
تحليل البيانات باستخدام بايثون [كل ما تريد معرفته]
نشرت: 2020-09-02بالنسبة لأي شخص يريد البدء في تحليل البيانات ، فإن اللغة الأولى التي تتبادر إلى الذهن هي R أو Python. والسبب في ميل المطورين الآن نحو Python يرجع إلى قدرتها على التكيف على نطاق واسع في مجال تطوير البرمجيات العام. وبالتالي ، يعد تحليل البيانات باستخدام Python أحد أكثر المصطلحات شهرة بالنسبة لشخص ما يبدأ رحلتهم في علوم البيانات.
جدول المحتويات
لماذا تحليل البيانات؟
الآن أولاً ، لماذا تحليل البيانات؟ حسنًا ، إنها الخطوة الأولى لمعرفة نوع البيانات التي تعمل بها. إنها الخطوة التي تجد فيها أنماطًا قيّمة في البيانات ، والتي قد لا تراها بخلاف ذلك. بشكل عام ، يوفر فهمًا بديهيًا لمجموعة البيانات الموجودة في متناول اليد.
هنا نحتاج إلى رسم خط بين تحليل البيانات والمعالجة المسبقة للبيانات. تتعامل المعالجة المسبقة للبيانات مع نمذجة مجموعة البيانات الخاصة بك للتأكد من أنها جاهزة للتدريب. تحليل البيانات لفهم مجموعة البيانات ، وهي خطوة مسبقة للمعالجة المسبقة للبيانات. في تحليل البيانات ، نحاول نمذجة البيانات لعرضها بشكل أفضل ، وبالتالي ، التعرف على رؤى حول مجموعة البيانات الموجودة في متناول اليد.
لماذا بايثون؟
السؤال الثاني هو لماذا بايثون؟ حسنًا ، لقد ذكرنا بالفعل أن بايثون لغة متكيفة على نطاق واسع. نعم ، إنه ليس الخيار الوحيد عندما يتعلق الأمر بتحليل البيانات ، ولكنه خيار جيد جدًا. سبب آخر هو أنه يتم استخدامه أكثر! Python سهلة ولديها مجتمع كبير من المطورين لمساعدتك فيما يتعلق بتحليل البيانات باستخدام Python . علاوة على ذلك ، يعد تحليل البيانات باستخدام Python ممتعًا للغاية نظرًا للعدد الكبير من المكتبات الإبداعية التي توفرها لتحليل البيانات والتصور.
في Python ، المكتبة الأساسية لتحليل البيانات هي Pandas. إنها مكتبة عالية المستوى ، مبنية على مكتبة NumPy ، وهي مخصصة للحوسبة العلمية والتحليل العددي. تعمل Pandas على تسهيل العمل مع البيانات من خلال تقديم هيكل البيانات الخاص بها ، والمعروف باسم DataFrame. يساعد DataFrame في قراءة مجموعة البيانات الخاصة بك وتخزينها. يوفر الوظائف الأساسية لقراءة مجموعة البيانات وكتابتها ، فضلاً عن عرض البيانات الوصفية ووظائف الاستعلام لاستخراج كل فكرة من مجموعة البيانات.
من المهم ملاحظة أن تصور البيانات هو جزء كبير من التحليل الشامل للبيانات. لأنه لا يساعد فقط في فهم البيانات بشكل أفضل ولكن أيضًا لأولئك الذين تقدم لهم الأفكار. سنناقش المكتبتين الأكثر استخدامًا للتصور: Matplotlib و Seaborn. Matplotlib هي المكتبة الأساسية لأي تصورات في Python. صُنع Seaborn أيضًا أعلى Matplotlib ، والذي يقدم بعضًا من أكثر وظائف تصور البيانات إبداعًا.
إعداد البيئة
الخطوة الأولى هي إعداد بيئتك. أثناء إجراء تحليل البيانات باستخدام Python ، من المهم أن يكون لديك بيئة مناسبة لحفظ كل عملك. لن يكون تحليل البيانات باستخدام Python مجرد نص برمجي ، ولكنه سيكون بمثابة تفاعل بينك وبين مجموعة البيانات ، ولهذا ، فإنك تحتاج إلى مكان مناسب للعمل.
في لغة بيثون ، يتم توفير هذه الخدمة من خلال توزيع Anaconda. مكان العمل الرائد في Anaconda هو دفتر Jupyter. إذن ، لماذا كوكب المشتري الآن؟ حسنًا ، يتيح لك الحصول على التصورات مباشرة داخل دفتر ملاحظاتك. كما أن لديها بعض الوظائف السحرية التي تتيح لك رؤية الإخراج مباشرة دون تحديد المكان الذي تريده صراحةً.
تأتي المكتبات و Pandas و Matplotlib مثبتة مسبقًا ، وبالتالي لا يوجد إعداد إضافي مطلوب لاستخدامها.
فيما يلي ملخص لكيفية الالتفاف حول إجراء تحليل البيانات باستخدام Python :
- تحميل مجموعة البيانات
- عرض البيانات الوصفية لمجموعة البيانات باستخدام Pandas
- تصورات البيانات باستخدام Matplotlib
- جمع الرؤى حول البيانات
استيراد المكتبات الضرورية
قبل أن نبدأ في البحث في الكود لمعرفة الخطوات ، ما عليك سوى استيراد المكتبات الضرورية ذات العلامات الزائفة ، كما هو الحال مع الاسم الذي نطلق عليه اسم البرنامج بأكمله.
استيراد numpy كـ np
استيراد الباندا كما pd
# لتصورات البيانات
استيراد matplotlib.pyplot كـ PLT
استيراد seaborn as sns
الآن سننظر في كل خطوة ونناقش الوظائف المتاحة وكيفية استخدامها.
أولاً ، قراءة مجموعات البيانات. توفر Pandas بعض الوظائف الأساسية لتحميل مجموعة البيانات في هيكل بياناتها الأساسي: DataFrame. يمكننا استخدامه على النحو التالي.
data_df = pd.read_csv ("heart.csv")
سيكون ناتج أي دالة قراءة هو DataFrame. بصرف النظر عن قارئات CSV ، توفر حيوانات الباندا القراء لجميع أنواع البيانات تقريبًا. من HTML إلى JSON و Excel.
بصرف النظر عن هذا ، إذا لم يكن لديك أي بيانات على هذا النحو وترغب في إنشاء مجموعة البيانات الخاصة بك ، فيمكنك بسهولة استخدام وظائف سلسلة Pandas وكائن DataFrame.
لذلك ، بمجرد حصولك على البيانات ، دعنا ننتقل إلى عرض ماهية البيانات. للحصول على العرض الأول للبيانات ، يمكنك استخدام وظائف مثل df.info أو df.describe لمعرفة بنية مجموعة البيانات الخاصة بك.
data_df.info ()
data_df.describe ()
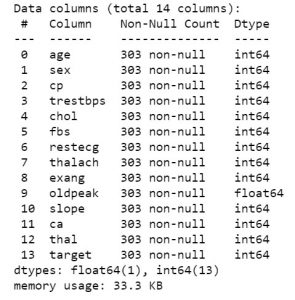
بمجرد معرفة الميزات التي تحتوي عليها مجموعة البيانات الخاصة بك ، قد ترغب في إلقاء نظرة على قيمها. يمكنك استخدام الدالة df.head () للحصول على أول 5 عينات.
data_df.head ()
#أو
data_df.head (3)
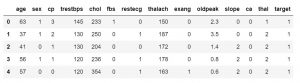
يمكنك أيضًا تحديد عدد العينات لتجاوز القيمة الافتراضية 5. يمكنك أيضًا استخدام الوظيفة df.tail () للحصول على آخر 5 قيم لمجموعة البيانات.
data_df.tail ()
هذا فقط للحصول على نظرة عامة عالية المستوى على الشكل الذي قد تبدو عليه بياناتك. بمجرد أن تصبح جاهزًا ، يمكنك بدء مهام تصورات البيانات الرئيسية باستخدام Matplotlib. أدخل الكود التالي لجعل الرسم تفاعليًا وعرضه في دفتر ملاحظاتك نفسه.
٪ matplotlib مضمنة
سنرى وظائف أفضل 5 تصورات في matplotlib. قبل الخوض فيه ، يجب أن نعرف بعض الوظائف الأخرى التي تتحكم في مؤامراتنا. وظائف مثل:
- الملصقات: xlabel () ، ylabel (). إنها لتسميات المحور السيني والمحور الصادي.
- وسيلة إيضاح: يتم استخدامها لعمل أسطورة الحبكة.
- العنوان: لتعيين عنوان لقطعة الأرض الخاصة بك
- وأخيرًا ، اعرض الوظيفة لعرض المؤامرة.
الخروج: راتب محلل البيانات في الهند
التصورات
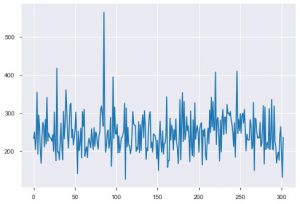
دعونا نرى التصورات الآن. سنبدأ بالحبكة الأساسية. يتم استخدام plt.plot () لإنشاء مخطط خط بسيط لبياناتك. تتطلب الوظيفة معلمتين في الإكراه ، وهما بيانات المحور السيني وبيانات المحور الصادي. يمكنك اختياريًا تقديم الأنماط والاسم واللون للمخطط. هنا كيف يبدو في الكود.
plt.plot (data_df ['chol'])
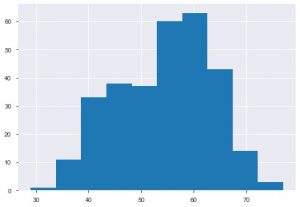
الحبكة الثانية هي الرسم البياني. يساعدك الرسم البياني في عرض التكرار أو التوزيع لميزة معينة. يساعدك في عرض كيفية ارتباط الكميات ببعضها البعض. Plt.hist () هي الوظيفة الأساسية لإنشاء رسم بياني لبياناتك. يمكنك ذكر معلمة الصناديق للتحكم في الرقم على قطعة الأرض. ما عليك سوى تمرير بيانات محور واحد إذا كنت تريد تحليلًا أحادي المتغير.

plt.hist (data_df ['age'])
قطعة أرض أخرى قد تراها كثيرًا هي مخطط الشريط. يساعد في تحليل ومقارنة الميزات المختلفة. على عكس الرسوم البيانية ، تُستخدم مخططات الشريط للعمل مع البيانات الفئوية.
يمكنك تطبيق الرسم مباشرة على DataFrame ، أو يمكنك تحديد المعلمات داخل وظيفة plt.bar (). هنا كيف نستخدمها.
df = pd.DataFrame (np.random.rand (15، 5)، الأعمدة = ['t1'، 't2'، 't3'، 't4'، 't5'])
df.plot.bar ()
يمكنك أيضًا استخدام مخطط الشريط أفقيًا باستخدام وظيفة barh ().
رسم بياني آخر ثاقب هو boxplot. يساعد في فهم توزيع القيم داخل كل ميزة. يمكنك استخدام وظيفة plt.boxplot () لتحديد البيانات التي تريد إنشاء مربع مخطط لها. تكون الحبكة مفيدة بشكل خاص عندما تحتاج إلى عرض التشتت في مجموعة البيانات أو الانحراف بسرعة. هنا كيف يمكنك استخدامه.
plt.boxplot (data_df ['chol'])
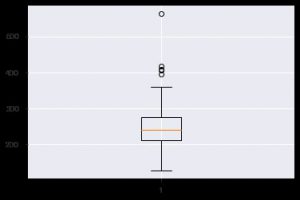
عندما تعمل مع البيانات الإحصائية ، سترى بالتأكيد مخطط مبعثر. يساعد مخطط التبعثر في مراقبة العلاقة بين ميزتين. يتطلب الرسم قيمًا رقمية لكل من بيانات المحور السيني وكذلك المحور الصادي. يمكنك ببساطة توفير هاتين القيمتين في دالة plt.scatter () أو يمكنك تطبيقها مباشرة على DataFrame عن طريق تحديد أسماء الأعمدة في السمتين x و y. إليك كيف يمكنك استخدام ذلك:
plt.scatter (data_df ['age']، data_df ['chol'])
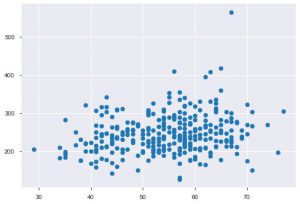
الآن هو الوقت المناسب لتعريفك بوظائف Seaborn. تعد مؤامرة التبعثر في seaborn أكثر سهولة من matplotlib لأنها توفر أيضًا بشكل افتراضي خط انحدار في المؤامرة ، لتصور المؤامرة بشكل أفضل. يمكنك استخدام الدالة sns.lmplot () لعمل تلك المؤامرة.
sns.lmplot ('Age'، 'chol'، data = data_df)
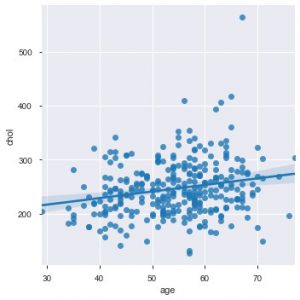
كما ترى في الرسم أعلاه ، يساعد خط الانحدار على فهم التوزيع بشكل أفضل.
تحسين آخر باستخدام البحر هو مخطط السرب. يتم استخدامه لرسم مخطط مبعثر قاطع. تتمثل إحدى مزايا مخطط السرب على مخطط الشريط المماثل في أنه يستخدم النقاط غير المتداخلة فقط. لذلك ، فهي حبكة أنظف وبالتالي تعطي رؤية أفضل.
sns.swarmplot (data_df ['age']، data_df ['chol'])
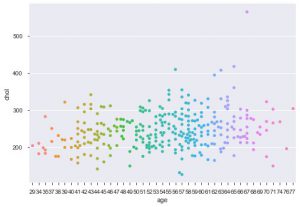
إذن ، هذه هي الأنواع المختلفة من قطع الأراضي في Matplotlib و Seaborn. هذا مجرد غيض من فيض ، وهناك المئات من الطرق المختلفة الأخرى لتخطيط بياناتك لاستخراج رؤى إبداعية عنها.
الآن بعد أن عرفت المؤامرات ، دعنا نرى كيفية إجراء تحليل فعلي للبيانات باستخدام بيثون . سنلقي نظرة على المزيد من المؤامرات ونرى ما يظهرونه لنا حول تحليل البيانات باستخدام بيثون .
لنبدأ.
بعد تحميل البيانات ، فإن أول شيء يفعله أي محلل بيانات الآن هو إنشاء ملف تعريف الباندا. الآن ، يمكن عرض هذا كاختصار أيضًا ، ولكن إذا كنت تريد رؤية جميع العلاقات والأعداد والمدرج التكراري للمتغيرات في مجموعة البيانات ، فيمكنك استخدام التنميط الباندا. من السهل جدًا إنشاء ذلك ، ما عليك سوى تنزيل وحدة تنميط الباندا واللكم في الكود التالي:
استيراد pandas_profiling
الملف الشخصي = pandas_profiling.ProfileReport (data_df)
الملف الشخصي
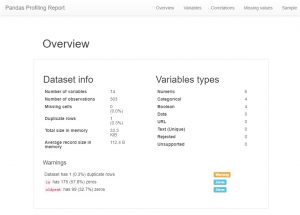
كما يمكنك أن ترى ، هناك قدر هائل من معلومات البيانات الوصفية وكذلك معلومات السمات الفردية. هذه يمكن أن تؤدي إلى بعض الفهم العظيم.
الشيء الثاني الذي يمكننا القيام به هو إنشاء خريطة حرارية. الآن ما تفعله خريطة التمثيل اللوني ، فهي تُظهر الارتباط بين كل ميزة والأخرى. وإذا وجدنا قيمة ذات ارتباط أعلى ، فهذا يعني أن السمتين تشبهان بعضهما البعض إلى حد كبير. لذلك ، يمكننا إسقاط إحدى الميزات ، ومع ذلك ، سيعمل النموذج بشكل جيد.
sns.heatmap (data_df.corr ()، annot = True ، cmap = 'Oranges')
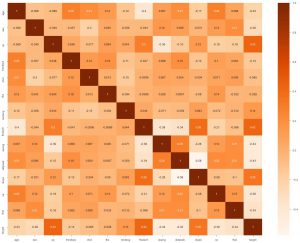
هنا لا يمكننا أن نرى أيًا منها وثيق الصلة لذا يمكننا إخبار مهندس النموذج أننا سنحتاج إلى جميع الميزات كمدخلات.
يمكننا أن نرى ما هو التوزيع العمري لأننا نتعامل مع مجموعة بيانات أمراض القلب ، دعونا نرى التوزيع ، حتى نتمكن من استخدام Distplot of seaborn.
sns.distplot (data_df ['age'] ، color = 'cyan')
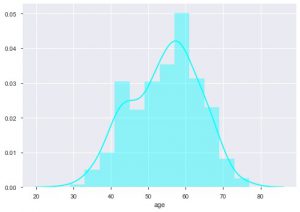
من المؤامرة ، يمكنك القول أن معظم الأشخاص الذين يعانون من أمراض القلب تتراوح أعمارهم بين 50 و 60 عامًا. وبنفس الطريقة ، يمكننا أيضًا مشاهدة بعض الميزات المهمة الأخرى مثل ضغط الدم أثناء الراحة ، والذي يشير إليه tresbps. يمكننا عمل مخطط مربع لرؤية التوزيع ، مقارنة بالقيمة المستهدفة ، أي 0 و 1.
sns.boxplot (data_df ['target'] ، data_df ['trestbps'] ، palette = 'twilight')
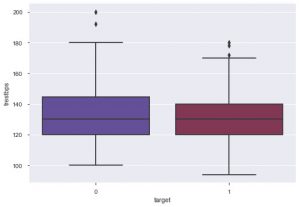
يمكننا أن نستنتج من المؤامرة أنه إذا كان الشخص يعاني من انخفاض معدل ضربات القلب ، فإن فرص إصابته بأمراض القلب تكون أقل من أولئك الذين لديهم قيمة أعلى لـ tres bps.
بنفس الطريقة ، يمكننا أيضًا رؤية العلاقة مع مستويات الكوليسترول. نحن نرى الأشخاص الذين لديهم مستويات أقل من الكوليسترول لديهم فرصة أقل للإصابة بأمراض القلب.
يمكنك توثيق كل هذه الأفكار وتقديمها لمهندس التعلم الآلي الذي يمكنه بعد ذلك استخدامها لإنشاء نموذج فعال.
خاتمة
إذن ، هذه هي الطريقة التي يمكنك بها تحليل البيانات باستخدام بايثون . هذه فقط الخطوة الأولى في رحلة علم البيانات. لمعرفة المزيد حول استخراج الرؤى الإبداعية من البيانات وعلوم البيانات الشاملة ، توجه إلى الدورات التدريبية التي تقدمها upGrad هنا . ستجد مجموعة من الدورات التدريبية المفيدة التي ستوجه تحليل البيانات بشكل فعال باستخدام بايثون.
تعلم دورات علوم البيانات من أفضل الجامعات في العالم. اربح برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.
كيف يمكنني البدء في تعلم بايثون لتحليل البيانات؟
إذا كنت في طريقك لتعلم بايثون لتحليل البيانات ، فأنت في المكان الصحيح. تحتاج إلى اتباع نهج تدريجي لجعل عملية التعلم أبسط لأي شيء. إليك كيف تبدو العملية:
1. كن واضحًا بشأن الغرض من تعلم Python وكيف ستتمكن من استخدامها في مجال عملك.
2- قم بتنزيل Python Terminal المطلوبة وقم بتثبيتها في نظامك.
3- ابدأ في تعلم أساسيات بايثون من خلال أخذ دورات مختلفة والتعرف على مكتبات بايثون المختلفة.
4- تعرف على التعبيرات النمطية المستخدمة في بايثون.
5. اعمل على اكتساب معرفة متعمقة بمكتبات Python المختلفة مثل Pandas و NumPy و Matplotlib و SciPy.
6. ابدأ في تعلم مفاهيم تحليل البيانات وكيف يمكنك دمج Python معها.
7. الآن ، تحتاج فقط إلى الاستمرار في ممارسة أدوات وتقنيات مختلفة للتحسن في Python لتحليل البيانات. من خلال اتباع هذا النهج التدريجي ، ستجد أنه من السهل جدًا تعلم Python وتحسينها للعمل مع تحليل البيانات.
كيف يتم استخدام بايثون لتحليل البيانات؟
من المعروف أن بايثون مورد مهم جدًا لتحليل البيانات. تساعد Python بطرق مختلفة في إجراء تحليل البيانات. ولكن قبل ذلك ، تحتاج إلى إعداد البيانات للتحليل ، وإجراء التحليل الإحصائي ، وإنشاء تصورات للبيانات التي يمكن أن توفر بعض الأفكار ، وتتنبأ بالاتجاهات المستقبلية بناءً على البيانات المتاحة ، وأكثر من ذلك بكثير.
تم العثور على Python كعنصر أساسي في تحليل البيانات لأنها تساعد في:
1. استيراد مجموعات البيانات
2- تنظيف وتجهيز البيانات لأداء التحليل
3. التلاعب في Pandas DataFrame
4. تلخيص مجموعات البيانات
5. تطوير نموذج التعلم الآلي لتحليل البيانات باستخدام بايثون
هل يمكنني تعلم بايثون في شهر؟
نعم ، يمكنك بالتأكيد تحقيق ذلك إذا كنت بارعًا في أي لغة برمجة أخرى مثل Java و C و C ++ وما إلى ذلك. إذا كانت قاعدتك واضحة ، فستجد أنه من السهل جدًا تعلم Python حتى في شهر واحد. بخلاف ذلك ، إذا بذلت الجهد واتبعت نهجًا تدريجيًا بطريقة منضبطة ، يمكنك تعلم Python في غضون شهر حتى عندما لا تكون لديك معرفة مسبقة بلغات البرمجة الأخرى. كل ما تحتاجه هو تحديد جدول وأن تكون مكرسًا لتعلم بايثون في شهر واحد.