
Datenanalyse mit Python [Alles, was Sie wissen müssen]
Veröffentlicht: 2020-09-02Jedem, der mit der Datenanalyse beginnen möchte, kommt als erstes R oder Python in den Sinn. Und der Grund, warum Entwickler jetzt mehr zu Python neigen, liegt in seiner breiten Anpassungsfähigkeit im Bereich der generischen Softwareentwicklung. Daher ist die Datenanalyse mit Python einer der am häufigsten gehörten Begriffe für jemanden, der seine Reise in die Datenwissenschaft beginnt.
Inhaltsverzeichnis
Warum Datenanalyse?
Nun zuerst, warum Datenanalyse? Nun, es ist der erste Schritt, um zu wissen, mit welcher Art von Daten Sie arbeiten. Es ist der Schritt, in dem Sie wertvolle Muster in Daten finden, die Sie sonst vielleicht nicht sehen würden. Insgesamt bietet es ein intuitives Verständnis des vorliegenden Datensatzes.
Hier müssen wir eine Grenze zwischen Datenanalyse und Datenvorverarbeitung ziehen. Die Datenvorverarbeitung befasst sich mit der Modellierung Ihres Datensatzes, um sicherzustellen, dass er für das Training bereit ist. Die Datenanalyse besteht darin, den Datensatz zu verstehen, was ein Vorschritt für die Datenvorverarbeitung ist. Bei der Datenanalyse versuchen wir, Daten zu modellieren, um sie besser anzuzeigen und so Erkenntnisse über den vorliegenden Datensatz zu gewinnen.
Warum Python?
Die zweite Frage ist, warum Python? Nun, wir haben bereits festgestellt, dass Python eine weit verbreitete Sprache ist. Ja, es ist nicht die einzige Wahl, wenn es um die Datenanalyse geht, aber es ist eine ziemlich gute. Ein weiterer Grund dafür ist, dass es mehr verwendet wird! Python ist einfach und hat eine große Community von Entwicklern, die Ihnen bei der Datenanalyse mit Python helfen . Darüber hinaus macht die Datenanalyse mit Python aufgrund der großen Anzahl kreativer Bibliotheken, die sie für die Datenanalyse und -visualisierung bietet, sehr viel Spaß.
In Python ist die Basisbibliothek für die Datenanalyse Pandas. Es ist eine High-Level-Bibliothek, die auf der NumPy-Bibliothek aufbaut, die für wissenschaftliches Rechnen und numerische Analyse vorgesehen ist. Pandas erleichtern die Arbeit mit Daten, indem sie ihre als DataFrame bekannte Datenstruktur anbieten. DataFrame hilft beim Lesen und Speichern Ihres Datensatzes. Es bietet die Basisfunktionen zum Lesen und Schreiben des Datensatzes sowie zum Anzeigen der Metadaten und Abfragefunktionen, um alle Erkenntnisse aus dem Datensatz zu extrahieren.
Es ist wichtig zu beachten, dass die Datenvisualisierung einen erheblichen Teil der gesamten Datenanalyse ausmacht. Weil es nicht nur dabei hilft, die Daten besser zu verstehen, sondern auch denen, denen Sie die Erkenntnisse liefern. Wir würden die beiden am häufigsten verwendeten Bibliotheken für die Visualisierung diskutieren: Matplotlib und Seaborn. Matplotlib ist die Basisbibliothek für alle Visualisierungen in Python. Seaborn basiert auch auf Matplotlib, das einige der kreativsten Datenvisualisierungsfunktionen bietet.
Umgebung einrichten
Der erste Schritt besteht darin, Ihre Umgebung einzurichten. Bei der Durchführung von Datenanalysen mit python ist es wichtig, eine geeignete Umgebung für die Aufbewahrung Ihrer gesamten Arbeit zu haben. Die Datenanalyse mit Python wird nicht nur ein Skript sein, sondern eine Interaktion von Ihnen selbst mit dem Datensatz, und dafür benötigen Sie einen geeigneten Arbeitsplatz.
In Python wird dieser Dienst von der Anaconda-Distribution bereitgestellt. Anacondas führender Arbeitsplatz ist das Jupyter-Notebook. Warum also Jupyter? Nun, Sie können die Visualisierungen direkt in Ihrem Notizbuch haben. Es hat auch einige magische Funktionen, mit denen Sie die Ausgabe direkt sehen können, ohne explizit anzugeben, wo Sie sie haben möchten.
Die Bibliotheken, Pandas und Matplotlib, sind vorinstalliert, und daher ist keine zusätzliche Einrichtung erforderlich, um sie zu verwenden.
Hier ist die Zusammenfassung, wie Sie die Datenanalyse mit Python umgehen können :
- Laden des Datensatzes
- Anzeigen der Metadaten des Datensatzes mit Pandas
- Datenvisualisierungen mit Matplotlib
- Sammeln von Erkenntnissen über Daten
Importieren Sie erforderliche Bibliotheken
Bevor wir anfangen, uns den Code für Schritte anzusehen, importieren Sie einfach die erforderlichen Bibliotheken mit Pseudo-Tags, z. B. mit dem Namen, den wir sie für das gesamte Programm nennen würden.
importiere numpy als np
pandas als pd importieren
# für Datenvisualisierungen
importiere matplotlib.pyplot als plt
seegeboren als sns importieren
Jetzt würden wir uns jeden Schritt ansehen und besprechen, welche Funktionen verfügbar sind und wie diese verwendet werden.
Zuerst Datensätze lesen. Pandas bieten einige grundlegende Funktionen zum Laden des Datensatzes in seine Kerndatenstruktur: DataFrame. Wir können es wie folgt verwenden.
data_df = pd.read_csv('heart.csv')
Die Ausgabe jeder Lesefunktion wird ein DataFrame sein. Abgesehen von CSV-Lesegeräten bieten Pandas Lesegeräte für fast alle Arten von Daten. Von HTML bis JSON und Excel.
Abgesehen davon, wenn Sie keine Daten als solche haben und Ihren Datensatz erstellen möchten, können Sie ganz einfach die Objektfunktionen von Pandas Series und DataFrame verwenden.
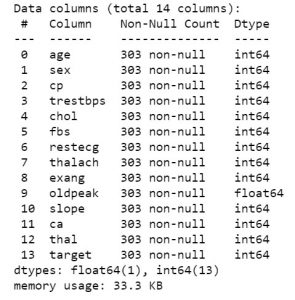
Sobald Sie also die Daten zur Hand haben, lassen Sie uns damit fortfahren, zu sehen, worum es in den Daten geht. Um eine erste Ansicht der Daten zu erhalten, können Sie Funktionen wie df.info oder df.describe verwenden, um die Struktur Ihres Datensatzes zu erfahren.
data_df.info()
data_df.describe()
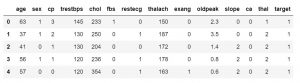
Sobald Sie wissen, welche Funktionen Ihr Datensatz enthält, möchten Sie sich vielleicht die Werte dieser Funktionen ansehen. Sie können die Funktion df.head() verwenden, um die ersten 5 Samples zu erhalten.
data_df.head()
#oder
data_df.head(3)
Sie können auch die Anzahl der Stichproben angeben, um den Standardwert von 5 zu überschreiben. Sie können auch die Funktion df.tail() verwenden, um die letzten 5 Werte des Datensatzes abzurufen.
data_df.tail()
Dies dient nur dazu, einen allgemeinen Überblick darüber zu erhalten, wie Ihre Daten aussehen könnten. Sobald Sie fertig sind, können Sie die wichtigsten Datenvisualisierungsaufgaben mit Matplotlib starten. Geben Sie den folgenden Code ein, um das Plotten interaktiv zu gestalten und dasselbe in Ihrem Notizbuch selbst anzuzeigen.
%matplotlib inline
Wir würden die Funktionalitäten der Top-5-Visualisierungen in matplotlib sehen. Bevor wir darauf eingehen, sollten wir einige andere Funktionen kennen, die unsere Diagramme steuern. Die Funktionen wie:
- Etiketten: xlabel(), ylabel(). Sie sind für die x-Achsen- und y-Achsen-Beschriftungen.
- Legende: Wird verwendet, um die Legende für die Handlung zu erstellen.
- Titel: Um Ihrer Handlung einen Titel zuzuweisen
- Und schließlich zeigen Sie die Funktion, um den Plot anzuzeigen.
Kasse: Gehalt für Datenanalysten in Indien
Visualisierungen
Sehen wir uns jetzt die Visualisierungen an. Wir würden mit der Grundhandlung beginnen. plt.plot() wird verwendet, um ein einfaches Liniendiagramm für Ihre Daten zu erstellen. Die Funktion erfordert zwangsweise zwei Parameter, und dies sind x-Achsendaten und y-Achsendaten. Sie können optional die Stile sowie den Namen und die Farbe für das Diagramm angeben. So sieht es im Code aus.
plt.plot(data_df['chol'])
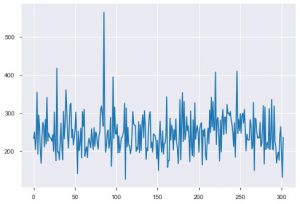
Der zweite Plot ist das Histogramm. Ein Histogramm hilft Ihnen, die Häufigkeit oder Verteilung eines bestimmten Merkmals anzuzeigen. Es hilft Ihnen zu sehen, wie sich die Mengen zueinander verhalten. Plt.hist() ist die Basisfunktion zum Erstellen eines Histogramms Ihrer Daten. Sie können den Parameter bins erwähnen, um die Anzahl auf dem Diagramm zu steuern. Sie müssen nur Daten einer einzelnen Achse übergeben, wenn Sie eine univariate Analyse wünschen.
plt.hist(data_df['age'])
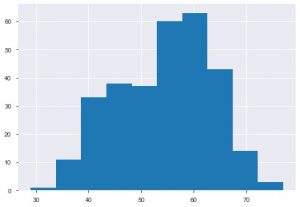
Ein weiteres Diagramm, das Sie häufig sehen würden, ist das Balkendiagramm. Es hilft bei der Analyse und dem Vergleich verschiedener Merkmale. Im Gegensatz zu Histogrammen werden Balkendiagramme zum Arbeiten mit kategorialen Daten verwendet.

Sie können das Diagramm direkt auf den DataFrame anwenden oder die Parameter in der Funktion plt.bar() angeben. So verwenden wir es.
df = pd.DataFrame(np.random.rand(15, 5), Spalten=['t1', 't2', 't3', 't4', 't5'])
df.plot.bar()
Sie können das Balkendiagramm auch horizontal verwenden, indem Sie die Funktion barh() verwenden.
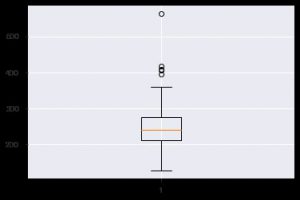
Eine weitere aufschlussreiche Grafik ist der Boxplot. Es hilft beim Verständnis der Verteilung der Werte innerhalb jedes Features. Sie können die Funktion plt.boxplot() verwenden, um die Daten anzugeben, für die Sie einen Boxplot generieren möchten. Das Diagramm ist besonders nützlich, wenn Sie die Streuung im Datensatz oder die Schiefe schnell anzeigen müssen. So können Sie es verwenden.
plt.boxplot(data_df['chol'])
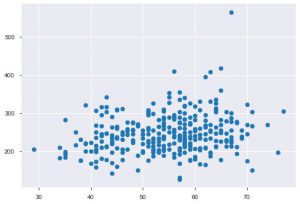
Wann immer Sie mit statistischen Daten arbeiten, sehen Sie auf jeden Fall ein Streudiagramm. Ein Streudiagramm hilft bei der Beobachtung der Beziehung zwischen zwei Merkmalen. Das Diagramm erfordert numerische Werte sowohl für die x-Achsendaten als auch für die y-Achse. Sie können diese beiden Werte einfach in der plt.scatter()-Funktion bereitstellen oder direkt auf den DataFrame anwenden, indem Sie Spaltennamen in den x- und y-Attributen angeben. So können Sie das verwenden:
plt.scatter(data_df['age'], data_df['chol'])
Jetzt ist der richtige Zeitpunkt, um Ihnen die Seaborn-Funktionen vorzustellen. Das Streudiagramm in Seaborn ist intuitiver als die Matplotlib, da es standardmäßig auch eine Regressionslinie im Diagramm bereitstellt, um das Diagramm besser zu visualisieren. Sie können die Funktion sns.lmplot() verwenden, um diesen Plot zu erstellen.
sns.lmplot('alter', 'chol', data=data_df)
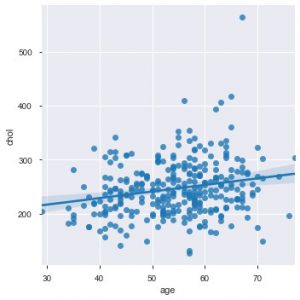
Wie Sie im obigen Diagramm sehen können, hilft die Regressionslinie, die Verteilung noch besser zu verstehen.
Eine weitere Verbesserung mit Seaborn ist der Schwarmplot. Es wird verwendet, um ein kategorisches Streudiagramm zu zeichnen. Einer der Vorteile des Schwarmdiagramms gegenüber dem ähnlichen Streifendiagramm besteht darin, dass es nur die nicht überlappenden Punkte verwendet. Es ist also eine sauberere Handlung und gibt daher einen besseren Einblick.
sns.swarmplot(data_df['age'], data_df['chol'])
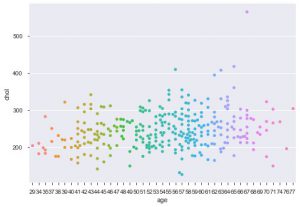
Das sind also die verschiedenen Arten von Plots in Matplotlib und Seaborn. Dies ist nur die Spitze des Eisbergs, und es gibt Hunderte anderer Möglichkeiten, Ihre Daten grafisch darzustellen, um daraus kreative Erkenntnisse zu gewinnen.
Nun, da Sie die Diagramme kennen, lassen Sie uns sehen, wie die eigentliche Datenanalyse mit python durchgeführt wird . Wir würden uns einige weitere Diagramme ansehen und sehen, was sie uns über die Datenanalyse mit Python zeigen .
Lasst uns beginnen.
Nach dem Laden der Daten erstellt jeder Datenanalyst als Erstes ein Pandas-Profil. Nun, dies kann auch als Abkürzung betrachtet werden, aber wenn Sie alle Beziehungen und Zählungen und Histogramme der Variablen im Datensatz sehen möchten, können Sie Pandas-Profilerstellung verwenden. Es ist sehr einfach zu generieren, laden Sie einfach das Pandas-Profiling-Modul herunter und geben Sie den folgenden Code ein:
pandas_profiling importieren
profile = pandas_profiling.ProfileReport(data_df)
Profil
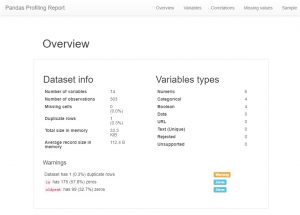
Wie Sie sehen können, gibt es eine riesige Menge an Metadateninformationen und auch Informationen zu einzelnen Merkmalen. Diese könnten zu einem großen Verständnis führen.
Als zweites können wir eine Heatmap generieren. Nun, was eine Heatmap tut, ist, sie zeigt die Korrelation jedes Merkmals mit dem anderen. Und wenn wir einen Wert mit einer höheren Korrelation finden, bedeutet das, dass die beiden Merkmale einander sehr ähnlich sind. Wir können also eines der Features weglassen, und das Modell wird trotzdem gut funktionieren.
sns.heatmap(data_df.corr(), annot = True , cmap='Oranges')
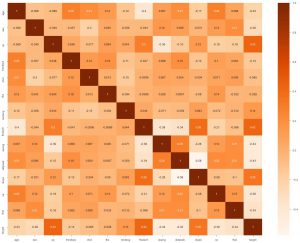
Hier können wir sehen, dass keine stark verwandt sind, sodass wir dem Modellingenieur sagen können, dass wir alle Merkmale als Eingabe benötigen würden.
Wir können die Altersverteilung sehen, weil wir es mit dem Herzkrankheitsdatensatz zu tun haben, lassen Sie uns die Verteilung sehen, damit wir das Distplot von Seaborn verwenden können.
sns.distplot(data_df['age'], color = 'cyan')
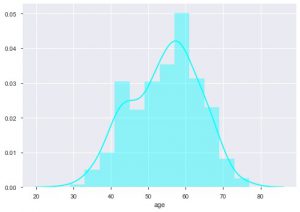
Aus dem Diagramm können Sie entnehmen, dass die meisten Menschen, die an Herzerkrankungen leiden, zwischen 50 und 60 Jahre alt sind. Auf die gleiche Weise können wir auch einige andere wichtige Merkmale wie den Ruheblutdruck sehen, der mit tresbps bezeichnet wird. Wir können ein Boxplot erstellen, um die Verteilung im Vergleich zum Zielwert, dh 0 und 1, zu sehen.
sns.boxplot(data_df['target'], data_df['trestbps'], palette = 'twilight')
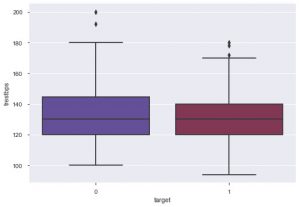
Wir können aus dem Diagramm schließen, dass die Wahrscheinlichkeit, dass die Person an einer Herzkrankheit leidet, geringer ist als bei Personen mit einem höheren Tres-bps-Wert, wenn die Person einen niedrigeren Tres-bps-Wert hat.
Auf die gleiche Weise können wir auch den Zusammenhang mit dem Cholesterinspiegel sehen. Wir sehen, dass Menschen mit einem niedrigeren Cholesterinspiegel ein geringeres Risiko haben, an Herzerkrankungen zu erkranken.
Sie können all diese Erkenntnisse dokumentieren und sie dem Machine Learning-Ingenieur zur Verfügung stellen, der sie dann zur Erstellung eines effizienten Modells verwenden kann.
Fazit
So können Sie also Datenanalysen mit Python durchführen . Dies ist nur der erste Schritt auf dem Weg zur Datenwissenschaft. Um mehr über das Extrahieren kreativer Erkenntnisse aus Daten und die allgemeine Datenwissenschaft zu erfahren, besuchen Sie die von upGrad angebotenen Kurse hier . Sie finden ein Spektrum an hilfreichen Kursen, die die Datenanalyse mit Python effektiv anleiten.
Lernen Sie Datenwissenschaftskurse von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.
Wie sollte ich anfangen, Python für die Datenanalyse zu lernen?
Wenn Sie auf dem Weg sind, Python für die Datenanalyse zu lernen, dann sind Sie hier genau richtig. Sie müssen Schritt für Schritt vorgehen, um den Lernprozess für alles einfacher zu machen. So sieht der Ablauf aus:
1. Machen Sie sich klar, warum Sie Python lernen möchten und wie Sie es in Ihrem Bereich einsetzen können.
2.Laden Sie das erforderliche Python-Terminal herunter und installieren Sie es in Ihrem System.
3. Beginnen Sie mit dem Erlernen der Grundlagen von Python, indem Sie verschiedene Kurse belegen und sich mit verschiedenen Python-Bibliotheken vertraut machen.
4. Machen Sie sich mit regulären Ausdrücken vertraut, die in Python verwendet werden.
5. Erwerben Sie fundierte Kenntnisse über verschiedene Python-Bibliotheken wie Pandas, NumPy, Matplotlib und SciPy.
6. Beginnen Sie mit dem Lernen von Datenanalysekonzepten und wie Sie Python damit integrieren können.
7. Jetzt müssen Sie nur noch verschiedene Tools und Techniken üben, um in Python for Data Analysis besser zu werden. Wenn Sie diesen Schritt-für-Schritt-Ansatz durchgehen, werden Sie es ziemlich einfach finden, Python zu lernen und sich für die Arbeit mit der Datenanalyse zu verbessern.
Wie wird Python für die Datenanalyse verwendet?
Python ist bekanntermaßen eine sehr wichtige Ressource für die Datenanalyse. Python hilft auf verschiedene Weise bei der Durchführung von Datenanalysen. Aber vorher müssen Sie Daten für die Analyse vorbereiten, statistische Analysen durchführen, Datenvisualisierungen erstellen, die Einblicke liefern könnten, zukünftige Trends auf der Grundlage der verfügbaren Daten vorhersagen und vieles mehr.
Python erweist sich als entscheidendes Element der Datenanalyse, da es hilft bei:
1. Datensätze importieren
2. Bereinigen und Vorbereiten der Daten für die Durchführung der Analyse
3. Manipulieren des Pandas DataFrame
4. Zusammenfassen der Datensätze
5. Entwicklung eines Machine-Learning-Modells für die Datenanalyse mit Python
Kann ich Python in einem Monat lernen?
Ja, Sie können dies auf jeden Fall erreichen, wenn Sie mit anderen Programmiersprachen wie Java, C, C++ usw. vertraut sind. Wenn Ihre Grundlagen klar sind, werden Sie es ziemlich einfach finden, Python selbst in einem einzigen Monat zu lernen. Abgesehen davon, wenn Sie sich Mühe geben und diszipliniert einem schrittweisen Ansatz folgen, können Sie Python in einem Monat lernen, selbst wenn Sie keine Vorkenntnisse in anderen Programmiersprachen haben. Sie müssen nur einen Zeitplan festlegen und sich in einem Monat dem Erlernen von Python widmen.