
Go y el Reto a la Inteligencia Artificial General
Publicado: 2018-02-15Este artículo tiene como objetivo explorar la conexión entre el juego 'Go' y la inteligencia artificial. El objetivo es responder a las preguntas: ¿Qué hace que el juego de Go sea especial? ¿Por qué era difícil dominar el juego de Go para una computadora? ¿Por qué un programa de computadora pudo vencer a un gran maestro de ajedrez en 1997? ¿Por qué tomó cerca de dos décadas descifrar Go?
“Los caballeros no deberían perder el tiempo en juegos triviales, deberían estudiar Go”
– Confucio
De hecho, los expertos en inteligencia artificial pensaron que las computadoras solo podrían vencer a un campeón mundial de Go para 2027. Gracias a DeepMind, una compañía de inteligencia artificial bajo el paraguas de Google, esta formidable tarea se logró una década antes. Este artículo hablará sobre las tecnologías utilizadas por DeepMind para vencer al campeón mundial de Go. Finalmente, esta publicación analiza cómo se puede usar esta tecnología para resolver algunos problemas complejos del mundo real.
Tabla de contenido
Ir - ¿Qué es?
Go es un juego de mesa de estrategia chino de 3000 años de antigüedad, que ha conservado su popularidad a lo largo de los siglos. Jugado por decenas de millones de personas en todo el mundo, Go es un juego de mesa para dos jugadores con reglas simples y una estrategia intuitiva. Se utilizan diferentes tamaños de tablero para jugar a este juego; los profesionales utilizan un tablero de 19×19.

El juego comienza con un tablero vacío. Luego, cada jugador se turna para colocar las piedras blancas y negras (las negras van primero) en el tablero, en la intersección de las líneas (a diferencia del ajedrez, donde colocas las piezas en los cuadrados). Un jugador puede capturar las piedras del oponente rodeándolo por todos lados. Por cada piedra capturada, se otorgan algunos puntos al jugador. El objetivo del juego es ocupar el máximo territorio en el tablero y capturar las piedras de tus oponentes.
Go se trata de creación, a diferencia del ajedrez, que se trata de destrucción. Go requiere libertad, creatividad, intuición, equilibrio, estrategia y profundidad intelectual para dominar el juego. Jugar Go involucra ambos lados del cerebro. De hecho, los escáneres cerebrales de los jugadores de Go han revelado que Go ayuda en el desarrollo del cerebro al mejorar las conexiones entre ambos hemisferios cerebrales.
Redes neuronales para tontos: una guía completa
Go y el Desafío a la Inteligencia Artificial (IA)
Las computadoras pudieron dominar Tic-Tac-Toe en 1952 . Deep Blue pudo vencer al gran maestro de ajedrez Garry Kasparov en 1997 . El programa de computadora pudo ganar contra el campeón mundial en Jeopardy (un popular juego estadounidense) en 2001 . AlphaGo de DeepMind pudo derrotar a un campeón mundial de Go en 2016 . ¿Por qué se considera un desafío para un programa de computadora dominar el juego de Go?
El ajedrez se juega en un tablero de 8×8 mientras que el Go usa un tablero de 19×19. En la apertura de un juego de ajedrez, un jugador tendrá 20 movimientos posibles. En una apertura de Go, un jugador puede tener 361 movimientos posibles. El número de posiciones posibles en el tablero de Go es igual a 10 elevado a 170; más que el número de átomos en nuestro universo! El número potencial de posiciones en el tablero hace que los tiempos de Go googol (10 elevado a 100) sean más complejos que el ajedrez.
En ajedrez, para cada paso, un jugador se enfrenta a una elección de 35 movimientos. En promedio, un jugador de Go tendrá 250 movimientos posibles en cada paso. En el ajedrez, en cualquier posición dada, es relativamente fácil para una computadora hacer una búsqueda de fuerza bruta y elegir el mejor movimiento posible que maximice las posibilidades de ganar. Una búsqueda de fuerza bruta no es posible en el caso de Go, ya que la cantidad potencial de movimientos legales permitidos para cada paso es enorme.
Para que una computadora domine el ajedrez, se vuelve más fácil a medida que avanza el juego porque las piezas se retiran del tablero. En Go, se vuelve más difícil para el programa de computadora ya que se agregan piedras al tablero a medida que avanza el juego. Por lo general, un juego de Go durará 3 veces más que un juego de ajedrez.
Por todas estas razones, un programa Go de computadora superior solo pudo alcanzar al campeón mundial de Go en 2016, después de una gran explosión de nuevas técnicas de aprendizaje automático. Los científicos que trabajan en DeepMind pudieron crear un programa de computadora llamado AlphaGo que derrotó al campeón mundial Lee Seedol . Lograr la tarea no fue fácil. Los investigadores de DeepMind propusieron muchas innovaciones novedosas en el proceso de creación de AlphaGo.
“Las reglas de Go son tan elegantes, orgánicas y rigurosamente lógicas que si existen formas de vida inteligentes en otras partes del universo, es casi seguro que juegan Go”.
–Eduardo Laskar
Redes neuronales: aplicaciones en el mundo real
Cómo funciona AlphaGo
AlphaGo es un algoritmo de propósito general, lo que significa que también se puede utilizar para resolver otras tareas. Por ejemplo, Deep Blue de IBM está diseñado específicamente para jugar al ajedrez. Las reglas del ajedrez junto con el conocimiento acumulado de siglos de juego están programados en el cerebro del programa. Deep Blue no se puede usar ni siquiera para jugar juegos triviales como Tic-Tac-Toe. Sólo puede hacer una cosa específica, en la que es muy bueno, es decir, jugar al ajedrez. AlphaGo también puede aprender a jugar otros juegos además de Go. Estos algoritmos de propósito general constituyen un campo de investigación novedoso, denominado Inteligencia General Artificial.
AlphaGo utiliza métodos de última generación: Deep Neural Networks (DNN), Reinforcement Learning (RL), Monte Carlo Tree Search (MCTS), Deep Q Networks (DQN) (una técnica novedosa introducida y popularizada por DeepMind que combina redes con aprendizaje por refuerzo), por nombrar algunos. Luego combina todos estos métodos de manera innovadora para lograr un dominio de nivel sobrehumano en el juego de Go.
Veamos primero cada pieza individual de este rompecabezas antes de ver cómo se unen estas piezas para lograr la tarea en cuestión.
Redes neuronales profundas
Las DNN son una técnica para realizar el aprendizaje automático, vagamente inspirada en el funcionamiento del cerebro humano. La arquitectura de una DNN consta de capas de neuronas. DNN puede reconocer patrones en los datos sin estar explícitamente programado para ello.
Asigna las entradas a las salidas sin que nadie lo programe específicamente para lo mismo. Como ejemplo, supongamos que hemos alimentado la red con muchas fotos de perros y gatos. Al mismo tiempo, también estamos entrenando al sistema diciéndole (en forma de etiquetas) si una imagen en particular es de un gato o un perro (esto se llama aprendizaje supervisado). Un DNN aprenderá a reconocer el patrón de las fotos para diferenciar con éxito entre un gato y un perro. El objetivo principal del entrenamiento es que cuando un DNN ve una nueva imagen de un perro o un gato, debe ser capaz de clasificarlo correctamente, es decir, predecir si es un gato o un perro.
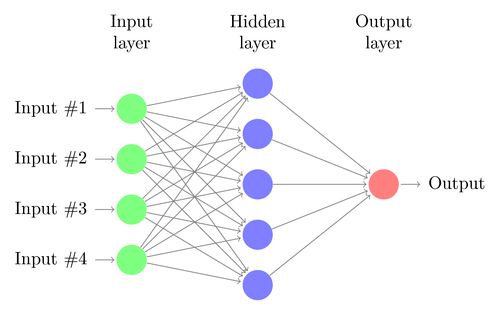
Entendamos la arquitectura de un DNN simple. El número de neuronas en la capa de entrada corresponde al tamaño de la entrada. Supongamos que nuestras fotos de gatos y perros son una imagen de 28×28. Cada fila y columna constará de 28 píxeles cada una, lo que hace un total de 784 píxeles para cada imagen. En tal caso, la capa de entrada estará compuesta por 784 neuronas, una para cada píxel. La cantidad de neuronas en la capa de salida dependerá de la cantidad de clases en las que se deba clasificar la salida. En este caso, la capa de salida constará de dos neuronas, una correspondiente a 'gato' y la otra a 'perro'.
Esté atento a la próxima gran novedad: el aprendizaje automático
Habrá muchas capas de neuronas entre las capas de entrada y salida (que es el origen del uso del término 'Profundo' en 'Red neuronal profunda'). Estas se llaman “capas ocultas”. El número de capas ocultas y el número de neuronas en cada capa no son fijos. De hecho, cambiar estos valores es exactamente lo que conduce a la optimización del rendimiento. Estos valores se denominan hiperparámetros y deben ajustarse de acuerdo con el problema en cuestión. Los experimentos que rodean a las redes neuronales implican en gran medida descubrir el número óptimo de hiperparámetros.
La fase de entrenamiento de las DNN consistirá en un pase hacia adelante y un pase hacia atrás. Primero, todas las conexiones entre las neuronas se inicializan con pesos aleatorios. Durante el pase hacia adelante, la red se alimenta con una sola imagen. Las entradas (datos de píxeles de la imagen) se combinan con los parámetros de la red (pesos, sesgos y funciones de activación) y se alimentan a través de capas ocultas, hasta llegar a la salida, que devuelve una probabilidad de que una foto pertenezca a cada uno. de las clases
Luego, esta probabilidad se compara con la etiqueta de clase real y se calcula un "error". En este punto, se realiza el paso hacia atrás: esta información de error se pasa de vuelta a través de la red a través de una técnica llamada "propagación hacia atrás". Durante las fases iniciales del entrenamiento, este error será alto y un buen mecanismo de entrenamiento reducirá gradualmente este error.
Los DNN se entrenan de esta manera con un pase hacia adelante y hacia atrás hasta que los pesos dejan de cambiar (esto se conoce como convergencia). Entonces, los DNN podrán predecir y clasificar las imágenes con un alto grado de precisión, es decir, si la imagen tiene un gato o un perro.

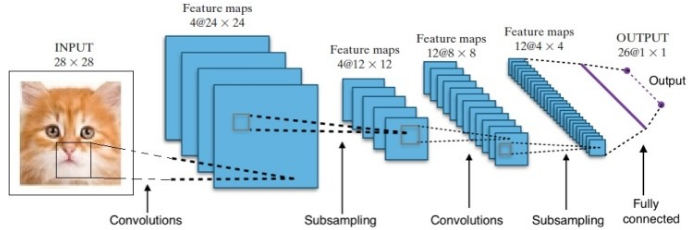
La investigación nos ha proporcionado muchas arquitecturas de redes neuronales profundas diferentes. Para los problemas de visión por computadora (es decir, problemas que involucran imágenes), las redes neuronales de convolución (CNN) tradicionalmente han dado buenos resultados. Para problemas que involucran una secuencia (reconocimiento de voz o traducción de idiomas), las redes neuronales recurrentes (RNN) brindan excelentes resultados.
Una guía para principiantes sobre la comprensión del lenguaje natural
En el caso de AlphaGo, el proceso fue el siguiente: primero, se entrenó la red neuronal de convolución (CNN) con millones de imágenes de posiciones de tableros. A continuación, se informaba a la red sobre el movimiento posterior realizado por los expertos humanos en cada caso durante la fase de formación de la red. De la misma manera que se mencionó anteriormente, el valor real se comparó con la salida y se encontró algún tipo de métrica de "error".
Al final del entrenamiento, la DNN generará los próximos movimientos junto con las probabilidades que probablemente jugará un jugador humano experto. Este tipo de red solo puede generar un paso que es jugado por un jugador humano experto. DeepMind pudo lograr una precisión del 60% al predecir el movimiento que haría el humano. Sin embargo, para vencer a un experto humano en Go, esto no es suficiente. La salida de la DNN es procesada por Deep Reinforcement Network, un enfoque concebido por DeepMind, que combina redes neuronales profundas y aprendizaje por refuerzo.
Aprendizaje por refuerzo profundo
El aprendizaje por refuerzo (RL) no es un concepto nuevo. El premio Nobel Ivan Pavlov experimentó con el condicionamiento clásico en perros y descubrió los principios del aprendizaje por refuerzo en 1902. RL es también uno de los métodos con los que los humanos aprenden nuevas habilidades. ¿Alguna vez se preguntó cómo se entrena a los delfines en los espectáculos para saltar a tan grandes alturas fuera del agua? Es con la ayuda de RL. Primero, la cuerda que se usa para preparar los delfines se sumerge en la piscina. Cada vez que el delfín cruza el cable desde arriba, es recompensado con comida. Cuando no cruza la cuerda se retira la recompensa. Lentamente el delfín aprenderá que se paga cada vez que pasa la cuerda desde arriba. La altura de la cuerda se aumenta gradualmente para entrenar al delfín. 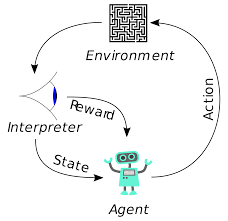
Generación de lenguaje natural: cosas principales que debe saber
Los agentes en el aprendizaje por refuerzo también se entrenan utilizando el mismo principio. El agente tomará acción e interactuará con el entorno. La acción realizada por el agente hace que el entorno cambie. Además, el agente recibió comentarios sobre el entorno. El agente es recompensado o no, dependiendo de su acción y del objetivo que tenga entre manos. El punto importante es que este objetivo en cuestión no se establece explícitamente para el agente. Con el tiempo suficiente, el agente aprenderá a maximizar las recompensas futuras.

Combinando esto con DNN, DeepMind inventó Deep Reinforcement Learning (DRL) o Deep Q Networks (DQN), donde Q significa máximas recompensas futuras obtenidas. Los DQN se aplicaron por primera vez a los juegos de Atari . DQN aprendió a jugar diferentes tipos de juegos de Atari recién salidos de la caja. El avance fue que no se requirió programación explícita para representar diferentes tipos de juegos de Atari. Un solo programa fue lo suficientemente inteligente como para aprender sobre todos los diferentes entornos del juego y, a través del juego autónomo, pudo dominar muchos de ellos.
En 2014, DQN superó a los métodos de aprendizaje automático anteriores en 43 de los 49 juegos (ahora se ha probado en más de 70 juegos). De hecho, en más de la mitad de los juegos, se desempeñó a más del 75 % del nivel de un jugador humano profesional. En ciertos juegos, DQN incluso ideó estrategias sorprendentemente clarividentes que le permitieron lograr la máxima puntuación posible; por ejemplo, en Breakout , aprendió a cavar primero un túnel en un extremo de la pared de ladrillos, para que la pelota rebotara. por la espalda y derriba los ladrillos por detrás.
Política y Redes de Valor
Hay dos tipos principales de redes dentro de AlphaGo:
Uno de los objetivos de los DQN de AlphaGo es ir más allá del juego experto humano e imitar nuevos movimientos innovadores, jugando contra sí mismo millones de veces y, por lo tanto, mejorando gradualmente los pesos. Este DQN tuvo una tasa de victorias del 80 % frente a los DNN comunes. DeepMind decidió combinar estas dos redes neuronales (DNN y DQN) para formar el primer tipo de red: una 'Red de políticas'. Brevemente, el trabajo de una red de políticas es reducir la amplitud de la búsqueda del próximo movimiento y proponer algunos buenos movimientos que vale la pena explorar más a fondo.
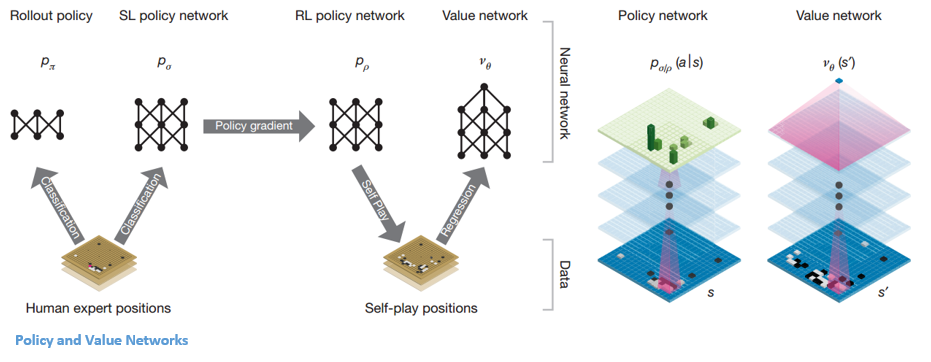 Una vez que la red de políticas está congelada, juega contra sí misma millones de veces. Estos juegos generan un nuevo conjunto de datos de Go, que consta de las distintas posiciones del tablero y los resultados de los juegos. Este conjunto de datos se utiliza para crear una función de evaluación. El segundo tipo de función: la 'Red de valor' se utiliza para predecir el resultado del juego. Aprende a tomar varias posiciones del tablero como entradas y predecir el resultado del juego y la medida del mismo.
Una vez que la red de políticas está congelada, juega contra sí misma millones de veces. Estos juegos generan un nuevo conjunto de datos de Go, que consta de las distintas posiciones del tablero y los resultados de los juegos. Este conjunto de datos se utiliza para crear una función de evaluación. El segundo tipo de función: la 'Red de valor' se utiliza para predecir el resultado del juego. Aprende a tomar varias posiciones del tablero como entradas y predecir el resultado del juego y la medida del mismo.
Combinando la Política y las Redes de Valor
Después de todo este entrenamiento, DeepMind finalmente terminó con dos redes neuronales: Policy y Value Networks. La red de políticas toma la posición del tablero como entrada y genera la distribución de probabilidad como la probabilidad de cada uno de los movimientos en esa posición. La red de valor vuelve a tomar la posición del tablero como entrada y genera un único número real entre 0 y 1. Si la salida de la red es cero, significa que las blancas están ganando por completo y 1 indica una victoria completa para el jugador con negras. piedras
La red de políticas evalúa las posiciones actuales y la red de valor evalúa los movimientos futuros. La división de tareas en estas dos redes por parte de DeepMind fue una de las principales razones detrás del éxito de AlphaGo.
Combinación de redes de políticas y valores con Monte Carlo Tree Search (MCTS) e implementaciones
Las redes neuronales por sí solas no serán suficientes. Para ganar el juego de Go, se requiere un poco más de estrategia. Este plan se logra con la ayuda de MCTS. Monte Carlo Tree Search también ayuda a unir las dos redes neuronales de una manera innovadora. Las redes neuronales ayudan en una búsqueda eficiente del próximo mejor movimiento.
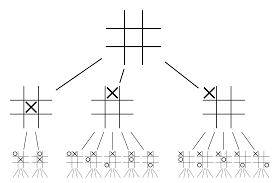
Intentemos construir un ejemplo que te ayudará a visualizar todo esto mucho mejor. Imagine que el juego está en una nueva posición, una que no se ha encontrado antes. En tal situación, se llama a una red de políticas para evaluar la situación actual y los posibles caminos futuros; así como la conveniencia de los caminos y el valor de cada movimiento por parte de las redes de valor, con el apoyo de los despliegues de Monte Carlo.
La red de políticas encuentra todos los posibles movimientos "buenos" y las redes de valor evalúan cada uno de sus resultados. En los lanzamientos de Monte Carlo, se juegan algunos miles de juegos aleatorios desde las posiciones reconocidas por la red de políticas. Se realizaron experimentos para determinar la importancia relativa de las redes de valor frente a los despliegues de Monte Carlo. Como resultado de esta experimentación, DeepMind asignó una ponderación del 80 % a las redes de valor y una ponderación del 20 % a la función de evaluación del despliegue de Monte Carlo.
La red de políticas reduce el ancho de la búsqueda de 200 posibles movimientos a los 4 o 5 mejores movimientos. La red de políticas amplía el árbol de estos 4 o 5 pasos que necesitan consideración. La red de valor ayuda a reducir la profundidad de la búsqueda del árbol al devolver instantáneamente el resultado del juego desde esa posición. Finalmente, se selecciona el movimiento con el valor Q más alto, es decir, el paso con el máximo beneficio.
“ El juego se juega principalmente a través de la intuición y la sensación, y debido a su belleza, sutileza y profundidad intelectual ha capturado la imaginación humana durante siglos”.
– Demis Hassabis
Aplicación de AlphaGo a problemas del mundo real
La visión de DeepMind, de su sitio web, es muy reveladora: “Resolver inteligencia. Usa este conocimiento para hacer del mundo un lugar mejor”. El objetivo final de este algoritmo es hacerlo de uso general para que pueda usarse para resolver problemas complejos del mundo real. AlphaGo de DeepMind es un importante paso adelante en la búsqueda de AGI. DeepMind ha utilizado su tecnología con éxito para resolver problemas del mundo real. Veamos algunos ejemplos:
Reducción del consumo de energía
La IA de DeepMind se utilizó con éxito para reducir el costo de enfriamiento del centro de datos de Google en un 40 %. En cualquier entorno que consuma energía a gran escala, esta mejora es un gran paso adelante. Una de las principales fuentes de consumo de energía de un centro de datos es la refrigeración. Es necesario eliminar una gran cantidad de calor generado por el funcionamiento de los servidores para mantenerlo operativo. Esto se logra mediante equipos industriales a gran escala como bombas, enfriadores y torres de enfriamiento. Dado que el entorno del centro de datos es muy dinámico, es un desafío operar con una eficiencia energética óptima. La IA de DeepMind se utilizó para abordar este problema.
Primero, procedieron utilizando datos históricos, que fueron recopilados por miles de sensores dentro del centro de datos. Usando estos datos, entrenaron a un conjunto de DNN en la eficacia del uso de energía (PUE) futura promedio. Como se trata de un algoritmo de propósito general, está previsto que también se aplique a otros desafíos en el entorno del centro de datos.
Las posibles aplicaciones de esta tecnología incluyen obtener más energía de la misma unidad de entrada, reducir el uso de energía y agua en la fabricación de semiconductores, etc. DeepMind anunció en su blog que este conocimiento se compartiría en una publicación futura para que otros centros de datos, industriales los operadores y, en última instancia, el medio ambiente pueden beneficiarse enormemente de este importante paso.
Planificación de la radioterapia para los cánceres de cabeza y cuello
DeepMind ha colaborado con el departamento de radioterapia del NHS Foundation Trust del University College London Hospital, líder mundial en el tratamiento del cáncer.
Cómo Big Data y Machine Learning se están uniendo contra el cáncer
Uno de cada 75 hombres y una de cada 150 mujeres son diagnosticados con cáncer oral en su vida. Debido a la naturaleza sensible de las estructuras y órganos en el área de la cabeza y el cuello, los radiólogos deben tener mucho cuidado al tratarlos.
Antes de administrar la radioterapia, se debe preparar un mapa detallado con las áreas a tratar y las áreas a evitar. Esto se conoce como segmentación. Este mapa segmentado se introduce en la máquina de radiografía, que luego apuntará a las células cancerosas sin dañar las células sanas.
En el caso del cáncer de la región de la cabeza o el cuello, este es un trabajo minucioso para los radiólogos, ya que involucra órganos muy sensibles. Los radiólogos tardan alrededor de cuatro horas en crear un mapa segmentado para esta área. DeepMind, a través de sus algoritmos, pretende reducir el tiempo necesario para generar los mapas segmentados, de cuatro a una hora. Esto liberará significativamente el tiempo del radiólogo. Más importante aún, este algoritmo de segmentación se puede utilizar para otras partes del cuerpo.
En resumen, AlphaGo venció con éxito al 18 veces campeón mundial de Go, Lee Seedol, cuatro veces en un torneo al mejor de cinco en 2016. En 2017, incluso venció a un equipo de los mejores jugadores del mundo. Utiliza una combinación de DNN y DQN como red de políticas para dar con el siguiente mejor movimiento y una DNN como red de valor para evaluar el resultado del juego. La búsqueda en árbol de Monte Carlo se usa junto con las redes de políticas y de valor para reducir el ancho y la profundidad de la búsqueda; se usan para mejorar la función de evaluación. El objetivo final de este algoritmo no es resolver juegos de mesa sino inventar un algoritmo de Inteligencia General Artificial. AlphaGo es sin duda un gran paso adelante en esa dirección.
¡La diferencia entre ciencia de datos, aprendizaje automático y Big Data!
Por supuesto, ha habido otros efectos. A medida que la noticia de AlphaGo Vs Lee Seedol se volvió viral, la demanda de tableros Go se multiplicó por diez. Muchas tiendas informaron casos de tableros Go que se agotaron y se convirtió en un desafío comprar un tablero Go.
Afortunadamente, acabo de encontrar uno y lo ordené para mí y para mi hijo. ¿Estás planeando comprar el tablero y aprender Go?
Aprenda cursos de ML de las mejores universidades del mundo. Obtenga programas de maestría, PGP ejecutivo o certificado avanzado para acelerar su carrera.
¿Cuáles son las limitaciones del aprendizaje por refuerzo profundo?
DL se olvida de los conocimientos adquiridos previamente cuando se introducen nuevos datos o información, por lo que no los desafía. Demasiado refuerzo a veces puede resultar en un exceso de estados, lo que reduce la efectividad. Debido a la complejidad de los modelos de datos, la capacitación es extremadamente costosa. El aprendizaje profundo también requiere el uso de GPU costosas y cientos de estaciones de trabajo. Como resultado, se vuelve menos económico de usar.
¿Cuáles son las desventajas de utilizar Monte Carlo Tree Search?
Aunque MCTS es un algoritmo simple de ejecutar, tiene ciertos inconvenientes. Cuando el árbol crece después de algunas iteraciones, se requiere mucha memoria. Cuando se aplica a los juegos por turnos, puede haber una sola rama o camino que conduzca a una pérdida contra el oponente en condiciones específicas. Como resultado, es un poco menos confiable. Después de muchas iteraciones, Monte Carlo Tree Search tarda mucho tiempo en determinar la ruta más efectiva.
¿En qué se diferencia AlphaZero de AlphaGo Zero?
Las versiones anteriores de AlphaGo incorporaron una pequeña cantidad de funciones diseñadas a mano, pero AlphaGo Zero solo usa las piedras en blanco y negro del tablero Go como entrada. Las versiones anteriores de AlphaGo se basaban en una red de políticas para elegir el próximo movimiento y una red de valor para estimar el ganador del juego en cada posición. Estos se fusionan en AlphaGo Zero, lo que permite una capacitación y evaluación más eficientes. Todas estas diferencias contribuyen a mejorar el rendimiento y la generalización del sistema. El ajuste algorítmico, por otro lado, hace que el sistema sea mucho más potente y eficiente.