Guide de l'auto-stoppeur sur MapReduce
Publié: 2018-02-05Si vous avez lu notre article sur les outils et technologies du Big Data, vous vous souvenez peut-être du terme « MapReduce ». C'est l'un des composants essentiels de l'architecture Hadoop et forme l'ensemble de la couche de traitement de Hadoop.
Dans cet article, nous parlerons de MapReduce un peu plus en profondeur - mais d'une manière conviviale pour les débutants. Pour faciliter votre compréhension, nous avons divisé l'article comme suit : 
- introduction
- Concepts de base
- Une analyse SWOT complète
Présentation de MapReduce
MapReduce est essentiellement un concept qui permet un traitement ultra-rapide d'ensembles de données volumineux sur un cluster distribué. C'est un modèle de programmation breveté par Google qui a d'abord été adopté par les gars d'Apache et qui est maintenant au cœur de tout l'écosystème Hadoop. Sa simplicité est ce qui le rend si efficace et louable.
MapReduce suit une logique très simple, celle qui est suivie depuis des lustres pour gérer les tâches quotidiennes - lorsque vous devez gérer beaucoup de matériel, employer un grand nombre de travailleurs accélérera le processus (le vieil adage "trop beaucoup de cuisiniers gâtent le bouillon » n'a pas sa place ici !).
Cependant, à ce stade, une question se pose : MapReduce fonctionne-t-il UNIQUEMENT avec d'énormes ensembles de données ?
La réponse est très simple : les ensembles de données ne doivent pas nécessairement être extrêmement volumineux. Cependant, pour des raisons économiques et de calcul, il est recommandé de faire fonctionner MapReduce uniquement si vous disposez de grands ensembles de données, suffisamment volumineux pour les calculs traditionnels. Il est toujours préférable de traiter de petits ensembles de données sur votre machine locale elle-même - comme c'était le cas avant l' introduction de MapReduce . Parce qu'honnêtement, utiliser MapReduce pour de petits morceaux de données revient à essayer de tuer une araignée à l'aide d'une mitrailleuse. L'araignée se fera tuer, sans aucun doute, mais cela en vaut-il la peine ?

Les concepts de base de MapReduce
À présent, vous avez une bonne idée de ce qu'est exactement MapReduce. Dans cette section, nous parlerons un peu plus du fonctionnement exact de MapReduce - les concepts de base qui mettent les roues en mouvement.
Si vous avez déjà rencontré des mathématiques de base dans votre vie (ce que nous espérons que vous avez si vous lisez ceci !), vous devez être conscient des concepts de « paires ordonnées ». C'est simplement une façon d'exprimer deux données sous la forme (x,y). Les paires ordonnées sont très utiles pour représenter des coordonnées, des fractions, des identifiants d'employés et d'autres formes de données similaires. MapReduce, également, s'appuie fortement sur le concept de paires ordonnées - en gros, toutes les données peuvent être "cartographiées" sous la forme d'une paire ordonnée, et peuvent être "réduites" de diverses manières, en fonction de l'énoncé du problème à portée de main.
Supposons que vous soyez seul dans une bibliothèque numérique contenant cent mille livres et que vous ayez la tâche ardue de trouver le nombre de fois qu'un mot particulier apparaît dans tous les livres combinés .
Ouf, comment commenceriez-vous ?
La première approche serait d'écrire un programme qui itérerait sur chaque mot, directement du Livre 1 - Mot 1, au Livre n - Mot n, et continue d'incrémenter une variable de compteur chaque fois que vous rencontrez le mot nécessaire. Le simple fait d'imaginer cela vous ferait réaliser le temps qu'il vous faudra pour accomplir cette tâche.
Voyons maintenant comment MapReduce répondra à la tâche :
- Exigences MapReduce :
MapReduce fonctionne bien dans un cluster distribué. Qu'est-ce qu'un cluster distribué, demandez-vous ?
Très simplement, il s'agit d'un grand nombre (souvent des milliers !) d'ordinateurs de base (ordinateurs à faible coût) entrelacés dans un réseau qui effectue une seule opération.
Maintenant, supposons que vous ayez un tel cluster. Pour notre énoncé de problème, l'entrée de ce cluster sera le contenu de tous les livres. Dès que nous introduisons ces données dans notre système, elles sont copiées dans chaque ordinateur (nœud) du cluster (en supposant que nous ne traitons qu'un seul travail pour le moment). Ceci est fait pour fournir un niveau de tolérance aux pannes - pour vous aider en cas de perte de données.
- Programmation dans MapReduce
Étant donné que MapReduce fonctionne en deux phases - Mapper et réduire, nous devons écrire deux programmes, Map () et Reduce (), pour obtenir un flux de travail MapReduce opérationnel. Auparavant, vous utilisiez Java pour écrire ces programmes, mais maintenant, en raison de la croissance rapide de la science des données, le framework MapReduce a été rendu suffisamment flexible pour gérer également les codes écrits en Python ou R.
Les scripts que vous écrivez s'exécuteront les uns après les autres, c'est-à-dire de manière successive. Cela nous amène à l'un des principaux inconvénients du paradigme MapReduce - le fait que vous ne pouvez pas exécuter les deux scripts en parallèle. Accomplir cela rendra MapReduc beaucoup plus rapide, et cela a fait l'objet de recherches approfondies.

- Parallélisation du flux de travail :
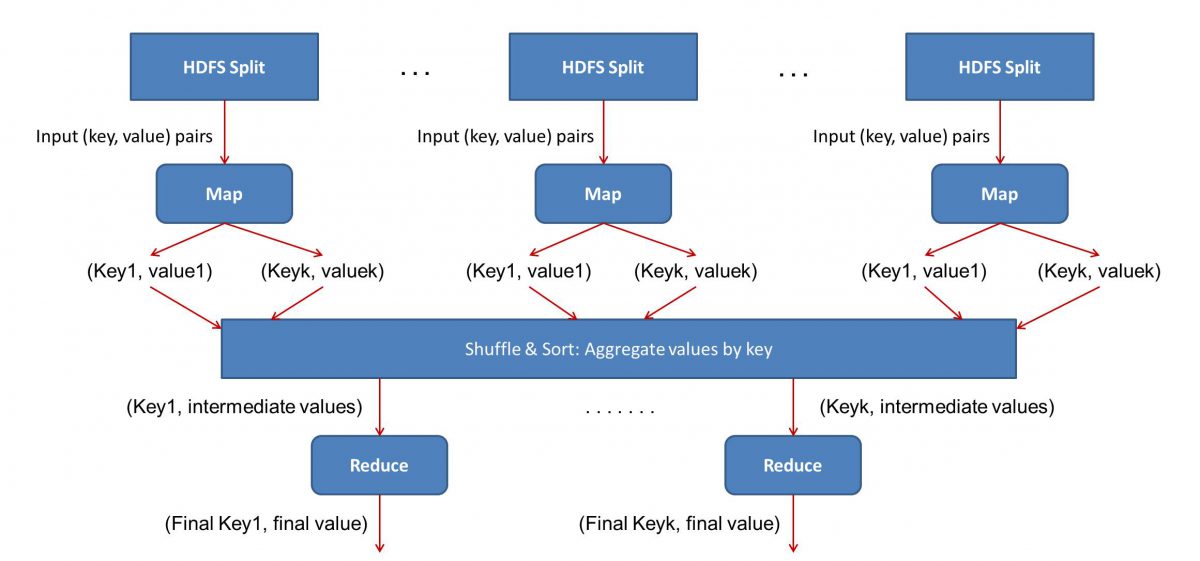
L'entrée (contenu de tous les livres) sera divisée en différents segments (égal au nombre d'ordinateurs dans le cluster, essentiellement), et chaque ordinateur se verra attribuer un segment particulier. Supposons que nous ayons divisé le fichier en lignes, puis le nœud 1 pourrait être invité à s'occuper des lignes 1 à 10 000, le nœud 2 pourrait être invité à 10 001 à 20 000, etc. (N'oubliez pas que ce ne sont que des chiffres illustratifs - les segments sont beaucoup plus grands dans la vraie vie)
Chaque machine exécutera alors votre programme Map().
- Le programme Map() :
Le programme Map() fait exactement ce que vous alliez faire avant de confier la tâche à MapReduce - scanner le fichier et lire un mot à la fois. L'avantage ici est qu'il fonctionnera simultanément sur plusieurs ordinateurs, ce qui réduira considérablement le temps. La sortie de la fonction Map() est une paire ordonnée. Dans ce cas, ce sera simplement (word, count), c'est-à-dire que lorsque la fonction Map() rencontre le mot "hello" (en supposant que c'est le mot que nous recherchons), elle éjectera simplement (hello, 1) comme un sortir. Étant donné que différentes parties du corps du code sont travaillées en même temps, vous aurez une version mappée de votre jeu de données en un rien de temps ! Pour apprécier la simplicité de MapReduce , sachez que l'opération effectuée ici est assez basique et ne nécessite aucun calcul intensif.
- Mélange des résultats mappés :
Une fois que nous obtenons les paires ordonnées finales de la fonction Map (), les résultats sont mélangés. Cela signifie simplement que les paires (mot, compte) avec le même mot sont transférées vers une seule machine.
Maintenant, si vous êtes familiarisé avec la programmation, vous vous rendrez compte qu'il y a une limite à laquelle cela peut être réalisé. Il y a littéralement des milliards de mots et seulement un nombre fini d'ordinateurs dans le cluster. À ce stade, il est important de noter que la phase de mélange n'est pas obligatoire pour que MapReduce fonctionne, cela rend simplement le script Reduce() beaucoup plus rapide en organisant les choses dans un ordre. Pour l'instant, disons simplement que nous avons mélangé nos sorties Map, et que nous avons maintenant toutes les instances du mot "hello" dans un seul ordinateur sous la forme d'une paire ordonnée - (hello, n) où n est le nombre de fois " bonjour » s'est produit dans un livre en particulier.

- Enfin, la phase Reduce() :
Enfin, nous arrivons à la dernière phase - Réduire(). Si vous faisiez attention à l'ensemble du flux de travail, vous avez peut-être correctement deviné que Reduce() comptera simplement le nombre de fois que chaque mot apparaît dans le fichier d'entrée. Tout ce qu'il a à faire est simplement d'ajouter le deuxième composant de nos paires ordonnées. S'il y a, disons, 200 mentions du mot "bonjour" dans tous les livres, le résultat final que nous obtiendrons après cette phase sera - (bonjour, 200). Juste par simple comptage et addition, nous sommes arrivés au résultat. Tout cela est rendu possible en employant plusieurs ordinateurs et en les faisant fonctionner simultanément.
Analyse SWOT MapReduce
Le paradigme MapReduce a simplifié la vie des Data Scientists. Voyons quelles sont les forces, les faiblesses, les opportunités et les menaces de ce framework :
| Forces | Traite des ensembles de données volumineux à des vitesses fulgurantes en les traitant en parallèle dans des clusters distribués. |
| Faiblesses | Les scripts Map() et Reduce() s'exécutent successivement. Les opérations de lecture/écriture sont effectuées sur HDFS, ce qui est lent en comparaison |
| Opportunités | Génération d'informations à partir d'ensembles de données précédemment rejetés et traitement du Big Data généré par les organisations. |
| Des menaces | Les opérations MapReduce autonomes pourraient ralentir le rythme de l'industrie du Big Data sans une avancée suffisante dans l'analyse. |
En conclusion…
Maintenant que vous êtes familiarisé avec le fonctionnement interne de MapReduce , vous comprendrez qu'il ne s'agit en aucun cas d'une nouvelle technologie - nous utilisons des paradigmes similaires pour gérer un grand volume de données, comme les résultats des élections, depuis très longtemps à présent. Vous réaliserez également l'importance de garder les choses simples - MapReduce n'a rien d'extraordinaire, et c'est ce qui le rend si puissant.
Si vous souhaitez en savoir plus sur le Big Data, consultez notre programme PG Diploma in Software Development Specialization in Big Data qui est conçu pour les professionnels en activité et fournit plus de 7 études de cas et projets, couvre 14 langages et outils de programmation, pratique pratique ateliers, plus de 400 heures d'apprentissage rigoureux et d'aide au placement dans les meilleures entreprises.
Apprenez des diplômes en génie logiciel en ligne dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.