Guía del autoestopista para MapReduce
Publicado: 2018-02-05Si ha leído nuestro artículo sobre herramientas y tecnologías de Big Data, es posible que recuerde haber encontrado el término " MapReduce ". Es uno de los componentes centrales de la arquitectura Hadoop y forma toda la capa de procesamiento de Hadoop.
En este artículo, hablaremos sobre MapReduce con un poco más de profundidad, pero de una manera amigable para principiantes. Para facilitar su comprensión, hemos desglosado el artículo de la siguiente manera: 
- Introducción
- Conceptos básicos
- Un análisis FODA completo
Introducción a MapReduce
MapReduce es esencialmente un concepto que permite el procesamiento ultrarrápido de conjuntos de datos masivos en un clúster distribuido. Es un modelo de programación patentado por Google que fue adoptado por primera vez por los chicos de Apache y ahora está en el corazón de todo el ecosistema de Hadoop. Su simplicidad es lo que lo hace tan efectivo y encomiable.
MapReduce sigue una lógica muy simple, que se ha seguido durante mucho tiempo para administrar las tareas diarias: cuando tiene que manejar una gran cantidad de material, emplear una gran cantidad de trabajadores acelerará el proceso (el antiguo adagio "demasiado muchos cocineros echan a perder el caldo” ¡no cabe aquí!).
Sin embargo, en este punto, surge una pregunta: ¿ MapReduce funciona bien SOLO con grandes conjuntos de datos?
La respuesta a esto es muy simple: los conjuntos de datos no necesariamente tienen que ser extremadamente grandes. Sin embargo, debido a razones económicas y computacionales, se recomienda poner en funcionamiento MapReduce solo si tiene grandes conjuntos de datos, lo suficientemente grandes para los cálculos tradicionales. Siempre es mejor procesar pequeños conjuntos de datos en su propia máquina local, como era antes de que se introdujera MapReduce . Porque, sinceramente, usar MapReduce para pequeños fragmentos de datos es muy parecido a intentar matar una araña con una ametralladora. La araña morirá, sin duda, pero ¿vale la pena?

Los conceptos básicos de MapReduce
A estas alturas, tiene una idea clara de qué es exactamente MapReduce. En esta sección, hablaremos un poco más sobre cómo funciona exactamente MapReduce : los conceptos básicos que ponen las ruedas en movimiento.
Si alguna vez te has encontrado con las matemáticas básicas en tu vida (¡que esperamos que tengas si estás leyendo esto!), debes conocer los conceptos de "pares ordenados". Es simplemente una forma de expresar dos datos en forma (x,y). Los pares ordenados son muy útiles para representar coordenadas, fracciones, identificaciones de empleados y otras formas de datos similares. MapReduce también se basa en gran medida en el concepto de pares ordenados: básicamente, cualquier dato se puede "asignar" en forma de un par ordenado y se puede "reducir" de varias maneras, según la declaración del problema en cuestión.
Suponga que se encuentra solo en una biblioteca digital que contiene cien mil libros y se le asigna la abrumadora tarea de encontrar la cantidad de veces que aparece una palabra en particular en todos los libros combinados .
Uf, ¿cómo empezarías?
El primer enfoque sería escribir un programa que repita cada palabra, directamente desde el Libro 1 – Palabra 1, hasta el Libro n – Palabra n, y siga incrementando una variable de contador cada vez que encuentre la palabra necesaria. Solo imaginar esto te haría darte cuenta de la cantidad de tiempo que tomará realizar esta tarea.
Ahora, echemos un vistazo a cómo MapReduce responderá a la tarea:
- Requisitos de MapReduce:
MapReduce funciona bien en un clúster distribuido. ¿Qué es un clúster distribuido, te preguntarás?
Muy simple, es una gran cantidad (¡a menudo miles!) de computadoras básicas (computadoras de bajo costo) entretejidas en una red que realiza una sola operación.
Ahora, suponga que tiene uno de esos clústeres. Para nuestro enunciado del problema, la entrada a este grupo será el contenido de todos los libros. Tan pronto como ingresamos estos datos en nuestro sistema, se copian en todas y cada una de las computadoras (nodos) en el clúster (suponiendo que solo estamos tratando con un trabajo en este momento). Esto se hace para proporcionar un nivel de tolerancia a fallas, para ayudarlo en caso de pérdida de datos.
- Programación en MapReduce
Dado que MapReduce funciona en dos fases: mapear y reducir, tenemos que escribir dos programas, Map() y Reduce(), para poner en marcha un flujo de trabajo de MapReduce . Anteriormente, había utilizado Java para escribir estos programas, pero ahora, debido al rápido crecimiento de la ciencia de datos, el marco MapReduce se ha vuelto lo suficientemente flexible para manejar códigos escritos en Python o R también.
Los scripts que escriba se ejecutarán uno tras otro, es decir, de manera sucesiva. Esto nos lleva a uno de los principales inconvenientes del paradigma MapReduce : el hecho de que no puede ejecutar ambos scripts en paralelo. Lograr eso hará que MapReduc sea mucho más rápido, y eso ha sido objeto de una extensa investigación.

- Paralelización del flujo de trabajo:
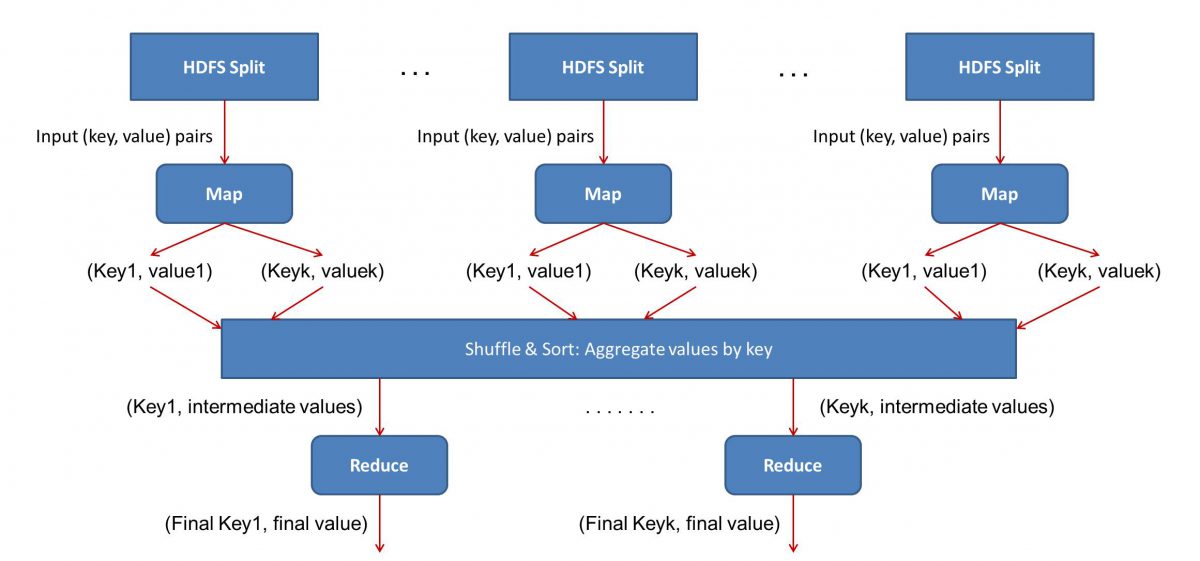
La entrada (contenido de todos los libros) se dividirá en varios segmentos (igual a la cantidad de computadoras en el clúster, esencialmente), y a cada computadora se le asignará un segmento en particular. Supongamos que hemos dividido el archivo en líneas, luego se le puede pedir al nodo 1 que se ocupe de las líneas 1 a 10,000, se le puede pedir al nodo 2 que se ocupe de las líneas 10,001 a 20,000, y así sucesivamente. (Recuerde que estas son solo cifras ilustrativas: los segmentos son mucho más grandes en la vida real)
Luego, cada máquina ejecutará su programa Map().
- El programa Mapa():
El programa Map() hace exactamente lo que iba a hacer antes de asignarle la tarea a MapReduce : escanear el archivo y leer una palabra a la vez. El beneficio aquí es que se ejecutará simultáneamente en varias computadoras, por lo que reducirá el tiempo por múltiples. La salida de la función Map() es un par ordenado. En este caso, será simplemente (palabra, cuenta), es decir, cuando la función Map() encuentra la palabra “hola” (asumiendo que esa es la palabra que estamos buscando), simplemente expulsará (hola, 1) como un producción. Dado que se está trabajando en varias partes del cuerpo del código al mismo tiempo, ¡tendrá una versión mapeada de su conjunto de datos en muy poco tiempo! Para apreciar la simplicidad de MapReduce , tenga en cuenta que la operación que se realiza aquí es bastante básica y no requiere cálculos intensivos.
- Barajar los resultados asignados:
Una vez que obtenemos los pares ordenados finales de la función Map(), los resultados se barajan. Eso simplemente significa que los pares (palabra, recuento) con la misma palabra se transfieren a una sola máquina.
Ahora, si está familiarizado con la programación, se dará cuenta de que hay un límite en el que esto se puede lograr. Hay literalmente miles de millones de palabras y solo un número finito de computadoras en el clúster. En este punto, es importante tener en cuenta que la fase de reproducción aleatoria no es obligatoria para que funcione MapReduce , simplemente hace que el script Reduce() sea mucho más rápido al organizar las cosas en un orden. Por ahora, digamos que mezclamos las salidas de Map y ahora tenemos todas las instancias de la palabra "hola" en una sola computadora en forma de un par ordenado (hola, n) donde n es el número de veces " hola” ocurrió en un libro en particular.

- Finalmente, la fase Reduce():
Finalmente, llegamos a la última fase: Reducir(). Si estaba prestando atención a todo el flujo de trabajo, es posible que haya adivinado correctamente que Reduce() solo contará la cantidad de veces que aparece cada palabra en el archivo de entrada. Todo lo que tiene que hacer es simplemente agregar el segundo componente de nuestros pares ordenados. Si hay, digamos 200 menciones de la palabra “hola” en todos los libros, el resultado final que obtendremos después de esta fase será – (hola, 200). Simplemente contando y sumando, hemos llegado al resultado. Todo hecho posible mediante el empleo de varias computadoras y haciéndolas funcionar simultáneamente.
Análisis DAFO de MapReduce
El paradigma MapReduce ha facilitado la vida de los científicos de datos. Echemos un vistazo a cuáles son las fortalezas, debilidades, oportunidades y amenazas de este marco:
| Fortalezas | Procesa conjuntos de datos masivos a velocidades ultrarrápidas al procesarlos en paralelo en clústeres distribuidos. |
| debilidades | Los scripts Map() y Reduce() se ejecutan sucesivamente. Las operaciones de lectura/escritura se realizan en HDFS, que es lento en comparación |
| Oportunidades | Generar conocimientos a partir de conjuntos de datos descartados anteriormente y procesar Big Data generado por las organizaciones. |
| amenazas | Las operaciones independientes de MapReduce pueden ralentizar el ritmo de la industria de Big Data sin un avance suficiente en el análisis. |
En conclusión…
Ahora que está familiarizado con el funcionamiento interno de MapReduce , apreciará que de ninguna manera es una tecnología nueva: hemos estado usando paradigmas similares para manejar grandes volúmenes de datos, como resultados de elecciones, durante mucho tiempo. ahora. También te darás cuenta de la importancia de mantener las cosas simples: MapReduce no hace nada especial, en absoluto, y eso es lo que lo hace tan poderoso.
Si está interesado en saber más sobre Big Data, consulte nuestro programa PG Diploma in Software Development Specialization in Big Data, que está diseñado para profesionales que trabajan y proporciona más de 7 estudios de casos y proyectos, cubre 14 lenguajes y herramientas de programación, prácticas talleres, más de 400 horas de aprendizaje riguroso y asistencia para la colocación laboral con las mejores empresas.
Aprenda títulos de ingeniería de software en línea de las mejores universidades del mundo. Obtenga programas Executive PG, programas de certificados avanzados o programas de maestría para acelerar su carrera.