
10 Teknik Pengurangan Dimensi Teratas Untuk Pembelajaran Mesin
Diterbitkan: 2020-08-07Setiap detik, dunia menghasilkan volume data yang belum pernah terjadi sebelumnya. Karena data telah menjadi komponen penting bisnis dan organisasi di semua industri, penting untuk memproses, menganalisis, dan memvisualisasikannya dengan tepat untuk mengekstrak wawasan yang berarti dari kumpulan data besar. Namun, ada tangkapan – lebih banyak tidak selalu berarti produktif dan akurat. Semakin banyak data yang kami hasilkan setiap detik, semakin sulit untuk menganalisis dan memvisualisasikannya untuk menarik kesimpulan yang valid.
Di sinilah Pengurangan Dimensi berperan.
Daftar isi
Apa itu Pengurangan Dimensi?
Dengan kata sederhana, pengurangan dimensi mengacu pada teknik pengurangan dimensi kumpulan fitur data. Biasanya, kumpulan data pembelajaran mesin (kumpulan fitur) berisi ratusan kolom (yaitu, fitur) atau larik titik, menciptakan bola besar dalam ruang tiga dimensi. Dengan menerapkan pengurangan dimensi , Anda dapat mengurangi atau menurunkan jumlah kolom ke jumlah yang dapat diukur, sehingga mengubah bola tiga dimensi menjadi objek dua dimensi (lingkaran).
Sekarang muncul pertanyaan, mengapa Anda harus mengurangi kolom dalam kumpulan data ketika Anda dapat langsung memasukkannya ke dalam algoritme ML dan membiarkannya menyelesaikan semuanya dengan sendirinya?
Kutukan dimensi mengamanatkan penerapan pengurangan dimensi .
Kutukan Dimensi
Kutukan dimensi adalah fenomena yang muncul ketika Anda bekerja (menganalisis dan memvisualisasikan) dengan data di ruang berdimensi tinggi yang tidak ada di ruang berdimensi rendah.

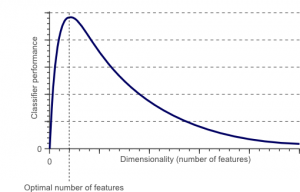
Sumber
Semakin tinggi jumlah fitur atau faktor (alias variabel) dalam set fitur, semakin sulit untuk memvisualisasikan set pelatihan dan mengerjakannya. Hal penting lain yang perlu dipertimbangkan adalah bahwa sebagian besar variabel sering berkorelasi. Jadi, jika menurut Anda setiap variabel dalam set fitur, Anda akan memasukkan banyak faktor yang berlebihan dalam set pelatihan.
Selanjutnya, semakin banyak variabel yang Anda miliki, semakin tinggi jumlah sampel untuk mewakili semua kemungkinan kombinasi nilai fitur dalam contoh. Ketika jumlah variabel meningkat, model akan menjadi lebih kompleks, sehingga meningkatkan kemungkinan overfitting. Saat Anda melatih model ML pada kumpulan data besar yang berisi banyak fitur, model tersebut pasti akan bergantung pada data pelatihan. Ini akan menghasilkan model overfitted yang gagal berkinerja baik pada data nyata.
Tujuan utama pengurangan dimensi adalah untuk menghindari overfitting. Data pelatihan dengan fitur yang jauh lebih sedikit akan memastikan model Anda tetap sederhana – ini akan membuat asumsi yang lebih kecil.
Selain itu, pengurangan dimensi memiliki banyak manfaat lain, seperti:
- Ini menghilangkan noise dan fitur yang berlebihan.
- Ini membantu meningkatkan akurasi dan kinerja model.
- Ini memfasilitasi penggunaan algoritma yang tidak cocok untuk dimensi yang lebih substansial.
- Ini mengurangi jumlah ruang penyimpanan yang dibutuhkan (lebih sedikit data membutuhkan lebih sedikit ruang penyimpanan).
- Ini memampatkan data, yang mengurangi waktu komputasi dan memfasilitasi pelatihan data yang lebih cepat.
Baca : Apa itu analisis diskriminan linier
Teknik Pengurangan Dimensi
Teknik pengurangan dimensi dapat dikategorikan ke dalam dua kategori besar:
1. Pemilihan fitur
Metode pemilihan fitur bertujuan untuk menemukan subset dari variabel input (yang paling relevan) dari dataset asli. Pemilihan fitur mencakup tiga strategi, yaitu:
- Filter strategi
- Strategi pembungkus
- Strategi tertanam
2. Ekstraksi fitur
Ekstraksi fitur, alias, proyeksi fitur, mengubah data dari ruang berdimensi tinggi menjadi satu dengan dimensi yang lebih rendah. Transformasi data ini mungkin linier atau mungkin juga nonlinier. Teknik ini menemukan sekumpulan variabel baru yang lebih kecil, yang masing-masing merupakan kombinasi dari variabel input (berisi informasi yang sama dengan variabel input).
Tanpa basa-basi lagi, mari selami diskusi mendetail tentang beberapa teknik pengurangan dimensi yang umum digunakan!
1. Analisis Komponen Utama (PCA)
Analisis Komponen Utama adalah salah satu teknik linier terkemuka pengurangan dimensi. Metode ini melakukan pemetaan langsung data ke ruang dimensi yang lebih rendah dengan cara yang memaksimalkan varians data dalam representasi dimensi rendah.
Pada dasarnya, ini adalah prosedur statistik yang secara ortogonal mengubah koordinat 'n' dari kumpulan data menjadi kumpulan koordinat n baru , yang dikenal sebagai komponen utama. Konversi ini menghasilkan penciptaan komponen utama pertama yang memiliki varians maksimum. Setiap komponen utama berikutnya memiliki varians tertinggi yang mungkin, dengan syarat komponen tersebut ortogonal (tidak berkorelasi) dengan komponen sebelumnya.
Konversi PCA sensitif terhadap penskalaan relatif dari variabel asli. Dengan demikian, rentang kolom data harus dinormalisasi terlebih dahulu sebelum menerapkan metode PCA. Hal lain yang perlu diingat adalah bahwa menggunakan pendekatan PCA akan membuat dataset Anda kehilangan kemampuan interpretasinya. Jadi, jika interpretabilitas sangat penting untuk analisis Anda, PCA bukanlah metode pengurangan dimensi yang tepat untuk proyek Anda.
2. Faktorisasi matriks non-negatif (NMF)
NMF memecah matriks non-negatif menjadi produk dari dua matriks non-negatif. Inilah yang menjadikan metode NMF alat yang berharga di area yang terutama berkaitan dengan sinyal non-negatif (misalnya, astronomi). Aturan pembaruan multiplikasi oleh Lee & Seung meningkatkan teknik NMF dengan – termasuk ketidakpastian, mempertimbangkan data yang hilang dan komputasi paralel, dan konstruksi sekuensial.
Inklusi ini berkontribusi untuk membuat pendekatan NMF stabil dan linier. Tidak seperti PCA, NMF tidak menghilangkan rata-rata matriks, sehingga menciptakan fluks non-negatif non-fisik. Dengan demikian, NMF dapat menyimpan lebih banyak informasi daripada metode PCA.
NMF berurutan dicirikan oleh basis komponen yang stabil selama konstruksi dan proses pemodelan linier. Ini menjadikannya alat yang sempurna dalam astronomi. NMF berurutan dapat mempertahankan fluks dalam pencitraan langsung struktur circumstellar dalam astronomi, seperti mendeteksi exoplanet dan pencitraan langsung piringan circumstellar.
3. Analisis diskriminan linier (LDA)
Analisis diskriminan linier merupakan generalisasi dari metode diskriminan linier Fisher yang banyak diterapkan dalam statistik, pengenalan pola, dan pembelajaran mesin. Teknik LDA bertujuan untuk menemukan kombinasi linear dari fitur-fitur yang dapat mencirikan atau membedakan antara dua atau lebih kelas objek. LDA mewakili data dengan cara yang memaksimalkan pemisahan kelas. Sementara benda-benda milik kelas yang sama disandingkan melalui proyeksi, benda-benda dari kelas yang berbeda diatur berjauhan.
4. Analisis diskriminan umum (GDA)
Analisis diskriminan umum adalah analisis diskriminan nonlinier yang memanfaatkan operator fungsi kernel. Teori yang mendasarinya sangat cocok dengan mesin vektor pendukung (SVM), sehingga teknik GDA membantu memetakan vektor input ke dalam ruang fitur dimensi tinggi. Sama seperti pendekatan LDA, GDA juga berusaha menemukan proyeksi untuk variabel dalam ruang dimensi yang lebih rendah dengan memaksimalkan rasio pencar antar kelas dengan pencar dalam kelas.

5. Rasio Nilai yang Hilang
Saat Anda menjelajahi kumpulan data tertentu, Anda mungkin menemukan bahwa ada beberapa nilai yang hilang dalam kumpulan data. Langkah pertama dalam menangani nilai-nilai yang hilang adalah mengidentifikasi alasan di baliknya. Dengan demikian, Anda kemudian dapat memasukkan nilai yang hilang atau menghapusnya sama sekali dengan menggunakan metode yang sesuai. Pendekatan ini sangat cocok untuk situasi ketika ada beberapa nilai yang hilang.
Namun, apa yang harus dilakukan ketika ada terlalu banyak nilai yang hilang, katakanlah, lebih dari 50%? Dalam situasi seperti itu, Anda dapat menetapkan nilai ambang dan menggunakan metode rasio nilai yang hilang. Semakin tinggi nilai ambang batas, semakin agresif pengurangan dimensi. Jika persentase nilai yang hilang dalam suatu variabel melebihi ambang batas, Anda dapat menghapus variabel tersebut.
Umumnya, kolom data yang memiliki banyak nilai yang hilang hampir tidak mengandung informasi yang berguna. Jadi, Anda dapat menghapus semua kolom data yang memiliki nilai yang hilang lebih tinggi dari ambang batas yang ditetapkan.
6. Filter Varians Rendah
Sama seperti Anda menggunakan metode rasio nilai yang hilang untuk variabel yang hilang, demikian juga untuk variabel konstan, ada teknik filter varians rendah. Ketika dataset memiliki variabel konstan, tidak mungkin untuk meningkatkan kinerja model. Mengapa? Karena memiliki varians nol.
Dalam metode ini juga, Anda dapat menetapkan nilai ambang batas untuk menghapus semua variabel konstan. Jadi, semua kolom data dengan varians lebih rendah dari nilai ambang batas akan dihilangkan. Namun, satu hal yang harus Anda ingat tentang metode filter varians rendah adalah bahwa varians bergantung pada rentang. Dengan demikian, normalisasi adalah suatu keharusan sebelum menerapkan teknik pengurangan dimensi ini.
7. Filter Korelasi Tinggi
Jika kumpulan data terdiri dari kolom data yang memiliki banyak pola/tren yang serupa, kolom data ini kemungkinan besar berisi informasi yang identik. Selain itu, dimensi yang menggambarkan korelasi yang lebih tinggi dapat berdampak buruk pada kinerja model. Dalam contoh seperti itu, salah satu variabel tersebut cukup untuk memberi makan model ML.
Untuk situasi seperti itu, yang terbaik adalah menggunakan matriks korelasi Pearson untuk mengidentifikasi variabel yang menunjukkan korelasi tinggi. Setelah diidentifikasi, Anda dapat memilih salah satunya menggunakan VIF (Variance Inflation Factor). Anda dapat menghapus semua variabel yang memiliki nilai lebih tinggi ( VIF > 5 ). Dalam pendekatan ini, Anda harus menghitung koefisien korelasi antara kolom numerik ( Koefisien Momen Produk Pearson ) dan antara kolom nominal ( nilai chi-kuadrat Pearson ). Di sini, semua pasangan kolom yang memiliki koefisien korelasi lebih tinggi dari ambang batas yang ditetapkan akan dikurangi menjadi 1.
Karena korelasi peka terhadap skala, Anda harus melakukan normalisasi kolom.
8. Penghapusan Fitur Mundur
Dalam teknik eliminasi fitur mundur, Anda harus mulai dengan semua dimensi 'n'. Jadi, pada iterasi yang diberikan, Anda dapat melatih algoritma klasifikasi tertentu yang dilatih pada n fitur input. Sekarang, Anda harus menghapus satu fitur input pada satu waktu dan melatih model yang sama pada n-1 variabel input n kali. Kemudian Anda menghapus variabel input yang eliminasinya menghasilkan peningkatan terkecil dalam tingkat kesalahan, yang meninggalkan n-1 fitur input. Selanjutnya, Anda mengulangi klasifikasi menggunakan fitur n-2 , dan ini berlanjut hingga tidak ada variabel lain yang dapat dihapus.
Setiap iterasi ( k) membuat model yang dilatih pada fitur nk yang memiliki tingkat kesalahan e(k) . Setelah ini, Anda harus memilih tingkat kesalahan maksimum yang dapat ditanggung untuk menentukan jumlah fitur terkecil yang diperlukan untuk mencapai kinerja klasifikasi tersebut dengan algoritme ML yang diberikan.
Baca Juga: Mengapa Analisis Data Penting dalam Bisnis
9. Konstruksi Fitur Maju
Konstruksi fitur maju adalah kebalikan dari metode penghapusan fitur mundur. Dalam metode konstruksi fitur maju, Anda mulai dengan satu fitur dan terus maju dengan menambahkan satu fitur pada satu waktu (ini adalah variabel yang menghasilkan peningkatan kinerja terbesar).
Konstruksi fitur maju dan penghapusan fitur mundur membutuhkan waktu dan komputasi yang intensif. Metode ini paling cocok untuk kumpulan data yang sudah memiliki jumlah kolom input yang sedikit.
10. Hutan Acak
Hutan acak tidak hanya pengklasifikasi yang sangat baik tetapi juga sangat berguna untuk pemilihan fitur. Dalam pendekatan pengurangan dimensi ini, Anda harus hati-hati membangun jaringan pohon yang luas terhadap atribut target. Misalnya, Anda dapat membuat satu set besar (misalnya, 2000) pohon dangkal (misalnya, memiliki dua tingkat), di mana setiap pohon dilatih pada fraksi kecil (3) dari jumlah total atribut.
Tujuannya adalah untuk menggunakan statistik penggunaan setiap atribut untuk mengidentifikasi subset fitur yang paling informatif. Jika suatu atribut ditemukan sebagai pemisahan terbaik, biasanya atribut tersebut berisi fitur informatif yang layak untuk dipertimbangkan. Saat Anda menghitung skor statistik penggunaan atribut di hutan acak dalam kaitannya dengan atribut lain, ini memberi Anda atribut yang paling prediktif.
Kesimpulan
Kesimpulannya, dalam hal pengurangan dimensi, tidak ada teknik yang benar-benar terbaik. Masing-masing memiliki kekhasan dan kelebihannya. Jadi, cara terbaik untuk menerapkan teknik pengurangan dimensi adalah dengan menggunakan eksperimen sistematis dan terkontrol untuk mencari tahu teknik mana yang bekerja dengan model Anda dan mana yang memberikan kinerja terbaik pada kumpulan data tertentu.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT- B Status alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa itu Pengurangan Dimensi?
Pengurangan dimensi adalah teknik yang digunakan dalam penambangan data untuk memetakan data berdimensi tinggi ke dalam representasi berdimensi rendah untuk memvisualisasikan data dan menemukan pola yang tidak terlihat dengan menggunakan metode tradisional. Ini sering digunakan bersama dengan teknik pengelompokan atau teknik klasifikasi untuk memproyeksikan data ke ruang dimensi yang lebih rendah untuk memfasilitasi visualisasi data dan menemukan pola.
Apa cara untuk mengurangi dimensi?
Teknik reduksi 3 dimensi sangat populer dan banyak digunakan. 1. Principal Component Analysis (PCA): Ini adalah metode untuk mengurangi dimensi kumpulan data dengan mengubahnya menjadi sistem koordinat baru sehingga varians terbesar dalam data dijelaskan oleh koordinat pertama dan varians terbesar kedua dijelaskan dengan koordinat kedua, dan seterusnya. 2. Analisis Faktor: Ini adalah teknik statistik untuk mengekstraksi variabel independen (juga disebut faktor) dari kumpulan data. Tujuannya adalah untuk menyederhanakan atau mengurangi jumlah variabel dalam suatu kumpulan data. 3. Analisis Korespondensi: Ini adalah metode serbaguna yang memungkinkan seseorang untuk secara bersamaan mempertimbangkan variabel kategorikal dan kontinu dalam kumpulan data.
Apa kerugian dari pengurangan dimensi?
Kerugian utama dari pengurangan dimensi adalah tidak menjamin rekonstruksi data asli. Misalnya, di PCA, dua titik data yang sangat berdekatan di ruang input mungkin berakhir sangat jauh satu sama lain di output. Hal ini membuat sulit untuk menemukan titik input dalam data output. Selain itu, data mungkin lebih sulit untuk ditafsirkan setelah pengurangan dimensi. Misalnya, di PCA, Anda masih dapat menganggap komponen pertama sebagai komponen utama pertama, tetapi tidak mudah untuk memberikan makna pada komponen kedua atau lebih tinggi. Dari sudut pandang praktis, karena kelemahan ini, reduksi dimensi umumnya diikuti dengan melakukan pengelompokan k-means atau teknik reduksi dimensi lain pada dataset.