Panduan Hitchhiker untuk MapReduce
Diterbitkan: 2018-02-05Jika Anda telah membaca artikel kami tentang Alat dan Teknologi Big Data, Anda mungkin ingat pernah menemukan istilah “ MapReduce ”. Ini adalah salah satu komponen inti dari arsitektur Hadoop dan membentuk seluruh lapisan pemrosesan Hadoop.
Dalam artikel ini, kita akan berbicara tentang MapReduce sedikit lebih dalam – tetapi dengan cara yang ramah bagi pemula. Untuk kemudahan pemahaman Anda, kami telah memecah artikel sebagai berikut: 
- pengantar
- Konsep inti
- Analisis SWOT Lengkap
Pengantar MapReduce
MapReduce pada dasarnya adalah sebuah konsep yang memungkinkan pemrosesan secepat kilat dari kumpulan data besar-besaran pada cluster terdistribusi. Ini adalah model pemrograman yang dipatenkan oleh Google yang pertama kali diadopsi oleh orang-orang di Apache dan sekarang menjadi jantung dari seluruh ekosistem Hadoop. Kesederhanaannya adalah apa yang membuatnya begitu efektif dan terpuji.
MapReduce mengikuti logika yang sangat sederhana, yang telah diikuti selama berabad-abad untuk mengelola tugas sehari-hari – ketika Anda harus berurusan dengan banyak materi, mempekerjakan sejumlah besar pekerja akan mempercepat proses (pepatah kuno “terlalu banyak juru masak merusak kaldu” tidak cocok di sini!).
Namun, pada titik ini, muncul satu pertanyaan – apakah MapReduce bekerja dengan baik HANYA dengan kumpulan data yang besar?
Jawabannya sangat sederhana – kumpulan data tidak perlu terlalu besar. Namun, karena alasan ekonomi dan komputasi, disarankan agar MapReduce hanya berfungsi jika Anda memiliki kumpulan data besar, cukup besar untuk komputasi tradisional. Selalu lebih baik untuk memproses kumpulan data kecil di mesin lokal Anda sendiri – seperti sebelum MapReduce diperkenalkan. Karena sejujurnya, menggunakan MapReduce untuk potongan kecil data sangat mirip dengan mencoba membunuh laba-laba menggunakan senapan mesin. Laba-laba akan terbunuh, tidak diragukan lagi, tetapi apakah itu sepadan?

Konsep Inti MapReduce
Sekarang, Anda memiliki gagasan yang adil tentang apa sebenarnya MapReduce. Di bagian ini, kita akan berbicara lebih banyak tentang bagaimana tepatnya MapReduce bekerja – konsep inti yang menggerakkan roda.
Jika Anda pernah menemukan matematika dasar dalam hidup Anda (yang kami harap Anda miliki jika Anda membaca ini!), Anda harus menyadari konsep "pasangan berurutan". Ini hanyalah cara untuk mengekspresikan dua bagian data dalam bentuk (x,y). Pasangan berurutan sangat berguna untuk mewakili koordinat, pecahan, ID karyawan, dan bentuk data serupa lainnya. MapReduce juga sangat bergantung pada konsep pasangan terurut – pada dasarnya, semua data dapat “dipetakan” ke dalam bentuk pasangan terurut, dan dapat “direduksi” dalam berbagai cara, tergantung pada pernyataan masalah yang dihadapi.
Misalkan Anda ditinggalkan sendirian di perpustakaan digital yang berisi seratus ribu buku dan diberi tugas berat untuk menemukan berapa kali kata tertentu muncul di semua buku yang digabungkan .
Fiuh, bagaimana Anda akan memulai?
Pendekatan pertama adalah menulis program yang akan mengulang setiap kata, langsung dari Buku 1 – Kata 1, ke Buku n – Kata n, dan terus menambahkan variabel penghitung setiap kali Anda menemukan kata yang dibutuhkan. Hanya membayangkan ini akan membuat Anda menyadari jumlah waktu yang diperlukan untuk menyelesaikan tugas ini.
Sekarang, mari kita lihat bagaimana MapReduce akan merespons tugas:
- Persyaratan MapReduce:
MapReduce bekerja dengan baik di cluster terdistribusi. Apa itu cluster terdistribusi, Anda bertanya?
Sangat sederhana, ini adalah sejumlah besar (seringkali ribuan!) komputer komoditas (komputer berbiaya rendah) terjalin ke dalam jaringan yang melakukan satu operasi.
Sekarang, anggap Anda memiliki satu cluster seperti itu. Untuk rumusan masalah kami, input ke cluster ini akan menjadi konten semua buku. Segera setelah kami memasukkan data ini ke dalam sistem kami, itu akan disalin ke setiap komputer (simpul) di cluster (dengan asumsi kami hanya berurusan dengan satu pekerjaan saat ini). Ini dilakukan untuk memberikan tingkat toleransi kesalahan – untuk membantu Anda jika terjadi kehilangan data.
- Pemrograman Dalam MapReduce
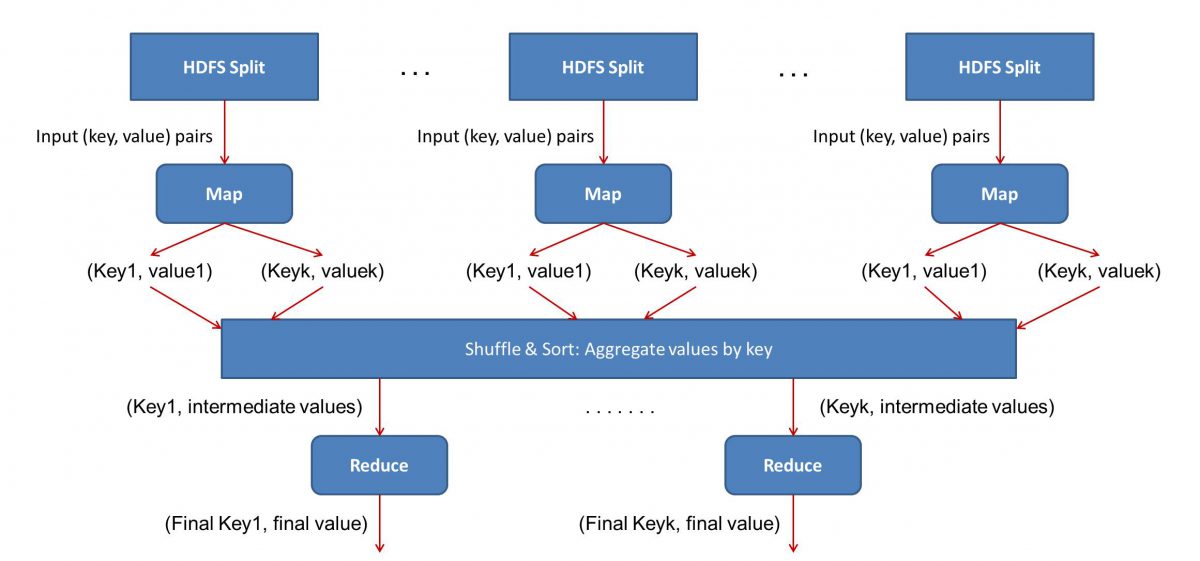
Karena MapReduce bekerja dalam dua fase – Map dan Reduce, kita harus menulis dua program, Map() dan Reduce(), untuk mengaktifkan dan menjalankan alur kerja MapReduce . Sebelumnya Anda telah menggunakan Java untuk menulis program ini, tetapi sekarang karena pertumbuhan pesat dalam Ilmu Data, kerangka kerja MapReduce telah dibuat cukup fleksibel untuk menangani kode yang ditulis dengan Python atau R juga.
Skrip yang Anda tulis akan berjalan satu demi satu, yaitu secara berurutan. Ini membawa kita ke salah satu kelemahan utama dari paradigma MapReduce – fakta bahwa Anda tidak dapat menjalankan kedua skrip secara paralel. Mencapai itu akan membuat MapReduc bekerja lebih cepat, dan itu telah menjadi subjek penelitian yang ekstensif.

- Paralelisasi alur kerja:
Input (isi dari semua buku) akan dibagi menjadi berbagai segmen (sama dengan jumlah komputer dalam cluster, pada dasarnya), dan setiap komputer akan diberikan segmen tertentu. Misalkan kita telah membagi file berdasarkan baris, maka node 1 mungkin diminta untuk mengurus baris 1 hingga 10.000, node 2 mungkin akan diminta seperti 10.000 hingga 20.000, dan seterusnya. (Ingat ini hanya figur ilustratif – segmennya jauh lebih besar dalam kehidupan nyata)
Setiap mesin kemudian akan menjalankan program Map() Anda.
- Program Peta():
Program Map() melakukan persis seperti yang akan Anda lakukan sebelum memberikan tugas ke MapReduce – memindai file dan membaca satu kata dalam satu waktu. Manfaatnya di sini adalah bahwa itu akan berjalan secara bersamaan di banyak komputer, sehingga akan mengurangi waktu dengan berlipat ganda. Output dari fungsi Map() adalah pasangan terurut. Dalam hal ini, itu hanya akan menjadi (kata, hitungan), yaitu ketika fungsi Map() menemukan kata "halo" (dengan asumsi itu adalah kata yang kita cari), itu hanya akan mengeluarkan (halo, 1) sebagai keluaran. Karena berbagai bagian dari badan kode sedang dikerjakan secara bersamaan, Anda akan segera memiliki versi peta dari kumpulan data Anda! Untuk menghargai kesederhanaan MapReduce , sadari bahwa operasi yang dilakukan di sini cukup mendasar tanpa memerlukan perhitungan yang intensif.
- Pengacakan hasil yang Dipetakan:
Setelah kita mendapatkan pasangan terurut terakhir dari fungsi Map(), hasilnya diacak. Itu berarti bahwa pasangan (kata, hitungan) dengan kata yang sama ditransfer ke satu mesin.
Sekarang, jika Anda mengenal pemrograman, Anda akan menyadari bahwa ada batas untuk mencapainya. Ada miliaran kata dan hanya sejumlah komputer yang terbatas dalam cluster. Pada titik ini, penting untuk dicatat bahwa fase acak tidak wajib untuk MapReduce berfungsi, itu hanya membuat skrip Reduce() lebih cepat dengan mengatur berbagai hal dalam urutan. Untuk saat ini, katakan saja kita mengacak output Peta kita, dan sekarang memiliki semua instance dari kata "halo" di satu komputer dalam bentuk pasangan terurut – (halo, n) di mana n adalah berapa kali “ halo” terjadi dalam satu buku tertentu.

- Akhirnya, fase Reduce():
Akhirnya, kita sampai pada fase terakhir – Reduce(). Jika Anda memperhatikan seluruh alur kerja, Anda mungkin telah menebak dengan benar bahwa Reduce() hanya akan menghitung berapa kali setiap kata muncul di file input. Yang harus dilakukan hanyalah menambahkan komponen kedua dari pasangan terurut kita. Jika ada, katakanlah 200 penyebutan kata "halo" di semua buku, hasil akhir yang akan kita dapatkan setelah fase ini adalah – (halo, 200). Hanya dengan menghitung dan menjumlahkan, kita telah sampai pada hasilnya. Semua dimungkinkan dengan menggunakan sejumlah komputer dan membuatnya bekerja secara bersamaan.
Analisis SWOT MapReduce
Paradigma MapReduce telah membuat kehidupan Ilmuwan Data lebih mudah. Mari kita lihat apa saja kekuatan, kelemahan, peluang, dan ancaman dari kerangka kerja ini:
| Kekuatan | Memproses kumpulan data besar dengan kecepatan kilat dengan memprosesnya secara paralel dalam klaster terdistribusi. |
| Kelemahan | Skrip Map() dan Reduce() dijalankan secara berurutan. Operasi Baca/Tulis dilakukan pada HDFS, yang lambat jika dibandingkan |
| Peluang | Menghasilkan wawasan dari kumpulan data yang dibuang sebelumnya dan memproses Big Data yang dihasilkan oleh organisasi. |
| Ancaman | Operasi MapReduce yang berdiri sendiri dapat memperlambat laju industri Big Data tanpa kemajuan analitik yang memadai. |
Kesimpulannya…
Sekarang setelah Anda terbiasa dengan cara kerja MapReduce , Anda akan menyadari bahwa ini sama sekali bukan teknologi baru – kami telah menggunakan paradigma serupa untuk menangani volume data yang besar, seperti hasil pemilu, untuk waktu yang sangat lama sekarang. Anda juga akan menyadari pentingnya menjaga hal-hal sederhana – MapReduce tidak ada yang mewah, sama sekali, dan itulah yang membuatnya begitu kuat.
Jika Anda tertarik untuk mengetahui lebih banyak tentang Big Data, lihat Diploma PG kami dalam Spesialisasi Pengembangan Perangkat Lunak dalam program Big Data yang dirancang untuk para profesional yang bekerja dan menyediakan 7+ studi kasus & proyek, mencakup 14 bahasa & alat pemrograman, praktik langsung lokakarya, lebih dari 400 jam pembelajaran yang ketat & bantuan penempatan kerja dengan perusahaan-perusahaan top.
Pelajari gelar Rekayasa Perangkat Lunak secara online dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karier Anda.