MapReduceのヒッチハイカーガイド
公開: 2018-02-05ビッグデータツールとテクノロジーに関する記事を読んだことがあれば、「 MapReduce 」という用語に出くわしたことを覚えているかもしれません。 これはHadoopアーキテクチャのコアコンポーネントの1つであり、Hadoopの処理レイヤー全体を形成します。
この記事では、 MapReduceについてもう少し詳しく説明しますが、初心者向けの方法です。 わかりやすくするために、記事を次のように分類しました。 
- 序章
- コアコンセプト
- 完全なSWOT分析
MapReduceの概要
MapReduceは本質的に、分散クラスター上の大規模なデータセットの超高速処理を可能にする概念です。 これはGoogleが特許を取得したプログラミングモデルであり、Apacheのメンバーによって最初に採用され、現在はHadoopエコシステム全体の中心となっています。 そのシンプルさがそれをとても効果的で称賛に値するものにしているのです。
MapReduceは非常に単純なロジックに従います。これは、日々のタスクを管理するために長年にわたって使用されてきたものです。大量の資料を処理する必要がある場合、多数のワーカーを採用すると、プロセスのペースが上がります(昔からの格言も多くの料理人がスープを台無しにします」はここに収まりません!)。
ただし、この時点で、1つの疑問が生じます。MapReduceは巨大なデータセットでのみうまく機能しますか?
これに対する答えは非常に単純です。データセットは必ずしも極端に大きい必要はありません。 ただし、経済的および計算上の理由から、従来の計算に十分な大きさの大きなデータセットがある場合にのみ、 MapReduceを機能させることをお勧めします。 MapReduceが導入される前と同じように、ローカルマシン自体で小さなデータセットを処理することをお勧めします。 正直なところ、データの小さなチャンクにMapReduceを使用することは、機関銃を使用してクモを殺そうとすることと非常によく似ています。 蜘蛛は間違いなく殺されるでしょうが、それだけの価値はありますか?

MapReduceのコアコンセプト
これで、 MapReduceとは正確に何であるかについての公正な考えが得られました。 このセクションでは、 MapReduceがどのように正確に機能するか、つまりホイールを動かすためのコアコンセプトについてもう少し説明します。
あなたが人生で基本的な数学に出会ったことがあるなら(これを読んでいるならあなたが持っていることを願っています!)、あなたは「順序対」の概念を知っている必要があります。 これは、2つのデータを(x、y)形式で表現する方法にすぎません。 順序対は、座標、分数、従業員ID、およびその他の同様の形式のデータを表すのに非常に役立ちます。 MapReduceも、順序対の概念に大きく依存しています。基本的に、任意のデータを順序対の形式に「マッピング」でき、目前の問題ステートメントに応じてさまざまな方法で「縮小」できます。
あなたが10万冊の本を含むデジタルライブラリに一人で残され、すべての本を合わせた特定の単語が出現する回数を見つけるという困難なタスクを与えられたとします。
ふぅ、どうやって始めますか?
最初のアプローチは、 Book 1 –Word1からBookn– Word nまで、すべての単語を反復処理するプログラムを作成し、必要な単語に遭遇するたびにカウンター変数をインクリメントし続けることです。 これを想像するだけで、このタスクを完了するのにかかる時間を理解できます。
それでは、 MapReduceがタスクにどのように応答するかを見てみましょう。
- MapReduceの要件:
MapReduceは、分散クラスターでうまく機能します。 分散クラスターとは何ですか?
非常に簡単に言えば、単一の操作を実行するネットワークに織り込まれた多数の(多くの場合数千の!)コモディティコンピューター(低コストのコンピューター)です。
ここで、そのようなクラスターが1つあると仮定します。 問題の説明では、このクラスターへの入力はすべての本の内容になります。 このデータをシステムにフィードするとすぐに、クラスター上のすべてのコンピューター(ノード)にコピーされます(現時点で1つのジョブのみを処理していると仮定します)。 これは、一定レベルのフォールトトレランスを提供するために行われます–データ損失の場合に役立ちます。
- MapReduceでのプログラミング
MapReduceはMapとreduceの2つのフェーズで機能するため、 MapReduceワークフローを稼働させるには、Map()とReduce()の2つのプログラムを作成する必要があります。 以前はJavaを使用してこれらのプログラムを記述していましたが、データサイエンスが急速に成長したため、 MapReduceフレームワークは、PythonまたはRで記述されたコードを処理するのに十分な柔軟性を備えています。
作成したスクリプトは、次々に、つまり連続して実行されます。 これにより、 MapReduceパラダイムの主な欠点の1つ、つまり両方のスクリプトを並行して実行できないという事実が発生します。 これを達成することで、 MapReducははるかに高速になり、これは広範な研究の対象となっています。

- ワークフローの並列化:
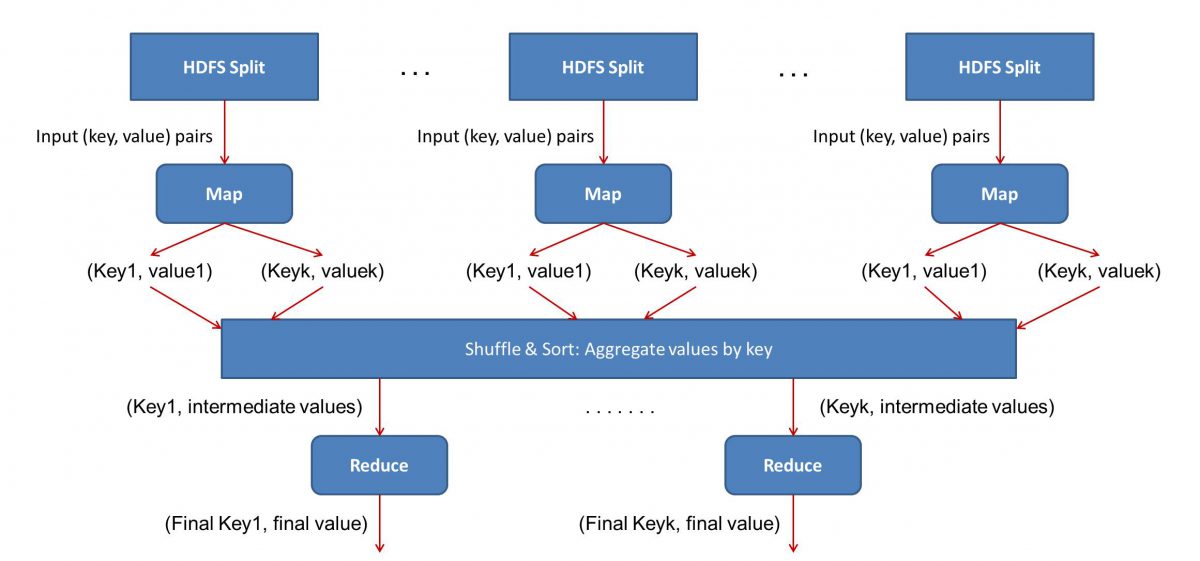
入力(すべての書籍の内容)はさまざまなセグメント(基本的にはクラスター内のコンピューターの数に等しい)に分割され、各コンピューターには特定のセグメントが割り当てられます。 ファイルを行に基づいて分割したとすると、ノード1は行1から10,000を処理するように要求され、ノード2は10,001から20,000のように要求される可能性があります。 (これらは単なる例示的な数値であることに注意してください。実際のセグメントははるかに大きくなっています)
その後、各マシンはMap()プログラムを実行します。
- Map()プログラム:
Map()プログラムは、 MapReduceにタスクを与える前に、ファイルをスキャンして一度に1つの単語を読み取る前に実行しようとしていたことを正確に実行します。 ここでの利点は、複数のコンピューターで同時に実行されるため、マニホールドによって時間が短縮されることです。 Map()関数の出力は、順序対です。 この場合、それは単に(word、count)になります。つまり、Map()関数が「hello」という単語に遭遇すると(それが私たちが探している単語であると仮定して)、単に(hello、1)を出力。 コード本体のさまざまな部分が同時に処理されているため、データセットのマップされたバージョンがすぐに作成されます。 MapReduceの単純さを理解するために、ここで実行される操作はかなり基本的なものであり、集中的な計算を必要としないことを理解してください。
- マップされた結果のシャッフル:
Map()関数から最終的な順序対を取得すると、結果がシャッフルされます。 これは単に、同じ単語を持つ(word、count)ペアが単一のマシンに転送されることを意味します。
さて、プログラミングに精通しているなら、これを達成できる限界があることに気付くでしょう。 クラスターには文字通り数十億の単語があり、コンピューターの数は限られています。 この時点で、シャッフルフェーズはMapReduceが機能するために必須ではないことに注意することが重要です。シャッフルフェーズは、物事を順番に並べることで、Reduce()スクリプトをはるかに高速にします。 今のところ、マップ出力をシャッフルし、順序対の形式で1台のコンピューターに「hello」という単語のすべてのインスタンスがあるとしましょう–(hello、n)ここで、nは「こんにちは」は、ある特定の本で発生しました。

- 最後に、Reduce()フェーズ:
最後に、最後のフェーズであるReduce()に進みます。 ワークフロー全体に注意を払っていた場合、Reduce()は各単語が入力ファイルに出現する回数をカウントするだけであると正しく推測したかもしれません。 必要なのは、順序対の2番目のコンポーネントを追加することだけです。 すべての本に「こんにちは」という単語が200件言及されている場合、このフェーズの後に得られる最終的な出力は–(こんにちは、200)になります。 単純なカウントと加算だけで、結果に到達しました。 多数のコンピューターを使用し、それらを同時に動作させることにより、すべてが可能になりました。
MapReduceSWOT分析
MapReduceパラダイムにより、データサイエンティストの生活が楽になりました。 このフレームワークの長所、短所、機会、脅威を見てみましょう。
| 強み | 大規模なデータセットを分散クラスターで並列処理することにより、非常に高速に処理します。 |
| 弱点 | Map()スクリプトとReduce()スクリプトは連続して実行されます。 読み取り/書き込み操作はHDFSで実行されますが、これは比較すると低速です。 |
| 機会 | 以前に破棄されたデータセットから洞察を生成し、組織によって生成されたビッグデータを処理します。 |
| 脅威 | スタンドアロンのMapReduce操作は、分析の十分な進歩なしにビッグデータ業界のペースを遅くする可能性があります。 |
結論は…
MapReduceの内部動作に精通しているので、これは決して新しいテクノロジーではないことを理解できます。私たちは、選挙結果などの大量のデータを非常に長い間処理するために同様のパラダイムを使用してきました。今。 また、物事をシンプルに保つことの重要性にも気付くでしょう。MapReduceは何も派手なことは何もしません。それが、 MapReduceを非常に強力なものにしているのです。
ビッグデータについて詳しく知りたい場合は、ビッグデータプログラムのソフトウェア開発スペシャライゼーションのPGディプロマをチェックしてください。このプログラムは、働く専門家向けに設計されており、7つ以上のケーススタディとプロジェクトを提供し、14のプログラミング言語とツール、実践的なハンズオンをカバーしています。ワークショップ、トップ企業との400時間以上の厳格な学習と就職支援。
世界のトップ大学からオンラインでソフトウェアエンジニアリングの学位を学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。