Un ghid pentru autostopul pentru MapReduce
Publicat: 2018-02-05Dacă ați citit articolul nostru despre Instrumentele și tehnologiile pentru Big Data, s-ar putea să vă amintiți că ați întâlnit termenul „ MapReduce ”. Este una dintre componentele de bază ale arhitecturii Hadoop și formează întregul strat de procesare al Hadoop.
În acest articol, vom vorbi despre MapReduce mai în profunzime – dar într-un mod prietenos pentru începători. Pentru a vă ușura înțelegerea, am defalcat articolul după cum urmează: 
- Introducere
- Concepte de baza
- O analiză SWOT completă
Introducere în MapReduce
MapReduce este, în esență, un concept care permite procesarea rapidă a seturilor de date masive pe un cluster distribuit. Este un model de programare brevetat de Google care a fost adoptat pentru prima dată de băieții de la Apache și acum se află în centrul întregului ecosistem Hadoop. Simplitatea sa este ceea ce îl face atât de eficient și lăudabil.
MapReduce urmează o logică foarte simplă, una care a fost urmată de secole pentru gestionarea sarcinilor de zi cu zi – atunci când trebuie să aveți de-a face cu o mulțime de materiale, angajarea unui număr mare de lucrători va accelera procesul (vechea zicală „de asemenea mulți bucătari strică bulionul” nu se potrivește aici!).
Cu toate acestea, în acest moment, apare o întrebare – MapReduce funcționează bine NUMAI cu seturi de date uriașe?
Răspunsul la aceasta este foarte simplu – seturile de date nu trebuie să fie neapărat extrem de mari. Cu toate acestea, din motive economice și de calcul, este recomandat să puneți MapReduce să funcționeze numai dacă aveți seturi de date mari, suficient de mari pentru calculele tradiționale. Este întotdeauna mai bine să procesați seturi de date mici pe mașina dvs. locală, așa cum era înainte de introducerea MapReduce . Pentru că, sincer, folosirea MapReduce pentru bucăți mici de date este foarte asemănătoare cu încercarea de a ucide un păianjen folosind o mitralieră. Păianjenul va fi ucis, fără îndoială, dar merită?

Conceptele de bază ale MapReduce
Până acum, aveți o idee corectă despre ce este exact MapReduce. În această secțiune, vom vorbi mai multe despre cum funcționează exact MapReduce – conceptele de bază care pun roțile în mișcare.
Dacă ai întâlnit vreodată matematică de bază în viața ta (ceea ce sperăm să o ai dacă citești asta!), trebuie să fii conștient de conceptele de „perechi ordonate”. Este pur și simplu o modalitate de a exprima două date în formă (x,y). Perechile ordonate sunt foarte utile pentru a reprezenta coordonatele, fracțiile, ID-urile angajaților și alte forme similare de date. MapReduce, de asemenea, se bazează în mare măsură pe conceptul de perechi ordonate – practic, orice date poate fi „mapată” sub forma unei perechi ordonate și poate fi „redusă” într-o varietate de moduri, în funcție de declarația problemei la îndemână.
Să presupunem că ești lăsat singur într-o bibliotecă digitală care conține o sută de mii de cărți și i s-a dat o sarcină descurajantă de a afla de câte ori apare un anumit cuvânt în toate cărțile combinate .
Puff, cum ai începe?
Prima abordare ar fi să scrieți un program care să itereze peste fiecare cuvânt, chiar de la Cartea 1 – Cuvântul 1, la Cartea n – Cuvântul n, și să continuați să incrementați o variabilă contor de fiecare dată când întâlniți cuvântul necesar. Doar imaginarea acestui lucru te-ar face să realizezi cât de timp va dura pentru a îndeplini această sarcină.
Acum, să aruncăm o privire la modul în care MapReduce va răspunde la sarcină:
- Cerințe MapReduce:
MapReduce funcționează bine într-un cluster distribuit. Ce este un cluster distribuit, vă întrebați?
Foarte simplu, este un număr mare (adesea mii!) de computere de bază (calculatoare low-cost) împletite într-o rețea care efectuează o singură operațiune.
Acum, să presupunem că aveți un astfel de cluster. Pentru declarația noastră de problemă, intrarea în acest cluster va fi conținutul tuturor cărților. De îndată ce introducem aceste date în sistemul nostru, acestea sunt copiate în fiecare computer (nod) din cluster (presupunând că avem de-a face cu o singură lucrare în acest moment). Acest lucru se face pentru a oferi un nivel de toleranță la erori – pentru a vă ajuta în caz de pierdere a datelor.
- Programare în MapReduce
Deoarece MapReduce funcționează în două faze - MapReduce și reduce, trebuie să scriem două programe, Map() și Reduce(), pentru a pune în funcțiune un flux de lucru MapReduce . Mai devreme ați folosit Java pentru a scrie aceste programe, dar acum, din cauza creșterii rapide în Data Science, cadrul MapReduce a fost suficient de flexibil pentru a gestiona codurile scrise și în Python sau R.
Scripturile pe care le scrieți se vor rula unul după altul, adică într-o manieră succesivă. Acest lucru ne aduce la unul dintre dezavantajele majore ale paradigmei MapReduce - faptul că nu puteți rula ambele scripturi în paralel. Realizarea acestui lucru va face MapReduc mult mai rapid și acesta a fost subiect de cercetări ample.

- Paralelizarea fluxului de lucru:
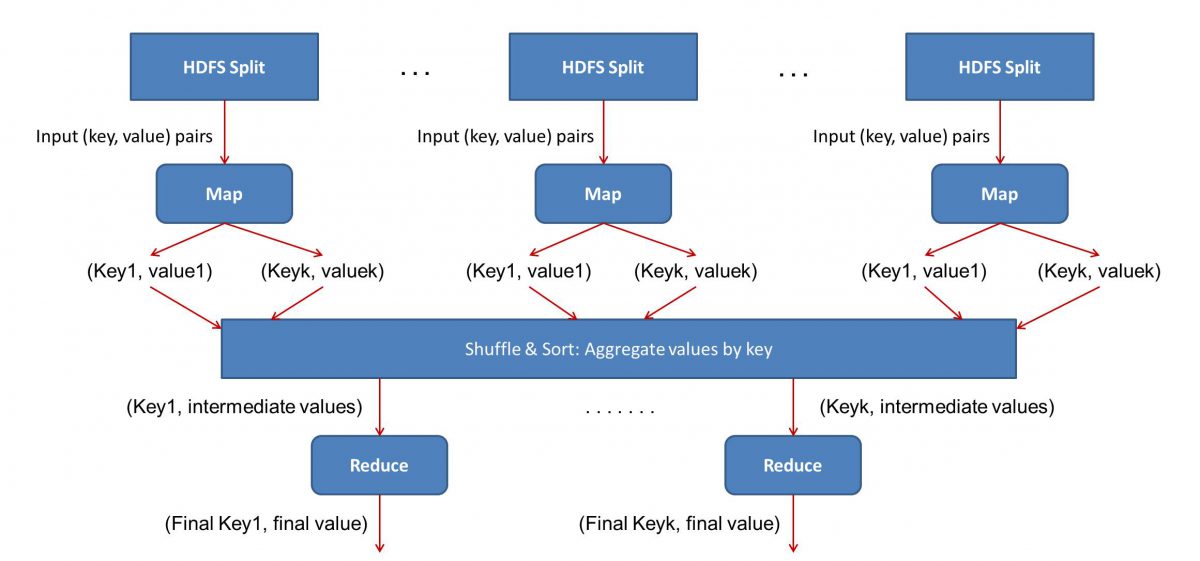
Intrarea (conținutul tuturor cărților) va fi împărțită în diferite segmente (egal cu numărul de computere din cluster, în esență), și fiecărui computer i se va atribui un anumit segment. Să presupunem că am împărțit fișierul în funcție de linii, atunci nodului 1 i se poate cere să aibă grijă de liniile de la 1 la 10.000, nodul 2 ar putea fi solicitat de la 10.001 la 20.000 și așa mai departe. (Rețineți că acestea sunt doar cifre ilustrative – segmentele sunt mult mai mari în viața reală)
Fiecare mașină va rula apoi programul dvs. Map().
- Programul Map():
Programul Map() face exact ceea ce urma să faci înainte de a da sarcina lui MapReduce – scanează fișierul și citește câte un cuvânt. Avantajul aici este că va rula simultan pe mai multe computere, așa că va reduce timpul cu mai multe. Ieșirea funcției Map() este o pereche ordonată. În acest caz, va fi pur și simplu (cuvânt, număr), adică atunci când funcția Map() întâlnește cuvântul „bună ziua” (presupunând că acesta este cuvântul pe care îl căutăm), pur și simplu va ejecta (bună ziua, 1) ca un ieșire. Deoarece se lucrează la diferite părți ale corpului codului în același timp, veți avea o versiune mapată a setului de date în cel mai scurt timp! Pentru a aprecia simplitatea MapReduce , realizați că operațiunea efectuată aici este destul de simplă și nu necesită calcule intensive.
- Amestecarea rezultatelor mapate:
Odată ce obținem perechile ordonate finale din funcția Map(), rezultatele sunt amestecate. Aceasta înseamnă pur și simplu că perechile (cuvânt, număr) cu același cuvânt sunt transferate la o singură mașină.
Acum, dacă sunteți familiarizat cu programarea, vă veți da seama că există o limită până la care acest lucru poate fi atins. Există literalmente miliarde de cuvinte și doar un număr finit de computere în cluster. În acest moment, este important să rețineți că faza de amestecare nu este obligatorie pentru ca MapReduce să funcționeze, pur și simplu face scriptul Reduce() mult mai rapid prin aranjarea lucrurilor într-o ordine. Deocamdată, să spunem doar că ne-am amestecat ieșirile Hartă și acum avem toate instanțele cuvântului „bună ziua” într-un singur computer sub forma unei perechi ordonate – (bună ziua, n) unde n este numărul de ori „ salut” a apărut într-o anumită carte.

- În cele din urmă, faza Reduce():
În cele din urmă, ajungem la ultima fază – Reduce(). Dacă ați acordat atenție întregului flux de lucru, poate ați ghicit corect că Reduce() va număra doar de câte ori apare fiecare cuvânt în fișierul de intrare. Tot ce trebuie să facă este să adauge pur și simplu a doua componentă a perechilor noastre ordonate. Dacă există, să spunem 200 de mențiuni ale cuvântului „bună ziua” în toate cărțile, rezultatul final pe care îl vom obține după această fază va fi – (bună ziua, 200). Doar prin simpla numărare și adăugare, am ajuns la rezultat. Toate sunt posibile prin folosirea unui număr de computere și făcându-le să funcționeze simultan.
Analiza SWOT MapReduce
Paradigma MapReduce a ușurat viața oamenilor de știință în domeniul datelor. Să aruncăm o privire la care sunt punctele forte, punctele slabe, oportunitățile și amenințările acestui cadru:
| Puncte forte | Procesează seturi de date masive la viteze fulgerătoare, procesându-le paralel în clustere distribuite. |
| Puncte slabe | Scripturile Map() și Reduce() rulează succesiv. Operațiile de citire/scriere sunt efectuate pe HDFS, care este lent prin comparație |
| Oportunități | Generarea de informații din seturi anterioare de date aruncate și procesarea Big Data generate de organizații. |
| Amenințări | Operațiunile autonome MapReduce ar putea încetini ritmul industriei Big Data fără un avans suficient în analiză. |
În concluzie…
Acum că sunteți familiarizat cu funcționarea interioară a MapReduce , veți aprecia că nu este deloc o tehnologie nouă - am folosit paradigme similare pentru a gestiona un volum mare de date, cum ar fi rezultatele alegerilor, de foarte mult timp. acum. Veți realiza, de asemenea, importanța de a menține lucrurile simple – MapReduce nu face deloc fantezie și asta este ceea ce îl face atât de puternic.
Dacă sunteți interesat să aflați mai multe despre Big Data, consultați programul nostru PG Diploma în Dezvoltare Software Specializare în Big Data, care este conceput pentru profesioniști care lucrează și oferă peste 7 studii de caz și proiecte, acoperă 14 limbaje și instrumente de programare, practică practică. ateliere de lucru, peste 400 de ore de învățare riguroasă și asistență pentru plasarea unui loc de muncă cu firme de top.
Învață diplome de Inginerie software online de la cele mai bune universități din lume. Câștigă programe Executive PG, programe avansate de certificat sau programe de master pentru a-ți accelera cariera.