Per Anhalter durch MapReduce
Veröffentlicht: 2018-02-05Wenn Sie unseren Artikel über Big-Data-Tools und -Technologien gelesen haben, erinnern Sie sich vielleicht, dass Sie auf den Begriff „ MapReduce “ gestoßen sind. Es ist eine der Kernkomponenten der Hadoop-Architektur und bildet die gesamte Verarbeitungsschicht von Hadoop.
In diesem Artikel gehen wir etwas ausführlicher auf MapReduce ein – aber auf anfängerfreundliche Weise. Zum leichteren Verständnis haben wir den Artikel wie folgt gegliedert: 
- Einführung
- Kernkonzepte
- Eine vollständige SWOT-Analyse
Einführung in MapReduce
MapReduce ist im Wesentlichen ein Konzept, das eine blitzschnelle Verarbeitung riesiger Datensätze in einem verteilten Cluster ermöglicht. Es ist ein von Google patentiertes Programmiermodell, das zuerst von den Leuten bei Apache übernommen wurde und nun das Herzstück des gesamten Hadoop-Ökosystems bildet. Seine Einfachheit macht es so effektiv und lobenswert.
MapReduce folgt einer sehr einfachen Logik, die seit Ewigkeiten für die Verwaltung alltäglicher Aufgaben befolgt wird – wenn Sie mit viel Material umgehen müssen, beschleunigt die Beschäftigung einer großen Anzahl von Mitarbeitern den Prozess (das uralte Sprichwort „auch viele Köche verderben den Brei“ passt hier nicht!).
An dieser Stelle stellt sich jedoch eine Frage: Funktioniert MapReduce NUR mit riesigen Datensätzen gut?
Die Antwort darauf ist ganz einfach – die Datensätze müssen nicht unbedingt extrem groß sein. Aus wirtschaftlichen und rechnerischen Gründen wird jedoch empfohlen, MapReduce nur dann einzusetzen, wenn Sie über große Datensätze verfügen, die groß genug für herkömmliche Berechnungen sind. Es ist immer besser, kleine Datensätze auf Ihrem lokalen Rechner selbst zu verarbeiten – so wie es vor der Einführung von MapReduce war. Denn ehrlich gesagt ist die Verwendung von MapReduce für kleine Datenmengen sehr ähnlich dem Versuch, eine Spinne mit einem Maschinengewehr zu töten. Die Spinne wird zweifellos getötet, aber ist es das wert?

Die Kernkonzepte von MapReduce
Inzwischen haben Sie eine ungefähre Vorstellung davon, was genau MapReduce ist. In diesem Abschnitt werden wir ein wenig mehr darüber sprechen, wie genau MapReduce funktioniert – die Kernkonzepte, die die Räder in Bewegung bringen.
Wenn Sie jemals in Ihrem Leben mit grundlegender Mathematik in Berührung gekommen sind (was wir hoffen, wenn Sie dies lesen!), müssen Sie sich der Konzepte „geordneter Paare“ bewusst sein. Es ist einfach eine Möglichkeit, zwei Daten in (x,y)-Form auszudrücken. Geordnete Paare sind sehr nützlich, um Koordinaten, Brüche, Mitarbeiter-IDs und andere ähnliche Datenformen darzustellen. Auch MapReduce setzt stark auf das Konzept der geordneten Paare – im Grunde lassen sich beliebige Daten in Form eines geordneten Paares „abbilden“ und je nach Problemstellung auf unterschiedliche Weise „reduzieren“.
Angenommen, Sie werden in einer digitalen Bibliothek mit hunderttausend Büchern allein gelassen und stehen vor der entmutigenden Aufgabe, herauszufinden, wie oft ein bestimmtes Wort in allen Büchern zusammen vorkommt .
Puh, wie fängst du an?
Der erste Ansatz wäre, ein Programm zu schreiben, das jedes Wort von Buch 1 – Wort 1 bis Buch n – Wort n durchläuft und jedes Mal, wenn Sie auf das benötigte Wort stoßen, eine Zählervariable erhöht. Wenn Sie sich das nur vorstellen, werden Sie erkennen, wie viel Zeit es dauern wird, diese Aufgabe zu erfüllen.
Schauen wir uns nun an, wie MapReduce auf die Aufgabe reagiert:
- MapReduce-Anforderungen:
MapReduce funktioniert gut in einem verteilten Cluster. Was ist ein verteilter Cluster, fragen Sie?
Ganz einfach, es ist eine große Anzahl (oft Tausende!) von Standardcomputern (Billigcomputern), die in ein Netzwerk verwoben sind, das eine einzige Operation ausführt.
Nehmen wir nun an, Sie haben einen solchen Cluster. Für unsere Problemstellung ist die Eingabe für diesen Cluster der Inhalt aller Bücher. Sobald wir diese Daten in unser System einspeisen, werden sie auf jeden einzelnen Computer (Knoten) im Cluster kopiert (vorausgesetzt, wir haben es im Moment nur mit einem Job zu tun). Dies geschieht, um ein gewisses Maß an Fehlertoleranz bereitzustellen – um Ihnen im Falle eines Datenverlusts zu helfen.
- Programmierung in MapReduce
Da MapReduce in zwei Phasen arbeitet – Map und Reduce, müssen wir zwei Programme schreiben, Map() und Reduce(), um einen MapReduce -Workflow zum Laufen zu bringen. Früher mussten Sie Java verwenden, um diese Programme zu schreiben, aber jetzt wurde das MapReduce -Framework aufgrund des schnellen Wachstums in Data Science flexibel genug gemacht, um auch in Python oder R geschriebene Codes zu verarbeiten.
Die von Ihnen geschriebenen Skripte werden nacheinander ausgeführt, d. h. nacheinander. Dies bringt uns zu einem der größten Nachteile des MapReduce- Paradigmas – der Tatsache, dass Sie nicht beide Skripte parallel ausführen können. Wenn Sie dies erreichen, wird MapReduc viel schneller, und das war Gegenstand umfangreicher Untersuchungen.

- Workflow-Parallelisierung:
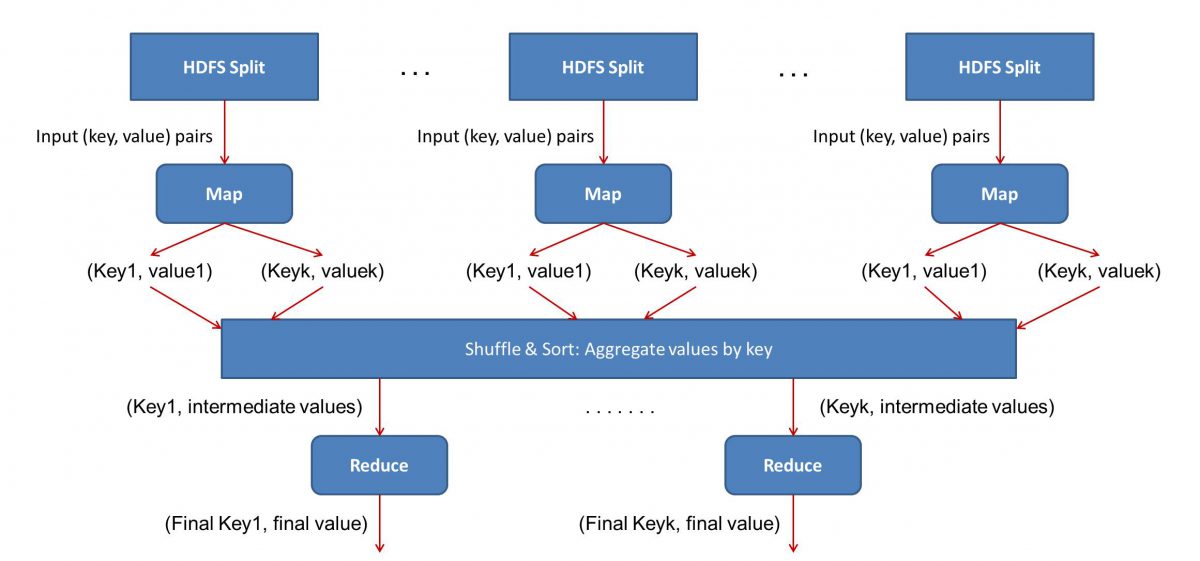
Die Eingabe (Inhalt aller Bücher) wird in verschiedene Segmente unterteilt (im Wesentlichen gleich der Anzahl der Computer im Cluster), und jedem Computer wird ein bestimmtes Segment zugewiesen. Angenommen, wir haben die Datei basierend auf Zeilen aufgeteilt, dann könnte Knoten 1 gebeten werden, sich um die Zeilen 1 bis 10.000 zu kümmern, Knoten 2 könnte nach 10.001 bis 20.000 gefragt werden und so weiter. (Denken Sie daran, dass dies nur illustrative Zahlen sind – die Segmente sind im wirklichen Leben viel größer)
Jede Maschine führt dann Ihr Map()-Programm aus.
- Das Map()-Programm:
Das Map()-Programm tut genau das, was Sie tun wollten, bevor Sie MapReduce die Aufgabe übertragen – die Datei scannen und ein Wort nach dem anderen lesen. Der Vorteil hierbei ist, dass es gleichzeitig auf mehreren Computern ausgeführt wird, sodass die Zeit um ein Vielfaches reduziert wird. Die Ausgabe der Funktion Map() ist ein geordnetes Paar. In diesem Fall ist es einfach (Wort, Anzahl), dh wenn die Map()-Funktion auf das Wort „Hallo“ trifft (vorausgesetzt, das ist das Wort, nach dem wir suchen), wird sie einfach (Hallo, 1) als ein ausgeben Ausgang. Da an verschiedenen Teilen des Codekörpers gleichzeitig gearbeitet wird, haben Sie in kürzester Zeit eine gemappte Version Ihres Datensatzes! Um die Einfachheit von MapReduce zu schätzen, sollten Sie sich darüber im Klaren sein, dass die hier durchgeführte Operation ziemlich einfach ist und keine intensiven Berechnungen erfordert.
- Mischen der zugeordneten Ergebnisse:
Sobald wir die letzten geordneten Paare von der Map()-Funktion erhalten, werden die Ergebnisse gemischt. Das bedeutet einfach, dass (Wort, Anzahl) Paare mit demselben Wort auf eine einzelne Maschine übertragen werden.
Nun, wenn Sie mit dem Programmieren vertraut sind, werden Sie feststellen, dass dies eine Grenze hat, bis zu der dies erreicht werden kann. Es gibt buchstäblich Milliarden von Wörtern und nur eine begrenzte Anzahl von Computern im Cluster. An dieser Stelle ist es wichtig zu beachten, dass die Shuffle-Phase nicht zwingend erforderlich ist, damit MapReduce funktioniert, sie macht das Reduce()-Skript einfach viel schneller, indem es Dinge in einer Reihenfolge anordnet. Nehmen wir fürs Erste einfach an, dass wir unsere Map-Ausgaben gemischt haben und nun alle Instanzen des Wortes „Hallo“ in einem einzigen Computer in Form eines geordneten Paars haben – (Hallo, n), wobei n die Anzahl der Male ist. hallo“ kam in einem bestimmten Buch vor.

- Schließlich die Phase Reduce():
Schließlich kommen wir zur letzten Phase – Reduce(). Wenn Sie auf den gesamten Arbeitsablauf geachtet haben, haben Sie vielleicht richtig vermutet, dass Reduce() nur zählt, wie oft jedes Wort in der Eingabedatei vorkommt. Es muss lediglich die zweite Komponente unserer bestellten Paare hinzugefügt werden. Wenn das Wort „Hallo“ in allen Büchern beispielsweise 200 Mal erwähnt wird, ist die endgültige Ausgabe, die wir nach dieser Phase erhalten, – (Hallo, 200). Durch einfaches Zählen und Addieren kommen wir zum Ergebnis. All dies wurde durch den Einsatz einer Reihe von Computern und deren gleichzeitige Arbeit ermöglicht.
MapReduce SWOT-Analyse
Das MapReduce -Paradigma hat das Leben von Datenwissenschaftlern einfacher gemacht. Werfen wir einen Blick auf die Stärken, Schwächen, Chancen und Risiken dieses Frameworks:
| Stärken | Verarbeitet riesige Datensätze blitzschnell, indem sie parallel in verteilten Clustern verarbeitet werden. |
| Schwächen | Die Map()- und Reduce()-Skripte werden nacheinander ausgeführt. Lese-/Schreibvorgänge werden auf HDFS ausgeführt, das im Vergleich langsam ist |
| Chancen | Gewinnung von Erkenntnissen aus zuvor verworfenen Datensätzen und Verarbeitung von Big Data, die von Organisationen generiert wurden. |
| Bedrohungen | Eigenständige MapReduce -Operationen könnten das Tempo der Big-Data-Branche ohne ausreichende Fortschritte in der Analyse verlangsamen. |
Abschließend…
Nachdem Sie nun mit dem Innenleben von MapReduce vertraut sind , werden Sie erkennen, dass es sich keineswegs um eine neue Technologie handelt – wir verwenden seit sehr langer Zeit ähnliche Paradigmen, um große Datenmengen wie Wahlergebnisse zu verarbeiten jetzt. Sie werden auch erkennen, wie wichtig es ist, die Dinge einfach zu halten – MapReduce macht überhaupt nichts Besonderes, und das macht es so leistungsfähig.
Wenn Sie mehr über Big Data erfahren möchten, schauen Sie sich unser PG Diploma in Software Development Specialization in Big Data-Programm an, das für Berufstätige konzipiert ist und mehr als 7 Fallstudien und Projekte bietet, 14 Programmiersprachen und Tools abdeckt und praktische praktische Übungen enthält Workshops, mehr als 400 Stunden gründliches Lernen und Unterstützung bei der Stellenvermittlung bei Top-Unternehmen.
Lernen Sie Software-Engineering-Abschlüsse online von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.