
Go et le défi de l'intelligence artificielle générale
Publié: 2018-02-15Cet article vise à explorer le lien entre le jeu 'Go' et l'intelligence artificielle. L'objectif est de répondre aux questions – Qu'est-ce qui rend le jeu de Go si spécial ? Pourquoi maîtriser le jeu de Go était-il difficile pour un ordinateur ? Pourquoi un programme informatique a-t-il pu battre un grand maître d'échecs en 1997 ? Pourquoi a-t-il fallu près de deux décennies pour craquer Go ?
"Les messieurs ne devraient pas perdre leur temps sur des jeux triviaux - ils devraient étudier Go"
– Confucius
En fait, les experts en intelligence artificielle pensaient que les ordinateurs ne pourraient battre un champion du monde de Go qu'en 2027. Grâce à DeepMind, une société d'intelligence artificielle sous l'égide de Google, cette tâche formidable a été accomplie une décennie plus tôt. Cet article parlera des technologies utilisées par DeepMind pour battre le champion du monde de Go. Enfin, cet article explique comment cette technologie peut être utilisée pour résoudre certains problèmes complexes du monde réel.
Table des matières
Allez - Qu'est-ce que c'est ?
Go est un jeu de société de stratégie chinois vieux de 3000 ans, qui a conservé sa popularité à travers les âges. Joué par des dizaines de millions de personnes dans le monde, Go est un jeu de société à deux joueurs avec des règles simples et une stratégie intuitive. Différentes tailles de plateau sont utilisées pour jouer à ce jeu; les professionnels utilisent une planche 19×19.

Le jeu commence avec un plateau vide. Chaque joueur place ensuite à tour de rôle les pierres noires et blanches (le noir joue en premier) sur le plateau, à l'intersection des lignes (contrairement aux échecs, où l'on place des pièces dans les cases). Un joueur peut capturer les pierres de l'adversaire en l'entourant de tous les côtés. Pour chaque pierre capturée, des points sont attribués au joueur. L'objectif du jeu est d'occuper un maximum de territoire sur le plateau tout en capturant les pierres de vos adversaires.
Le go concerne la création, contrairement aux échecs, qui concernent la destruction. Go nécessite liberté, créativité, intuition, équilibre, stratégie et profondeur intellectuelle pour maîtriser le jeu. Jouer au go implique les deux côtés du cerveau. En fait, les scanners cérébraux des joueurs de Go ont révélé que Go aide au développement du cerveau en améliorant les connexions entre les deux hémisphères cérébraux.
Les réseaux de neurones pour les nuls : un guide complet
Go et le défi de l'intelligence artificielle (IA)
Les ordinateurs étaient capables de maîtriser le Tic-Tac-Toe en 1952 . Deep Blue a pu battre le grand maître des échecs Garry Kasparov en 1997 . Le programme informatique a pu gagner contre le champion du monde de Jeopardy (un jeu populaire américain) en 2001 . L'AlphaGo de DeepMind a réussi à vaincre un champion du monde de Go en 2016 . Pourquoi est-il difficile pour un programme informatique de maîtriser le jeu de Go ?
Les échecs se jouent sur un plateau 8 × 8 alors que Go utilise un plateau de taille 19 × 19. Dans l'ouverture d'une partie d'échecs, un joueur aura 20 coups possibles. Dans une ouverture de Go, un joueur peut avoir 361 coups possibles. Le nombre de positions possibles sur le plateau de Go est égal à 10 puissance 170 ; plus que le nombre d'atomes de notre univers ! Le nombre potentiel de positions sur l'échiquier rend les temps Go googol (10 à la puissance 100) plus complexes que les échecs.
Aux échecs, pour chaque étape, un joueur est confronté à un choix de 35 coups. En moyenne, un joueur de Go aura 250 coups possibles à chaque étape. Aux échecs, à n'importe quelle position donnée, il est relativement facile pour un ordinateur d'effectuer une recherche par force brute et de choisir le meilleur coup possible qui maximise les chances de gagner. Une recherche par force brute n'est pas possible dans le cas du Go, car le nombre potentiel de mouvements légaux autorisés pour chaque étape est énorme.
Pour qu'un ordinateur maîtrise les échecs, cela devient plus facile au fur et à mesure que le jeu progresse car les pièces sont retirées de l'échiquier. Au Go, cela devient plus difficile pour le programme informatique car des pierres sont ajoutées au plateau au fur et à mesure que le jeu progresse. Typiquement, une partie de Go durera 3 fois plus longtemps qu'une partie d'échecs.
Pour toutes ces raisons, un programme informatique de haut niveau n'a pu rattraper le champion du monde de Go qu'en 2016, après une énorme explosion de nouvelles techniques d'apprentissage automatique. Les scientifiques travaillant chez DeepMind ont pu mettre au point un programme informatique appelé AlphaGo qui a vaincu le champion du monde Lee Seedol . Réaliser la tâche n'a pas été facile. Les chercheurs de DeepMind ont proposé de nombreuses innovations dans le processus de création d'AlphaGo.
"Les règles de Go sont si élégantes, organiques et rigoureusement logiques que si des formes de vie intelligentes existent ailleurs dans l'univers, elles jouent presque certainement au Go."
– Edouard Laskar
Réseaux de neurones : applications dans le monde réel
Comment fonctionne AlphaGo
AlphaGo est un algorithme à usage général, ce qui signifie qu'il peut également être utilisé pour résoudre d'autres tâches. Par exemple, Deep Blue d'IBM est spécialement conçu pour jouer aux échecs. Les règles des échecs ainsi que les connaissances accumulées au fil des siècles de jeu sont programmées dans le cerveau du programme. Deep Blue ne peut pas être utilisé même pour jouer à des jeux triviaux comme Tic-Tac-Toe. Il ne peut faire qu'une chose précise, pour laquelle il est très doué, c'est-à-dire jouer aux échecs. AlphaGo peut également apprendre à jouer à d'autres jeux en dehors de Go. Ces algorithmes à usage général constituent un nouveau domaine de recherche, appelé Intelligence Artificielle Générale.
AlphaGo utilise des méthodes de pointe - Deep Neural Networks (DNN), Reinforcement Learning (RL), Monte Carlo Tree Search (MCTS), Deep Q Networks (DQN) (une nouvelle technique introduite et popularisée par DeepMind qui combine les réseaux avec apprentissage par renforcement), pour n'en nommer que quelques-uns. Il combine ensuite toutes ces méthodes de manière innovante pour atteindre un niveau de maîtrise surhumain dans le jeu de Go.
Examinons d'abord chaque pièce individuelle de ce puzzle avant d'expliquer comment ces pièces sont liées ensemble pour accomplir la tâche à accomplir.
Réseaux de neurones profonds
Les DNN sont une technique d'apprentissage automatique, vaguement inspirée du fonctionnement du cerveau humain. L'architecture d'un DNN est constituée de couches de neurones. DNN peut reconnaître des modèles dans les données sans être explicitement programmé pour cela.
Il mappe les entrées aux sorties sans que personne ne le programme spécifiquement pour la même chose. A titre d'exemple, supposons que nous ayons alimenté le réseau avec beaucoup de photos de chats et de chiens. Dans le même temps, nous entraînons également le système en lui indiquant (sous forme d'étiquettes) si une image particulière est celle d'un chat ou d'un chien (c'est ce qu'on appelle l'apprentissage supervisé). Un DNN apprendra à reconnaître le motif des photos pour réussir à différencier un chat d'un chien. L'objectif principal de la formation est que lorsqu'un DNN voit une nouvelle photo d'un chien ou d'un chat, il doit être capable de la classer correctement, c'est-à-dire de prédire s'il s'agit d'un chat ou d'un chien.
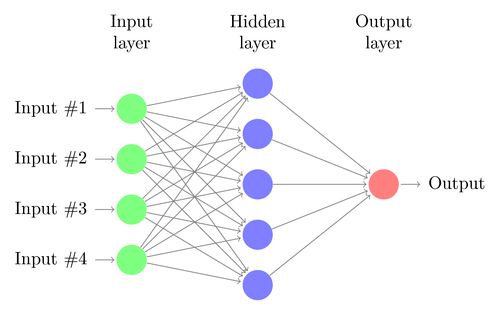
Comprenons l'architecture d'un DNN simple. Le nombre de neurones dans la couche d'entrée correspond à la taille de l'entrée. Supposons que nos photos de chat et de chien soient une image 28×28. Chaque ligne et chaque colonne seront composées de 28 pixels chacune, ce qui fait un total de 784 pixels pour chaque image. Dans un tel cas, la couche d'entrée comprendra 784 neurones, un pour chaque pixel. Le nombre de neurones dans la couche de sortie dépendra du nombre de classes dans lesquelles la sortie doit être classée. Dans ce cas, la couche de sortie sera constituée de deux neurones, l'un correspondant à 'chat', l'autre à 'chien'.
Gardez un œil sur la prochaine grande chose : l'apprentissage automatique
Il y aura de nombreuses couches de neurones entre les couches d'entrée et de sortie (ce qui est à l'origine de l'utilisation du terme 'Deep' dans 'Deep Neural Network'). Celles-ci sont appelées "couches cachées". Le nombre de couches cachées et le nombre de neurones dans chaque couche ne sont pas fixes. En fait, la modification de ces valeurs est exactement ce qui conduit à l'optimisation des performances. Ces valeurs sont appelées hyper-paramètres et doivent être ajustées en fonction du problème à résoudre. Les expériences autour des réseaux de neurones consistent en grande partie à trouver le nombre optimal d'hyperparamètres.
La phase d'entraînement des DNN consistera en une passe avant et une passe arrière. Tout d'abord, toutes les connexions entre les neurones sont initialisées avec des poids aléatoires. Lors de la passe aller, le réseau est alimenté avec une seule image. Les entrées (données de pixels de l'image) sont combinées avec les paramètres du réseau (poids, biais et fonctions d'activation) et transmises à travers des couches cachées, jusqu'à la sortie, qui renvoie une probabilité qu'une photo appartienne à chaque des cours.
Ensuite, cette probabilité est comparée à l'étiquette de classe réelle et une « erreur » est calculée. À ce stade, le passage en arrière est effectué - ces informations d'erreur sont renvoyées à travers le réseau via une technique appelée "rétro-propagation". Pendant les phases initiales de formation, cette erreur sera élevée et un bon mécanisme de formation réduira progressivement cette erreur.
Les DNN sont formés de cette manière avec un passage en avant et en arrière jusqu'à ce que les poids cessent de changer (c'est ce qu'on appelle la convergence). Ensuite, les DNN pourront prédire et classer les images avec un haut degré de précision, c'est-à-dire si l'image a un chat ou un chien.

La recherche nous a donné de nombreuses architectures de réseaux de neurones profonds différentes. Pour les problèmes de vision par ordinateur (c'est-à-dire les problèmes impliquant des images), les réseaux de neurones à convolution (CNN) ont traditionnellement donné de bons résultats. Pour les problèmes impliquant une séquence - reconnaissance de la parole ou traduction de la langue - les réseaux de neurones récurrents (RNN) fournissent d'excellents résultats.
Un guide du débutant pour la compréhension du langage naturel
Dans le cas d'AlphaGo, le processus était le suivant : premièrement, le réseau de neurones à convolution (CNN) a été formé sur des millions d'images de postes au conseil d'administration. Ensuite, le réseau a été informé du coup ultérieur joué par les experts humains dans chaque cas pendant la phase de formation du réseau. De la même manière que mentionnée précédemment, la valeur réelle a été comparée à la sortie et une sorte de métrique "d'erreur" a été trouvée.
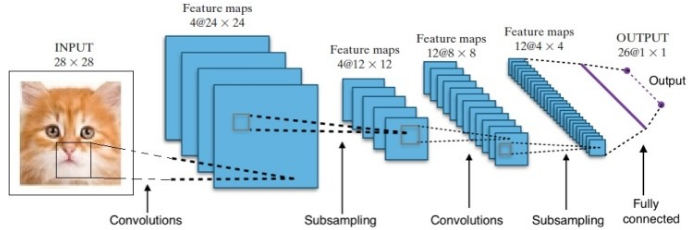
À la fin de l'entraînement, le DNN affichera les prochains mouvements ainsi que les probabilités susceptibles d'être jouées par un joueur humain expert. Ce type de réseau ne peut proposer qu'une étape qui est jouée par un joueur expert humain. DeepMind a pu atteindre une précision de 60 % en prédisant le mouvement que l'humain ferait. Cependant, pour battre un expert humain au Go, cela ne suffit pas. La sortie du DNN est ensuite traitée par Deep Reinforcement Network, une approche conçue par DeepMind, qui combine des réseaux de neurones profonds et un apprentissage par renforcement.
Apprentissage par renforcement profond
L'apprentissage par renforcement (RL) n'est pas un nouveau concept. Le lauréat du prix Nobel Ivan Pavlov a expérimenté le conditionnement classique sur les chiens et a découvert les principes de l'apprentissage par renforcement en 1902. RL est également l'une des méthodes avec lesquelles les humains acquièrent de nouvelles compétences. Vous êtes-vous déjà demandé comment les dauphins des spectacles sont entraînés à sauter à de si grandes hauteurs hors de l'eau ? C'est avec l'aide de RL. Tout d'abord, la corde qui sert à préparer les dauphins est immergée dans le bassin. Chaque fois que le dauphin traverse le câble par le haut, il est récompensé par de la nourriture. Lorsqu'il ne franchit pas la corde, la récompense est retirée. Lentement, le dauphin apprendra qu'il est payé chaque fois qu'il passe la corde par le haut. La hauteur de la corde est augmentée progressivement pour entraîner le dauphin. 
Génération de langage naturel : ce que vous devez savoir
Les agents en apprentissage par renforcement sont également formés selon le même principe. L'agent agira et interagira avec l'environnement. L'action entreprise par l'agent modifie l'environnement. De plus, l'agent a reçu des commentaires sur l'environnement. L'agent est récompensé ou non, selon son action et l'objectif visé. Le point important est que cet objectif à portée de main n'est pas explicitement énoncé pour l'agent. Avec suffisamment de temps, l'agent apprendra comment maximiser les récompenses futures.

En combinant cela avec les DNN, DeepMind a inventé Deep Reinforcement Learning (DRL) ou Deep Q Networks (DQN) où Q représente les récompenses futures maximales obtenues. Les DQN ont d'abord été appliqués aux jeux Atari . DQN a appris à jouer à différents types de jeux Atari dès la sortie de la boîte. La percée était qu'aucune programmation explicite n'était requise pour représenter différents types de jeux Atari. Un seul programme était assez intelligent pour en apprendre davantage sur tous les différents environnements du jeu, et grâce à l'auto-jeu, il était capable de maîtriser plusieurs d'entre eux.
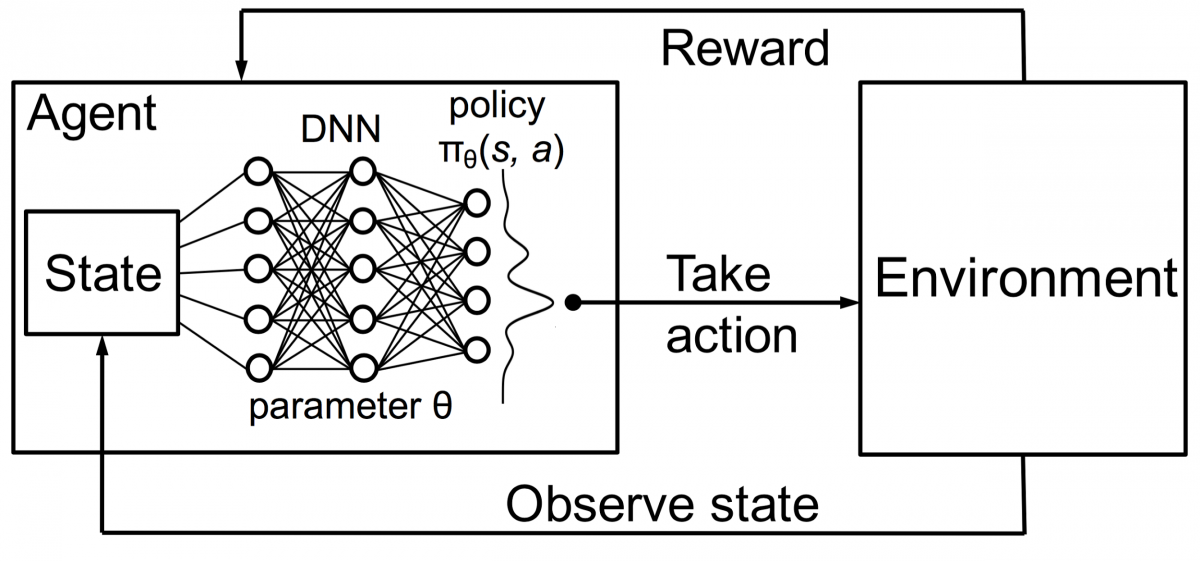
En 2014, DQN a surpassé les méthodes d'apprentissage automatique précédentes dans 43 des 49 jeux (il a maintenant été testé sur plus de 70 jeux). En fait, dans plus de la moitié des matchs, il a joué à plus de 75 % du niveau d'un joueur humain professionnel. Dans certains jeux, DQN a même proposé des stratégies étonnamment clairvoyantes qui lui ont permis d'atteindre le score maximal atteignable. Par exemple, dans Breakout , il a appris à creuser d'abord un tunnel à une extrémité du mur de briques pour que la balle rebondisse. autour du dos et assommez les briques par derrière.
Réseaux de politique et de valeur
Il existe deux principaux types de réseaux dans AlphaGo :
L'un des objectifs des DQN d'AlphaGo est d'aller au-delà du jeu d'expert humain et d'imiter de nouveaux mouvements innovants, en jouant contre lui-même des millions de fois et en améliorant ainsi progressivement les poids. Ce DQN avait un taux de réussite de 80 % par rapport aux DNN courants. DeepMind a décidé de combiner ces deux réseaux de neurones (DNN et DQN) pour former le premier type de réseau – un « Policy Network ». En bref, le travail d'un réseau politique est de réduire l'ampleur de la recherche du prochain coup et de proposer quelques bons coups qui méritent d'être explorés plus avant.
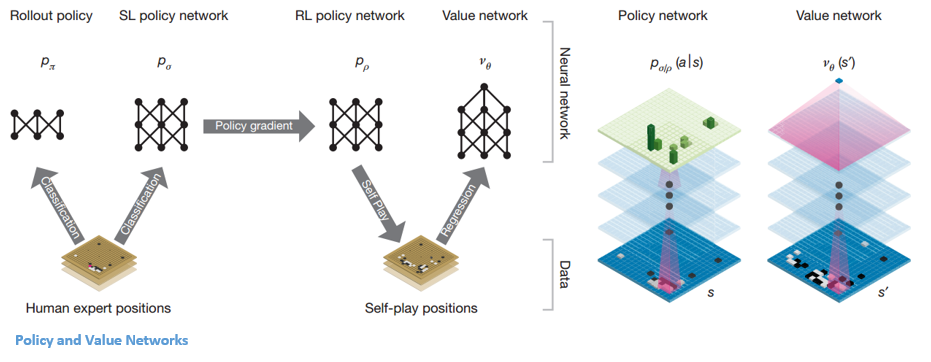 Une fois que le réseau politique est gelé, il joue contre lui-même des millions de fois. Ces jeux génèrent un nouvel ensemble de données Go, composé des différentes positions du plateau et des résultats des jeux. Cet ensemble de données est utilisé pour créer une fonction d'évaluation. Le deuxième type de fonction – le « Value Network » est utilisé pour prédire le résultat du jeu. Il apprend à prendre diverses positions sur le tableau comme entrées et à prédire le résultat du jeu et sa mesure.
Une fois que le réseau politique est gelé, il joue contre lui-même des millions de fois. Ces jeux génèrent un nouvel ensemble de données Go, composé des différentes positions du plateau et des résultats des jeux. Cet ensemble de données est utilisé pour créer une fonction d'évaluation. Le deuxième type de fonction – le « Value Network » est utilisé pour prédire le résultat du jeu. Il apprend à prendre diverses positions sur le tableau comme entrées et à prédire le résultat du jeu et sa mesure.
Combiner les réseaux de politique et de valeur
Après toute cette formation, DeepMind s'est finalement retrouvé avec deux réseaux de neurones - Policy and Value Networks. Le réseau de politiques prend la position au tableau comme entrée et produit la distribution de probabilité comme la probabilité de chacun des mouvements dans cette position. Le réseau de valeur prend à nouveau la position du tableau en entrée et sort un seul nombre réel entre 0 et 1. Si la sortie du réseau est zéro, cela signifie que le blanc est complètement gagnant et 1 indique une victoire complète pour le joueur avec le noir. des pierres.
Le réseau Politique évalue les positions actuelles et le réseau Valeur évalue les mouvements futurs. La répartition des tâches entre ces deux réseaux par DeepMind a été l'une des principales raisons du succès d'AlphaGo.
Combiner les réseaux de politique et de valeur avec Monte Carlo Tree Search (MCTS) et les déploiements
Les réseaux de neurones à eux seuls ne suffiront pas. Pour gagner le jeu de Go, une stratégie supplémentaire est nécessaire. Ce plan est réalisé avec l'aide de MCTS. Monte Carlo Tree Search aide également à assembler les deux réseaux de neurones de manière innovante. Les réseaux de neurones aident à une recherche efficace du prochain meilleur mouvement.
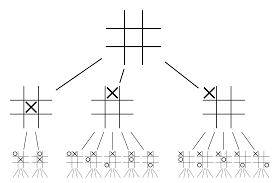
Essayons de construire un exemple qui vous aidera à mieux visualiser tout cela. Imaginez que le jeu se trouve dans une nouvelle position, une qui n'a jamais été rencontrée auparavant. Dans une telle situation, un réseau politique est appelé à évaluer la situation actuelle et les voies futures possibles ; ainsi que la désirabilité des parcours et la valeur de chaque mouvement par les réseaux Value, soutenus par les déploiements Monte Carlo.
Le réseau politique trouve tous les « bons » mouvements possibles et les réseaux de valeur évaluent chacun de leurs résultats. Dans les déploiements de Monte Carlo, quelques milliers de jeux aléatoires sont joués à partir des positions reconnues par le réseau politique. Des expériences ont été réalisées pour déterminer l'importance relative des réseaux de valeur par rapport aux déploiements de Monte Carlo. À la suite de cette expérimentation, DeepMind a attribué une pondération de 80 % aux réseaux de valeur et une pondération de 20 % à la fonction d'évaluation du déploiement de Monte Carlo.
Le réseau de politiques réduit la largeur de la recherche de 200 coups possibles aux 4 ou 5 meilleurs coups. Le réseau politique développe l'arborescence à partir de ces 4 ou 5 étapes qui doivent être prises en compte. Le réseau de valeur aide à réduire la profondeur de la recherche arborescente en renvoyant instantanément le résultat du jeu à partir de cette position. Enfin, le mouvement avec la valeur Q la plus élevée est sélectionné, c'est-à-dire l'étape avec le maximum d'avantages.
" Le jeu se joue principalement par l'intuition et la sensation, et en raison de sa beauté, de sa subtilité et de sa profondeur intellectuelle, il a captivé l'imagination humaine pendant des siècles."
– Demis Hassabis
Application d'AlphaGo aux problèmes du monde réel
La vision de DeepMind, à partir de leur site Web, est très révélatrice - "Résoudre l'intelligence. Utilisez ces connaissances pour rendre le monde meilleur ». L'objectif final de cet algorithme est de le rendre polyvalent afin qu'il puisse être utilisé pour résoudre des problèmes complexes du monde réel. AlphaGo de DeepMind est une avancée significative dans la quête d'AGI. DeepMind a utilisé sa technologie avec succès pour résoudre des problèmes du monde réel - regardons quelques exemples :
Réduction de la consommation d'énergie
L'IA de DeepMind a été utilisée avec succès pour réduire de 40 % les coûts de refroidissement du centre de données de Google. Dans tout environnement consommateur d'énergie à grande échelle, cette amélioration est un pas en avant phénoménal. L'une des principales sources de consommation d'énergie pour un centre de données est le refroidissement. Une grande partie de la chaleur générée par le fonctionnement des serveurs doit être éliminée pour le maintenir opérationnel. Ceci est accompli par des équipements industriels à grande échelle tels que des pompes, des refroidisseurs et des tours de refroidissement. Comme l'environnement du centre de données est très dynamique, il est difficile de fonctionner avec une efficacité énergétique optimale. L'IA de DeepMind a été utilisée pour résoudre ce problème.
Tout d'abord, ils ont procédé à l'aide de données historiques, qui ont été collectées par des milliers de capteurs au sein du centre de données. À l'aide de ces données, ils ont formé un ensemble de DNN sur l'efficacité future moyenne de l'utilisation de l'énergie (PUE). Comme il s'agit d'un algorithme à usage général, il est prévu qu'il soit également appliqué à d'autres défis, dans l'environnement du centre de données.
Les applications possibles de cette technologie incluent l'obtention de plus d'énergie à partir de la même unité d'entrée, la réduction de la consommation d'énergie et d'eau de fabrication de semi-conducteurs, etc. DeepMind a annoncé dans son article de blog que ces connaissances seraient partagées dans une future publication afin que d'autres centres de données, industriels les opérateurs et, en fin de compte, l'environnement peuvent grandement bénéficier de cette étape importante.
Planification de la radiothérapie pour les cancers de la tête et du cou
DeepMind a collaboré avec le département de radiothérapie du NHS Foundation Trust de l'University College London Hospital, un leader mondial dans le traitement du cancer.
Comment le Big Data et l'apprentissage automatique s'unissent contre le cancer
Un homme sur 75 et une femme sur 150 reçoivent un diagnostic de cancer de la bouche au cours de leur vie. En raison de la nature sensible des structures et des organes de la tête et du cou, les radiologues doivent faire preuve d'une extrême prudence lors de leur traitement.
Avant d'administrer la radiothérapie, une carte détaillée doit être préparée avec les zones à traiter et les zones à éviter. C'est ce qu'on appelle la segmentation. Cette carte segmentée est introduite dans la machine de radiographie, qui ciblera ensuite les cellules cancéreuses sans nuire aux cellules saines.
Dans le cas d'un cancer de la tête ou du cou, c'est un travail fastidieux pour les radiologues car il s'agit d'organes très sensibles. Il faut environ quatre heures aux radiologues pour créer une carte segmentée de cette zone. DeepMind, à travers ses algorithmes, vise à réduire le temps nécessaire à la génération des cartes segmentées, de quatre à une heure. Cela libérera considérablement le temps du radiologue. Plus important encore, cet algorithme de segmentation peut être utilisé pour d'autres parties du corps.
Pour résumer, AlphaGo a battu avec succès le 18 fois champion du monde de go, Lee Seedol, quatre fois dans un tournoi au meilleur des cinq en 2016. En 2017, il a même battu une équipe des meilleurs joueurs du monde. Il utilise une combinaison de DNN et DQN comme réseau de politique pour trouver le prochain meilleur coup, et un DNN comme réseau de valeur pour évaluer le résultat du jeu. La recherche arborescente de Monte Carlo est utilisée avec les réseaux de politique et de valeur pour réduire la largeur et la profondeur de la recherche - elles sont utilisées pour améliorer la fonction d'évaluation. Le but ultime de cet algorithme n'est pas de résoudre des jeux de société mais d'inventer un algorithme d'Intelligence Générale Artificielle. AlphaGo est sans aucun doute un grand pas en avant dans cette direction.
La différence entre Data Science, Machine Learning et Big Data !
Bien sûr, il y a eu d'autres effets. Alors que la nouvelle d'AlphaGo Vs Lee Seedol devenait virale, la demande de cartes Go a décuplé. De nombreux magasins ont signalé des cas de rupture de stock de cartes Go, et il est devenu difficile d'acheter une carte Go.
Heureusement, je viens d'en trouver un et je l'ai commandé pour moi et mon enfant. Envisagez-vous d'acheter la planche et d'apprendre Go?
Apprenez des cours de ML dans les meilleures universités du monde. Gagnez des programmes de maîtrise, Executive PGP ou Advanced Certificate pour accélérer votre carrière.
Quelles sont les limites de l'apprentissage par renforcement profond ?
DL oublie les connaissances précédemment acquises lorsque de nouvelles données ou informations sont introduites, de sorte qu'il ne les remet pas en question. Trop de renforcement peut parfois entraîner un excès d'états, diminuant l'efficacité. En raison de la complexité des modèles de données, la formation est extrêmement coûteuse. L'apprentissage en profondeur nécessite également l'utilisation de GPU coûteux et de centaines de postes de travail. En conséquence, il devient moins économique à utiliser.
Quels sont les inconvénients de l'utilisation de Monte Carlo Tree Search ?
Bien que MCTS soit un algorithme simple à exécuter, il présente certains inconvénients. Lorsque l'arbre s'agrandit après quelques itérations, beaucoup de mémoire est nécessaire. Lorsqu'il est appliqué aux jeux au tour par tour, il peut y avoir une seule branche ou un seul chemin qui mène à une perte contre l'adversaire dans des conditions spécifiques. Du coup, c'est un peu moins fiable. Après de nombreuses itérations, Monte Carlo Tree Search prend beaucoup de temps pour déterminer le chemin le plus efficace.
En quoi AlphaZero est-il différent d'AlphaGo Zero ?
Les versions précédentes d'AlphaGo incorporaient un petit nombre de fonctionnalités conçues à la main, mais AlphaGo Zero n'utilise que les pierres noires et blanches de la carte Go comme entrée. Les versions antérieures d'AlphaGo s'appuyaient sur un réseau de politiques pour choisir le coup suivant et sur un réseau de valeurs pour estimer le gagnant du jeu à partir de chaque position. Ceux-ci sont fusionnés dans AlphaGo Zero, permettant une formation et une évaluation plus efficaces. Toutes ces différences contribuent à l'amélioration des performances et à la généralisation du système. L'ajustement algorithmique, d'autre part, rend le système beaucoup plus puissant et efficace.