دليل المسافر إلى MapReduce
نشرت: 2018-02-05إذا كنت قد قرأت مقالتنا حول أدوات وتقنيات البيانات الضخمة ، فقد تتذكر أنك صادفت مصطلح " MapReduce ". إنه أحد المكونات الأساسية لبنية Hadoop ويشكل طبقة المعالجة الكاملة لـ Hadoop.
في هذه المقالة ، سنتحدث عن MapReduce بمزيد من التعمق - ولكن بطريقة صديقة للمبتدئين. لتسهيل فهمك ، قمنا بتقسيم المقالة على النحو التالي: 
- مقدمة
- المفاهيم الأساسية
- تحليل SWOT كامل
مقدمة إلى MapReduce
MapReduce هو في الأساس مفهوم يسمح بمعالجة سريعة لمجموعات البيانات الضخمة على كتلة موزعة. إنه نموذج برمجة حاصل على براءة اختراع بواسطة Google والذي تم تبنيه لأول مرة من قبل الرجال في Apache وهو الآن في قلب نظام Hadoop البيئي بأكمله. إن بساطته هي ما يجعله فعالاً للغاية ويستحق الثناء.
يتبع MapReduce منطقًا بسيطًا للغاية ، وهو منطق تم اتباعه للأعمار لإدارة المهام اليومية - عندما تضطر إلى التعامل مع الكثير من المواد ، سيؤدي توظيف عدد كبير من العمال إلى تسريع العملية (القول المأثور القديم "أيضًا" العديد من الطهاة يفسدون المرق "لا يصلح هنا!).
ومع ذلك ، في هذه المرحلة ، يُطرح سؤال واحد - هل يعمل MapReduce جيدًا فقط مع مجموعات البيانات الضخمة؟
الإجابة عن ذلك بسيطة للغاية - لا يلزم بالضرورة أن تكون مجموعات البيانات كبيرة للغاية. ومع ذلك ، نظرًا لأسباب اقتصادية وحسابية ، يوصى بتشغيل MapReduce فقط إذا كانت لديك مجموعات بيانات كبيرة ، وكبيرة بما يكفي لإجراء العمليات الحسابية التقليدية. من الأفضل دائمًا معالجة مجموعات البيانات الصغيرة على جهازك المحلي نفسه - بالطريقة التي كانت عليها قبل تقديم MapReduce . لأنه بصراحة ، فإن استخدام MapReduce لقطع صغيرة من البيانات يشبه إلى حد كبير محاولة قتل العنكبوت باستخدام مدفع رشاش. سيقتل العنكبوت بلا شك ، لكن هل يستحق ذلك؟

المفاهيم الأساسية لبرنامج MapReduce
الآن ، لديك فكرة جيدة عما هو MapReduce بالضبط. في هذا القسم ، سنتحدث أكثر قليلاً عن كيفية عمل MapReduce بالضبط - المفاهيم الأساسية التي تحرك العجلات.
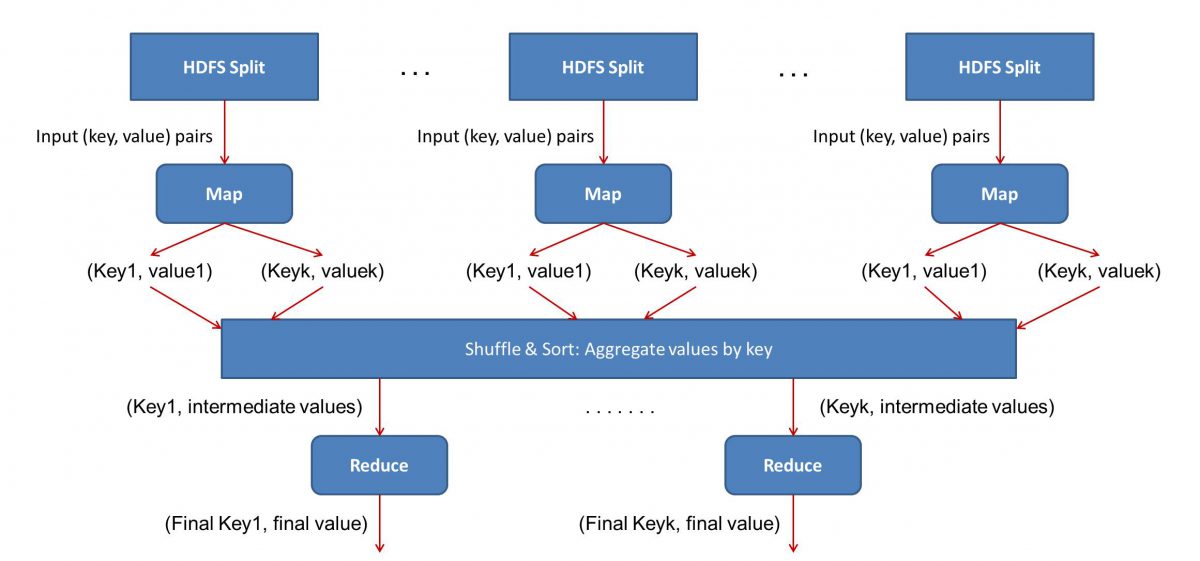
إذا واجهت الرياضيات الأساسية في حياتك (والتي نأمل أن تكون لديك إذا كنت تقرأ هذا!) ، يجب أن تكون على دراية بمفاهيم "الأزواج المرتبة". إنها ببساطة طريقة للتعبير عن جزأين من البيانات بصيغة (س ، ص). تعتبر الأزواج المرتبة مفيدة جدًا لتمثيل الإحداثيات والكسور ومعرفات الموظفين والأشكال المماثلة الأخرى من البيانات. يعتمد MapReduce أيضًا بشكل كبير على مفهوم الأزواج المرتبة - بشكل أساسي ، يمكن "تعيين" أي بيانات في شكل زوج مرتب ، ويمكن "تقليلها" بعدة طرق ، اعتمادًا على بيان المشكلة المطروح.
لنفترض أنك تركت بمفردك في مكتبة رقمية تحتوي على مائة ألف كتاب وأعطيت مهمة شاقة تتمثل في العثور على عدد المرات التي تظهر فيها كلمة معينة في جميع الكتب مجتمعة .
كيف تبدأ؟
تتمثل الطريقة الأولى في كتابة برنامج يتكرر على كل كلمة ، بدءًا من الكتاب 1 - Word 1 ، إلى Book n - Word n ، والاستمرار في زيادة متغير العداد في كل مرة تواجه فيها الكلمة المطلوبة. مجرد تخيل هذا سيجعلك تدرك مقدار الوقت الذي ستستغرقه لإنجاز هذه المهمة.
الآن ، دعنا نلقي نظرة على كيفية استجابة MapReduce للمهمة:
- متطلبات MapReduce:
يعمل MapReduce بشكل جيد في مجموعة موزعة. ما هي الكتلة الموزعة ، تسأل؟
ببساطة شديدة ، هو عدد كبير (غالبًا آلاف!) من أجهزة الكمبيوتر السلعية (أجهزة كمبيوتر منخفضة التكلفة) متشابكة في شبكة تؤدي عملية واحدة.
الآن ، افترض أن لديك مجموعة واحدة من هذا القبيل. بالنسبة لبيان مشكلتنا ، فإن المدخلات في هذه المجموعة ستكون محتوى جميع الكتب. بمجرد قيامنا بإدخال هذه البيانات في نظامنا ، يتم نسخها في كل كمبيوتر (عقدة) على الكتلة (على افتراض أننا نتعامل مع وظيفة واحدة فقط في الوقت الحالي). يتم ذلك لتوفير مستوى من التسامح مع الخطأ - لمساعدتك في حالة فقد البيانات.
- البرمجة في MapReduce
نظرًا لأن MapReduce يعمل على مرحلتين - تعيين وتقليل ، يتعين علينا كتابة برنامجين ، Map () و Reduce () ، للحصول على سير عمل MapReduce وتشغيله. في وقت سابق كنت قد استخدمت Java لكتابة هذه البرامج ، ولكن الآن بسبب النمو السريع في Data Science ، أصبح إطار عمل MapReduce مرنًا بدرجة كافية للتعامل مع الأكواد المكتوبة بلغة Python أو R أيضًا.
سيتم تشغيل البرامج النصية التي تكتبها واحدة تلو الأخرى ، أي بطريقة متتالية. يقودنا هذا إلى إحدى العيوب الرئيسية في نموذج MapReduce - حقيقة أنه لا يمكنك تشغيل كلا النصين بالتوازي. سيؤدي إنجاز ذلك إلى جعل MapReduc أسرع كثيرًا ، وقد كان ذلك موضوع بحث مكثف.

- موازاة سير العمل:
سيتم تقسيم المدخلات (محتوى جميع الكتب) إلى أجزاء مختلفة (مساوية لعدد أجهزة الكمبيوتر في المجموعة ، بشكل أساسي) ، وسيتم تخصيص مقطع معين لكل كمبيوتر. لنفترض أننا قمنا بتقسيم الملف إلى أسطر ، ثم قد يُطلب من العقدة 1 الاهتمام بالخطوط من 1 إلى 10000 ، وقد يُطلب من العقدة 2 مثل 10001 إلى 20000 ، وهكذا. (تذكر أن هذه مجرد أرقام توضيحية - الأجزاء أكبر بكثير في الحياة الواقعية)
سيقوم كل جهاز بعد ذلك بتشغيل برنامج Map () الخاص بك.
- برنامج الخريطة ():
يقوم برنامج Map () بما كنت ستفعله بالضبط قبل إعطاء المهمة لـ MapReduce - مسح الملف وقراءة كلمة واحدة في كل مرة. الفائدة هنا هي أنه سيتم تشغيله في وقت واحد على أجهزة كمبيوتر متعددة ، لذلك سيقلل الوقت من خلال المشعبات. ناتج الوظيفة Map () هو زوج مرتب. في هذه الحالة ، ستكون ببساطة (كلمة ، عدد) ، أي عندما تصادف وظيفة Map () كلمة "مرحبًا" (بافتراض أن هذه هي الكلمة التي نبحث عنها) ، سيتم إخراجها ببساطة (مرحبًا ، 1) باعتبارها انتاج. نظرًا لأنه يتم العمل على أجزاء مختلفة من نص الكود في نفس الوقت ، سيكون لديك نسخة محددة من مجموعة البيانات الخاصة بك في أي وقت من الأوقات! لتقدير بساطة MapReduce ، أدرك أن العملية التي يتم إجراؤها هنا أساسية إلى حد ما ولا تتطلب حسابات مكثفة.
- خلط النتائج المعينة:
بمجرد أن نحصل على الأزواج النهائية المرتبة من وظيفة Map () ، يتم خلط النتائج. هذا يعني ببساطة أنه يتم نقل أزواج (كلمة ، عدد) بنفس الكلمة إلى آلة واحدة.
الآن ، إذا كنت على دراية بالبرمجة ، فسوف تدرك أن هناك حدًا يمكن تحقيق ذلك. يوجد فعليًا بلايين الكلمات وعدد محدود فقط من أجهزة الكمبيوتر في المجموعة. في هذه المرحلة ، من المهم ملاحظة أن مرحلة الخلط غير إلزامية لكي تعمل MapReduce ، فهي ببساطة تجعل البرنامج النصي Reduce () أسرع بكثير عن طريق ترتيب الأشياء في ترتيب. في الوقت الحالي ، دعنا نقول فقط أننا قمنا بتبديل مخرجات الخريطة ، ولدينا الآن جميع مثيلات كلمة "مرحبًا" في جهاز كمبيوتر واحد في شكل زوج مرتب - (مرحبًا ، n) حيث n هو عدد المرات " مرحبًا "حدث في كتاب واحد معين.

- أخيرًا ، مرحلة Reduce ():
أخيرًا ، نصل إلى المرحلة الأخيرة - تقليل (). إذا كنت تهتم بسير العمل بالكامل ، فربما تكون قد خمنت بشكل صحيح أن Reduce () سيحسب فقط عدد المرات التي تظهر فيها كل كلمة في ملف الإدخال. كل ما عليه فعله هو ببساطة إضافة المكون الثاني من أزواجنا المرتبة. إذا كان هناك ، لنقل 200 إشارة لكلمة "hello" في جميع الكتب ، فإن الناتج النهائي الذي سنحصل عليه بعد هذه المرحلة سيكون - (مرحبًا ، 200). فقط عن طريق العد والجمع البسيط ، وصلنا إلى النتيجة. أصبح كل ذلك ممكنًا من خلال استخدام عدد من أجهزة الكمبيوتر وجعلها تعمل في وقت واحد.
MapReduce تحليل SWOT
لقد جعل نموذج MapReduce حياة علماء البيانات أسهل. دعنا نلقي نظرة على نقاط القوة والضعف والفرص والتهديدات في هذا الإطار:
| نقاط القوة | يعالج مجموعات البيانات الضخمة بسرعة البرق من خلال معالجتها بشكل متوازي في مجموعات موزعة. |
| نقاط الضعف | يتم تشغيل البرامج النصية Map () و Reduce () على التوالي. يتم تنفيذ عمليات القراءة / الكتابة على HDFS ، وهي بطيئة بالمقارنة |
| فرص | توليد الرؤى من مجموعات البيانات المهملة السابقة ومعالجة البيانات الضخمة التي أنشأتها المؤسسات. |
| التهديدات | قد تؤدي عمليات MapReduce المستقلة إلى إبطاء وتيرة صناعة البيانات الضخمة دون التقدم الكافي في التحليلات. |
ختاما…
الآن بعد أن أصبحت على دراية بالأعمال الداخلية لـ MapReduce ، ستدرك أنها ليست بأي حال من الأحوال تقنية جديدة - لقد استخدمنا نماذج مماثلة للتعامل مع حجم كبير من البيانات ، مثل نتائج الانتخابات ، لفترة طويلة جدًا حاليا. ستدرك أيضًا أهمية إبقاء الأشياء بسيطة - لا يقوم MapReduce بأي شيء خيالي على الإطلاق ، وهذا ما يجعله قويًا للغاية.
إذا كنت مهتمًا بمعرفة المزيد عن البيانات الضخمة ، فراجع دبلومة PG في تخصص تطوير البرمجيات في برنامج البيانات الضخمة المصمم للمهنيين العاملين ويوفر أكثر من 7 دراسات حالة ومشاريع ، ويغطي 14 لغة وأدوات برمجة ، وتدريب عملي عملي ورش العمل ، أكثر من 400 ساعة من التعلم الصارم والمساعدة في التوظيف مع الشركات الكبرى.
تعلم شهادات هندسة البرمجيات عبر الإنترنت من أفضل الجامعات في العالم. اربح برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.