Guia do Mochileiro para MapReduce
Publicados: 2018-02-05Se você leu nosso artigo sobre Ferramentas e Tecnologias de Big Data, deve se lembrar de encontrar o termo “ MapReduce ”. É um dos componentes principais da arquitetura do Hadoop e forma toda a camada de processamento do Hadoop.
Neste artigo, falaremos sobre o MapReduce com um pouco mais de profundidade – mas de uma maneira amigável para iniciantes. Para facilitar o entendimento, dividimos o artigo da seguinte forma: 
- Introdução
- Conceitos Fundamentais
- Uma análise SWOT completa
Introdução ao MapReduce
MapReduce é essencialmente um conceito que permite o processamento extremamente rápido de grandes conjuntos de dados em um cluster distribuído. É um modelo de programação patenteado pelo Google que foi adotado pela primeira vez pelos caras do Apache e agora está no coração de todo o ecossistema Hadoop. Sua simplicidade é o que o torna tão eficaz e louvável.
O MapReduce segue uma lógica muito simples, que vem sendo seguida há muito tempo para gerenciar tarefas do dia a dia – quando você tem que lidar com muito material, empregar um grande número de trabalhadores acelera o processo (o velho ditado “demasiado muitos cozinheiros estragam o caldo” não cabe aqui!).
No entanto, neste ponto, surge uma pergunta – o MapReduce funciona bem APENAS com grandes conjuntos de dados?
A resposta para isso é muito simples – os conjuntos de dados não precisam necessariamente ser extremamente grandes. No entanto, devido a razões econômicas e computacionais, é recomendável colocar o MapReduce para funcionar apenas se você tiver grandes conjuntos de dados, grandes o suficiente para cálculos tradicionais. É sempre melhor processar pequenos conjuntos de dados em sua própria máquina local – como era antes do MapReduce ser introduzido. Porque, honestamente, usar o MapReduce para pequenos pedaços de dados é como tentar matar uma aranha usando uma metralhadora. A aranha será morta, sem dúvida, mas vale a pena?

Os Conceitos Fundamentais do MapReduce
Até agora, você tem uma boa ideia do que exatamente é MapReduce. Nesta seção, falaremos um pouco mais sobre como exatamente o MapReduce funciona – os conceitos centrais que colocam as rodas em movimento.
Se você já encontrou matemática básica em sua vida (o que esperamos que você tenha se estiver lendo isso!), você deve estar ciente dos conceitos de “pares ordenados”. É simplesmente uma maneira de expressar dois dados na forma (x,y). Os pares ordenados são muito úteis para representar coordenadas, frações, IDs de funcionários e outras formas semelhantes de dados. O MapReduce também depende muito do conceito de pares ordenados – basicamente, qualquer dado pode ser “mapeado” na forma de um par ordenado e pode ser “reduzido” de várias maneiras, dependendo da declaração do problema em mãos.
Suponha que você seja deixado sozinho em uma biblioteca digital contendo cem mil livros e receba uma tarefa assustadora de descobrir o número de vezes que uma determinada palavra ocorre em todos os livros combinados .
Ufa, como você começaria?
A primeira abordagem seria escrever um programa que iteraria sobre cada palavra, desde o Livro 1 – Palavra 1, até o Livro n – Palavra n, e continuar incrementando uma variável de contador cada vez que encontrar a palavra necessária. Apenas imaginar isso faria você perceber a quantidade de tempo que levará para realizar essa tarefa.
Agora, vamos dar uma olhada em como o MapReduce responderá à tarefa:
- Requisitos do MapReduce:
MapReduce funciona bem em um cluster distribuído. O que é um cluster distribuído, você pergunta?
Muito simplesmente, é um grande número (muitas vezes milhares!) de computadores comuns (computadores de baixo custo) interligados em uma rede que executa uma única operação.
Agora, suponha que você tenha um desses clusters. Para nossa declaração de problema, a entrada para este cluster será o conteúdo de todos os livros. Assim que alimentamos esses dados em nosso sistema, eles são copiados em cada computador (nó) no cluster (assumindo que estamos lidando apenas com um trabalho no momento). Isso é feito para fornecer um nível de tolerância a falhas – para ajudá-lo em caso de perda de dados.
- Programando no MapReduce
Como o MapReduce funciona em duas fases – Mapear e reduzir, temos que escrever dois programas, Map() e Reduce(), para colocar um fluxo de trabalho MapReduce em funcionamento. Anteriormente, você usava Java para escrever esses programas, mas agora, devido ao rápido crescimento em Data Science, a estrutura MapReduce tornou-se flexível o suficiente para lidar com códigos escritos em Python ou R também.
Os scripts que você escrever serão executados um após o outro, ou seja, de maneira sucessiva. Isso nos leva a uma das principais desvantagens do paradigma MapReduce – o fato de que você não pode executar os dois scripts em paralelo. Conseguir isso tornará o MapReduc muito mais rápido, e isso tem sido objeto de extensa pesquisa.

- Paralelização do fluxo de trabalho:
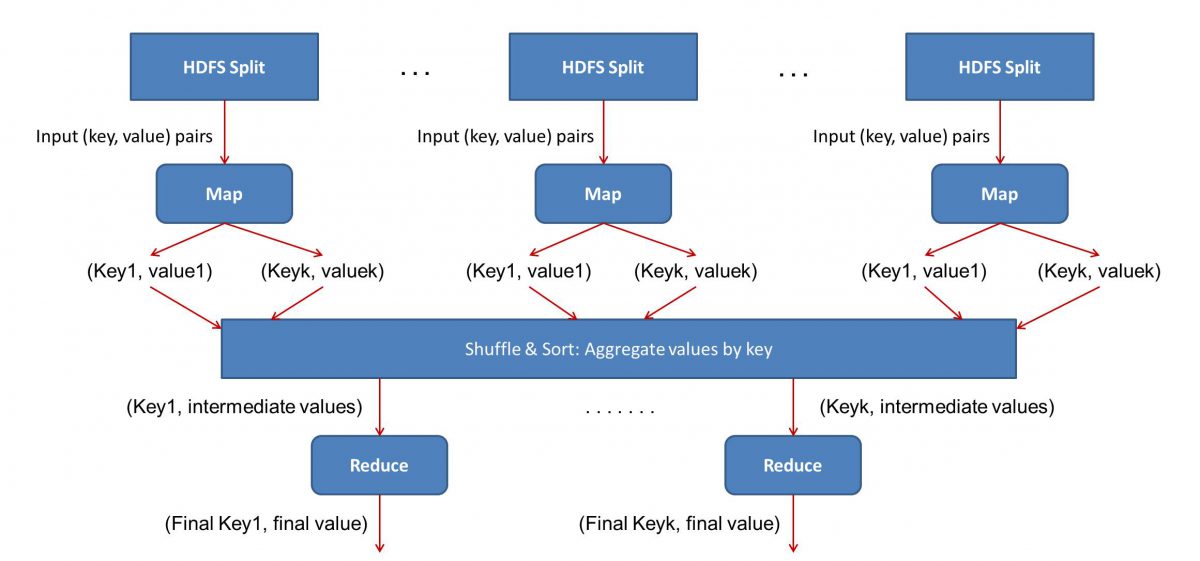
A entrada (conteúdo de todos os livros) será dividida em vários segmentos (igual ao número de computadores no cluster, essencialmente), e a cada computador será atribuído um segmento específico. Suponha que dividimos o arquivo com base em linhas, então o nó 1 pode ser solicitado a cuidar das linhas de 1 a 10.000, o nó 2 pode ser solicitado por 10.001 a 20.000 e assim por diante. (Lembre-se que estes são apenas números ilustrativos – os segmentos são muito maiores na vida real)
Cada máquina irá então executar seu programa Map().
- O programa Map():
O programa Map() faz exatamente o que você faria antes de dar a tarefa ao MapReduce – escanear o arquivo e ler uma palavra de cada vez. O benefício aqui é que ele será executado simultaneamente em vários computadores, portanto, reduzirá muito o tempo. A saída da função Map() é um par ordenado. Neste caso, será simplesmente (word, count), ou seja, quando a função Map() encontrar a palavra “hello” (assumindo que é a palavra que estamos procurando), ela simplesmente ejetará (hello, 1) como um saída. Como várias partes do corpo do código estão sendo trabalhadas ao mesmo tempo, você terá uma versão mapeada do seu conjunto de dados em pouco tempo! Para apreciar a simplicidade do MapReduce , perceba que a operação que está sendo executada aqui é bastante básica, não exigindo cálculos intensivos.
- Embaralhamento dos resultados mapeados:
Assim que obtivermos os pares ordenados finais da função Map(), os resultados serão embaralhados. Isso significa simplesmente que (palavra, contagem) pares com a mesma palavra são transferidos para uma única máquina.
Agora, se você estiver familiarizado com programação, perceberá que existe um limite para o qual isso pode ser alcançado. Existem literalmente bilhões de palavras e apenas um número finito de computadores no cluster. Neste ponto, é importante observar que a fase de embaralhamento não é obrigatória para o MapReduce funcionar, ela simplesmente torna o script Reduce() muito mais rápido, organizando as coisas em uma ordem. Por enquanto, vamos apenas dizer que embaralhamos nossas saídas do Map e agora temos todas as instâncias da palavra “hello” em um único computador na forma de um par ordenado – (hello, n) onde n é o número de vezes “ hello” ocorreu em um livro em particular.

- Finalmente, a fase Reduce():
Finalmente, chegamos à última fase – Reduzir(). Se você estivesse prestando atenção em todo o fluxo de trabalho, poderia ter adivinhado corretamente que Reduce() apenas contará o número de vezes que cada palavra aparece no arquivo de entrada. Tudo o que precisa fazer é simplesmente adicionar o segundo componente de nossos pares ordenados. Se houver, digamos, 200 menções à palavra “hello” em todos os livros, o resultado final que teremos após esta fase será – (hello, 200). Apenas por simples contagem e adição, chegamos ao resultado. Tudo isso foi possível empregando vários computadores e fazendo-os funcionar simultaneamente.
Análise SWOT MapReduce
O paradigma MapReduce facilitou a vida dos Cientistas de Dados. Vamos dar uma olhada em quais são os pontos fortes, fracos, oportunidades e ameaças desta estrutura:
| Forças | Processa grandes conjuntos de dados em velocidades extremamente rápidas, processando-os paralelamente em clusters distribuídos. |
| Fraquezas | Os scripts Map() e Reduce() são executados sucessivamente. As operações de leitura/gravação são executadas no HDFS, que é lento em comparação |
| Oportunidades | Gerando insights de conjuntos de dados descartados anteriormente e processando Big Data gerados pelas organizações. |
| Ameaças | As operações independentes do MapReduce podem diminuir o ritmo do setor de Big Data sem avanço suficiente na análise. |
Para concluir…
Agora que você está familiarizado com o funcionamento interno do MapReduce , você perceberá que não é de forma alguma uma tecnologia nova - temos usado paradigmas semelhantes para lidar com grandes volumes de dados, como resultados de eleições, há muito tempo agora. Você também perceberá a importância de manter as coisas simples – o MapReduce não faz nada extravagante, e é isso que o torna tão poderoso.
Se você estiver interessado em saber mais sobre Big Data, confira nosso programa PG Diploma in Software Development Specialization in Big Data, projetado para profissionais que trabalham e fornece mais de 7 estudos de caso e projetos, abrange 14 linguagens e ferramentas de programação, práticas práticas workshops, mais de 400 horas de aprendizado rigoroso e assistência para colocação de emprego com as principais empresas.
Aprenda os graus de Engenharia de Software online das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.