Руководство автостопщика по MapReduce
Опубликовано: 2018-02-05Если вы читали нашу статью об инструментах и технологиях для работы с большими данными, возможно, вы помните термин « MapReduce ». Это один из основных компонентов архитектуры Hadoop, формирующий весь уровень обработки Hadoop.
В этой статье мы поговорим о MapReduce немного подробнее, но в удобной для начинающих форме. Для простоты понимания мы разбили статью следующим образом: 
- Введение
- Основные концепции
- Полный SWOT-анализ
Введение в MapReduce
MapReduce — это, по сути, концепция, которая позволяет молниеносно обрабатывать массивные наборы данных в распределенном кластере. Это запатентованная Google модель программирования, которая была впервые принята ребятами из Apache и теперь лежит в основе всей экосистемы Hadoop. Его простота - вот что делает его таким эффективным и похвальным.
MapReduce следует очень простой логике, которой веками следовали для управления повседневными задачами — когда вам приходится иметь дело с большим количеством материала, найм большого количества работников ускорит процесс (старая поговорка «слишком много многие повара портят бульон» сюда не подходит!).
Однако в этот момент возникает один вопрос — MapReduce хорошо работает ТОЛЬКО с огромными наборами данных?
Ответ на этот вопрос очень прост — наборы данных не обязательно должны быть очень большими. Однако по экономическим и вычислительным причинам рекомендуется использовать MapReduce только в том случае, если у вас есть большие наборы данных, достаточно большие для традиционных вычислений. Всегда лучше обрабатывать небольшие наборы данных на своем локальном компьютере — так, как это было до появления MapReduce . Потому что, честно говоря, использование MapReduce для небольших фрагментов данных очень похоже на попытку убить паука из пулемета. Паук, несомненно, будет убит, но стоит ли оно того?

Основные концепции MapReduce
К настоящему времени у вас есть четкое представление о том, что такое MapReduce. В этом разделе мы немного подробнее поговорим о том, как именно работает MapReduce , — об основных концепциях, которые приводят в движение колеса.
Если вы когда-либо сталкивались с основами математики в своей жизни (мы надеемся, что вы сталкивались с ними, если вы читаете это!), вы должны быть знакомы с концепцией «упорядоченных пар». Это просто способ выражения двух частей данных в (x, y) форме. Упорядоченные пары очень полезны для представления координат, дробей, идентификаторов сотрудников и других подобных форм данных. MapReduce также в значительной степени опирается на концепцию упорядоченных пар — по сути, любые данные могут быть «отображены» в форму упорядоченной пары и могут быть «сведены» различными способами, в зависимости от поставленной задачи.
Предположим, вы остались одни в цифровой библиотеке, содержащей сто тысяч книг, и вам дали сложную задачу найти, сколько раз конкретное слово встречается во всех книгах вместе взятых .
Фу, как бы вы начали?
Первый подход состоял бы в том, чтобы написать программу, которая перебирала бы каждое слово, начиная с Книги 1 — Слово 1, и заканчивая Книгой n — Слово n, и продолжала бы увеличивать переменную-счетчик каждый раз, когда вы сталкиваетесь с нужным словом. Просто представив это, вы поймете, сколько времени потребуется для выполнения этой задачи.
Теперь посмотрим, как MapReduce отреагирует на поставленную задачу:
- Требования MapReduce:
MapReduce хорошо работает в распределенном кластере. Вы спросите, что такое распределенный кластер?
Проще говоря, это большое количество (часто тысячи!) обычных компьютеров (недорогих компьютеров), объединенных в сеть, выполняющую одну операцию.
Теперь предположим, что у вас есть один такой кластер. Для нашей постановки задачи входными данными для этого кластера будет содержание всех книг. Как только мы вводим эти данные в нашу систему, они копируются на каждый компьютер (узел) в кластере (при условии, что в данный момент мы имеем дело только с одним заданием). Это сделано для обеспечения уровня отказоустойчивости — чтобы помочь вам в случае потери данных.
- Программирование в MapReduce
Поскольку MapReduce работает в два этапа — Map и Reduce, нам нужно написать две программы, Map() и Reduce(), чтобы запустить и запустить рабочий процесс MapReduce . Раньше для написания этих программ вы использовали Java, но теперь из-за быстрого роста науки о данных инфраструктура MapReduce стала достаточно гибкой, чтобы обрабатывать коды, написанные также на Python или R.
Написанные вами сценарии будут запускаться один за другим, то есть последовательно. Это подводит нас к одному из основных недостатков парадигмы MapReduce — тому факту, что вы не можете запускать оба скрипта параллельно. Достижение этого сделает MapReduc намного быстрее, и это было предметом обширных исследований.

- Распараллеливание рабочего процесса:
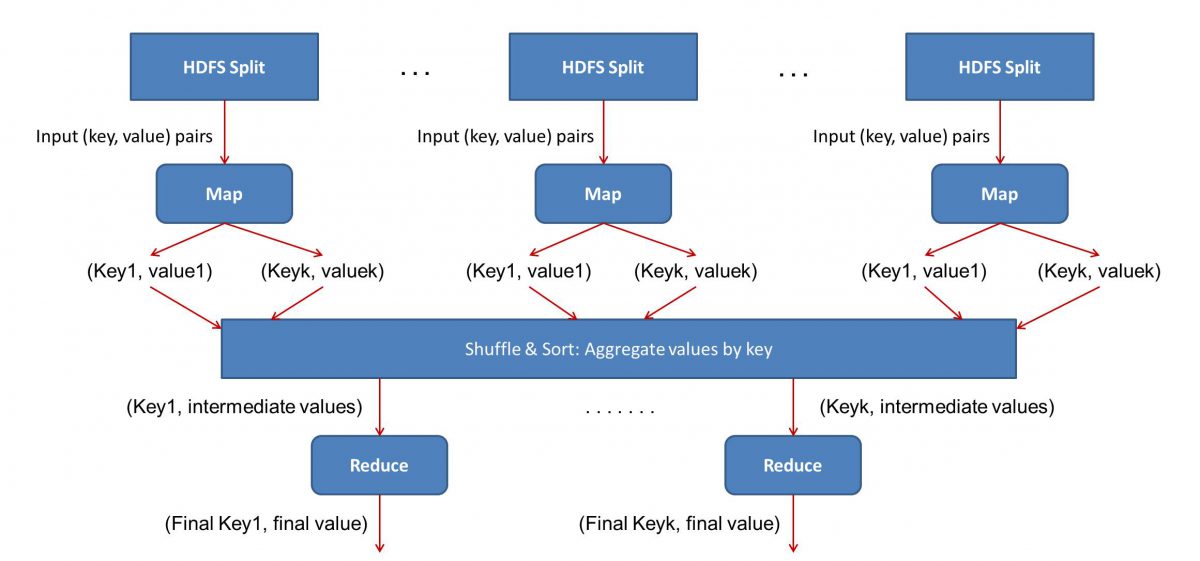
Ввод (содержание всех книг) будет разделен на различные сегменты (по сути, равные количеству компьютеров в кластере), и каждому компьютеру будет назначен определенный сегмент. Предположим, мы разделили файл на строки, тогда узлу 1 может быть предложено позаботиться о строках с 1 по 10 000, узлу 2 может быть запрошено, например, от 10 001 до 20 000 и так далее. (Помните, что это всего лишь иллюстративные цифры — в реальной жизни сегменты намного больше)
Затем каждая машина запустит вашу программу Map().
- Программа Карта():
Программа Map() делает именно то, что вы собирались сделать, прежде чем давать задачу MapReduce — сканирует файл и читает по одному слову за раз. Преимущество здесь в том, что он будет работать одновременно на нескольких компьютерах, что сократит время в разы. Результатом функции Map() является упорядоченная пара. В данном случае это будет просто (слово, количество), т.е. когда функция Map() встречает слово «привет» (при условии, что это слово, которое мы ищем), она просто извлекает (привет, 1) как выход. Поскольку различные части тела кода обрабатываются одновременно, у вас будет сопоставленная версия набора данных в кратчайшие сроки! Чтобы оценить простоту MapReduce , поймите, что выполняемая здесь операция довольно проста и не требует интенсивных вычислений.
- Перетасовка сопоставленных результатов:
Как только мы получаем окончательные упорядоченные пары из функции Map(), результаты перемешиваются. Это просто означает, что пары (word, count) с одним и тем же словом передаются на одну машину.
Теперь, если вы знакомы с программированием, вы поймете, что есть предел, до которого это может быть достигнуто. В кластере буквально миллиарды слов и лишь конечное число компьютеров. На этом этапе важно отметить, что фаза перемешивания не является обязательной для работы MapReduce , она просто делает скрипт Reduce() намного быстрее, упорядочивая элементы. А пока давайте просто скажем, что мы перетасовали выходные данные карты, и теперь у нас есть все экземпляры слова «привет» на одном компьютере в виде упорядоченной пары — (привет, n), где n — количество раз « привет» произошло в одной конкретной книге.

- Наконец, фаза Reduce():
Наконец, мы подошли к последнему этапу — Reduce(). Если бы вы обращали внимание на весь рабочий процесс, вы могли бы правильно догадаться, что функция Reduce() будет просто подсчитывать, сколько раз каждое слово появляется во входном файле. Все, что ему нужно сделать, это просто добавить второй компонент наших упорядоченных пар. Если есть, скажем, 200 упоминаний слова «привет» во всех книгах, окончательный вывод, который мы получим после этой фазы, будет — (привет, 200). Просто путем простого подсчета и сложения мы пришли к результату. Все это стало возможным благодаря использованию нескольких компьютеров и их одновременной работе.
SWOT-анализ MapReduce
Парадигма MapReduce упростила жизнь специалистам по данным. Давайте посмотрим, каковы сильные и слабые стороны, возможности и угрозы этой структуры:
| Сильные стороны | Обрабатывает массивные наборы данных с молниеносной скоростью, обрабатывая их параллельно в распределенных кластерах. |
| Слабые стороны | Сценарии Map() и Reduce() выполняются последовательно. Операции чтения/записи выполняются на HDFS, которая медленнее по сравнению с |
| Возможности | Получение информации из ранее отброшенных наборов данных и обработка больших данных, созданных организациями. |
| Угрозы | Автономные операции MapReduce могут замедлить темпы развития индустрии больших данных без достаточного прогресса в аналитике. |
В заключение…
Теперь, когда вы знакомы с внутренней работой MapReduce , вы поймете, что это ни в коем случае не новая технология — мы использовали аналогичные парадигмы для обработки больших объемов данных, таких как результаты выборов, в течение очень долгого времени. сейчас. Вы также поймете важность простоты — MapReduce не делает ничего особенного, и именно это делает его таким мощным.
Если вам интересно узнать больше о больших данных, ознакомьтесь с нашей программой PG Diploma в области разработки программного обеспечения со специализацией в области больших данных, которая предназначена для работающих профессионалов и включает более 7 тематических исследований и проектов, охватывает 14 языков и инструментов программирования, практические занятия. семинары, более 400 часов интенсивного обучения и помощь в трудоустройстве в ведущих фирмах.
Изучайте степени по программной инженерии онлайн в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.