
مقدمة عملية للتحقق من صحة النموذج وتنظيمه في التعلم العميق باستخدام TensorFlow
نشرت: 2020-10-28جدول المحتويات
مقدمة
أحدثت ممارسة الآلات لاستيعاب المعلومات عبر نموذج خوارزميات التعلم الخاضعة للإشراف ثورة في العديد من المهام مثل إنشاء التسلسل ومعالجة اللغة الطبيعية وحتى رؤية الكمبيوتر. يعتمد هذا النهج على استخدام مجموعة بيانات تحتوي على مجموعة من ميزات الإدخال ومجموعة مقابلة من الملصقات. ثم تستخدم الآلة هذه المعلومات الموجودة في شكل ميزات وتسميات لمعرفة توزيع وأنماط البيانات لعمل تنبؤات إحصائية حول المدخلات غير المرئية.
تتمثل الخطوة الأساسية في تصميم نماذج التعلم العميق في تقييم أداء النموذج ، خاصةً في نقاط البيانات الجديدة وغير المرئية. الهدف الرئيسي هو تطوير نماذج تعمم بما يتجاوز البيانات التي تم تدريبهم عليها. نريد نماذج يمكنها تقديم تنبؤات جيدة وموثوقة في العالم الحقيقي. أحد المفاهيم المهمة التي تساعدنا في ذلك هو التحقق من صحة النموذج وتنظيمه الذي سنغطيه اليوم.
التحقق من صحة النموذج
يتلخص بناء نموذج التعلم الآلي دائمًا في تقسيم البيانات المتاحة إلى ثلاث مجموعات: التدريب والتحقق من الصحة ومجموعة الاختبار. يتم استخدام بيانات التدريب من قبل النموذج لمعرفة المراوغات وخصائص التوزيع.
النقطة المحورية التي يجب معرفتها هنا هي أن الأداء المرضي للنموذج في مجموعة التدريب لا يعني أن النموذج سيعمم أيضًا على البيانات الجديدة ذات الأداء المماثل ، وذلك لأن النموذج أصبح متحيزًا لمجموعة التدريب. لذلك يتم استخدام مفهوم التحقق من الصحة ومجموعة الاختبار للإبلاغ عن مدى نجاح النموذج في التعميم على نقاط البيانات الجديدة.
يتمثل الإجراء القياسي في استخدام بيانات التدريب لتلائم النموذج ، وتقييم أداء النموذج باستخدام بيانات التحقق ، وفي النهاية يتم استخدام بيانات الاختبار لمعرفة مدى جودة أداء النموذج في الأمثلة الجديدة تمامًا.
تُستخدم مجموعة التحقق من الصحة لضبط المعلمات الفائقة (عدد الطبقات المخفية ، ومعدل التعلم ، ومعدل التسرب ، وما إلى ذلك) بحيث يمكن للنموذج التعميم جيدًا. اللغز الشائع الذي يواجهه المبتدئون في التعلم الآلي هو فهم الحاجة إلى مجموعات منفصلة للتحقق من الصحة والاختبار.

يمكن فهم الحاجة إلى مجموعتين متميزتين من خلال الحدس التالي: لكل شبكة عصبية عميقة تحتاج إلى التصميم ، توجد أعداد متعددة من المعلمات الفائقة التي تحتاج إلى تعديل للحصول على أداء مرضٍ.
يمكن تدريب نماذج متعددة باستخدام أي من المعلمات الفائقة ومن ثم يمكن تحديد النموذج الذي يحتوي على أفضل مقياس أداء بناءً على أداء هذا النموذج في مجموعة التحقق من الصحة. الآن ، في كل مرة يتم فيها تعديل المعلمات الفائقة للحصول على أداء أفضل في مجموعة التحقق من الصحة ، يتم تسريب / إدخال بعض المعلومات في النموذج ، وبالتالي ، قد تنحاز الأوزان النهائية للشبكة العصبية نحو مجموعة التحقق من الصحة.
بعد كل تعديل للمعلمة الفائقة ، يستمر نموذجنا في الأداء الجيد في مجموعة التحقق من الصحة لأن هذا هو ما قمنا بتحسينه من أجله. هذا هو السبب في أن اختبار التحقق لا يمكن أن يشير بدقة إلى قدرة التعميم للنموذج. للتغلب على هذا العيب ، يتم تشغيل مجموعة الاختبار.
يتم تقديم التمثيل الأكثر دقة لقدرة التعميم للنموذج من خلال الأداء في مجموعة الاختبار لأننا لم نحسن النموذج للحصول على أداء أفضل في هذه المجموعة ، وبالتالي ، سيشير هذا إلى التقدير الأكثر واقعية لقدرة النموذج.
يجب أن تقرأ: أهم تقنيات التعلم العميق التي يجب أن تعرفها
تنفيذ استراتيجيات التحقق باستخدام TensorFlow 2.0
يوفر TensorFlow 2.0 حلاً سهلًا للغاية لتتبع أداء نموذجنا في اختبار تحقق منفصل. يمكننا تمرير وسيطة الكلمة الأساسية validation_split في طريقة model.fit () .
تأخذ الكلمة الأساسية validation_split الإدخال كرقم عائم بين 0 و 1 والذي يمثل جزء بيانات التدريب الذي سيتم استخدامه كبيانات التحقق من الصحة. لذا ، فإن تمرير قيمة 0.1 في الكلمة الأساسية يعني حجز 10٪ من بيانات التدريب للتحقق من صحتها.
يمكن إثبات التنفيذ العملي لتقسيم التحقق بسهولة باستخدام مجموعة بيانات السكري من sklearn. تحتوي مجموعة البيانات على 442 حالة مع 10 متغيرات أساسية (العمر والجنس ومؤشر كتلة الجسم وما إلى ذلك) كميزات تدريب وقياس تطور المرض بعد عام واحد كتسمية لها.
نقوم باستيراد مجموعة البيانات باستخدام TensorFlow و sklearn:

تتمثل الخطوة الأساسية بعد المعالجة المسبقة للبيانات في بناء شبكة عصبية تلقائية متتابعة ذات طبقات كثيفة:

هنا ، لدينا شبكة عصبية بها ست طبقات مخفية مع تنشيط relu وطبقة إخراج واحدة مع تنشيط خطي .

نقوم بعد ذلك بتجميع النموذج باستخدام مُحسِّن آدم ونعني دالة فقدان الخطأ التربيعي .

ثم يتم استخدام طريقة model.fit () لتدريب النموذج لمدة 100 عصر مع انقسام_صحة تحقق بنسبة 15٪.

قد نرسم أيضًا فقدان النموذج كما هو ملاحظ لكل من بيانات التدريب وبيانات التحقق من الصحة:
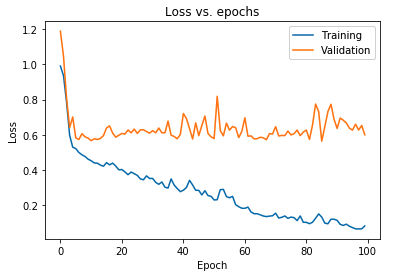
توضح الحبكة المعروضة أعلاه أن فقدان التحقق من الصحة يرتفع باستمرار بعد 10 فترات بينما يستمر فقدان التدريب في الانخفاض. هذا الاتجاه هو مثال كتابي لمشكلة كبيرة بشكل لا يصدق في التعلم الآلي تسمى overfitting .
تم إجراء الكثير من الأبحاث الأساسية للتغلب على هذه المشكلة وتسمى هذه الحلول مجتمعة تقنيات التنظيم . سيغطي القسم التالي جانب التنظيم وإجراءات تنظيم أي نموذج تعلم عميق.
تنظيم نموذجنا
في القسم السابق ، لاحظنا اتجاهًا عكسيًا في مخططات الخسارة الخاصة بمجموعات التدريب والتحقق من الصحة حيث يبدو أن مخطط دالة التكلفة للمجموعة الأخيرة في ارتفاع وتستمر المجموعة الأولى في التناقص ، وبالتالي خلق فجوة ( فجوة التعميم ). تعرف على المزيد حول التنظيم في التعلم الآلي.
ترمز حقيقة وجود فجوة كهذه بين قطعتي الخسارة إلى أن النموذج لا يمكن تعميمه جيدًا على مجموعة التحقق من الصحة ( البيانات غير المرئية) ، وبالتالي فإن قيمة التكلفة / الخسارة المتكبدة على مجموعة البيانات هذه ستكون عالية حتمًا.
تحدث هذه الخصوصية لأن أوزان وتحيزات النموذج المدرب تتكيف بشكل مشترك لتعلم توزيع بيانات التدريب جيدًا ، لدرجة أنها تفشل في التنبؤ بتسميات الميزات الجديدة وغير المرئية مما يؤدي إلى زيادة فقدان التحقق من الصحة.
الأساس المنطقي هو أن تكوين نموذج معقد سينتج مثل هذه الحالات الشاذة لأن معلمات النماذج تنمو لتصبح قوية للغاية لبيانات التدريب. ومن ثم ، فإن تبسيط أو تقليل سعة / تعقيد النماذج سيقلل من تأثير فرط التجهيز. تتمثل إحدى طرق تحقيق ذلك في استخدام المتسربين في نموذج التعلم العميق الخاص بنا والذي سنقوم بتغطيته في القسم التالي.
فهم وتنفيذ المتسربين في TensorFlow
التصور الرئيسي وراء استخدام التسرب هو إسقاط الوحدات المخفية والمرئية بشكل عشوائي من أجل الحصول على نموذج أقل تعقيدًا يقيد معلمات النموذج من الزيادة وبالتالي ، مما يجعل النموذج أكثر متانة للأداء على مجموعة البيانات المعممة.
هذه الممارسة المقبولة مؤخرًا هي نهج قوي يستخدمه ممارسو التعلم الآلي لإحداث تأثير تنظيمي في أي نموذج تعلم عميق. يمكن تنفيذ عمليات التسرب بسهولة باستخدام Keras API عبر TensorFlow عن طريق استيراد طبقة التسرب وتمرير وسيطة المعدل فيها لتحديد جزء الوحدات التي يجب إسقاطها.
عادة ما يتم تكديس طبقات التسرب هذه مباشرة بعد كل طبقة كثيفة لإنتاج مد متناوب من بنية طبقة كثيفة المتسربة .
يمكننا تعديل شبكتنا العصبية المحددة مسبقًا لتتضمن ست طبقات منسدلة ، واحدة لكل طبقة مخفية:


هنا ، تم ضبط معدل التسرب على 0.2 مما يعني أنه سيتم إسقاط 20٪ من العقد أثناء تدريب النموذج. نقوم بتجميع النموذج وتدريبه باستخدام نفس المُحسِّن ووظيفة الخسارة والمقاييس وعدد الفترات لإجراء مقارنة عادلة.
يمكن تفسير التأثير الأساسي لتنظيم النموذج باستخدام المتسربين من خلال رسم منحنى الخسارة للنموذج الذي تم الحصول عليه في مجموعات التدريب والتحقق:
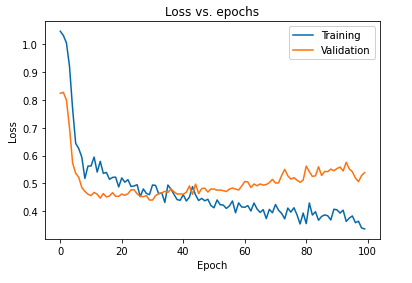
يتضح من المؤامرة أعلاه أن فجوة التعميم التي تم الحصول عليها بعد تنظيم النموذج أقل بكثير مما يجعل النموذج أقل عرضة لتجهيز بيانات التدريب.
اقرأ أيضًا: أفكار مشروع التعلم العميق
خاتمة
يعد جانب التحقق من صحة النموذج وتنظيمه جزءًا أساسيًا من تصميم سير العمل لبناء أي حل للتعلم الآلي. يتم إجراء الكثير من الأبحاث من أجل الارتجال في التعلم الخاضع للإشراف ويقدم هذا البرنامج التعليمي العملي نظرة ثاقبة لبعض الممارسات والتقنيات الأكثر قبولًا أثناء تجميع أي خوارزمية تعليمية.
إذا كنت مهتمًا بمعرفة المزيد حول تقنيات التعلم العميق ، والتعلم الآلي ، فراجع IIIT-B & upGrad's PG Certification في التعلم الآلي والتعلم العميق المصمم للمهنيين العاملين ويقدم أكثر من 240 ساعة من التدريب الصارم ، وأكثر من 5 دراسات حالة والتعيينات ، وحالة خريجي IIIT-B والمساعدة في العمل مع الشركات الكبرى.