
Go und die Herausforderung der Künstlichen Allgemeinen Intelligenz
Veröffentlicht: 2018-02-15Dieser Artikel zielt darauf ab, die Verbindung zwischen dem Spiel „Go“ und künstlicher Intelligenz zu untersuchen. Das Ziel ist die Beantwortung der Fragen – Was macht das Go-Spiel besonders? Warum war es für einen Computer schwierig, das Go-Spiel zu meistern? Warum konnte ein Computerprogramm 1997 einen Schachgroßmeister schlagen? Warum hat es fast zwei Jahrzehnte gedauert, um Go zu knacken?
„Herren sollten ihre Zeit nicht mit trivialen Spielen verschwenden – sie sollten Go lernen“
– Konfuzius
Tatsächlich dachten Experten für künstliche Intelligenz, dass Computer nur bis 2027 in der Lage sein würden, einen Go-Weltmeister zu schlagen. Dank DeepMind, einem Unternehmen für künstliche Intelligenz unter dem Dach von Google, wurde diese gewaltige Aufgabe ein Jahrzehnt früher bewältigt. Dieser Artikel wird über die Technologien sprechen, die DeepMind verwendet, um den Go-Weltmeister zu schlagen. Schließlich erörtert dieser Beitrag, wie diese Technologie verwendet werden kann, um einige komplexe, reale Probleme zu lösen.
Inhaltsverzeichnis
Gehen – Was ist das?
Go ist ein 3000 Jahre altes chinesisches Strategie-Brettspiel, das seine Popularität über die Jahrhunderte hinweg bewahrt hat. Go wird von Millionen von Menschen weltweit gespielt und ist ein Brettspiel für zwei Spieler mit einfachen Regeln und intuitiver Strategie. Für dieses Spiel werden verschiedene Brettgrößen verwendet; Profis verwenden ein 19×19-Board.

Das Spiel beginnt mit einem leeren Brett. Jeder Spieler platziert dann abwechselnd die schwarzen und weißen Steine (Schwarz geht zuerst) auf dem Brett am Schnittpunkt der Linien (anders als beim Schach, wo Sie Figuren in die Quadrate legen). Ein Spieler kann die Steine des Gegners erobern, indem er sie von allen Seiten umgibt. Für jeden erbeuteten Stein werden dem Spieler einige Punkte gutgeschrieben. Das Ziel des Spiels ist es, das größtmögliche Territorium auf dem Brett zu besetzen und gleichzeitig die Steine Ihrer Gegner zu erobern.
Bei Go geht es um Schöpfung, im Gegensatz zu Schach, bei dem es um Zerstörung geht. Go erfordert Freiheit, Kreativität, Intuition, Gleichgewicht, Strategie und intellektuelle Tiefe, um das Spiel zu meistern. Go spielen betrifft beide Gehirnhälften. Tatsächlich haben die Gehirnscans von Go-Spielern gezeigt, dass Go bei der Gehirnentwicklung hilft, indem es die Verbindungen zwischen beiden Gehirnhälften verbessert.
Neuronale Netze für Dummies: Ein umfassender Leitfaden
Go und die Herausforderung der künstlichen Intelligenz (KI)
1952 beherrschten Computer Tic-Tac- Toe . Deep Blue konnte Schach -Großmeister Garry Kasparov 1997 schlagen . Das Computerprogramm konnte 2001 in Jeopardy (einem populären amerikanischen Spiel) gegen den Weltmeister gewinnen . AlphaGo von DeepMind konnte 2016 einen Go - Weltmeister besiegen . Warum wird es als Herausforderung für ein Computerprogramm angesehen, das Go-Spiel zu beherrschen?
Schach wird auf einem 8×8-Brett gespielt, während Go ein 19×19-Brett verwendet. Bei der Eröffnung eines Schachspiels hat ein Spieler 20 mögliche Züge. Bei einer Go-Eröffnung kann ein Spieler 361 mögliche Züge haben. Die Anzahl der möglichen Positionen auf dem Go-Brett entspricht 10 hoch 170; mehr als die Zahl der Atome in unserem Universum! Die potenzielle Anzahl von Brettpositionen macht Go Googol mal (10 hoch 100) komplexer als Schach.
Beim Schach steht ein Spieler für jeden Schritt vor einer Auswahl von 35 Zügen. Im Durchschnitt hat ein Go-Spieler bei jedem Schritt 250 mögliche Züge. Beim Schach ist es für einen Computer relativ einfach, an jeder beliebigen Position eine Brute-Force-Suche durchzuführen und den bestmöglichen Zug auszuwählen, der die Gewinnchancen maximiert. Eine Brute-Force-Suche ist im Fall von Go nicht möglich, da die potenzielle Anzahl zulässiger Züge für jeden Schritt enorm ist.
Für einen Computer, Schach zu beherrschen, wird es im Laufe des Spiels einfacher, weil die Figuren vom Brett entfernt werden. Bei Go wird es für das Computerprogramm schwieriger, da im Laufe des Spiels Steine auf das Brett gelegt werden. Normalerweise dauert ein Go-Spiel dreimal länger als eine Schachpartie.
Aus all diesen Gründen konnte ein Top-Computer-Go-Programm den Go-Weltmeister erst 2016 nach einer gewaltigen Explosion neuer maschineller Lerntechniken einholen. Wissenschaftler, die bei DeepMind arbeiteten, waren in der Lage, ein Computerprogramm namens AlphaGo zu entwickeln , das den Weltmeister Lee Seedol besiegte . Die Erfüllung der Aufgabe war nicht einfach. Die Forscher von DeepMind haben bei der Entwicklung von AlphaGo viele neuartige Innovationen hervorgebracht.
„Die Regeln von Go sind so elegant, organisch und rigoros logisch, dass, wenn es irgendwo im Universum intelligente Lebensformen gibt, sie mit ziemlicher Sicherheit Go spielen.“
– Eduard Laskar
Neuronale Netze: Anwendungen in der realen Welt
Wie AlphaGo funktioniert
AlphaGo ist ein universeller Algorithmus, was bedeutet, dass er auch zum Lösen anderer Aufgaben verwendet werden kann. Beispielsweise ist Deep Blue von IBM speziell für das Schachspielen konzipiert. Schachregeln zusammen mit dem gesammelten Wissen aus Jahrhunderten des Spielens des Spiels sind in das Gehirn des Programms einprogrammiert. Deep Blue kann nicht einmal für triviale Spiele wie Tic-Tac-Toe verwendet werden. Es kann nur eine bestimmte Sache, worin es sehr gut ist, nämlich Schach spielen. AlphaGo kann lernen, neben Go auch andere Spiele zu spielen. Diese Allzweckalgorithmen bilden ein neues Forschungsgebiet, das als Künstliche Allgemeine Intelligenz bezeichnet wird.
AlphaGo verwendet modernste Methoden – Deep Neural Networks (DNN), Reinforcement Learning (RL), Monte Carlo Tree Search (MCTS), Deep Q Networks (DQN) (eine neuartige Technik, die von DeepMind eingeführt und populär gemacht wurde und neuronale Netzwerke mit Reinforcement Learning), um nur einige zu nennen. Anschließend kombiniert es all diese Methoden auf innovative Weise, um im Go-Spiel eine Meisterschaft auf übermenschlichem Niveau zu erreichen.
Schauen wir uns zuerst jedes einzelne Teil dieses Puzzles an, bevor wir uns ansehen, wie diese Teile miteinander verbunden sind, um die anstehende Aufgabe zu erfüllen.
Tiefe neuronale Netze
DNNs sind eine Technik zum maschinellen Lernen, die lose von der Funktionsweise des menschlichen Gehirns inspiriert ist. Die Architektur eines DNN besteht aus Schichten von Neuronen. DNN kann Muster in Daten erkennen, ohne explizit dafür programmiert zu sein.
Es ordnet die Eingänge den Ausgängen zu, ohne dass jemand es speziell dafür programmiert. Nehmen wir als Beispiel an, dass wir das Netz mit vielen Katzen- und Hundefotos gefüttert haben. Gleichzeitig trainieren wir das System auch, indem wir ihm (in Form von Labels) mitteilen, ob ein bestimmtes Bild von einer Katze oder einem Hund stammt (dies wird als überwachtes Lernen bezeichnet). Ein DNN wird lernen, das Muster auf den Fotos zu erkennen, um erfolgreich zwischen einer Katze und einem Hund zu unterscheiden. Das Hauptziel des Trainings besteht darin, dass ein DNN, wenn er ein neues Bild von einem Hund oder einer Katze sieht, in der Lage sein sollte, es richtig zu klassifizieren, dh vorherzusagen, ob es sich um eine Katze oder einen Hund handelt.
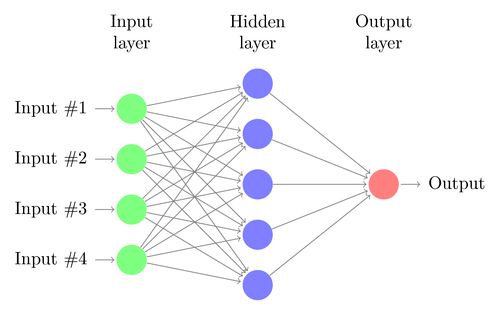
Lassen Sie uns die Architektur eines einfachen DNN verstehen. Die Anzahl der Neuronen in der Eingabeschicht entspricht der Größe der Eingabe. Nehmen wir an, unsere Katzen- und Hundefotos sind ein 28×28-Bild. Jede Zeile und Spalte besteht aus jeweils 28 Pixeln, was insgesamt 784 Pixel für jedes Bild ergibt. In einem solchen Fall besteht die Eingabeschicht aus 784 Neuronen, eines für jedes Pixel. Die Anzahl der Neuronen in der Ausgabeschicht hängt von der Anzahl der Klassen ab, in die die Ausgabe klassifiziert werden muss. In diesem Fall besteht die Ausgabeschicht aus zwei Neuronen – eines entspricht „Katze“, das andere „Hund“.
Halten Sie Ausschau nach dem nächsten großen Ding: Maschinelles Lernen
Es wird viele Neuronenschichten zwischen den Eingabe- und Ausgabeschichten geben (was der Ursprung der Verwendung des Begriffs „Deep“ in „Deep Neural Network“) ist. Diese werden als „versteckte Schichten“ bezeichnet. Die Anzahl der verborgenen Schichten und die Anzahl der Neuronen in jeder Schicht ist nicht festgelegt. Tatsächlich führt die Änderung dieser Werte genau zur Leistungsoptimierung. Diese Werte werden als Hyperparameter bezeichnet und müssen entsprechend dem jeweiligen Problem angepasst werden. Bei den Experimenten rund um neuronale Netze geht es vor allem darum, die optimale Anzahl von Hyperparametern herauszufinden.
Die Trainingsphase von DNNs besteht aus einem Vorwärtspass und einem Rückwärtspass. Zunächst werden alle Verbindungen zwischen den Neuronen mit zufälligen Gewichten initialisiert. Während des Vorwärtsdurchlaufs wird das Netzwerk mit einem einzigen Bild gespeist. Die Eingaben (Pixeldaten aus dem Bild) werden mit den Parametern des Netzwerks (Gewichte, Bias und Aktivierungsfunktionen) kombiniert und durch verborgene Schichten bis hin zur Ausgabe weitergeleitet, die eine Wahrscheinlichkeit zurückgibt, dass ein Foto zu jeder gehört der Klassen.
Dann wird diese Wahrscheinlichkeit mit dem tatsächlichen Klassenlabel verglichen und ein „Fehler“ berechnet. An diesem Punkt wird der Rückwärtsdurchgang durchgeführt – diese Fehlerinformationen werden durch eine Technik namens „Back-Propagation“ durch das Netzwerk zurückgeleitet. Während der Anfangsphasen des Trainings wird dieser Fehler hoch sein, und ein guter Trainingsmechanismus wird diesen Fehler allmählich reduzieren.
Die DNNs werden auf diese Weise mit einem Vorwärts- und Rückwärtsdurchgang trainiert, bis sich die Gewichte nicht mehr ändern (dies wird als Konvergenz bezeichnet). Dann werden die DNNs in der Lage sein, die Bilder mit hoher Genauigkeit vorherzusagen und zu klassifizieren, dh ob auf dem Bild eine Katze oder ein Hund zu sehen ist.

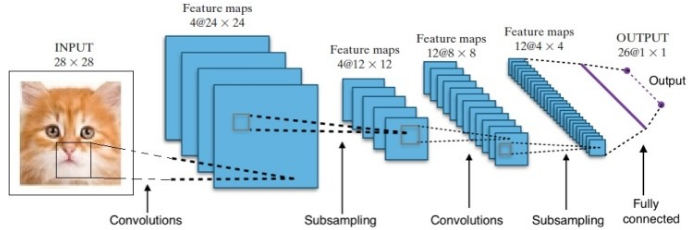
Die Forschung hat uns viele verschiedene tiefe neuronale Netzwerkarchitekturen beschert. Bei Computer-Vision-Problemen (dh Problemen mit Bildern) haben Convolution Neural Networks (CNNs) traditionell gute Ergebnisse erzielt. Bei Fragestellungen, die eine Sequenz betreffen – Spracherkennung oder Sprachübersetzung – liefern Recurrent Neural Networks (RNN) hervorragende Ergebnisse.
Ein Leitfaden für Anfänger zum Verständnis natürlicher Sprache
Im Fall von AlphaGo war der Prozess wie folgt: Zunächst wurde das Convolution Neural Network (CNN) auf Millionen von Bildern von Vorstandspositionen trainiert. Als nächstes wurde das Netzwerk über den jeweils nachfolgenden Spielzug der menschlichen Experten während der Trainingsphase des Netzwerks informiert. Auf die gleiche Weise wie zuvor erwähnt, wurde der tatsächliche Wert mit der Ausgabe verglichen und eine Art „Fehler“-Metrik gefunden.
Am Ende des Trainings gibt das DNN die nächsten Züge zusammen mit Wahrscheinlichkeiten aus, die wahrscheinlich von einem erfahrenen menschlichen Spieler gespielt werden. Diese Art von Netzwerk kann nur einen Schritt hervorbringen, der von einem menschlichen Expertenspieler gespielt wird. DeepMind war in der Lage, eine Genauigkeit von 60 % bei der Vorhersage der Bewegung zu erreichen, die der Mensch machen würde. Um einen menschlichen Experten bei Go zu schlagen, reicht dies jedoch nicht aus. Die Ausgabe des DNN wird von Deep Reinforcement Network weiterverarbeitet, einem von DeepMind konzipierten Ansatz, der tiefe neuronale Netze und Reinforcement Learning kombiniert.
Tiefes Verstärkungslernen
Reinforcement Learning (RL) ist kein neues Konzept. Nobelpreisträger Ivan Pavlov experimentierte mit klassischer Konditionierung an Hunden und entdeckte 1902 die Prinzipien des Reinforcement Learning. RL ist auch eine der Methoden, mit denen Menschen neue Fähigkeiten erlernen. Haben Sie sich jemals gefragt, wie die Delfine in Shows darauf trainiert werden, in so große Höhen aus dem Wasser zu springen? Es ist mit Hilfe von RL. Zuerst wird das Seil, das zum Präparieren der Delfine verwendet wird, in das Becken getaucht. Immer wenn der Delfin das Kabel von oben überquert, wird er mit Futter belohnt. Wenn es das Seil nicht überquert, wird die Belohnung zurückgezogen. Langsam lernt der Delphin, dass er bezahlt wird, wenn er die Schnur von oben passiert. Die Höhe des Seils wird allmählich erhöht, um den Delfin zu trainieren. 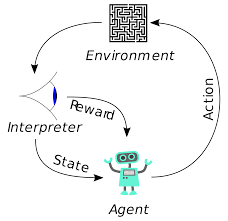
Generierung natürlicher Sprache: Die wichtigsten Dinge, die Sie wissen müssen
Auch Agenten im Reinforcement Learning werden nach dem gleichen Prinzip trainiert. Der Agent wird handeln und mit der Umgebung interagieren. Die vom Agenten durchgeführte Aktion bewirkt, dass sich die Umgebung ändert. Außerdem erhielt der Agent Feedback über die Umgebung. Der Agent wird entweder belohnt oder nicht, abhängig von seiner Aktion und dem vorliegenden Ziel. Wichtig ist, dass dieses Ziel nicht ausdrücklich für den Agenten angegeben wird. Bei ausreichender Zeit lernt der Agent, wie er zukünftige Belohnungen maximieren kann.

In Kombination mit DNNs erfand DeepMind Deep Reinforcement Learning (DRL) oder Deep Q Networks (DQN), wobei Q für maximale zukünftige Belohnungen steht. DQNs wurden zuerst auf Atari - Spiele angewendet. DQN hat gelernt, wie man verschiedene Arten von Atari-Spielen direkt nach dem Auspacken spielt. Der Durchbruch war, dass keine explizite Programmierung erforderlich war, um verschiedene Arten von Atari-Spielen darzustellen. Ein einziges Programm war intelligent genug, um alle verschiedenen Umgebungen des Spiels kennenzulernen, und konnte durch Selbstspiel viele davon meistern.
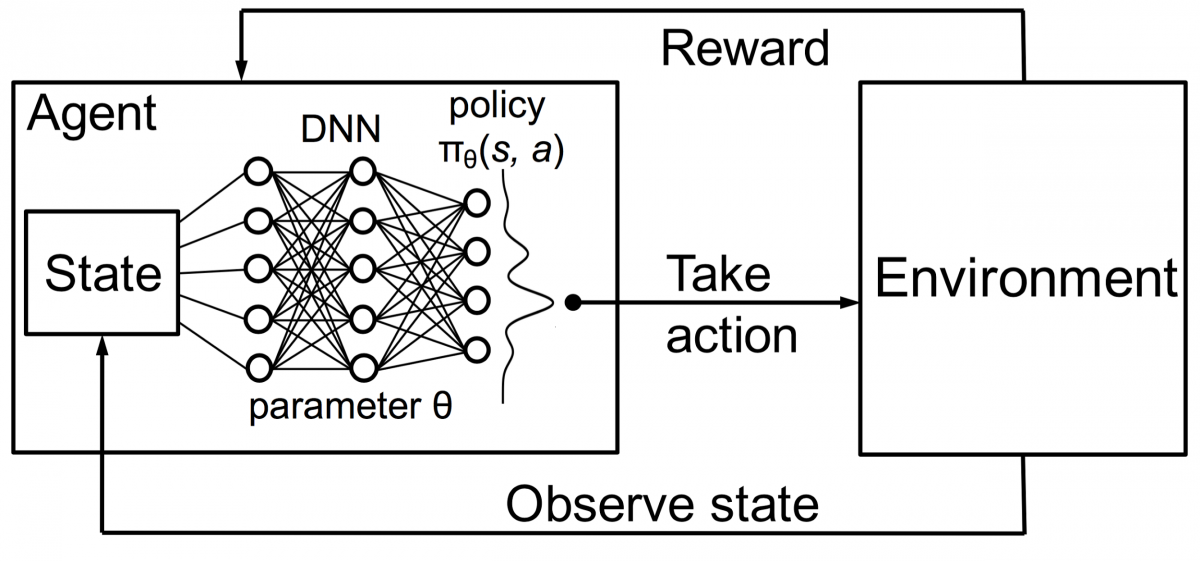
Im Jahr 2014 übertraf DQN frühere Methoden des maschinellen Lernens in 43 der 49 Spiele (jetzt wurde es in mehr als 70 Spielen getestet). Tatsächlich hat es in mehr als der Hälfte der Spiele mehr als 75 % des Niveaus eines professionellen menschlichen Spielers erreicht. In bestimmten Spielen entwickelte DQN sogar überraschend weitsichtige Strategien, die es ihm ermöglichten, die maximal erreichbare Punktzahl zu erreichen – zum Beispiel lernte es in Breakout , zuerst einen Tunnel an einem Ende der Mauer zu graben, damit der Ball abprallt um die Rückseite und klopfe Steine von hinten heraus.
Politik und Wertenetzwerke
Es gibt zwei Haupttypen von Netzwerken innerhalb von AlphaGo:
Eines der Ziele der DQNs von AlphaGo ist es, über das menschliche Expertenspiel hinauszugehen und neue innovative Züge nachzuahmen, indem es millionenfach gegen sich selbst spielt und dadurch die Gewichte schrittweise verbessert. Dieser DQN hatte eine Gewinnrate von 80 % gegenüber herkömmlichen DNNs. DeepMind beschloss, diese beiden neuronalen Netze (DNN und DQN) zu kombinieren, um den ersten Netztyp zu bilden – ein „Policy Network“. Kurz gesagt besteht die Aufgabe eines politischen Netzwerks darin, die Breite der Suche nach dem nächsten Schritt zu verringern und einige gute Schritte zu finden, die es wert sind, weiter untersucht zu werden.
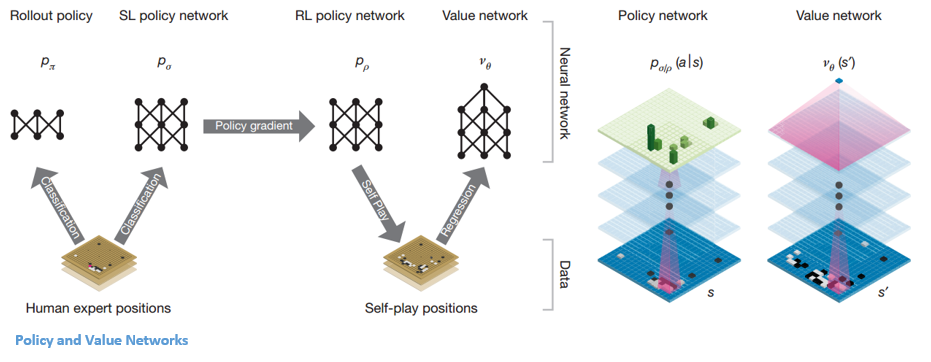 Sobald das Richtliniennetzwerk eingefroren ist, spielt es millionenfach gegen sich selbst. Diese Spiele generieren einen neuen Go-Datensatz, der aus den verschiedenen Brettpositionen und den Ergebnissen der Spiele besteht. Dieser Datensatz wird verwendet, um eine Bewertungsfunktion zu erstellen. Der zweite Funktionstyp – das „Value Network“ – wird verwendet, um den Ausgang des Spiels vorherzusagen. Es lernt, verschiedene Brettpositionen als Eingaben zu nehmen und das Ergebnis des Spiels und dessen Maß vorherzusagen.
Sobald das Richtliniennetzwerk eingefroren ist, spielt es millionenfach gegen sich selbst. Diese Spiele generieren einen neuen Go-Datensatz, der aus den verschiedenen Brettpositionen und den Ergebnissen der Spiele besteht. Dieser Datensatz wird verwendet, um eine Bewertungsfunktion zu erstellen. Der zweite Funktionstyp – das „Value Network“ – wird verwendet, um den Ausgang des Spiels vorherzusagen. Es lernt, verschiedene Brettpositionen als Eingaben zu nehmen und das Ergebnis des Spiels und dessen Maß vorherzusagen.
Kombination von Politik- und Wertenetzwerken
Nach all diesem Training hatte DeepMind schließlich zwei neuronale Netze – Policy und Value Networks. Das Richtliniennetzwerk nimmt die Vorstandsposition als Eingabe und gibt die Wahrscheinlichkeitsverteilung als die Wahrscheinlichkeit jeder der Bewegungen in dieser Position aus. Das Wertenetzwerk nimmt wieder die Position des Bretts als Input ein und gibt eine einzelne reelle Zahl zwischen 0 und 1 aus. Wenn der Output des Netzwerks null ist, bedeutet dies, dass Weiß vollständig gewinnt, und 1 zeigt einen vollständigen Gewinn für den Spieler mit Schwarz an Steine.
Das Policy-Netzwerk bewertet aktuelle Positionen, und das Wertenetzwerk bewertet zukünftige Schritte. Die Aufgabenteilung in diese beiden Netzwerke durch DeepMind war einer der wesentlichen Gründe für den Erfolg von AlphaGo.
Kombinieren von Policy- und Value-Netzwerken mit Monte Carlo Tree Search (MCTS) und Rollouts
Die neuronalen Netze allein werden nicht ausreichen. Um das Go-Spiel zu gewinnen, ist etwas mehr Strategie erforderlich. Dieser Plan wird mit Hilfe von MCTS erreicht. Die Monte-Carlo-Baumsuche hilft auch dabei, die beiden neuronalen Netze auf innovative Weise zusammenzufügen. Neuronale Netze helfen bei einer effizienten Suche nach dem nächstbesten Zug.
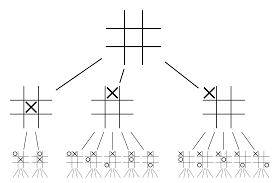
Lassen Sie uns versuchen, ein Beispiel zu konstruieren, das Ihnen hilft, sich das alles viel besser vorzustellen. Stellen Sie sich vor, das Spiel befindet sich in einer neuen Position, die noch nie zuvor aufgetreten ist. In einer solchen Situation wird ein politisches Netzwerk aufgerufen, um die aktuelle Situation und mögliche zukünftige Wege zu bewerten; sowie die Attraktivität der Pfade und der Wert jeder Bewegung durch die Wertschöpfungsnetzwerke, unterstützt durch Monte-Carlo-Rollouts.
Policy Network findet alle möglichen „guten“ Schritte und Value Networks bewerten jedes ihrer Ergebnisse. Bei Monte-Carlo-Rollouts werden einige tausend zufällige Spiele von den Positionen aus gespielt, die vom Richtliniennetzwerk erkannt werden. Es wurden Experimente durchgeführt, um die relative Bedeutung von Wertschöpfungsnetzwerken gegenüber Monte-Carlo-Einführungen zu bestimmen. Als Ergebnis dieser Experimente wies DeepMind den Wertnetzwerken eine Gewichtung von 80 % und der Monte-Carlo-Rollout-Evaluierungsfunktion eine Gewichtung von 20 % zu.
Das Richtliniennetzwerk reduziert die Breite der Suche von etwa 200 möglichen Zügen auf die 4 oder 5 besten Züge. Das Richtliniennetzwerk erweitert den Baum aus diesen 4 oder 5 Schritten, die berücksichtigt werden müssen. Das Wertenetzwerk hilft dabei, die Tiefe der Baumsuche zu verringern, indem das Ergebnis des Spiels von dieser Position sofort zurückgegeben wird. Schließlich wird der Zug mit dem höchsten Q-Wert ausgewählt, dh der Schritt mit dem größten Nutzen.
„ Das Spiel wird hauptsächlich durch Intuition und Gefühl gespielt, und wegen seiner Schönheit, Subtilität und intellektuellen Tiefe hat es die menschliche Vorstellungskraft seit Jahrhunderten gefesselt.“
– Demis Hassabis
Anwendung von AlphaGo auf reale Probleme
Die Vision von DeepMind auf ihrer Website ist sehr aufschlussreich – „Intelligenz lösen. Nutzen Sie dieses Wissen, um die Welt zu einem besseren Ort zu machen.“ Das Endziel dieses Algorithmus ist es, ihn universell zu machen, damit er zur Lösung komplexer realer Probleme verwendet werden kann. AlphaGo von DeepMind ist ein bedeutender Fortschritt bei der Suche nach AGI. DeepMind hat seine Technologie erfolgreich eingesetzt, um reale Probleme zu lösen – schauen wir uns einige Beispiele an:
Reduzierung des Energieverbrauchs
Die KI von DeepMind wurde erfolgreich eingesetzt, um die Kühlkosten von Googles Rechenzentrum um 40 % zu senken. In jeder groß angelegten energieverbrauchenden Umgebung ist diese Verbesserung ein phänomenaler Schritt nach vorn. Eine der Hauptenergiequellen für ein Rechenzentrum ist die Kühlung. Viel Wärme, die beim Betrieb der Server entsteht, muss abgeführt werden, um sie betriebsbereit zu halten. Dies wird durch industrielle Großanlagen wie Pumpen, Kältemaschinen und Kühltürme erreicht. Da die Umgebung des Rechenzentrums sehr dynamisch ist, ist es eine Herausforderung, mit optimaler Energieeffizienz zu arbeiten. Die KI von DeepMind wurde verwendet, um dieses Problem anzugehen.
Zunächst nutzten sie historische Daten, die von Tausenden von Sensoren im Rechenzentrum gesammelt wurden. Anhand dieser Daten trainierten sie ein Ensemble von DNNs auf die durchschnittliche zukünftige Power Usage Effectiveness (PUE). Da es sich um einen Allzweckalgorithmus handelt, ist geplant, ihn auch auf andere Herausforderungen im Rechenzentrumsumfeld anzuwenden.
Zu den möglichen Anwendungen dieser Technologie gehören die Gewinnung von mehr Energie aus der gleichen Eingangseinheit, die Reduzierung des Energie- und Wasserverbrauchs bei der Halbleiterherstellung usw. DeepMind kündigte in seinem Blogbeitrag an, dass dieses Wissen in einer zukünftigen Veröffentlichung geteilt werden würde, damit andere Rechenzentren, Industrie Betreiber und letztendlich die Umwelt können von diesem bedeutenden Schritt stark profitieren.
Strahlentherapieplanung bei Kopf-Hals-Tumoren
DeepMind hat mit der Abteilung für Strahlentherapie des NHS Foundation Trust des University College London Hospital zusammengearbeitet, einem weltweit führenden Unternehmen in der Krebsbehandlung.
Wie sich Big Data und maschinelles Lernen gegen Krebs vereinen
Bei einem von 75 Männern und einer von 150 Frauen wird in ihrem Leben Mundkrebs diagnostiziert. Aufgrund der Empfindlichkeit der Strukturen und Organe im Kopf-Hals-Bereich müssen Radiologen bei der Behandlung äußerste Sorgfalt walten lassen.
Vor der Durchführung einer Strahlentherapie muss eine detaillierte Karte mit den zu behandelnden und zu vermeidenden Bereichen erstellt werden. Dies wird als Segmentierung bezeichnet. Diese segmentierte Karte wird in das Röntgengerät eingespeist, das dann auf Krebszellen abzielt, ohne gesunde Zellen zu schädigen.
Bei Krebserkrankungen im Kopf-Hals-Bereich ist dies für die Radiologen eine mühselige Arbeit, da es sich um sehr empfindliche Organe handelt. Rund vier Stunden brauchen die Radiologen, um eine segmentierte Karte für diesen Bereich zu erstellen. DeepMind zielt durch seine Algorithmen darauf ab, die Zeit, die zum Generieren der segmentierten Karten benötigt wird, von vier auf eine Stunde zu reduzieren. Dies wird die Zeit des Radiologen erheblich entlasten. Noch wichtiger ist, dass dieser Segmentierungsalgorithmus für andere Körperteile verwendet werden kann.
Zusammenfassend hat AlphaGo den 18-fachen Go-Weltmeister Lee Seedol 2016 in einem Best-of-Five-Turnier viermal erfolgreich geschlagen. 2017 schlug es sogar ein Team der weltbesten Spieler. Es verwendet eine Kombination aus DNN und DQN als Richtliniennetzwerk, um den nächstbesten Zug zu finden, und ein DNN als Wertenetzwerk, um das Ergebnis des Spiels zu bewerten. Die Monte-Carlo-Baumsuche wird zusammen mit den Richtlinien- und Wertnetzwerken verwendet, um die Breite und Tiefe der Suche zu reduzieren – sie werden verwendet, um die Bewertungsfunktion zu verbessern. Das ultimative Ziel dieses Algorithmus ist es nicht, Brettspiele zu lösen, sondern einen Algorithmus für künstliche allgemeine Intelligenz zu erfinden. AlphaGo ist zweifellos einen großen Schritt in diese Richtung voraus.
Der Unterschied zwischen Data Science, Machine Learning und Big Data!
Natürlich gab es noch andere Effekte. Als die Nachricht von AlphaGo gegen Lee Seedol viral wurde, stieg die Nachfrage nach Go-Boards um das Zehnfache. Viele Geschäfte berichteten, dass Go-Boards ausverkauft waren, und es wurde schwierig, ein Go-Board zu kaufen.
Glücklicherweise habe ich gerade einen gefunden und ihn für mich und mein Kind bestellt. Planen Sie, das Board zu kaufen und Go zu lernen?
Lernen Sie ML-Kurse von den besten Universitäten der Welt. Erwerben Sie Master-, Executive PGP- oder Advanced Certificate-Programme, um Ihre Karriere zu beschleunigen.
Welche Grenzen hat Deep Reinforcement Learning?
DL vergisst zuvor erworbenes Wissen, wenn neue Daten oder Informationen eingeführt werden, also stellt es es nicht in Frage. Zu viel Verstärkung kann manchmal zu einem Überschuss an Zuständen führen, was die Effektivität verringert. Aufgrund der Komplexität von Datenmodellen ist das Training äußerst kostspielig. Deep Learning erfordert auch den Einsatz teurer GPUs und Hunderter von Workstations. Infolgedessen wird es weniger wirtschaftlich in der Anwendung.
Welche Nachteile hat die Monte-Carlo-Baumsuche?
Obwohl MCTS ein einfach auszuführender Algorithmus ist, hat er bestimmte Nachteile. Wenn der Baum nach einigen Iterationen größer wird, wird viel Speicher benötigt. Bei rundenbasierten Spielen kann es einen einzelnen Zweig oder Pfad geben, der unter bestimmten Bedingungen zu einer Niederlage gegen den Gegner führt. Infolgedessen ist es etwas weniger zuverlässig. Nach vielen Iterationen braucht die Monte-Carlo-Baumsuche lange, um den effektivsten Pfad zu bestimmen.
Wie unterscheidet sich AlphaZero von AlphaGo Zero?
Frühere Versionen von AlphaGo enthielten eine kleine Anzahl von handgearbeiteten Funktionen, aber AlphaGo Zero verwendet nur die schwarzen und weißen Steine vom Go-Brett als Eingabe. Frühere Versionen von AlphaGo stützten sich auf ein Richtliniennetzwerk, um den nächsten Zug auszuwählen, und auf ein Wertenetzwerk, um den Gewinner des Spiels aus jeder Position zu schätzen. Diese werden in AlphaGo Zero zusammengeführt, was ein effizienteres Training und eine effizientere Bewertung ermöglicht. Alle diese Unterschiede tragen zur verbesserten Leistung und Verallgemeinerung des Systems bei. Die algorithmische Anpassung hingegen macht das System deutlich leistungsfähiger und effizienter.