Una guida per autostoppisti a MapReduce
Pubblicato: 2018-02-05Se hai letto il nostro articolo sugli strumenti e le tecnologie per i big data, potresti ricordare di esserti imbattuto nel termine " MapReduce ". È uno dei componenti principali dell'architettura Hadoop e costituisce l'intero livello di elaborazione di Hadoop.
In questo articolo parleremo di MapReduce in modo un po' più approfondito, ma in un modo adatto ai principianti. Per facilità di comprensione, abbiamo suddiviso l'articolo come segue: 
- introduzione
- Concetti principali
- Un'analisi SWOT completa
Introduzione a MapReduce
MapReduce è essenzialmente un concetto che consente l'elaborazione fulminea di enormi set di dati su un cluster distribuito. È un modello di programmazione brevettato da Google che è stato adottato per la prima volta dai ragazzi di Apache ed è ora al centro dell'intero ecosistema Hadoop. La sua semplicità è ciò che lo rende così efficace e lodevole.
MapReduce segue una logica molto semplice, che è stata seguita per anni per la gestione delle attività quotidiane: quando hai a che fare con molto materiale, l'assunzione di un gran numero di lavoratori accelererà il processo (l'antico adagio "anche molti cuochi rovinano il brodo” non sta bene qui!).
Tuttavia, a questo punto, sorge una domanda: MapReduce funziona bene SOLO con enormi set di dati?
La risposta è molto semplice: i set di dati non devono necessariamente essere estremamente grandi. Tuttavia, per motivi economici e computazionali, si consiglia di far funzionare MapReduce solo se si dispone di set di dati di grandi dimensioni, sufficientemente grandi per i calcoli tradizionali. È sempre meglio elaborare piccoli set di dati sulla tua macchina locale stessa, com'era prima dell'introduzione di MapReduce . Perché onestamente, usare MapReduce per piccoli blocchi di dati è molto simile a cercare di uccidere un ragno usando una mitragliatrice. Il ragno verrà ucciso, senza dubbio, ma ne vale la pena?

I concetti fondamentali di MapReduce
Ormai, hai una buona idea di cosa sia esattamente MapReduce. In questa sezione parleremo un po' di più di come funziona esattamente MapReduce : i concetti fondamentali che mettono in moto le ruote.
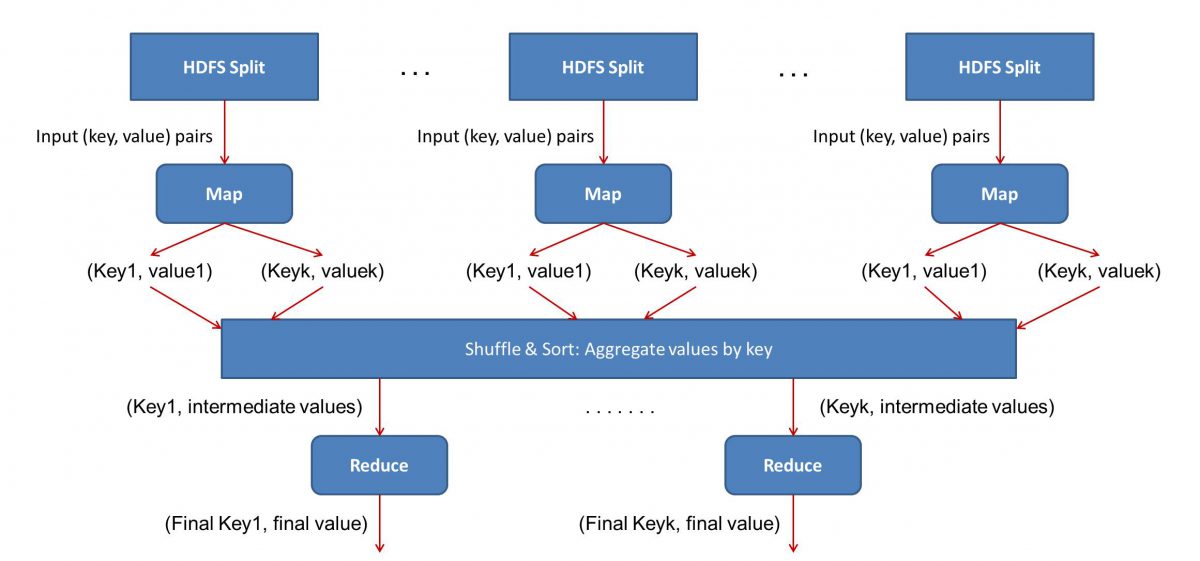
Se hai mai incontrato matematica di base nella tua vita (cosa che speriamo tu abbia se stai leggendo questo!), devi essere consapevole dei concetti di "coppie ordinate". È semplicemente un modo per esprimere due dati in forma (x,y). Le coppie ordinate sono molto utili per rappresentare coordinate, frazioni, ID dipendenti e altre forme di dati simili. Anche MapReduce si basa fortemente sul concetto di coppie ordinate: in pratica, qualsiasi dato può essere "mappato" nella forma di una coppia ordinata e può essere "ridotto" in vari modi, a seconda dell'affermazione del problema a portata di mano.
Supponiamo di essere lasciato solo in una biblioteca digitale contenente centomila libri e di avere l'arduo compito di trovare il numero di volte in cui una parola particolare ricorre in tutti i libri messi insieme .
Uff, come inizieresti?
Il primo approccio sarebbe scrivere un programma che itera su ogni parola, direttamente dal Libro 1 – Parola 1, al Libro n – Parola n, e continuare a incrementare una variabile contatore ogni volta che incontri la parola necessaria. Il solo fatto di immaginare questo ti farebbe capire quanto tempo ci vorrà per portare a termine questo compito.
Ora, diamo un'occhiata a come MapReduce risponderà all'attività:
- Requisiti di MapReduce:
MapReduce funziona bene in un cluster distribuito. Che cos'è un cluster distribuito, chiedi?
Molto semplicemente, si tratta di un gran numero (spesso migliaia!) di computer di base (computer a basso costo) intrecciati in una rete che esegue una singola operazione.
Ora, supponi di avere uno di questi cluster. Per la nostra affermazione del problema, l'input di questo cluster sarà il contenuto di tutti i libri. Non appena inseriamo questi dati nel nostro sistema, questi vengono copiati in ogni computer (nodo) del cluster (supponendo che al momento abbiamo a che fare con un solo lavoro). Questo viene fatto per fornire un livello di tolleranza agli errori, per aiutarti in caso di perdita di dati.
- Programmazione in MapReduce
Poiché MapReduce funziona in due fasi – Mappa e riduci, dobbiamo scrivere due programmi, Map() e Reduce(), per ottenere un flusso di lavoro MapReduce attivo e funzionante. In precedenza si usava Java per scrivere questi programmi, ma ora a causa della rapida crescita di Data Science, il framework MapReduce è stato reso sufficientemente flessibile da gestire anche codici scritti in Python o R.
Gli script che scrivi verranno eseguiti uno dopo l'altro, ovvero in modo successivo. Questo ci porta a uno dei principali svantaggi del paradigma MapReduce : il fatto che non è possibile eseguire entrambi gli script in parallelo. Il raggiungimento di ciò renderà MapReduc molto più veloce e questo è stato oggetto di ricerche approfondite.

- Parallelizzazione del flusso di lavoro:
L'input (contenuto di tutti i libri) sarà suddiviso in vari segmenti (pari al numero di computer del cluster, in sostanza) e ad ogni computer verrà assegnato un segmento particolare. Supponiamo di aver diviso il file in base a righe, quindi al nodo 1 potrebbe essere chiesto di occuparsi delle righe da 1 a 10.000, al nodo 2 potrebbe essere richiesto da 10.001 a 20.000 e così via. (Ricorda che queste sono solo cifre illustrative: i segmenti sono molto più grandi nella vita reale)
Ogni macchina eseguirà quindi il tuo programma Map().
- Il programma Map():
Il programma Map() fa esattamente quello che stavi per fare prima di affidare il compito a MapReduce : scansionare il file e leggere una parola alla volta. Il vantaggio qui è che verrà eseguito contemporaneamente su più computer, quindi ridurrà il tempo di molte varietà. L'output della funzione Map() è una coppia ordinata. In questo caso, sarà semplicemente (parola, conteggio), cioè quando la funzione Map() incontra la parola "ciao" (supponendo che sia la parola che stiamo cercando), verrà semplicemente espulsa (ciao, 1) come produzione. Poiché si stanno lavorando contemporaneamente su varie parti del corpo del codice, avrai una versione mappata del tuo set di dati in pochissimo tempo! Per apprezzare la semplicità di MapReduce , rendersi conto che l'operazione eseguita qui è abbastanza semplice e non richiede calcoli intensivi.
- Mescolare i risultati mappati:
Una volta ottenute le coppie ordinate finali dalla funzione Map(), i risultati vengono mescolati. Ciò significa semplicemente che le coppie (parola, conteggio) con la stessa parola vengono trasferite su una singola macchina.
Ora, se hai familiarità con la programmazione, ti renderai conto che c'è un limite al quale questo può essere raggiunto. Ci sono letteralmente miliardi di parole e solo un numero limitato di computer nel cluster. A questo punto, è importante notare che la fase di shuffle non è obbligatoria per il funzionamento di MapReduce , semplicemente rende lo script Reduce() molto più veloce disponendo le cose in un ordine. Per ora, diciamo solo che abbiamo mescolato i nostri output della mappa e ora abbiamo tutte le istanze della parola "ciao" in un singolo computer sotto forma di una coppia ordinata - (ciao, n) dove n è il numero di volte " ciao" si è verificato in un libro particolare.

- Infine, la fase Reduce():
Infine, arriviamo all'ultima fase: Reduce(). Se stavi prestando attenzione all'intero flusso di lavoro, potresti aver indovinato correttamente che Reduce() conterà solo il numero di volte in cui ogni parola appare nel file di input. Tutto quello che deve fare è semplicemente aggiungere il secondo componente delle nostre paia ordinate. Se ci sono, diciamo, 200 menzioni della parola "ciao" in tutti i libri, l'output finale che otterremo dopo questa fase sarà – (ciao, 200). Solo con un semplice conteggio e addizione, siamo arrivati al risultato. Il tutto grazie all'impiego di più computer e al loro funzionamento simultaneo.
Analisi SWOT MapReduce
Il paradigma MapReduce ha semplificato la vita dei data scientist. Diamo un'occhiata a quali sono i punti di forza, di debolezza, le opportunità e le minacce di questo framework:
| Punti di forza | Elabora enormi set di dati a velocità fulminea elaborandoli parallelamente in cluster distribuiti. |
| Debolezze | Gli script Map() e Reduce() vengono eseguiti in successione. Le operazioni di lettura/scrittura vengono eseguite su HDFS, che in confronto è lento |
| Opportunità | Generazione di insight da precedenti set di dati scartati ed elaborazione di Big Data generati dalle organizzazioni. |
| Minacce | Le operazioni standalone di MapReduce potrebbero rallentare il ritmo del settore dei Big Data senza un sufficiente progresso nell'analisi. |
In conclusione…
Ora che hai familiarità con il funzionamento interno di MapReduce , apprezzerai che non è affatto una nuova tecnologia: utilizziamo paradigmi simili per gestire grandi volumi di dati, come i risultati elettorali, da molto tempo adesso. Ti renderai conto anche dell'importanza di mantenere le cose semplici: MapReduce non ha niente di speciale, ed è questo che lo rende così potente.
Se sei interessato a saperne di più sui Big Data, dai un'occhiata al nostro PG Diploma in Software Development Specialization nel programma Big Data, progettato per professionisti che lavorano e fornisce oltre 7 casi di studio e progetti, copre 14 linguaggi e strumenti di programmazione, pratiche pratiche workshop, oltre 400 ore di apprendimento rigoroso e assistenza all'inserimento lavorativo con le migliori aziende.
Impara le lauree in ingegneria del software online dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.