
انطلق وتحدي الذكاء العام الاصطناعي
نشرت: 2018-02-15تهدف هذه المقالة إلى استكشاف العلاقة بين لعبة "Go" والذكاء الاصطناعي. الهدف هو الإجابة على الأسئلة - ما الذي يجعل لعبة Go مميزة؟ لماذا كان إتقان لعبة Go صعبًا على الكمبيوتر؟ لماذا تمكن برنامج كمبيوتر من التغلب على معلم الشطرنج في عام 1997؟ لماذا استغرق الأمر ما يقرب من عقدين من الزمن لكسر Go؟
"يجب على السادة ألا يضيعوا وقتهم في ألعاب تافهة - يجب أن يدرسوا Go"
- كونفوشيوس
في الواقع ، اعتقد خبراء الذكاء الاصطناعي أن أجهزة الكمبيوتر ستكون قادرة فقط على التغلب على بطل العالم في Go بحلول عام 2027. وبفضل شركة DeepMind ، وهي شركة ذكاء اصطناعي تحت مظلة Google ، تم تحقيق هذه المهمة الهائلة قبل عقد من الزمن. سيتحدث هذا المقال عن التقنيات التي تستخدمها DeepMind للتغلب على بطل العالم Go. أخيرًا ، يناقش هذا المنشور كيف يمكن استخدام هذه التقنية لحل بعض مشاكل العالم الواقعي المعقدة.
جدول المحتويات
اذهب - ما هذا؟
Go هي لعبة لوحة إستراتيجية صينية عمرها 3000 عام ، وقد احتفظت بشعبيتها عبر العصور. يلعبها عشرات الملايين من الأشخاص في جميع أنحاء العالم ، Go هي لعبة لوحية ثنائية اللاعبين بقواعد بسيطة واستراتيجية بديهية. يتم استخدام أحجام مختلفة للوحة للعب هذه اللعبة ؛ يستخدم المحترفون لوحة 19 × 19.

تبدأ اللعبة بلوحة فارغة. يتناوب كل لاعب على وضع الحجارة السوداء والبيضاء (الأسود أولًا) على السبورة ، عند تقاطع الخطوط (على عكس الشطرنج ، حيث تضع القطع في المربعات). يمكن للاعب التقاط أحجار الخصم من خلال إحاطة اللاعب من جميع الجهات. لكل حجر تم التقاطه ، يتم منح بعض النقاط للاعب. الهدف من اللعبة هو احتلال أقصى مساحة على اللوحة جنبًا إلى جنب مع الاستيلاء على أحجار خصومك.
Go تدور حول الخلق ، على عكس الشطرنج ، الذي يدور حول التدمير. يتطلب Go الحرية والإبداع والحدس والتوازن والاستراتيجية والعمق الفكري لإتقان اللعبة. تتضمن لعبة Go كلا الجانبين من الدماغ. في الواقع ، كشفت فحوصات الدماغ للاعبين Go أن Go يساعد في نمو الدماغ من خلال تحسين الروابط بين نصفي الكرة المخية.
الشبكات العصبية للدمى: دليل شامل
انطلق وتحدي الذكاء الاصطناعي (AI)
تمكنت أجهزة الكمبيوتر من إتقان Tic-Tac-Toe في عام 1952 . كان ديب بلو قادراً على هزيمة قائد الشطرنج الكبير غاري كاسباروف في عام 1997 . تمكن برنامج الكمبيوتر من الفوز على بطل العالم في لعبة Jeopardy (لعبة أمريكية شهيرة) في عام 2001 . تمكن AlphaGo من DeepMind من هزيمة بطل العالم Go في عام 2016 . لماذا يعتبر إتقان لعبة Go تحديًا لبرنامج كمبيوتر؟
يتم لعب الشطرنج على لوحة 8 × 8 بينما يستخدم Go لوحة بحجم 19 × 19. في بداية لعبة الشطرنج ، يحصل اللاعب على 20 حركة ممكنة. في فتح Go ، يمكن للاعب أن يحصل على 361 نقلة ممكنة. عدد مواضع لوحة Go الممكنة يساوي 10 إلى القوة 170 ؛ أكثر من عدد الذرات في كوننا! العدد المحتمل لمواضع اللوحة يجعل Googol مرات (10 إلى القوة 100) أكثر تعقيدًا من الشطرنج.
في الشطرنج ، لكل خطوة ، يواجه اللاعب خيارًا من 35 حركة. في المتوسط ، سيكون لدى لاعب Go 250 حركة ممكنة في كل خطوة. في لعبة الشطرنج ، في أي مركز معين ، من السهل نسبيًا أن يقوم الكمبيوتر بالبحث عن القوة الغاشمة واختيار أفضل حركة ممكنة تزيد من فرص الفوز. لا يمكن البحث عن القوة الغاشمة في حالة Go ، حيث أن العدد المحتمل من التحركات القانونية المسموح بها لكل خطوة هو هائل.
لكي يتقن الكمبيوتر الشطرنج ، يصبح الأمر أسهل مع تقدم اللعبة لأن القطع تتم إزالتها من اللوحة. في Go ، يصبح الأمر أكثر صعوبة بالنسبة لبرنامج الكمبيوتر حيث تتم إضافة الأحجار إلى اللوحة مع تقدم اللعبة. عادةً ما تدوم لعبة Go 3 مرات أطول من لعبة الشطرنج.
نظرًا لكل هذه الأسباب ، لم يتمكن برنامج Computer Go المتميز من اللحاق بالبطل العالمي Go إلا في عام 2016 ، بعد انفجار هائل في تقنيات التعلم الآلي الجديدة. تمكن العلماء العاملون في DeepMind من ابتكار برنامج كمبيوتر يسمى AlphaGo والذي هزم بطل العالم Lee Seedol . لم يكن إنجاز المهمة سهلاً. توصل الباحثون في DeepMind إلى العديد من الابتكارات الجديدة في عملية إنشاء AlphaGo.
"قواعد Go أنيقة جدًا وعضوية ومنطقية تمامًا لدرجة أنه إذا كانت أشكال الحياة الذكية موجودة في مكان آخر من الكون ، فمن شبه المؤكد أنها تلعب دور Go."
- إدوارد لاسكار
الشبكات العصبية: تطبيقات في العالم الحقيقي
كيف يعمل AlphaGo
AlphaGo هي خوارزمية للأغراض العامة ، مما يعني أنه يمكن استخدامها لحل المهام الأخرى أيضًا. على سبيل المثال ، تم تصميم Deep Blue من IBM خصيصًا للعب الشطرنج. تمت برمجة قواعد الشطرنج جنبًا إلى جنب مع المعرفة المتراكمة من قرون من لعب اللعبة في دماغ البرنامج. لا يمكن استخدام Deep Blue حتى في لعب ألعاب تافهة مثل Tic-Tac-Toe. يمكنه أن يفعل شيئًا واحدًا محددًا فقط ، وهو جيد جدًا ، مثل لعب الشطرنج. يمكن أن يتعلم AlphaGo لعب ألعاب أخرى بالإضافة إلى Go. تشكل خوارزميات الأغراض العامة هذه مجالًا جديدًا للبحث يسمى الذكاء العام الاصطناعي.
يستخدم AlphaGo أحدث الأساليب - الشبكات العصبية العميقة (DNN) ، وتعليم التعزيز (RL) ، و Monte Carlo Tree Search (MCTS) ، و Deep Q Networks (DQN) (تقنية جديدة قدمتها ورائحتها DeepMind والتي تجمع بين العصبية. الشبكات مع التعلم المعزز) ، على سبيل المثال لا الحصر. ثم تجمع بين كل هذه الأساليب بشكل مبتكر لتحقيق إتقان فوق مستوى البشر في لعبة Go.
دعنا أولاً نلقي نظرة على كل قطعة فردية من هذا اللغز قبل الخوض في كيفية ربط هذه القطع معًا لتحقيق المهمة المطروحة.
الشبكات العصبية العميقة
DNNs هي تقنية لأداء التعلم الآلي ، مستوحاة بشكل فضفاض من عمل الدماغ البشري. تتكون بنية DNN من طبقات من الخلايا العصبية. يمكن لـ DNN التعرف على الأنماط في البيانات دون أن تتم برمجتها بشكل صريح.
يقوم بتعيين المدخلات إلى المخرجات دون أن يقوم أي شخص ببرمجتها على وجه التحديد لنفسها. على سبيل المثال ، دعنا نفترض أننا قمنا بتغذية الشبكة بالكثير من صور القطط والكلاب. في الوقت نفسه ، نقوم أيضًا بتدريب النظام من خلال إخباره (في شكل ملصقات) إذا كانت صورة معينة لقط أو كلب (وهذا ما يسمى التعلم الخاضع للإشراف). سوف يتعلم DNN التعرف على النمط من الصور للتمييز بنجاح بين القط والكلب. الهدف الرئيسي من التدريب هو أنه عندما يرى DNN صورة جديدة لكلب أو قطة ، يجب أن يكون قادرًا على تصنيفها بشكل صحيح ، أي توقع ما إذا كانت قطة أو كلبًا.
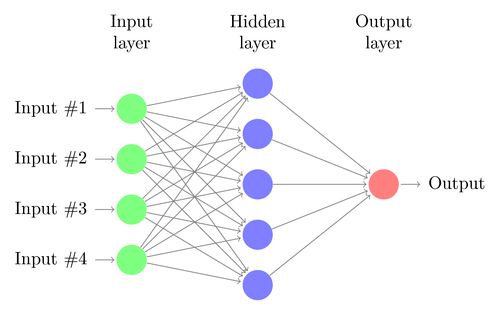
دعونا نفهم بنية DNN بسيط. يتوافق عدد الخلايا العصبية في طبقة الإدخال مع حجم الإدخال. لنفترض أن صور القطط والكلاب لدينا هي صورة مقاس 28 × 28. سيتكون كل صف وعمود من 28 بكسل لكل منهما ، مما يجعله إجمالي 784 بكسل لكل صورة. في مثل هذه الحالة ، ستتألف طبقة الإدخال من 784 خلية عصبية ، واحدة لكل بكسل. سيعتمد عدد الخلايا العصبية في طبقة الإخراج على عدد الفئات التي يجب تصنيف المخرجات إليها. في هذه الحالة ، ستتألف طبقة المخرجات من خليتين عصبيتين - أحدهما يقابل كلمة "قطة" والأخرى لكلمة "كلب".
ترقب الشيء الكبير التالي: التعلم الآلي
سيكون هناك العديد من طبقات الخلايا العصبية بين طبقات الإدخال والإخراج (وهو أصل استخدام مصطلح "عميق" في "الشبكة العصبية العميقة"). هذه تسمى "الطبقات المخفية". عدد الطبقات المخفية وعدد الخلايا العصبية في كل طبقة غير ثابت. في الواقع ، تغيير هذه القيم هو بالضبط ما يؤدي إلى تحسين الأداء. تسمى هذه القيم المعلمات المفرطة ، ويجب ضبطها وفقًا للمشكلة المطروحة. تتضمن التجارب المحيطة بالشبكات العصبية إلى حد كبير اكتشاف العدد الأمثل للمعلمات الفائقة.
ستتألف مرحلة تدريب DNNs من تمريرة إلى الأمام وتمريرة للخلف. أولاً ، يتم تهيئة جميع الاتصالات بين الخلايا العصبية بأوزان عشوائية. أثناء المرور الأمامي ، يتم تغذية الشبكة بصورة واحدة. يتم دمج المدخلات (بيانات البكسل من الصورة) مع معلمات الشبكة (الأوزان والتحيزات ووظائف التنشيط) وإعادة توجيهها من خلال الطبقات المخفية ، وصولاً إلى الإخراج ، مما يؤدي إلى إرجاع احتمالية لصورة تنتمي إلى كل منها من الطبقات.
بعد ذلك ، تتم مقارنة هذا الاحتمال بتسمية الفئة الفعلية ، ويتم حساب "خطأ". في هذه المرحلة ، يتم تنفيذ التمرير الخلفي - يتم تمرير معلومات الخطأ هذه مرة أخرى عبر الشبكة من خلال تقنية تسمى "الانتشار الخلفي". خلال المراحل الأولية من التدريب ، سيكون هذا الخطأ عالياً ، وستعمل آلية التدريب الجيدة على تقليل هذا الخطأ تدريجياً.
يتم تدريب DNN بهذه الطريقة بتمريرة للأمام وللخلف حتى تتوقف الأوزان عن التغير (يُعرف هذا بالتقارب). بعد ذلك ، ستكون DNNs قادرة على التنبؤ بالصور وتصنيفها بدرجة عالية من الدقة ، أي ما إذا كانت الصورة بها قطة أم كلب.

لقد أعطانا البحث العديد من بنى الشبكات العصبية العميقة المختلفة. بالنسبة لمشاكل الرؤية الحاسوبية (أي المشكلات التي تتضمن الصور) ، أعطت شبكات الالتفاف العصبية (CNNs) نتائج جيدة تقليديًا. بالنسبة للمشكلات التي تتضمن تسلسلاً - التعرف على الكلام أو ترجمة اللغة - توفر الشبكات العصبية المتكررة (RNN) نتائج ممتازة.
دليل المبتدئين لفهم اللغة الطبيعية
في حالة AlphaGo ، كانت العملية على النحو التالي: أولاً ، تم تدريب شبكة Convolution العصبية (CNN) على ملايين الصور لمواضع اللوحة. بعد ذلك ، تم إبلاغ الشبكة بالخطوة اللاحقة التي قام بها الخبراء البشريون في كل حالة خلال مرحلة التدريب للشبكة. بالطريقة نفسها كما ذكرنا سابقًا ، تمت مقارنة القيمة الفعلية بالمخرجات وتم العثور على نوع من مقياس "الخطأ".
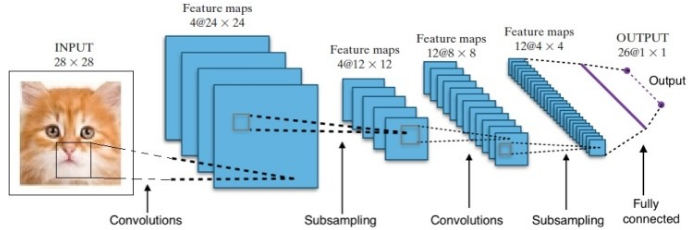
في نهاية التدريب ، سيخرج DNN الحركات التالية جنبًا إلى جنب مع الاحتمالات التي من المحتمل أن يلعبها لاعب بشري خبير. هذا النوع من الشبكات لا يمكن أن يأتي إلا بخطوة يلعبها لاعب خبير بشري. تمكنت DeepMind من تحقيق دقة تصل إلى 60٪ في توقع الحركة التي قد يقوم بها الإنسان. ومع ذلك ، للتغلب على خبير بشري في Go ، هذا لا يكفي. تتم معالجة ناتج DNN بشكل أكبر بواسطة Deep Reinforcement Network ، وهو نهج ابتكرته DeepMind ، والذي يجمع بين الشبكات العصبية العميقة والتعلم المعزز.
التعلم العميق المعزز
التعلم المعزز (RL) ليس مفهومًا جديدًا. جرب إيفان بافلوف الحائز على جائزة نوبل التكييف الكلاسيكي للكلاب واكتشف مبادئ التعلم المعزز في عام 1902. RL هي أيضًا إحدى الطرق التي يتعلم بها البشر مهارات جديدة. هل تساءلت يومًا كيف يتم تدريب الدلافين في العروض على القفز إلى هذه المرتفعات الكبيرة بعيدًا عن الماء؟ إنه بمساعدة RL. أولاً ، يتم غمر الحبل المستخدم في تحضير الدلافين في حوض السباحة. عندما يعبر الدلفين الكابل من الأعلى ، يكافأ بالطعام. عندما لا تعبر الحبل يتم سحب المكافأة. ببطء سوف يتعلم الدلفين أنه يتم الدفع له كلما مر الحبل من أعلى. يتم زيادة ارتفاع الحبل تدريجياً لتدريب الدلفين. 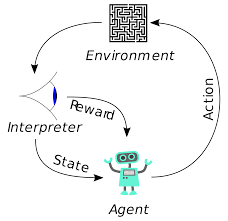
توليد اللغة الطبيعية: أهم الأشياء التي تحتاج إلى معرفتها
يتم أيضًا تدريب وكلاء في التعلم المعزز باستخدام نفس المبدأ. سيتخذ الوكيل إجراءات ويتفاعل مع البيئة. الإجراء الذي اتخذه الوكيل يتسبب في تغيير البيئة. علاوة على ذلك ، تلقى الوكيل ملاحظات حول البيئة. الوكيل إما يكافأ أو لا يكافأ ، اعتمادًا على عمله والهدف المطروح. النقطة المهمة هي أن هذا الهدف لم يُذكر صراحةً للوكيل. بالنظر إلى الوقت الكافي ، سيتعلم الوكيل كيفية تعظيم المكافآت المستقبلية.

بدمج هذا مع DNNs ، اخترع DeepMind التعلم التعزيزي العميق (DRL) أو شبكات Deep Q (DQN) حيث تمثل Q أقصى قدر من المكافآت المستقبلية التي تم الحصول عليها. تم تطبيق DQNs لأول مرة على ألعاب Atari . تعلمت DQN كيفية لعب أنواع مختلفة من ألعاب Atari بمجرد إخراجها من منطقة الجزاء. كان الاختراق هو عدم الحاجة إلى برمجة صريحة لتمثيل أنواع مختلفة من ألعاب أتاري. كان برنامج واحد ذكيًا بما يكفي للتعرف على جميع بيئات اللعبة المختلفة ، ومن خلال اللعب الذاتي ، تمكن من إتقان العديد منها.
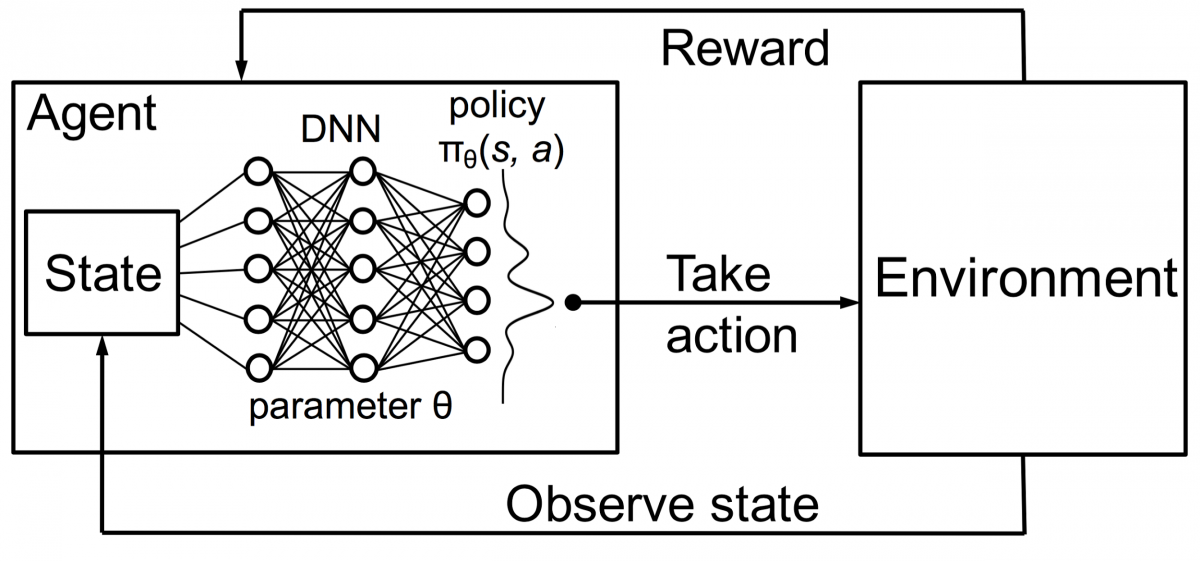
في عام 2014 ، تفوقت DQN على أساليب التعلم الآلي السابقة في 43 لعبة من أصل 49 لعبة (تم اختبارها الآن في أكثر من 70 لعبة). في الواقع ، في أكثر من نصف الألعاب ، كان أداؤها أكثر من 75٪ من مستوى اللاعب البشري المحترف. في بعض الألعاب ، توصلت DQN إلى استراتيجيات بعيدة النظر بشكل مدهش سمحت لها بتحقيق أقصى درجة يمكن بلوغها - على سبيل المثال ، في Breakout ، تعلمت حفر نفق أولاً في أحد طرفي جدار القرميد ، بحيث ترتد الكرة حول الظهر وضرب الطوب من الخلف.
شبكات السياسة والقيمة
هناك نوعان رئيسيان من الشبكات داخل AlphaGo:
يتمثل أحد أهداف DQNs في AlphaGo في تجاوز لعب الخبراء البشري وتقليد الحركات المبتكرة الجديدة ، من خلال اللعب ضد نفسها ملايين المرات وبالتالي تحسين الأوزان بشكل تدريجي. هذا DQN كان له معدل فوز 80٪ ضد DNNs الشائعة. قررت DeepMind دمج هاتين الشبكتين العصبيتين (DNN و DQN) لتشكيل النوع الأول من الشبكة - "شبكة السياسة". باختصار ، تتمثل وظيفة شبكة السياسة في تقليل اتساع نطاق البحث عن الخطوة التالية والتوصل إلى بعض التحركات الجيدة التي تستحق المزيد من الاستكشاف.
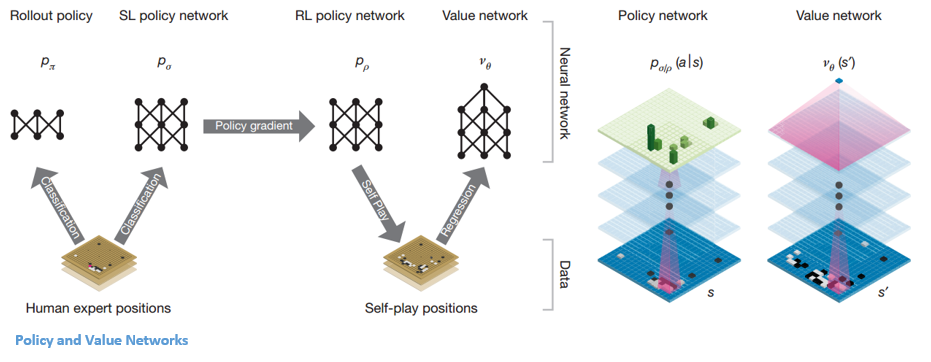 بمجرد تجميد شبكة السياسة ، فإنها تلعب ضد نفسها ملايين المرات. تنشئ هذه الألعاب مجموعة بيانات Go جديدة ، تتكون من مواضع اللوحة المختلفة ونتائج الألعاب. تُستخدم مجموعة البيانات هذه لإنشاء وظيفة تقييم. النوع الثاني من الوظيفة - يتم استخدام "شبكة القيمة" للتنبؤ بنتيجة اللعبة. يتعلم اتخاذ مواقف مختلفة على اللوحة كمدخلات والتنبؤ بنتيجة اللعبة وقياسها.
بمجرد تجميد شبكة السياسة ، فإنها تلعب ضد نفسها ملايين المرات. تنشئ هذه الألعاب مجموعة بيانات Go جديدة ، تتكون من مواضع اللوحة المختلفة ونتائج الألعاب. تُستخدم مجموعة البيانات هذه لإنشاء وظيفة تقييم. النوع الثاني من الوظيفة - يتم استخدام "شبكة القيمة" للتنبؤ بنتيجة اللعبة. يتعلم اتخاذ مواقف مختلفة على اللوحة كمدخلات والتنبؤ بنتيجة اللعبة وقياسها.
الجمع بين السياسة وشبكات القيمة
بعد كل هذا التدريب ، انتهى الأمر بـ DeepMind أخيرًا مع شبكتين عصبيتين - السياسة وشبكات القيمة. تأخذ شبكة السياسة موقع اللوحة كمدخلات وتخرج توزيع الاحتمالات كاحتمال لكل من الحركات في هذا الموضع. تأخذ شبكة القيمة مرة أخرى موضع اللوحة كمدخلات وتخرج رقمًا حقيقيًا واحدًا بين 0 و 1. إذا كان ناتج الشبكة صفرًا ، فهذا يعني أن اللون الأبيض يفوز تمامًا ويشير 1 إلى فوز كامل للاعب ذي اللون الأسود الحجارة.
تقوم شبكة السياسة بتقييم المواقف الحالية ، وتقوم شبكة القيمة بتقييم التحركات المستقبلية. كان تقسيم المهام إلى هاتين الشبكتين بواسطة DeepMind أحد الأسباب الرئيسية وراء نجاح AlphaGo.
الجمع بين شبكات السياسة والقيمة مع Monte Carlo Tree Search (MCTS) و Rollouts
لن تكون الشبكات العصبية بمفردها كافية. للفوز بلعبة Go ، يلزم المزيد من الاستراتيجيات. يتم تحقيق هذه الخطة بمساعدة MCTS. يساعد Monte Carlo Tree Search أيضًا في ربط الشبكتين العصبيتين معًا بطريقة مبتكرة. تساعد الشبكات العصبية في البحث الفعال عن الخطوة التالية الأفضل.
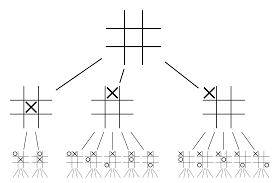
دعنا نحاول بناء مثال سيساعدك على تصور كل هذا بشكل أفضل. تخيل أن اللعبة في وضع جديد لم نواجهه من قبل. في مثل هذه الحالة ، يُطلب من شبكة السياسات تقييم الوضع الحالي والمسارات المستقبلية المحتملة ؛ وكذلك مدى استصواب المسارات وقيمة كل حركة بواسطة شبكات القيمة ، التي تدعمها عمليات طرح مونتي كارلو.
تجد شبكة السياسة جميع التحركات "الجيدة" الممكنة وتقوم شبكات القيمة بتقييم كل نتيجة من نتائجها. في عروض مونت كارلو ، يتم لعب بضعة آلاف من الألعاب العشوائية من المواقف المعترف بها من قبل شبكة السياسة. تم إجراء تجارب لتحديد الأهمية النسبية لشبكات القيمة مقابل عمليات طرح مونتي كارلو. نتيجة لهذه التجربة ، خصص DeepMind وزنًا بنسبة 80 ٪ لشبكات القيمة و 20 ٪ وزنًا لوظيفة تقييم طرح مونت كارلو.
تعمل شبكة السياسة على تقليل عرض البحث من 200 خطوة ممكنة إلى أفضل 4 أو 5 حركات. توسع شبكة السياسة الشجرة من هذه الخطوات الأربع أو الخمس التي تحتاج إلى دراسة. تساعد شبكة القيمة في تقليل عمق البحث عن الشجرة من خلال إرجاع نتيجة اللعبة فورًا من هذا الموضع. أخيرًا ، يتم تحديد الحركة بأعلى قيمة Q ، أي الخطوة ذات الفائدة القصوى.
" تُلعب اللعبة في المقام الأول من خلال الحدس والشعور ، وبسبب جمالها ودقتها وعمقها الفكري ، فقد استحوذت على الخيال البشري لعدة قرون."
- ديميس حسابيس
تطبيق AlphaGo لمشاكل العالم الحقيقي
رؤية DeepMind ، من موقعها على شبكة الإنترنت ، معبرة للغاية - "حل الذكاء. استخدم هذه المعرفة لجعل العالم مكانًا أفضل ". الهدف النهائي لهذه الخوارزمية هو جعلها ذات أغراض عامة بحيث يمكن استخدامها لحل مشاكل العالم الحقيقي المعقدة. يعد برنامج AlphaGo من DeepMind خطوة مهمة إلى الأمام في البحث عن الذكاء الاصطناعي العام. استخدمت DeepMind تقنيتها بنجاح لحل مشاكل العالم الحقيقي - دعنا نلقي نظرة على بعض الأمثلة:
تقليل استهلاك الطاقة
تم استخدام الذكاء الاصطناعي الخاص بـ DeepMind بنجاح لتقليل تكلفة تبريد مركز بيانات Google بنسبة 40٪. في أي بيئة مستهلكة للطاقة على نطاق واسع ، يعد هذا التحسين خطوة استثنائية إلى الأمام. التبريد هو أحد المصادر الأساسية لاستهلاك الطاقة لمركز البيانات. يجب إزالة الكثير من الحرارة الناتجة عن تشغيل الخوادم لإبقائها قيد التشغيل. يتم تحقيق ذلك من خلال المعدات الصناعية واسعة النطاق مثل المضخات والمبردات وأبراج التبريد. نظرًا لأن بيئة مركز البيانات ديناميكية للغاية ، فمن الصعب العمل بكفاءة الطاقة المثلى. تم استخدام الذكاء الاصطناعي الخاص بـ DeepMind لمعالجة هذه المشكلة.
أولاً ، شرعوا في استخدام البيانات التاريخية ، التي تم جمعها بواسطة الآلاف من أجهزة الاستشعار داخل مركز البيانات. باستخدام هذه البيانات ، قاموا بتدريب مجموعة من DNNs على متوسط فعالية استخدام الطاقة في المستقبل (PUE). نظرًا لأن هذه خوارزمية للأغراض العامة ، فمن المخطط أن يتم تطبيقها على تحديات أخرى أيضًا ، في بيئة مركز البيانات.
تتضمن التطبيقات المحتملة لهذه التقنية الحصول على المزيد من الطاقة من نفس وحدة الإدخال ، وتقليل استخدام الطاقة في تصنيع أشباه الموصلات والمياه ، وما إلى ذلك ، أعلنت DeepMind في منشورها على المدونة أن هذه المعرفة ستتم مشاركتها في منشور مستقبلي بحيث يتم مشاركة مراكز البيانات الأخرى ، الصناعية يمكن للمشغلين والبيئة في النهاية الاستفادة بشكل كبير من هذه الخطوة المهمة.
تخطيط العلاج الإشعاعي لسرطان الرأس والرقبة
تعاونت شركة DeepMind مع قسم العلاج الإشعاعي في NHS Foundation Trust التابع لمستشفى جامعة لندن الجامعية ، وهي مؤسسة رائدة عالميًا في علاج السرطان.
كيف تتحد البيانات الضخمة والتعلم الآلي ضد السرطان
تم تشخيص إصابة رجل واحد من كل 75 رجلاً وواحدة من كل 150 امرأة بسرطان الفم في حياتهم. نظرًا للطبيعة الحساسة للهياكل والأعضاء في منطقة الرأس والرقبة ، يحتاج اختصاصيو الأشعة إلى توخي الحذر الشديد أثناء علاجهم.
قبل إجراء العلاج الإشعاعي ، يجب إعداد خريطة مفصلة بالمناطق المراد علاجها والمناطق التي يجب تجنبها. هذا هو المعروف باسم التجزئة. يتم إدخال هذه الخريطة المجزأة في آلة التصوير الشعاعي ، والتي ستستهدف بعد ذلك الخلايا السرطانية دون الإضرار بالخلايا السليمة.
في حالة سرطان الرأس أو الرقبة ، فهذه مهمة شاقة لأطباء الأشعة لأنها تشمل أعضاء حساسة للغاية. يستغرق اختصاصي الأشعة حوالي أربع ساعات لإنشاء خريطة مجزأة لهذه المنطقة. يهدف DeepMind ، من خلال خوارزمياته ، إلى تقليل الوقت اللازم لإنشاء الخرائط المجزأة ، من أربع إلى ساعة واحدة. سيؤدي ذلك إلى توفير وقت اختصاصي الأشعة بشكل كبير. الأهم من ذلك ، يمكن استخدام خوارزمية التجزئة هذه لأجزاء أخرى من الجسم.
للتلخيص ، نجح AlphaGo في الفوز على بطل العالم 18 مرة ، Lee Seedol ، أربع مرات في بطولة أفضل من خمسة في عام 2016. في عام 2017 ، حتى أنه تغلب على فريق من أفضل اللاعبين في العالم. يستخدم مزيجًا من DNN و DQN كشبكة سياسة للتوصل إلى الخطوة التالية الأفضل ، و DNN واحد كشبكة قيمة لتقييم نتيجة اللعبة. يتم استخدام بحث شجرة مونت كارلو جنبًا إلى جنب مع كل من شبكات السياسة والقيمة لتقليل عرض البحث وعمقه - حيث يتم استخدامها لتحسين وظيفة التقييم. الهدف النهائي لهذه الخوارزمية ليس حل ألعاب الطاولة ولكن لابتكار خوارزمية الذكاء الاصطناعي العام. AlphaGo هو بلا شك خطوة كبيرة إلى الأمام في هذا الاتجاه.
الفرق بين علم البيانات والتعلم الآلي والبيانات الضخمة!
بالطبع ، كانت هناك تأثيرات أخرى. مع انتشار أخبار AlphaGo Vs Lee Seedol ، قفز الطلب على ألواح Go عشرة أضعاف. أبلغت العديد من المتاجر عن حالات نفاد مخزون لوحات Go ، وأصبح من الصعب شراء لوحة Go.
لحسن الحظ ، لقد وجدت للتو واحدة وطلبتها لنفسي ولطفلي. هل تخطط لشراء السبورة وتعلم Go؟
تعلم دورات تعلم الآلة من أفضل الجامعات في العالم. احصل على درجة الماجستير أو برنامج PGP التنفيذي أو برامج الشهادات المتقدمة لتسريع مسار حياتك المهنية.
ما هي حدود التعلم المعزز العميق؟
تنسى DL المعرفة المكتسبة سابقًا عند تقديم بيانات أو معلومات جديدة ، لذا فهي لا تتحدى ذلك. يمكن أن يؤدي التعزيز المفرط في بعض الأحيان إلى زيادة الحالات ، مما يقلل من الفعالية. نظرًا لتعقيد نماذج البيانات ، فإن التدريب مكلف للغاية. يتطلب التعلم العميق أيضًا استخدام وحدات معالجة الرسومات باهظة الثمن ومئات محطات العمل. نتيجة لذلك ، يصبح استخدامه أقل اقتصادا.
ما هي سلبيات استخدام Monte Carlo Tree Search؟
على الرغم من أن MCTS عبارة عن خوارزمية بسيطة للتنفيذ ، إلا أن لها عيوبًا معينة. عندما تنمو الشجرة بشكل أكبر بعد عدة تكرارات ، يتطلب الأمر قدرًا كبيرًا من الذاكرة. عند تطبيقها على الألعاب القائمة على الأدوار ، قد يكون هناك فرع أو مسار واحد يؤدي إلى خسارة ضد الخصم في ظروف معينة. نتيجة لذلك ، يمكن الاعتماد عليها قليلاً. بعد العديد من التكرارات ، يستغرق Monte Carlo Tree Search وقتًا طويلاً لتحديد المسار الأكثر فعالية.
كيف يختلف AlphaZero عن AlphaGo Zero؟
تضمنت الإصدارات السابقة من AlphaGo عددًا ضئيلًا من الميزات المصممة يدويًا ، لكن AlphaGo Zero يستخدم فقط الأحجار السوداء والبيضاء من لوحة Go كمدخلات. اعتمدت الإصدارات السابقة من AlphaGo على شبكة سياسة لاختيار الخطوة التالية وشبكة قيمة لتقدير الفائز في اللعبة من كل مركز. تم دمجها في AlphaGo Zero ، مما يسمح بتدريب وتقييم أكثر كفاءة. تساهم كل هذه الاختلافات في تحسين أداء النظام وتعميمه. من ناحية أخرى ، يجعل التعديل الحسابي النظام أكثر قوة وكفاءة.