คู่มือการโบกรถเพื่อ MapReduce
เผยแพร่แล้ว: 2018-02-05หากคุณเคยอ่านบทความของเราเกี่ยวกับ Big Data Tools and Technologies คุณอาจจำคำว่า “ MapReduce ” ได้ มันเป็นหนึ่งในองค์ประกอบหลักของสถาปัตยกรรม Hadoop และสร้างเลเยอร์การประมวลผลทั้งหมดของ Hadoop
ในบทความนี้ เราจะพูดถึง MapReduce ในเชิงลึกมากขึ้น – แต่ในวิธีที่เป็นมิตรกับผู้เริ่มต้นใช้งาน เพื่อความสะดวกในการทำความเข้าใจ เราได้แยกย่อยบทความดังต่อไปนี้: 
- บทนำ
- แนวคิดหลัก
- การวิเคราะห์ SWOT ที่สมบูรณ์
ข้อมูลเบื้องต้นเกี่ยวกับ MapReduce
โดยพื้นฐานแล้ว MapReduce เป็นแนวคิดที่ช่วยให้สามารถประมวลผลชุดข้อมูลขนาดใหญ่บนคลัสเตอร์แบบกระจายได้อย่างรวดเร็ว เป็นโมเดลการเขียนโปรแกรมที่ได้รับการจดสิทธิบัตรโดย Google ซึ่งได้รับการยอมรับครั้งแรกโดยพวกที่ Apache และตอนนี้เป็นหัวใจสำคัญของระบบนิเวศ Hadoop ทั้งหมด ความเรียบง่ายคือสิ่งที่ทำให้มันมีประสิทธิภาพและน่ายกย่อง
MapReduce เป็นไปตามตรรกะง่ายๆ อย่างหนึ่งซึ่งถูกติดตามมาเป็นเวลานานสำหรับการจัดการงานในแต่ละวัน เมื่อคุณต้องจัดการกับวัสดุจำนวนมาก การจ้างคนงานจำนวนมากจะทำให้กระบวนการเร็วขึ้น (สุภาษิตโบราณ “เช่นกัน พ่อครัวหลายคนเสียน้ำซุป” ไม่เหมาะกับที่นี่!)
อย่างไรก็ตาม ณ จุดนี้ มีคำถามหนึ่งเกิดขึ้น – MapReduce ทำงานได้ดีกับชุดข้อมูลขนาดใหญ่เท่านั้นหรือไม่
คำตอบนั้นง่ายมาก – ชุดข้อมูลไม่ จำเป็นต้อง มีขนาดใหญ่มาก อย่างไรก็ตาม ด้วยเหตุผลทางเศรษฐกิจและการคำนวณ ขอแนะนำให้ใช้ MapReduce เฉพาะในกรณีที่คุณมีชุดข้อมูลขนาดใหญ่ ซึ่งใหญ่พอสำหรับการคำนวณแบบเดิม จะดีกว่าเสมอที่จะประมวลผลชุดข้อมูลขนาดเล็กบนเครื่องของคุณ – อย่างที่เคยเป็นมา ก่อน MapReduce เพราะตามจริงแล้ว การใช้ MapReduce กับข้อมูลเล็กๆ น้อยๆ ก็เหมือนกับการพยายามฆ่าแมงมุมโดยใช้ปืนกล แมงมุมจะถูกฆ่าอย่างไม่ต้องสงสัย แต่มันคุ้มค่าหรือไม่?

แนวคิดหลักของ MapReduce
ถึงตอนนี้ คุณมีความคิดที่เป็นธรรมว่า MapReduce คืออะไรกันแน่ ในส่วนนี้ เราจะพูดเพิ่มเติมอีกเล็กน้อยว่า MapReduce ทำงานอย่างไร – แนวคิดหลักที่ทำให้วงล้อเคลื่อนที่
หากคุณเคยเจอคณิตศาสตร์พื้นฐานในชีวิตของคุณ (ซึ่งเราหวังว่าคุณจะมีถ้าคุณกำลังอ่านสิ่งนี้อยู่!) คุณต้องตระหนักถึงแนวคิดของ "คู่ที่เรียงลำดับ" เป็นเพียงวิธีการแสดงข้อมูลสองส่วนในรูปแบบ (x,y) คู่ลำดับมีประโยชน์มากสำหรับการแสดงพิกัด เศษส่วน รหัสพนักงาน และข้อมูลรูปแบบอื่นที่คล้ายคลึงกัน MapReduce อาศัยแนวคิดของคู่คำสั่งเป็นอย่างมาก โดยพื้นฐานแล้ว ข้อมูลใดๆ สามารถ "จับคู่" ในรูปแบบของคู่ที่สั่งซื้อ และสามารถ "ลด" ได้หลายวิธี ขึ้นอยู่กับคำชี้แจงปัญหาที่มีอยู่
สมมติว่าคุณถูกทิ้งให้อยู่ตามลำพังในห้องสมุดดิจิทัลที่มีหนังสือนับแสนเล่ม และต้องพบกับความยากลำบากในการค้นหาจำนวนครั้งที่คำบางคำเกิดขึ้นในหนังสือทุกเล่ม รวม กัน
วุ้ย คุณจะเริ่มต้นอย่างไร
วิธีแรกคือการเขียนโปรแกรมที่จะวนซ้ำทุกคำ ตั้งแต่ เล่ม 1 – Word 1 ถึง Book n – Word n และเพิ่มตัวแปรตัวนับทุกครั้งที่คุณพบคำที่ต้องการ แค่จินตนาการถึงสิ่งนี้จะทำให้คุณรู้ว่าต้องใช้เวลานานแค่ไหนกว่าจะทำภารกิจนี้ได้สำเร็จ
ตอนนี้ มาดูกันว่า MapReduce จะตอบสนองต่องานอย่างไร:
- ข้อกำหนด MapReduce:
MapReduce ทำงานได้ดีในคลัสเตอร์แบบกระจาย คุณถามคลัสเตอร์แบบกระจายคืออะไร
พูดง่ายๆ ก็คือ มีคอมพิวเตอร์สินค้าโภคภัณฑ์ (คอมพิวเตอร์ต้นทุนต่ำ) จำนวนมาก (บ่อยครั้งเป็นพัน!) ที่รวมเข้ากับเครือข่ายที่ดำเนินการเพียงครั้งเดียว
ตอนนี้ สมมติว่าคุณมีคลัสเตอร์ดังกล่าว สำหรับคำชี้แจงปัญหาของเรา ข้อมูลในคลัสเตอร์นี้จะเป็นเนื้อหาของหนังสือทุกเล่ม ทันทีที่เราป้อนข้อมูลนี้เข้าสู่ระบบของเรา ข้อมูลนั้นจะถูกคัดลอกไปยังคอมพิวเตอร์ทุกเครื่อง (โหนด) บนคลัสเตอร์ (สมมติว่าเราจัดการกับงานเดียวเท่านั้นในขณะนี้) สิ่งนี้ทำขึ้นเพื่อให้ระดับความทนทานต่อข้อผิดพลาด – เพื่อช่วยคุณในกรณีที่ข้อมูลสูญหาย
- การเขียนโปรแกรมใน MapReduce
เนื่องจาก MapReduce ทำงานในสองขั้นตอน – แผนที่และย่อ เราจึงต้องเขียนสองโปรแกรม Map() และ Reduce() เพื่อให้ เวิร์กโฟลว์ MapReduce ทำงานได้ ก่อนหน้านี้คุณใช้ Java เพื่อเขียนโปรแกรมเหล่านี้ แต่ตอนนี้เนื่องจากการเติบโตอย่างรวดเร็วใน Data Science เฟรมเวิร์ก MapReduce จึงมีความยืดหยุ่นเพียงพอที่จะจัดการกับโค้ดที่เขียนด้วย Python หรือ R ได้เช่นกัน
สคริปต์ที่คุณเขียนจะทำงานตามลำดับ กล่าวคือ ในลักษณะที่ต่อเนื่องกัน สิ่งนี้นำเราไปสู่ข้อเสียเปรียบที่สำคัญประการหนึ่งของ กระบวนทัศน์ MapReduce – ความจริงที่ว่าคุณไม่สามารถเรียกใช้สคริปต์ทั้งสองแบบพร้อมกันได้ ความสำเร็จนั้นจะทำให้ MapReduc ทำงานเร็วขึ้นมาก และนั่นเป็นหัวข้อของการวิจัยอย่างกว้างขวาง

- เวิร์กโฟลว์ Parallelization:
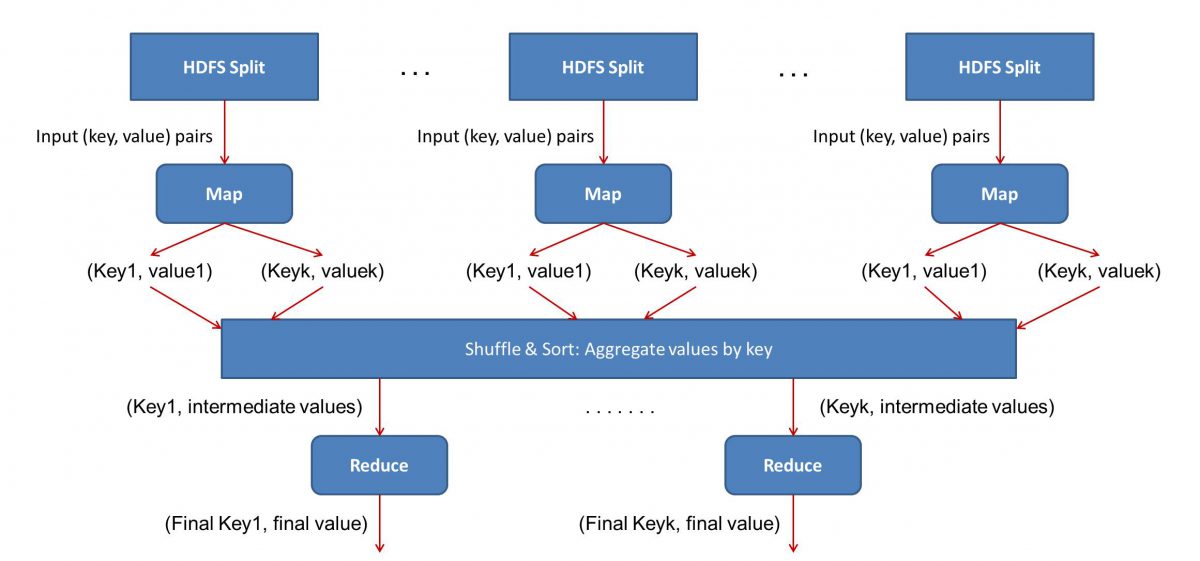
ข้อมูลเข้า (เนื้อหาของหนังสือทั้งหมด) จะถูกแบ่งออกเป็นส่วนต่างๆ (เท่ากับจำนวนคอมพิวเตอร์ในคลัสเตอร์โดยพื้นฐาน) และคอมพิวเตอร์แต่ละเครื่องจะได้รับมอบหมายส่วนเฉพาะ สมมติว่าเราแบ่งไฟล์ตามบรรทัด โหนด 1 อาจถูกขอให้ดูแลบรรทัดที่ 1 ถึง 10,000 โหนด 2 อาจถูกถามเช่น 10,001 ถึง 20,000 เป็นต้น (โปรดจำไว้ว่านี่เป็นเพียงตัวอย่างเท่านั้น - ส่วนต่างๆ ในชีวิตจริงมีขนาดใหญ่กว่า มาก )
แต่ละเครื่องจะเรียกใช้โปรแกรม Map() ของคุณ
- แผนที่ () โปรแกรม:
โปรแกรม Map() ทำสิ่งที่คุณกำลังจะทำจริงๆ ก่อนมอบงานให้กับ MapReduce โดยจะ สแกนไฟล์และอ่านทีละคำ ประโยชน์ที่นี่คือมันจะทำงานพร้อมกันบนคอมพิวเตอร์หลายเครื่อง ดังนั้นมันจึงลดเวลาลงได้หลายเท่า ผลลัพธ์ของฟังก์ชัน Map() เป็นคู่ที่เรียงลำดับ ในกรณีนี้ จะเป็นเพียงแค่ (คำ นับ) เช่น เมื่อฟังก์ชัน Map() พบคำว่า "สวัสดี" (สมมติว่าเป็นคำที่เรากำลังมองหา) ก็จะดีดออก (สวัสดี 1) เป็น เอาท์พุท เนื่องจากส่วนต่างๆ ของโค้ดมีการทำงานพร้อมกัน คุณจะมีชุดข้อมูลเวอร์ชันที่แมปในเวลาไม่นาน! เพื่อชื่นชมความเรียบง่ายของ MapReduce โปรดทราบว่าการดำเนินการที่ดำเนินการที่นี่ค่อนข้างเป็นพื้นฐานที่ไม่ต้องการการคำนวณอย่างเข้มข้น
- การสับเปลี่ยนผลลัพธ์ที่แมป:
เมื่อเราได้รับคู่ลำดับสุดท้ายจากฟังก์ชัน Map() ผลลัพธ์จะถูกสับเปลี่ยน นั่นก็หมายความว่า (คำ นับ) จับคู่กับคำเดียวกันจะถูกโอนไปยังเครื่องเดียว
ตอนนี้ ถ้าคุณคุ้นเคยกับการเขียนโปรแกรม คุณจะรู้ว่ามีขีดจำกัดที่สามารถทำได้ มีคำศัพท์หลายพันล้านคำและมีคอมพิวเตอร์จำนวนจำกัดในคลัสเตอร์ ณ จุดนี้ สิ่งสำคัญคือต้องสังเกตว่าเฟสสลับไม่จำเป็นสำหรับ MapReduce ในการทำงาน มันเพียงทำให้สคริปต์ Reduce() เร็วขึ้นมากโดยจัดเรียงสิ่งต่าง ๆ ตามลำดับ ในตอนนี้ สมมติว่าเราสลับเอาต์พุตแผนที่ของเรา และตอนนี้มีอินสแตนซ์ทั้งหมดของคำว่า "สวัสดี" ในคอมพิวเตอร์เครื่องเดียวในรูปแบบของคู่เรียงลำดับ – (สวัสดี n) โดยที่ n คือจำนวนครั้ง “ สวัสดี” เกิดขึ้นในหนังสือเล่มหนึ่งโดยเฉพาะ

- ในที่สุด เฟส Reduce():
มาถึงช่วงสุดท้ายแล้ว – Reduce() หากคุณให้ความสนใจกับเวิร์กโฟลว์ทั้งหมด คุณอาจเดาได้อย่างถูกต้องว่า Reduce() จะนับแค่จำนวนครั้งที่แต่ละคำปรากฏในไฟล์อินพุต ทั้งหมดที่คุณต้องทำคือเพียงเพิ่มองค์ประกอบที่สองของคู่คำสั่งของเรา หากมี ให้พูดถึงคำว่า "สวัสดี" 200 ครั้งในหนังสือทุกเล่ม ผลลัพธ์สุดท้ายที่เราจะได้รับหลังจากช่วงนี้จะเป็น – (สวัสดี 200) เพียงแค่นับและบวก เราก็มาถึงผลลัพธ์แล้ว ทั้งหมดนี้เกิดขึ้นได้โดยใช้คอมพิวเตอร์หลายเครื่องและทำงานพร้อมกัน
การวิเคราะห์ SWOT MapReduce
กระบวน ทัศน์ MapReduce ทำให้ชีวิตของนักวิทยาศาสตร์ข้อมูลง่ายขึ้น มาดูกันว่าจุดแข็ง จุดอ่อน โอกาส และภัยคุกคามของกรอบนี้คืออะไร:
| จุดแข็ง | ประมวลผลชุดข้อมูลขนาดใหญ่ด้วยความเร็วสูงด้วยการประมวลผลแบบคู่ขนานในคลัสเตอร์แบบกระจาย |
| จุดอ่อน | สคริปต์ Map() และ Reduce() ทำงานอย่างต่อเนื่อง การอ่าน/เขียนดำเนินการบน HDFS ซึ่งช้าโดยการเปรียบเทียบ |
| โอกาส | การสร้างข้อมูลเชิงลึกจากชุดข้อมูลที่ถูกทิ้งก่อนหน้านี้และการประมวลผล Big Data ที่สร้างโดยองค์กร |
| ภัยคุกคาม | การดำเนินการ MapReduce แบบสแตนด์อโลน อาจชะลอความเร็วของอุตสาหกรรม Big Data หากไม่มีความก้าวหน้าเพียงพอในการวิเคราะห์ |
สรุปแล้ว…
เมื่อคุณคุ้นเคยกับการทำงานภายในของ MapReduce แล้ว คุณจะประทับใจที่เทคโนโลยีนี้ไม่ใช่เทคโนโลยีใหม่ เราใช้กระบวนทัศน์ที่คล้ายคลึงกันในการจัดการข้อมูลจำนวนมาก เช่น ผลการเลือกตั้ง มาเป็นเวลานาน ตอนนี้. คุณจะเข้าใจถึงความสำคัญของการทำให้สิ่งต่าง ๆ เรียบง่าย – MapReduce ไม่ได้ทำอะไรที่แปลกใหม่เลย และนั่นคือสิ่งที่ทำให้มันมีประสิทธิภาพมาก
หากคุณสนใจที่จะทราบข้อมูลเพิ่มเติมเกี่ยวกับ Big Data โปรดดูที่ PG Diploma in Software Development Specialization in Big Data program ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 7 กรณี ครอบคลุมภาษาและเครื่องมือในการเขียนโปรแกรม 14 รายการ เวิร์กช็อป ความช่วยเหลือด้านการเรียนรู้และจัดหางานอย่างเข้มงวดมากกว่า 400 ชั่วโมงกับบริษัทชั้นนำ
เรียนรู้ ปริญญาวิศวกรรมซอฟต์แวร์ ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม PG สำหรับผู้บริหาร โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว