di Go, Lee Seedol, quattro volte in un torneo al meglio dei cinque nel 2016. Nel 2017, ha persino battuto una squadra dei migliori giocatori del mondo. Utilizza una combinazione di DNN e DQN come rete politica per elaborare la prossima mossa migliore e un DNN come rete di valore per valutare l'esito del gioco. La ricerca ad albero Monte Carlo viene utilizzata insieme alla politica e alle reti di valore per ridurre l'ampiezza e la profondità della ricerca: vengono utilizzate per migliorare la funzione di valutazione. Lo scopo ultimo di questo algoritmo non è quello di risolvere giochi da tavolo ma di inventare un algoritmo di Intelligenza Generale Artificiale. AlphaGo è senza dubbio un grande passo avanti in quella direzione.
La differenza tra data science, machine learning e big data!
Naturalmente, ci sono stati altri effetti. Quando la notizia di AlphaGo Vs Lee Seedol è diventata virale, la richiesta di schede Go è aumentata di dieci volte. Molti negozi hanno segnalato casi di schede Go esaurite ed è diventato difficile acquistare una scheda Go.
Fortunatamente, ne ho appena trovato uno e l'ho ordinato per me e mio figlio. Hai intenzione di acquistare la tavola e imparare Go?
Impara i corsi ML dalle migliori università del mondo. Guadagna master, Executive PGP o programmi di certificazione avanzati per accelerare la tua carriera.
Quali sono i limiti dell'apprendimento per rinforzo profondo?
DL dimentica le conoscenze acquisite in precedenza quando vengono introdotti nuovi dati o informazioni, quindi non lo mette in discussione. Troppo rinforzo a volte può comportare un eccesso di stati, riducendone l'efficacia. A causa della complessità dei modelli di dati, la formazione è estremamente costosa. Il deep learning richiede anche l'uso di costose GPU e centinaia di workstation. Di conseguenza, diventa meno economico da usare.
Quali sono i contro dell'utilizzo di Monte Carlo Tree Search?
Sebbene MCTS sia un algoritmo semplice da eseguire, presenta alcuni inconvenienti. Quando l'albero diventa più grande dopo alcune iterazioni, è necessaria molta memoria. Se applicato ai giochi a turni, potrebbe esserci un singolo ramo o percorso che porta a una sconfitta contro l'avversario in condizioni specifiche. Di conseguenza, è un po' meno affidabile. Dopo molte iterazioni, Monte Carlo Tree Search impiega molto tempo per determinare il percorso più efficace.
In che modo AlphaZero è diverso da AlphaGo Zero?
Le versioni precedenti di AlphaGo incorporavano un numero esiguo di funzionalità progettate a mano, ma AlphaGo Zero utilizza solo le pietre bianche e nere della scheda Go come input. Le versioni precedenti di AlphaGo facevano affidamento su una rete politica per scegliere la mossa successiva e una rete di valore per stimare il vincitore del gioco da ciascuna posizione. Questi sono fusi in AlphaGo Zero, consentendo una formazione e una valutazione più efficienti. Tutte queste differenze contribuiscono al miglioramento delle prestazioni e alla generalizzazione del sistema. La regolazione algoritmica, invece, rende il sistema molto più potente ed efficiente.