MapReduce에 대한 히치하이커를 위한 안내서
게시 됨: 2018-02-05빅 데이터 도구 및 기술에 대한 기사를 읽었다면 " MapReduce " 라는 용어를 접한 것을 기억할 것 입니다. Hadoop 아키텍처의 핵심 구성 요소 중 하나이며 Hadoop의 전체 처리 계층을 구성합니다.
이 기사에서 우리는 MapReduce 에 대해 조금 더 깊이 있게 이야기할 것입니다. 그러나 초보자에게 친숙한 방식입니다. 이해의 편의를 위해 기사를 다음과 같이 분류했습니다. 
- 소개
- 핵심 개념
- 완전한 SWOT 분석
맵리듀스 소개
MapReduce 는 기본적으로 분산 클러스터에서 대규모 데이터 세트를 번개처럼 빠르게 처리할 수 있는 개념입니다. 이것은 Apache 직원들이 처음으로 채택한 Google이 특허를 받은 프로그래밍 모델이며 현재 전체 Hadoop 생태계의 핵심입니다. 그 단순함은 그것을 매우 효과적이고 칭찬할 만하게 만듭니다.
MapReduce 는 일상적인 작업을 관리하기 위해 오랫동안 따라온 매우 간단한 논리를 따릅니다. 많은 자료를 처리해야 할 때 많은 수의 작업자를 고용하면 프로세스 속도가 빨라집니다. 많은 요리사가 국물을 망친다”는 말은 여기에 어울리지 않습니다.).
그러나 이 시점에서 한 가지 질문이 생깁니다. MapReduce 는 거대한 데이터 세트에서만 잘 작동합니까?
이에 대한 대답은 매우 간단합니다. 데이터 세트가 반드시 매우 클 필요는 없습니다 . 그러나 경제적이고 계산적인 이유 때문에 기존 계산에 충분히 큰 큰 데이터 세트가 있는 경우에만 MapReduce 를 작동하도록 하는 것이 좋습니다. MapReduce 가 도입 되기 전과 같이 로컬 시스템 자체에서 작은 데이터 세트를 처리하는 것이 항상 더 좋습니다 . 솔직히 말해서 작은 데이터 덩어리에 MapReduce 를 사용하는 것은 기관총을 사용하여 거미를 죽이려고 하는 것과 매우 비슷하기 때문입니다. 거미는 죽임을 당할 것입니다. 하지만 그럴만한 가치가 있습니까?

MapReduce의 핵심 개념
지금쯤이면 MapReduce가 정확히 무엇인지 알 수 있을 것입니다. 이 섹션에서는 바퀴를 움직이는 핵심 개념인 MapReduce 가 정확히 어떻게 작동하는지에 대해 조금 더 이야기할 것 입니다.
만약 당신이 인생에서 기본적인 수학을 접해본 적이 있다면(당신이 이것을 읽고 있다면 우리는 당신이 그것을 가지고 있기를 바랍니다!), 당신은 "순서쌍"의 개념을 알고 있어야 합니다. 단순히 두 개의 데이터를 (x,y) 형식으로 표현하는 방법입니다. 순서 쌍은 좌표, 분수, 직원 ID 및 기타 유사한 형식의 데이터를 나타내는 데 매우 유용합니다. MapReduce 역시 순서 쌍의 개념에 크게 의존합니다. 기본적으로 모든 데이터는 순서 쌍의 형태로 "매핑"될 수 있으며 당면한 문제 설명에 따라 다양한 방식으로 "축소"될 수 있습니다.
십만 권의 책이 있는 디지털 도서관에 혼자 남겨져 있고 모든 책을 합친 것에서 특정 단어가 나오는 횟수를 찾는 어려운 작업이 주어졌다고 가정해 보겠습니다 .
휴, 어떻게 시작하시겠습니까?
첫 번째 접근 방식은 책 1 – 단어 1에서 책 n – 단어 n까지 모든 단어를 반복 하고 필요한 단어를 만날 때마다 카운터 변수를 계속 증가시키는 프로그램을 작성하는 것입니다. 이것을 상상하는 것만으로도 이 작업을 수행하는 데 걸리는 시간을 알 수 있습니다.
이제 MapReduce 가 작업에 어떻게 응답 하는지 살펴보겠습니다 .
- 맵리듀스 요구사항:
MapReduce 는 분산 클러스터에서 잘 작동합니다. 분산 클러스터가 무엇입니까?
아주 간단히 말해서, 그것은 단일 작업을 수행하는 네트워크에 짜여진 다수의(종종 수천!) 상용 컴퓨터(저가 컴퓨터)입니다.
이제 그러한 클러스터가 하나 있다고 가정합니다. 문제 설명의 경우 이 클러스터에 대한 입력은 모든 책의 내용이 됩니다. 이 데이터를 시스템에 공급하자마자 클러스터의 모든 컴퓨터(노드)에 복사됩니다(현재 하나의 작업만 처리한다고 가정). 이는 데이터 손실 시 도움이 되도록 내결함성 수준을 제공하기 위해 수행됩니다.
- MapReduce 프로그래밍
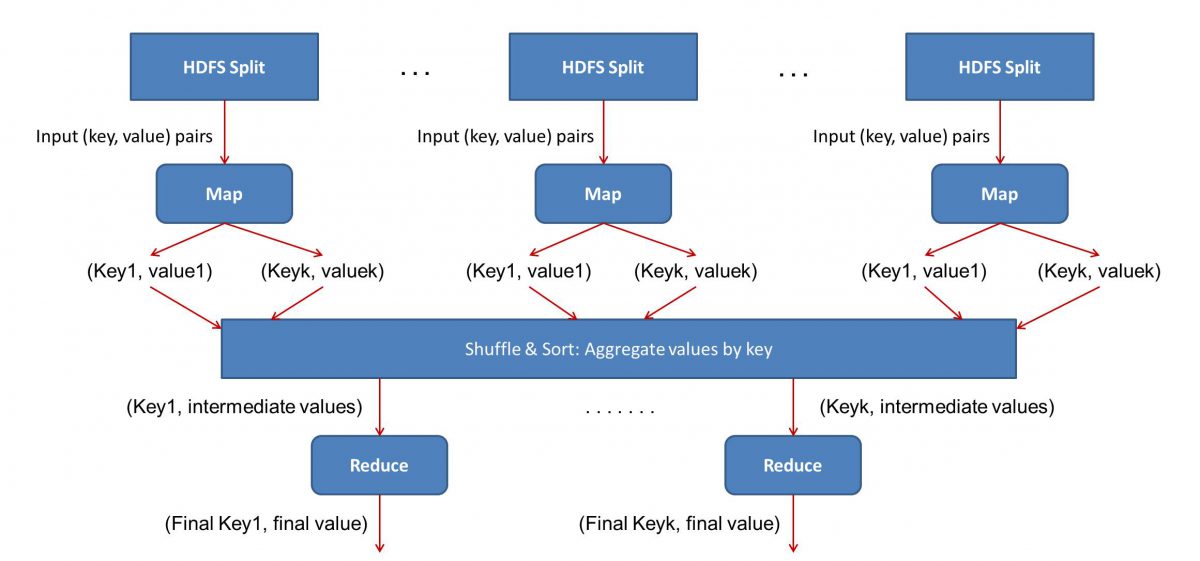
MapReduce 는 Map과 Reduce의 두 단계로 작동 하므로 MapReduce 워크플로를 시작하고 실행하려면 Map()과 Reduce()라는 두 가지 프로그램을 작성해야 합니다 . 이전에는 Java를 사용하여 이러한 프로그램을 작성했지만 이제는 데이터 과학의 급속한 성장으로 인해 MapReduce 프레임워크가 Python 또는 R로 작성된 코드도 처리할 수 있을 정도로 유연해졌습니다.
작성한 스크립트는 차례로, 즉 연속적인 방식으로 실행됩니다. 이것은 MapReduce 패러다임 의 주요 단점 중 하나, 즉 두 스크립트를 동시에 실행할 수 없다는 사실을 알려줍니다. 이를 달성하면 MapReduc 를 훨씬 더 빠르게 만들 수 있으며 이는 광범위한 연구의 주제였습니다.

- 워크플로 병렬화:
입력(모든 책의 내용)은 다양한 세그먼트(기본적으로 클러스터의 컴퓨터 수와 동일)로 나뉘고 각 컴퓨터에는 특정 세그먼트가 할당됩니다. 파일을 줄을 기준으로 나누었다고 가정하면 노드 1은 줄 1에서 10,000까지 처리하도록 요청받을 수 있고 노드 2는 10,001에서 20,000까지 처리하도록 요청받을 수 있습니다. (이것은 단지 예시적인 수치라는 것을 기억하십시오. 세그먼트는 실제 생활에서 훨씬 더 큽니다)
그러면 각 머신이 Map() 프로그램을 실행합니다.
- Map() 프로그램:
Map() 프로그램은 MapReduce 에 작업을 제공하기 전에 수행하려는 작업을 정확히 수행합니다 . 즉, 파일을 스캔하고 한 번에 한 단어를 읽는 것입니다. 여기서의 이점은 여러 컴퓨터에서 동시에 실행되므로 매니폴드에 의해 시간이 단축된다는 것입니다. Map() 함수의 출력은 순서쌍입니다. 이 경우, 그것은 단순히 (단어, 개수)가 될 것입니다. 즉, Map() 함수가 단어 "hello"를 만나면(이것이 우리가 찾고 있는 단어라고 가정), 단순히 (hello, 1) 산출. 코드 본문의 다양한 부분이 동시에 작업되고 있기 때문에 데이터 세트의 매핑된 버전을 곧 갖게 될 것입니다! MapReduce 의 단순성을 이해하려면 여기에서 수행되는 작업이 집중적인 계산이 필요하지 않은 상당히 기본적이라는 것을 인식하십시오.
- 매핑된 결과 섞기:
Map() 함수에서 최종 순서 쌍을 얻으면 결과가 섞입니다. 그것은 단순히 동일한 단어를 가진 (단어, 개수) 쌍이 단일 기계로 전송된다는 것을 의미합니다.
이제 프로그래밍에 대해 잘 알고 있다면 달성할 수 있는 한계가 있음을 알게 될 것입니다. 클러스터에는 말 그대로 수십억 개의 단어와 유한한 수의 컴퓨터만 있습니다. 이 시점에서 셔플 단계는 MapReduce 가 작동하는 데 필수가 아니며 단순히 순서대로 정렬하여 Reduce() 스크립트를 훨씬 빠르게 만듭니다. 지금은 Map 출력을 섞었고 이제 단일 컴퓨터에 순서쌍의 형태로 "hello"라는 단어의 모든 인스턴스가 있다고 가정해 보겠습니다. (hello, n) 여기서 n은 " 안녕하세요”라는 특정 책에서 발생했습니다.

- 마지막으로 Reduce() 단계:
마지막으로, 우리는 마지막 단계인 Reduce()에 도달했습니다. 전체 워크플로에 주의를 기울였다면 Reduce()가 입력 파일에 각 단어가 나타나는 횟수만 계산할 것이라고 올바르게 추측했을 수 있습니다. 순서 쌍의 두 번째 구성 요소를 추가하기만 하면 됩니다. 예를 들어 모든 책에 "hello"라는 단어가 200번 언급된 경우 이 단계 후에 얻을 수 있는 최종 출력은 - (hello, 200)입니다. 단순히 세고 더하기만 하면 결과에 도달했습니다. 이 모든 것은 여러 대의 컴퓨터를 사용하여 동시에 작동하도록 함으로써 가능했습니다.
맵리듀스 SWOT 분석
MapReduce 패러다임 은 데이터 과학자의 삶을 더 쉽게 만들었습니다. 이 프레임워크의 강점, 약점, 기회 및 위협이 무엇인지 살펴보겠습니다.
| 강점 | 대규모 데이터 세트를 분산 클러스터에서 병렬로 처리하여 초고속으로 처리합니다. |
| 약점 | Map() 및 Reduce() 스크립트는 연속적으로 실행됩니다. 읽기/쓰기 작업은 HDFS에서 수행되며 이에 비해 속도가 느립니다. |
| 기회 | 이전에 폐기된 데이터 집합에서 통찰력을 생성하고 조직에서 생성한 빅 데이터를 처리합니다. |
| 위협 | 독립형 MapReduce 작업은 분석의 충분한 발전 없이 빅 데이터 산업의 속도를 늦출 수 있습니다. |
결론적으로…
이제 MapReduce 의 내부 작동 방식에 익숙해 졌으므로 이것이 결코 새로운 기술이 아님을 알게 될 것입니다. 우리는 매우 오랫동안 선거 결과와 같은 대용량 데이터를 처리하기 위해 유사한 패러다임을 사용해 왔습니다. 지금. 또한 단순하게 유지하는 것의 중요성을 깨닫게 될 것입니다. MapReduce 는 멋진 작업을 전혀 수행하지 않으며 이것이 바로 MapReduce를 매우 강력하게 만드는 이유입니다.
빅 데이터에 대해 더 알고 싶다면 PG 디플로마 빅 데이터 소프트웨어 개발 전문화 프로그램을 확인하세요. 이 프로그램은 실무 전문가를 위해 설계되었으며 7개 이상의 사례 연구 및 프로젝트를 제공하고 14개 프로그래밍 언어 및 도구, 실용적인 실습을 다룹니다. 워크샵, 400시간 이상의 엄격한 학습 및 최고의 기업과의 취업 지원.
세계 최고의 대학에서 온라인으로 소프트웨어 엔지니어링 학위 를 배우십시오 . 이그 제 큐 티브 PG 프로그램, 고급 인증 프로그램 또는 석사 프로그램을 획득하여 경력을 빠르게 추적하십시오.