Przewodnik autostopowicza po MapReduce
Opublikowany: 2018-02-05Jeśli czytałeś nasz artykuł na temat narzędzi i technologii Big Data, być może pamiętasz, że natknąłeś się na termin „ MapReduce ”. Jest to jeden z podstawowych elementów architektury Hadoop i tworzy całą warstwę przetwarzania Hadoop.
W tym artykule omówimy MapReduce nieco bardziej szczegółowo – ale w sposób przyjazny dla początkujących. Aby ułatwić zrozumienie, artykuł podzieliliśmy w następujący sposób: 
- Wstęp
- Podstawowe pojęcia
- Pełna analiza SWOT
Wprowadzenie do MapReduce
MapReduce to zasadniczo koncepcja, która umożliwia błyskawiczne przetwarzanie ogromnych zestawów danych w rozproszonym klastrze. Jest to model programowania opatentowany przez Google, który po raz pierwszy został zaadaptowany przez chłopaków z Apache, a teraz jest sercem całego ekosystemu Hadoop. Jego prostota sprawia, że jest tak skuteczny i godny polecenia.
MapReduce kieruje się bardzo prostą logiką, taką, która była stosowana od wieków przy zarządzaniu codziennymi zadaniami – kiedy masz do czynienia z dużą ilością materiału, zatrudnienie dużej liczby pracowników przyspieszy proces (odwieczne powiedzenie „też wielu kucharzy psuje rosół” tu nie pasuje!).
Jednak w tym momencie pojawia się jedno pytanie – czy MapReduce działa dobrze TYLKO z ogromnymi zestawami danych?
Odpowiedź na to jest bardzo prosta — zbiory danych niekoniecznie muszą być bardzo duże. Jednak ze względów ekonomicznych i obliczeniowych zaleca się, aby MapReduce działał tylko wtedy, gdy masz duże zestawy danych, wystarczająco duże dla tradycyjnych obliczeń. Zawsze lepiej jest przetwarzać małe zestawy danych na komputerze lokalnym — tak jak było przed wprowadzeniem MapReduce . Szczerze mówiąc, używanie MapReduce do małych porcji danych jest bardzo podobne do próby zabicia pająka za pomocą karabinu maszynowego. Pająk bez wątpienia zostanie zabity, ale czy warto?

Podstawowe pojęcia MapReduce
Do tej pory masz dobre pojęcie o tym, czym dokładnie jest MapReduce. W tej sekcji omówimy nieco więcej o tym, jak dokładnie działa MapReduce — podstawowe koncepcje, które wprawiają koła w ruch.
Jeśli kiedykolwiek zetknąłeś się w swoim życiu z podstawową matematyką (którą mamy nadzieję, że masz, jeśli to czytasz!), musisz być świadomy pojęć „uporządkowanych par”. Jest to po prostu sposób wyrażenia dwóch części danych w formie (x,y). Pary uporządkowane są bardzo przydatne do przedstawiania współrzędnych, ułamków, identyfikatorów pracowników i innych podobnych form danych. MapReduce również w dużym stopniu opiera się na koncepcji par uporządkowanych – w zasadzie wszystkie dane można „zmapować” do postaci uporządkowanej pary i można je „zredukować” na różne sposoby, w zależności od opisu problemu.
Załóżmy, że zostajesz sam w bibliotece cyfrowej zawierającej sto tysięcy książek i masz przed sobą trudne zadanie znalezienia, ile razy dane słowo występuje we wszystkich połączonych książkach .
Uff, jak byś zaczął?
Pierwszym podejściem byłoby napisanie programu, który będzie iterował po każdym słowie, od Księgi 1 – Słowo 1 do Księgi n – Słowa n, i stale zwiększał zmienną licznika za każdym razem, gdy napotkasz potrzebne słowo. Samo wyobrażenie tego uświadomiłoby ci, ile czasu zajmie wykonanie tego zadania.
Przyjrzyjmy się teraz, jak MapReduce zareaguje na zadanie:
- Wymagania MapReduce:
MapReduce działa dobrze w klastrze rozproszonym. Pytasz, co to jest klaster rozproszony?
Mówiąc prościej, jest to duża liczba (często tysiące!) zwykłych komputerów (komputerów o niskich kosztach) wplecionych w sieć, która wykonuje pojedynczą operację.
Załóżmy teraz, że masz jeden taki klaster. W przypadku naszego opisu problemu danymi wejściowymi do tego skupienia będzie zawartość wszystkich książek. Gdy tylko wprowadzimy te dane do naszego systemu, zostaną one skopiowane do każdego komputera (węzła) w klastrze (zakładając, że w danej chwili mamy do czynienia tylko z jednym zadaniem). Ma to na celu zapewnienie poziomu odporności na awarie – aby pomóc w przypadku utraty danych.
- Programowanie w MapReduce
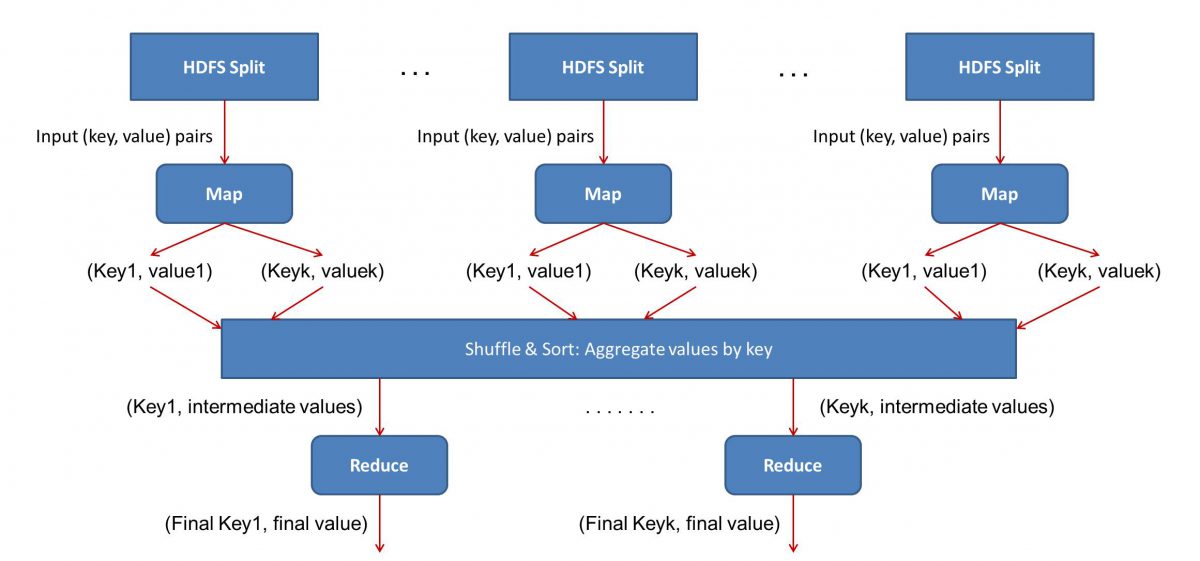
Ponieważ MapReduce działa w dwóch fazach — mapowania i zmniejszania, musimy napisać dwa programy, Map() i Reduce(), aby uruchomić przepływ pracy MapReduce . Wcześniej do pisania tych programów używałeś Javy, ale teraz, ze względu na szybki rozwój Data Science, framework MapReduce stał się wystarczająco elastyczny, aby obsługiwać kody napisane również w Pythonie lub R.
Skrypty, które napiszesz, będą uruchamiane jeden po drugim, czyli kolejno. To prowadzi nas do jednej z głównych wad paradygmatu MapReduce – faktu, że nie można równolegle uruchamiać obu skryptów. Osiągnięcie, które sprawi, że MapReduc będzie znacznie szybsze i było przedmiotem szeroko zakrojonych badań.

- Równoległość przepływu pracy:
Dane wejściowe (zawartość wszystkich książek) zostaną podzielone na różne segmenty (w zasadzie równe liczbie komputerów w klastrze), a każdemu komputerowi zostanie przypisany określony segment. Załóżmy, że podzieliliśmy plik na wiersze, a następnie węzeł 1 może zostać poproszony o zajęcie się wierszami od 1 do 10 000, węzeł 2 może zostać poproszony o od 10 001 do 20 000 i tak dalej. (Pamiętaj, że to tylko liczby ilustracyjne – w rzeczywistości segmenty są znacznie większe)
Każda maszyna uruchomi wtedy twój program Map().
- Program Map():
Program Map() robi dokładnie to, co miałeś zrobić przed przekazaniem zadania MapReduce — skanuje plik i czyta jedno słowo na raz. Zaletą jest to, że będzie działać jednocześnie na wielu komputerach, więc skróci czas o wiele. Wynikiem funkcji Map() jest uporządkowana para. W tym przypadku będzie to po prostu (word, count), tj. gdy funkcja Map() napotka słowo „hello” (zakładając, że tego szukamy), po prostu wysunie (hello, 1) jako wyjście. Ponieważ różne części kodu są opracowywane w tym samym czasie, otrzymasz zmapowaną wersję swojego zestawu danych w mgnieniu oka! Aby docenić prostotę MapReduce , zdaj sobie sprawę, że wykonywana tutaj operacja jest dość podstawowa i nie wymaga intensywnych obliczeń.
- Tasowanie zmapowanych wyników:
Gdy otrzymamy ostateczne uporządkowane pary z funkcji Map(), wyniki są tasowane. Oznacza to po prostu, że pary (słowo, liczba) z tym samym słowem są przesyłane do jednej maszyny.
Teraz, jeśli jesteś zaznajomiony z programowaniem, zdasz sobie sprawę, że istnieje granica, do której można to osiągnąć. W klastrze są dosłownie miliardy słów i tylko skończona liczba komputerów. W tym momencie należy zauważyć, że faza odtwarzania losowego nie jest obowiązkowa, aby MapReduce działała, po prostu przyspiesza działanie skryptu Reduce() poprzez uporządkowanie rzeczy w kolejności. Na razie powiedzmy, że potasowaliśmy wyniki naszej Mapy i teraz mamy wszystkie wystąpienia słowa „hello” w jednym komputerze w postaci uporządkowanej pary – (hello, n) gdzie n to liczba razy „ cześć” pojawiło się w jednej konkretnej książce.

- Na koniec faza Reduce():
Wreszcie dochodzimy do ostatniej fazy – Reduce(). Jeśli zwracałeś uwagę na cały przepływ pracy, być może poprawnie odgadłeś, że Reduce() po prostu policzy, ile razy każde słowo pojawia się w pliku wejściowym. Wystarczy dodać drugi składnik z naszych zamówionych par. Jeśli we wszystkich książkach jest, powiedzmy, 200 wzmianek o słowie „cześć”, ostateczny wynik, jaki otrzymamy po tej fazie, będzie – (cześć, 200). Po prostu przez proste liczenie i dodawanie doszliśmy do wyniku. Wszystko to jest możliwe dzięki zastosowaniu kilku komputerów i jednoczesnej ich pracy.
Analiza SWOT MapReduce
Paradygmat MapReduce ułatwił życie naukowcom zajmującym się danymi. Przyjrzyjmy się, jakie są mocne i słabe strony, szanse i zagrożenia tego frameworka:
| Silne strony | Przetwarza ogromne zbiory danych z błyskawicznymi prędkościami, przetwarzając je równolegle w rozproszonych klastrach. |
| Słabości | Skrypty Map() i Reduce() są uruchamiane kolejno. Operacje odczytu/zapisu są wykonywane na HDFS, który w porównaniu jest powolny |
| Możliwości | Generowanie spostrzeżeń z poprzednich odrzuconych zestawów danych i przetwarzanie Big Data generowanych przez organizacje. |
| Zagrożenia | Samodzielne operacje MapReduce mogą spowolnić tempo branży Big Data bez odpowiedniego zaawansowania analiz. |
Podsumowując…
Teraz, gdy znasz już wewnętrzne działanie MapReduce , zrozumiesz, że w żadnym wypadku nie jest to nowa technologia – od bardzo dawna używamy podobnych paradygmatów do obsługi dużych ilości danych, takich jak wyniki wyborów Teraz. Zrozumiesz również, jak ważne jest, aby wszystko było proste — MapReduce w ogóle nie robi nic wyszukanego i to właśnie czyni go tak potężnym.
Jeśli chcesz dowiedzieć się więcej o Big Data, sprawdź nasz program PG Diploma in Software Development Specialization in Big Data, który jest przeznaczony dla pracujących profesjonalistów i zawiera ponad 7 studiów przypadków i projektów, obejmuje 14 języków programowania i narzędzi, praktyczne praktyczne warsztaty, ponad 400 godzin rygorystycznej pomocy w nauce i pośrednictwie pracy w najlepszych firmach.
Ucz się stopni inżynierii oprogramowania online z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.