
Análisis de datos usando Python [Todo lo que necesita saber]
Publicado: 2020-09-02Para cualquiera que quiera iniciarse en el análisis de datos, el primer lenguaje que se le viene a la mente es R o Python. Y la razón por la que los desarrolladores ahora se inclinan más por Python se debe a su amplia adaptabilidad en el campo genérico del desarrollo de software. Por lo tanto, el análisis de datos con python es uno de los términos más escuchados para alguien que comienza su viaje hacia la ciencia de datos.
Tabla de contenido
¿Por qué análisis de datos?
Ahora primero, ¿por qué análisis de datos? Bueno, es el primer paso para saber con qué tipo de datos estás trabajando. Es el paso en el que encuentra patrones valiosos en los datos, que de otra manera no vería. En general, proporciona una comprensión intuitiva del conjunto de datos en cuestión.
Aquí necesitamos trazar una línea entre el análisis de datos y el preprocesamiento de datos. El preprocesamiento de datos se ocupa de modelar su conjunto de datos para asegurarse de que esté listo para el entrenamiento. El análisis de datos es comprender el conjunto de datos, que es un paso previo para el preprocesamiento de datos. En el análisis de datos, tratamos de modelar los datos para verlos mejor y, por lo tanto, obtener información sobre el conjunto de datos en cuestión.
¿Por qué Python?
La segunda pregunta es, ¿por qué Python? Bueno, ya dijimos que Python es un lenguaje ampliamente adaptado. Sí, no es la única opción cuando se trata de análisis de datos, pero es bastante buena. ¡Otra razón por la cual es que se usa más! Python es fácil y tiene una gran comunidad de desarrolladores para ayudarlo con el análisis de datos usando python . Además, el análisis de datos con Python es bastante agradable debido a la gran cantidad de bibliotecas creativas que ofrece para el análisis y la visualización de datos.
En Python, la biblioteca base para el análisis de datos es Pandas. Es una biblioteca de alto nivel, construida sobre la biblioteca NumPy, que es para computación científica y análisis numérico. Pandas facilita el trabajo con datos al ofrecer su estructura de datos, conocida como DataFrame. DataFrame ayuda a leer y almacenar su conjunto de datos. Proporciona las funciones básicas para leer y escribir el conjunto de datos, además de ver los metadatos y funciones de consulta para extraer todos los conocimientos del conjunto de datos.
Es importante tener en cuenta que la visualización de datos es una parte considerable del análisis general de datos. Porque no solo ayuda a comprender mejor los datos, sino también a aquellos a quienes les proporciona información. Estaríamos hablando de las dos bibliotecas más utilizadas para la visualización: Matplotlib y Seaborn. Matplotlib es la biblioteca base para cualquier visualización en Python. Seaborn también está hecho sobre Matplotlib, que ofrece algunas de las funciones de visualización de datos más creativas.
Configurar entorno
El primer paso es configurar su entorno. Al realizar análisis de datos con python , es importante contar con un entorno adecuado para mantener todo su trabajo. El análisis de datos usando python no será solo un script, sino que será una interacción de usted mismo con el conjunto de datos, y para eso, necesita un lugar apropiado para trabajar.
En Python, ese servicio lo proporciona Anaconda Distribution. El lugar de trabajo líder de Anaconda es el cuaderno Jupyter. Entonces, ¿por qué Jupyter? Bueno, te permite tener las visualizaciones directamente dentro de tu cuaderno. También tiene algunas funciones mágicas que le permiten ver la salida directamente sin indicar explícitamente dónde la quiere.
Las bibliotecas, Pandas y Matplotlib, vienen preinstaladas y, por lo tanto, no se requiere configuración adicional para usarlas.
Aquí está la sinopsis de cómo moverse haciendo análisis de datos usando Python :
- Carga del conjunto de datos
- Ver los metadatos del conjunto de datos usando Pandas
- Visualizaciones de datos usando Matplotlib
- Recopilación de información sobre los datos
Importar bibliotecas necesarias
Antes de comenzar a buscar en el código los pasos, solo importe las bibliotecas necesarias con pseudoetiquetas, como en el nombre con el que las llamaríamos para todo el programa.
importar numpy como np
importar pandas como pd
# para visualizaciones de datos
importar matplotlib.pyplot como plt
importar seaborn como sns
Ahora miraríamos cada paso y discutiríamos qué funciones están disponibles y cómo usarlas.
Primero, leer conjuntos de datos. Pandas proporciona algunas funciones básicas para cargar el conjunto de datos en su estructura de datos central: DataFrame. Podemos usarlo de la siguiente manera.
data_df = pd.read_csv('corazón.csv')
La salida de cualquier función de lectura será un DataFrame. Además de los lectores de CSV, los pandas proporcionan lectores para casi todos los tipos de datos. De HTML a JSON y excel.
Aparte de esto, si no tiene ningún dato como tal y desea crear su conjunto de datos, puede usar fácilmente las funciones de objeto Pandas' Series y DataFrame.
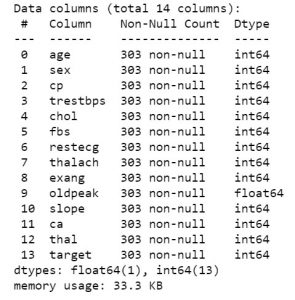
Entonces, una vez que tenga los datos a mano, pasemos a ver de qué se tratan los datos. Para obtener la primera vista de los datos, puede usar funciones como df.info o df.describe para conocer la estructura de su conjunto de datos.
datos_df.info()
datos_df.describe()
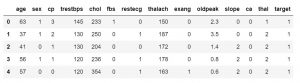
Una vez que sepa qué características contiene su conjunto de datos, es posible que desee ver los valores de esos. Puede usar la función df.head() para obtener las primeras 5 muestras.
data_df.head()
#o
data_df.head(3)
También puede especificar la cantidad de muestras para anular el valor predeterminado de 5. También puede usar la función df.tail() para obtener los últimos 5 valores del conjunto de datos.
data_df.tail()
Esto es solo para obtener una descripción general de alto nivel de cómo se verían sus datos. Una vez listo, puede iniciar las principales tareas de visualización de datos, utilizando Matplotlib. Ingrese el siguiente código para que el trazado sea interactivo y vea lo mismo en su cuaderno.
% matplotlib en línea
Veríamos las funcionalidades de las 5 visualizaciones principales en matplotlib. Antes de entrar en él, debemos conocer algunas otras funciones que controlan nuestros gráficos. Las funciones como:
- Etiquetas: xlabel(), ylabel(). Son para las etiquetas del eje x y del eje y.
- Leyenda: Se utiliza para hacer la leyenda de la trama.
- Título: Para asignar un título a su parcela
- Y finalmente, muestra la función para ver la trama.
Checkout: Salario del analista de datos en la India
visualizaciones
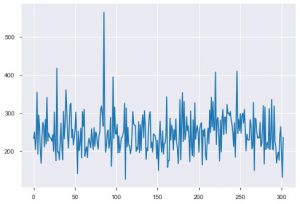
Veamos ahora las visualizaciones. Comenzaríamos con la trama básica. El plt.plot() se usa para generar un diagrama de línea simple para sus datos. La función requiere dos parámetros en compulsión, y estos son los datos del eje x y los datos del eje y. Opcionalmente, puede proporcionar los estilos, el nombre y el color de la trama. Así es como se ve en el código.
plt.plot(data_df['chol'])
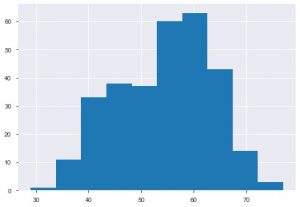
El segundo gráfico es el histograma. Un histograma le ayuda a ver la frecuencia o distribución de una característica en particular. Le ayuda a ver cómo las cantidades se relacionan entre sí. Plt.hist() es la función base para crear un histograma en sus datos. Puede mencionar el parámetro bins para controlar el número en el gráfico. Solo necesita pasar datos de un solo eje si desea un análisis univariado.
plt.hist(data_df['edad'])
Otro gráfico que verías mucho es el gráfico de barras. Ayuda a analizar y comparar diferentes características. A diferencia de los histogramas, los diagramas de barras se utilizan para trabajar con datos categóricos.

Puede aplicar directamente el gráfico en el DataFrame, o puede especificar los parámetros dentro de la función plt.bar(). Así es como lo usamos.
df = pd.DataFrame(np.random.rand(15, 5), columnas=['t1', 't2', 't3', 't4', 't5'])
df.plot.bar()
También puede usar el diagrama de barras horizontalmente usando la función barh().
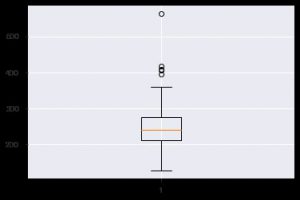
Otro gráfico perspicaz es el diagrama de caja. Ayuda a comprender la distribución de valores dentro de cada característica. Puede usar la función plt.boxplot() para especificar los datos en los que desea generar un diagrama de caja. El gráfico es especialmente útil cuando necesita ver la dispersión en el conjunto de datos o la asimetría rápidamente. Así es como puedes usarlo.
plt.boxplot(data_df['chol'])
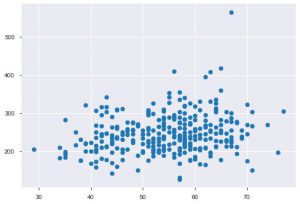
Siempre que trabaje con datos estadísticos, definitivamente verá un diagrama de dispersión. Un diagrama de dispersión ayuda a observar la relación entre dos características. La gráfica requiere valores numéricos tanto para los datos del eje x como para el eje y. Simplemente puede proporcionar esos dos valores en la función plt.scatter() o puede aplicarlos directamente en el DataFrame especificando los nombres de las columnas en los atributos x e y. Así es como puedes usar eso:
plt.dispersión(data_df['edad'], data_df['chol'])
Ahora es el momento apropiado para presentarle las funciones de Seaborn. El gráfico de dispersión en seaborn es más intuitivo que matplotlib porque también proporciona de forma predeterminada una línea de regresión en el gráfico para visualizarlo mejor. Puede usar la función sns.lmplot() para hacer ese gráfico.
sns.lmplot('edad', 'chol', data=data_df)
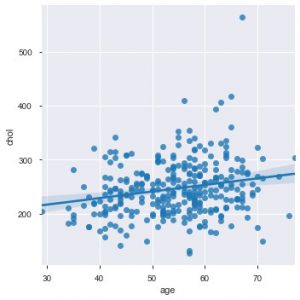
Como puede ver en el gráfico anterior, la línea de regresión ayuda a comprender aún mejor la distribución.
Otra mejora al usar seaborn es la trama de enjambre. Se utiliza para dibujar un gráfico de dispersión categórica. Una de las ventajas del diagrama de enjambre sobre el diagrama de franjas similar es que utiliza solo los puntos que no se superponen. Por lo tanto, es una trama más limpia y, por lo tanto, ofrece una mejor perspectiva.
sns.swarmplot(data_df['edad'], data_df['chol'])
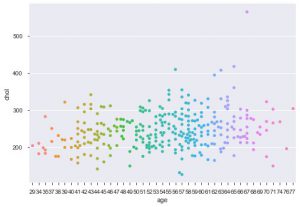
Entonces, estos son los diferentes tipos de gráficos en Matplotlib y Seaborn. Esta es solo la punta del iceberg, y hay cientos de otras formas diferentes de graficar sus datos para extraer ideas creativas al respecto.
Ahora que conoce las gráficas, veamos cómo hacer un análisis de datos real usando python . Echaremos un vistazo a algunos diagramas más y veremos qué nos muestran sobre el análisis de datos usando python .
Empecemos.
Después de cargar los datos, lo primero que hace cualquier analista de datos ahora es crear un perfil de pandas. Ahora, esto también se puede ver como un atajo, pero si desea ver todas las relaciones, recuentos e histogramas de las variables en el conjunto de datos, puede usar la creación de perfiles de pandas. Es muy fácil de generar, simplemente descargue el módulo de perfilado de pandas e ingrese el siguiente código:
importar pandas_perfiles
perfil = pandas_profiling.ProfileReport(data_df)
perfil
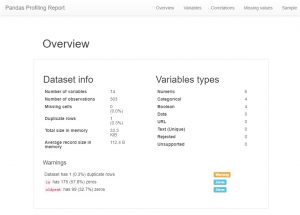
Como podrá ver, hay una gran cantidad de información de metadatos y también información de características individuales. Estos podrían conducir a un gran entendimiento.
Lo segundo que podemos hacer es generar un mapa de calor. Ahora, lo que hace un mapa de calor es mostrar la correlación de cada característica con la otra. Y si encontramos un valor con una correlación más alta, eso significa que las dos características se parecen mucho entre sí. Entonces, podemos eliminar una de las características y aún así, el modelo funcionará bien.
sns.heatmap(data_df.corr(), annot = True , cmap='Naranjas')
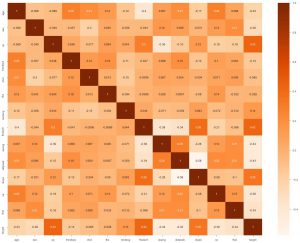
Aquí podemos ver que ninguno está muy relacionado, por lo que podemos decirle al ingeniero de modelos que necesitaríamos todas las funciones como entrada.
Podemos ver cuál es la distribución por edad porque estamos tratando con el conjunto de datos de enfermedades cardíacas, veamos la distribución, para que podamos usar el diagrama de distribución de nacidos en el mar.
sns.distplot(data_df['edad'], color = 'cian')
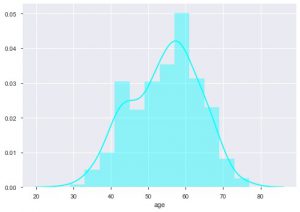
A partir de la trama, puede decir que la mayoría de las personas que padecen enfermedades cardíacas tienen entre 50 y 60 años. De la misma manera, también podemos ver algunas otras características importantes como la presión arterial en reposo, que se denota por tresbps. Podemos hacer un diagrama de caja para ver la distribución, en comparación con el valor objetivo, es decir, 0 y 1.
sns.boxplot(data_df['objetivo'], data_df['trestbps'], paleta = 'crepúsculo')
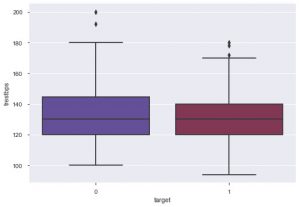
Podemos concluir de la gráfica que si la persona tiene tres bps más bajos, entonces las posibilidades de que sufra una enfermedad cardíaca son menores que aquellos con un valor más alto de tres bps.
Del mismo modo, también podemos ver la relación con los niveles de colesterol. Vemos que las personas con niveles de colesterol más bajos tienen menos posibilidades de sufrir enfermedades del corazón.
Puede documentar todos estos conocimientos y proporcionárselos al ingeniero de aprendizaje automático, quien luego puede usarlos para crear un modelo eficiente.
Conclusión
Entonces, así es como puedes hacer análisis de datos usando python . Este es solo el primer paso en el viaje de la ciencia de datos. Para obtener más información sobre cómo extraer información creativa de los datos y la ciencia de datos en general, diríjase a los cursos que ofrece upGrad aquí . Encontrará un espectro de cursos útiles que guiarán de manera efectiva el análisis de datos usando Python.
Aprenda cursos de ciencia de datos de las mejores universidades del mundo. Obtenga programas Executive PG, programas de certificados avanzados o programas de maestría para acelerar su carrera.
¿Cómo debo comenzar a aprender Python para el análisis de datos?
Si está en camino de aprender Python para el análisis de datos, entonces está en el lugar correcto. Debe tener un enfoque paso a paso para simplificar el proceso de aprendizaje para cualquier cosa. Así es como se ve el proceso:
1. Sea claro con el propósito de aprender Python y cómo podrá usarlo en su campo.
2.Descargue el terminal Python requerido e instálelo en su sistema.
3. Comience a aprender los conceptos básicos de Python tomando diferentes cursos y familiarizándose con las diferentes bibliotecas de Python.
4. Familiarícese con las expresiones regulares que se utilizan en Python.
5. Busque obtener un conocimiento profundo de las diferentes bibliotecas de Python, como Pandas, NumPy, Matplotlib y SciPy.
6. Comience a aprender conceptos de análisis de datos y cómo puede integrar Python junto con él.
7. Ahora, solo necesita seguir practicando diferentes herramientas y técnicas para mejorar en Python para el análisis de datos. Al seguir este enfoque paso a paso, le resultará bastante fácil aprender Python y mejorarlo para trabajar con el análisis de datos.
¿Cómo se usa Python para el análisis de datos?
Se sabe que Python es un recurso muy importante para el análisis de datos. Python ayuda de diferentes maneras para realizar el análisis de datos. Pero antes de eso, debe preparar los datos para el análisis, realizar análisis estadísticos, crear visualizaciones de datos que puedan proporcionar información, predecir las tendencias futuras en función de los datos disponibles y mucho más.
Se encuentra que Python es un elemento crucial del análisis de datos, ya que ayuda en:
1. Importación de conjuntos de datos
2.Limpieza y preparación de los datos para realizar el análisis
3. Manipulación del marco de datos de Pandas
4. Resumiendo los conjuntos de datos
5. Desarrollo de un modelo de Machine Learning para el análisis de datos con Python
¿Puedo aprender Python en un mes?
Sí, definitivamente puede hacer que esto suceda si domina otros lenguajes de programación como Java, C, C++, etc. Si su base es clara, le resultará bastante fácil aprender Python incluso en un solo mes. Aparte de eso, si te esfuerzas y sigues un enfoque paso a paso de manera disciplinada, puedes aprender Python en un mes, incluso si no tienes conocimientos previos de otros lenguajes de programación. Solo necesita establecer un horario y dedicarse a aprender Python en un mes.