MapReduce 搭便车指南
已发表: 2018-02-05如果您阅读过我们关于大数据工具和技术的文章,您可能还记得遇到过“ MapReduce ”一词。 它是 Hadoop 架构的核心组件之一,构成了 Hadoop 的整个处理层。
在本文中,我们将更深入地讨论MapReduce——但是以一种对初学者友好的方式。 为了便于理解,我们将文章分解如下: 
- 介绍
- 核心概念
- 完整的 SWOT 分析
MapReduce 简介
MapReduce本质上是一个允许在分布式集群上快速处理海量数据集的概念。 它是一种由谷歌获得专利的编程模型,最初被 Apache 的人采用,现在是整个 Hadoop 生态系统的核心。 它的简单性使它如此有效和值得称道。
MapReduce遵循一个非常简单的逻辑,多年来一直遵循该逻辑来管理日常任务——当您必须处理大量材料时,雇用大量工人将加快流程(古老的格言“太许多厨师破坏肉汤”不适合这里!)。
然而,此时出现了一个问题——MapReduce 是否仅适用于庞大的数据集?
答案很简单——数据集不一定非常大。 但是,由于经济和计算方面的原因,建议仅在您拥有足够大的数据集以进行传统计算时才使用MapReduce 。 在本地机器上处理小型数据集总是更好——就像在引入MapReduce之前那样。 因为老实说,对小块数据使用MapReduce非常类似于试图用机关枪杀死蜘蛛。 毫无疑问,蜘蛛会被杀死,但这值得吗?

MapReduce 的核心概念
到目前为止,您对MapReduce到底是什么有了一个清晰的认识。 在本节中,我们将更多地讨论MapReduce究竟是如何工作的——让车轮运转的核心概念。
如果您在生活中遇到过基础数学(我们希望您正在阅读本文!),您必须了解“有序对”的概念。 它只是一种以 (x,y) 形式表达两条数据的方式。 有序对对于表示坐标、分数、员工 ID 和其他类似形式的数据非常有用。 MapReduce也严重依赖有序对的概念——基本上,任何数据都可以“映射”成有序对的形式,并且可以通过多种方式“归约”,具体取决于手头的问题陈述。
假设您独自待在一个包含十万本书籍的数字图书馆中,并面临一项艰巨的任务,即找出特定单词在所有书籍中出现的次数。
呸,你会怎么开始?
第一种方法是编写一个程序,迭代每个单词,从Book 1 - Word 1 到 Book n - Word n,并在每次遇到所需单词时不断增加一个计数器变量。 只要想象一下,您就会意识到完成这项任务需要花费的时间。
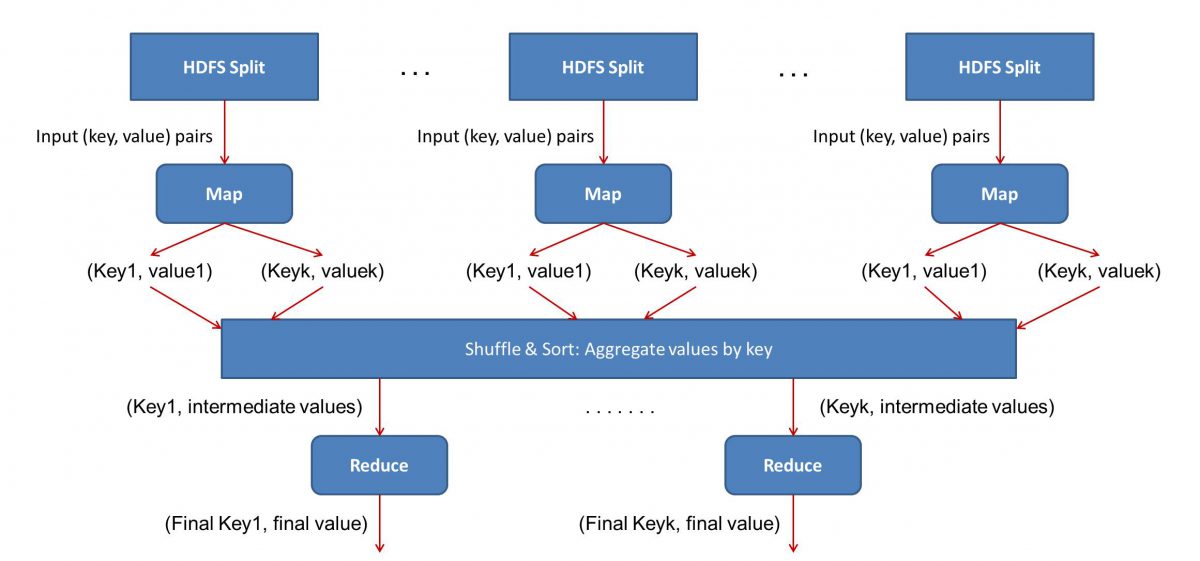
现在,让我们看看MapReduce将如何响应任务:
- MapReduce 要求:
MapReduce在分布式集群中运行良好。 你问什么是分布式集群?
很简单,它是大量(通常是数千!)商品计算机(低成本计算机)交织成一个执行单一操作的网络。
现在,假设您有一个这样的集群。 对于我们的问题陈述,该集群的输入将是所有书籍的内容。 一旦我们将这些数据输入我们的系统,它就会被复制到集群上的每台计算机(节点)中(假设我们目前只处理一项工作)。 这样做是为了提供一定程度的容错能力——在数据丢失的情况下为您提供帮助。
- MapReduce 中的编程
由于MapReduce分两个阶段工作 - Map 和 reduce,我们必须编写两个程序 Map() 和 Reduce(),以启动和运行MapReduce工作流。 早些时候,您曾使用 Java 编写这些程序,但现在由于数据科学的快速发展, MapReduce框架已经变得足够灵活,可以处理用 Python 或 R 编写的代码。
您编写的脚本将一个接一个地运行,即以连续的方式运行。 这给我们带来了MapReduce范式的主要缺点之一——您不能同时运行两个脚本。 实现这一点将使MapReduce更快,这一直是广泛研究的主题。

- 工作流程并行化:
输入(所有书籍的内容)将被分成不同的段(基本上等于集群中的计算机数量),并且每台计算机将被分配一个特定的段。 假设我们已经根据行划分了文件,那么节点 1 可能会被要求处理第 1 到 10,000 行,节点 2 可能会被要求处理 10,001 到 20,000 行,依此类推。 (请记住,这些只是说明性的数字——这些部分在现实生活中要大得多)
然后每台机器将运行您的 Map() 程序。
- Map() 程序:
Map() 程序完全按照您在将任务交给MapReduce之前要做的事情- 扫描文件并一次读取一个单词。 这里的好处是它将在多台计算机上同时运行,因此它将通过多种方式减少时间。 Map() 函数的输出是一个有序对。 在这种情况下,它只是 (word, count),即当 Map() 函数遇到单词“hello”(假设这是我们要查找的单词)时,它会简单地弹出 (hello, 1) 作为输出。 由于代码主体的各个部分正在同时处理,您将立即拥有数据集的映射版本! 要欣赏MapReduce的简单性,请意识到这里执行的操作是相当基本的,不需要密集计算。
- 映射结果的洗牌:
一旦我们从 Map() 函数中得到最终的有序对,结果就会被打乱。 这仅仅意味着具有相同单词的 (word, count) 对被传输到一台机器上。
现在,如果您熟悉编程,您会意识到实现这一目标是有限度的。 实际上有数十亿个单词,并且集群中只有有限数量的计算机。 在这一点上,重要的是要注意 shuffle 阶段对于MapReduce运行不是强制性的,它只是通过按顺序排列事物来使 Reduce() 脚本更快。 现在,假设我们打乱了我们的 Map 输出,现在在一台计算机中以有序对的形式拥有单词“hello”的所有实例 - (hello, n) 其中 n 是次数“你好”出现在一本特定的书中。

- 最后,Reduce() 阶段:
最后,我们来到最后一个阶段——Reduce()。 如果您关注整个工作流程,您可能已经正确猜到 Reduce() 只会计算每个单词在输入文件中出现的次数。 它所要做的就是简单地添加我们有序对的第二个组件。 如果在所有书中有 200 次提到“你好”这个词,我们将在这个阶段之后得到的最终输出将是 –(你好,200)。 只需通过简单的计数和加法,我们就得出了结果。 通过使用多台计算机并使它们同时工作,所有这些都成为可能。
MapReduce SWOT 分析
MapReduce范式使数据科学家的生活变得更轻松。 让我们看看这个框架的优势、劣势、机会和威胁是什么:
| 优势 | 通过在分布式集群中并行处理海量数据集,以闪电般的速度处理它们。 |
| 弱点 | Map() 和 Reduce() 脚本依次运行。 读/写操作在HDFS上进行,相比之下比较慢 |
| 机会 | 从以前丢弃的数据集生成洞察并处理组织生成的大数据。 |
| 威胁 | 如果分析没有足够的进步,独立的MapReduce操作可能会减慢大数据行业的步伐。 |
综上所述…
既然您熟悉MapReduce的内部工作原理,您就会明白它绝不是一项新技术——我们一直在使用类似的范例来处理大量数据,比如选举结果,很长一段时间以来现在。 您还将意识到保持简单的重要性——MapReduce根本没有做任何花哨的事情,这就是它如此强大的原因。
如果您有兴趣了解有关大数据的更多信息,请查看我们的 PG 大数据软件开发专业文凭课程,该课程专为在职专业人士设计,提供 7 多个案例研究和项目,涵盖 14 种编程语言和工具,实用的动手操作研讨会,超过 400 小时的严格学习和顶级公司的就业帮助。
从世界顶级大学在线学习软件工程学位。 获得行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。