
TensorFlow 入門:機器學習教程
已發表: 2022-03-11TensorFlow 是谷歌創建的一個開源軟件庫,用於實現機器學習和深度學習系統。 這兩個名稱包含一系列功能強大的算法,它們具有共同的挑戰——允許計算機學習如何自動發現複雜模式和/或做出最佳決策。
如果您對這些系統的詳細信息感興趣,可以從關於機器學習和深度學習的 Toptal 博客文章中了解更多信息。
TensorFlow 的核心是數據流編程庫。 它利用各種優化技術使數學表達式的計算更容易和更高效。
TensorFlow 的一些關鍵特性包括:
- 有效地處理涉及多維數組的數學表達式
- 對深度神經網絡和機器學習概念的良好支持
- GPU/CPU 計算可以在兩種架構上執行相同的代碼
- 跨機器計算和海量數據集的高可擴展性
這些功能共同使 TensorFlow 成為生產規模的機器智能的完美框架。
在本 TensorFlow 教程中,您將了解如何在 TensorFlow 中使用簡單而強大的機器學習方法,以及如何使用它的一些輔助庫來調試、可視化和調整使用它創建的模型。
安裝 TensorFlow
我們將使用 TensorFlow Python API,它適用於 Python 2.7 和 Python 3.3+。 GPU 版本(僅限 Linux)需要 Cuda Toolkit 7.0+ 和 cuDNN v2+。
我們將使用 Conda 包依賴管理系統來安裝 TensorFlow。 Conda 允許我們在一台機器上分離多個環境。 您可以從此處了解如何安裝 Conda。
安裝 Conda 後,我們可以創建用於 TensorFlow 安裝和使用的環境。 以下命令將使用一些額外的庫(如 NumPy)創建我們的環境,一旦我們開始使用 TensorFlow,這將非常有用。
這個環境裡面安裝的Python版本是2.7,我們將在本文中使用這個版本。
conda create --name TensorflowEnv biopython 為了方便起見,我們在這里安裝 biopython 而不僅僅是 NumPy。 這包括 NumPy 和我們將需要的一些其他包。 您始終可以根據需要使用conda install或pip install命令安裝軟件包。
以下命令將激活創建的 Conda 環境。 我們將能夠使用安裝在其中的包,而無需與全局或其他環境中安裝的包混合。
source activate TensorFlowEnvpip 安裝工具是 Conda 環境的標準部分。 我們將使用它來安裝 TensorFlow 庫。 在此之前,好的第一步是將 pip 更新到最新版本,使用以下命令:
pip install --upgrade pip現在我們準備好安裝 TensorFlow,運行:
pip install tensorflowTensorFlow 的下載和構建可能需要幾分鐘時間。 在撰寫本文時,這將安裝 TensorFlow 1.1.0。
數據流圖
在 TensorFlow 中,計算是使用數據流圖來描述的。 圖的每個節點代表一個數學運算(如加法、除法或乘法)的實例,每條邊都是一個多維數據集(張量),在其上執行操作。
由於 TensorFlow 與計算圖一起工作,它們在每個節點代表一個操作的實例化的地方進行管理,其中每個操作都有零個或多個輸入和零個或多個輸出。
TensorFlow 中的邊可以分為兩類:普通邊傳輸數據結構(張量),其中一個操作的輸出可能成為另一操作的輸入,特殊邊用於控制兩個節點之間的依賴關係以設置一個節點等待另一個節點完成的操作順序。
簡單表達式
在我們繼續討論 TensorFlow 的元素之前,我們將首先進行一次使用 TensorFlow 的會議,以了解 TensorFlow 程序的外觀。
讓我們從簡單的表達式開始,假設出於某種原因,我們想以 TensorFlow 方式計算函數y = 5*x + 13 。
在簡單的 Python 代碼中,它看起來像:
x = -2.0 y = 5*x + 13 print y在這種情況下,這給了我們 3.0 的結果。
現在我們將上述表達式轉換為 TensorFlow 項。
常數
在 TensorFlow 中,常量是使用函數常量創建的,該函數具有簽名constant(value, dtype=None, shape=None, name='Const', verify_shape=False) ,其中value是一個實際的常量值,將用於進一步計算, dtype是數據類型參數(例如,float32/64、int8/16 等), shape是可選尺寸, name是張量的可選名稱,最後一個參數是一個布爾值,表示驗證價值觀的形式。
如果您需要在訓練模型中具有特定值的常量,則可以使用constant對象,如下例所示:
z = tf.constant(5.2, name="x", dtype=tf.float32)變量
TensorFlow 中的變量是包含張量的內存緩衝區,這些張量必須被顯式初始化並在圖中使用以維護跨會話的狀態。 通過簡單地調用構造函數,變量被添加到計算圖中。
一旦您開始訓練模型,變量就特別有用,它們用於保存和更新參數。 作為構造函數的參數傳遞的初始值表示可以轉換或作為張量返回的張量或對象。 這意味著,如果我們想用一些預定義的或隨機的值填充一個變量,以便以後在訓練過程中使用並在迭代中更新,我們可以通過以下方式定義它:
k = tf.Variable(tf.zeros([1]), name="k")在 TensorFlow 中使用變量的另一種方法是在計算中該變量不可訓練,可以通過以下方式定義:
k = tf.Variable(tf.add(a, b), trainable=False)會話
為了實際評估節點,我們必須在會話中運行計算圖。
會話封裝了 TensorFlow 運行時的控制和狀態。 沒有參數的會話將使用在當前會話中創建的默認圖,否則會話類接受一個圖參數,該參數將在該會話中執行。
下面是一個簡短的代碼片段,展示瞭如何在 TensorFlow 中使用上面定義的術語來計算簡單的線性函數。
import tensorflow as tf x = tf.constant(-2.0, name="x", dtype=tf.float32) a = tf.constant(5.0, name="a", dtype=tf.float32) b = tf.constant(13.0, name="b", dtype=tf.float32) y = tf.Variable(tf.add(tf.multiply(a, x), b)) init = tf.global_variables_initializer() with tf.Session() as session: session.run(init) print session.run(y)使用 TensorFlow:定義計算圖
使用數據流圖的好處是執行模型與其執行分離(在 CPU、GPU 或某種組合上),一旦實現,TensorFlow 中的軟件可以在所有復雜性與代碼相關的 CPU 或 GPU 上使用執行被隱藏。
計算圖可以在使用 TensorFlow 庫的過程中構建,而無需顯式實例化 Graph 對象。
TensorFlow 中的 Graph 對象可以通過像c = tf.add(a, b)這樣的簡單代碼行來創建。 這將創建一個操作節點,該節點採用兩個張量a和b ,產生它們的總和c作為輸出。
計算圖是一個使用庫的內置進程,無需直接調用圖對象。 TensorFlow 中的圖形對象包含一組操作和張量作為數據單元,用於在允許相同過程的操作之間使用,並且包含多個圖形,其中每個圖形將分配給不同的會話。 例如,簡單的代碼行c = tf.add(a, b)將創建一個操作節點,該節點將兩個張量a和b作為輸入,並產生它們的總和c作為輸出。
TensorFlow 還提供了一種饋送機制,用於將張量修補到圖中的任何操作,其中饋送用張量值替換操作的輸出。 提要數據在run()函數調用中作為參數傳遞。
佔位符是 TensorFlow 允許開發人員通過綁定在某些表達式中的佔位符將數據注入計算圖中的方式。 佔位符的簽名是:
placeholder(dtype, shape=None, name=None)其中 dtype 是張量中元素的類型,可以提供要輸入的張量的形狀和操作的名稱。
如果形狀沒有通過,這個張量可以被輸入任何形狀。 一個重要的注意事項是佔位符張量必須提供數據,否則,在執行會話時,如果缺少該部分,佔位符會生成具有以下結構的錯誤:
InvalidArgumentError (see above for traceback): You must feed a value for placeholder tensor 'y' with dtype float佔位符的優點是它們允許開發人員創建操作和一般的計算圖,而無需為此提前提供數據,並且可以在運行時從外部源添加數據。
讓我們來看一個簡單的問題,即以 TensorFlow 方式將兩個整數x和y相乘,其中一個佔位符將通過 session run方法與 feed 機制一起使用。
import tensorflow as tf x = tf.placeholder(tf.float32, name="x") y = tf.placeholder(tf.float32, name="y") z = tf.multiply(x, y, name="z") with tf.Session() as session: print session.run(z, feed_dict={x: 2.1, y: 3.0})使用 TensorBoard 可視化計算圖
TensorBoard 是一個用於分析數據流圖的可視化工具。 這對於更好地理解機器學習模型很有用。
使用 TensorBoard,您可以深入了解有關參數的不同類型的統計數據以及有關計算圖的一般部分的詳細信息。 深度神經網絡具有大量節點並不罕見。 TensorBoard 允許開發人員深入了解每個節點以及如何在 TensorFlow 運行時執行計算。
現在讓我們回到本 TensorFlow 教程開頭的示例,其中我們定義了格式y = a*x + b的線性函數。
為了記錄會話中的事件,以後可以在 TensorBoard 中使用,TensorFlow 提供了FileWriter類。 它可用於創建事件文件以存儲摘要,其中構造函數接受六個參數,如下所示:
__init__(logdir, graph=None, max_queue=10, flush_secs=120, graph_def=None, filename_suffix=None)其中 logdir 參數是必需的,其他有默認值。 圖參數將從訓練程序中創建的會話對像傳遞。 完整的示例代碼如下所示:
import tensorflow as tf x = tf.constant(-2.0, name="x", dtype=tf.float32) a = tf.constant(5.0, name="a", dtype=tf.float32) b = tf.constant(13.0, name="b", dtype=tf.float32) y = tf.Variable(tf.add(tf.multiply(a, x), b)) init = tf.global_variables_initializer() with tf.Session() as session: merged = tf.summary.merge_all() // new writer = tf.summary.FileWriter("logs", session.graph) // new session.run(init) print session.run(y) 我們只添加了兩條新線。 我們合併了默認圖表中收集的所有摘要,並且FileWriter分別用於將事件轉儲到文件中,如上所述。
運行程序後,我們在目錄日誌中有文件,最後一步是運行tensorboard :
tensorboard --logdir logs/ 現在 TensorBoard 已啟動並在默認端口 6006 上運行。打開http://localhost:6006並單擊 Graphs 菜單項(位於頁面頂部)後,您將能夠看到圖形,就像在下圖中:
TensorBoard 標記常量和匯總節點特定符號,如下所述。
TensorFlow 數學
張量是 TensorFlow 中的基本數據結構,它們表示數據流圖中的連接邊。
張量只是標識一個多維數組或列表。 張量結構可以用三個參數來識別:等級、形狀和類型。
- Rank:標識張量的維數。 秩稱為張量的階數或 n 維,例如,秩 1 的張量是向量或秩 2 的張量是矩陣。
- 形狀:張量的形狀是它的行數和列數。
- 類型:分配給張量元素的數據類型。
要在 TensorFlow 中構建張量,我們可以構建一個 n 維數組。 這可以通過使用 NumPy 庫或將 Python n 維數組轉換為 TensorFlow 張量來輕鬆完成。
為了構建一維張量,我們將使用一個 NumPy 數組,我們將通過傳遞一個內置的 Python 列表來構建它。
import numpy as np tensor_1d = np.array([1.45, -1, 0.2, 102.1])使用這種數組類似於使用內置 Python 列表。 主要區別在於 NumPy 數組還包含一些附加屬性,如維度、形狀和類型。
> > print tensor1d [ 1.45 -1. 0.2 102.1 ] > > print tensor1d[0] 1.45 > > print tensor1d[2] 0.2 > > print tensor1d.ndim 1 > > print tensor1d.shape (4,) > > print tensor1d.dtype float64NumPy 數組可以通過輔助函數 convert_to_tensor 輕鬆轉換為 TensorFlow 張量,幫助開發人員將 Python 對象轉換為張量對象。 此函數接受張量對象、NumPy 數組、Python 列表和 Python 標量。
tensor = tf.convert_to_tensor(tensor_1d, dtype=tf.float64)現在,如果我們將張量綁定到 TensorFlow 會話,我們將能夠看到轉換的結果。
tensor = tf.convert_to_tensor(tensor_1d, dtype=tf.float64) with tf.Session() as session: print session.run(tensor) print session.run(tensor[0]) print session.run(tensor[1])輸出:
[ 1.45 -1. 0.2 102.1 ] 1.45 -1.0我們可以用類似的方式創建一個二維張量或矩陣:
tensor_2d = np.array(np.random.rand(4, 4), dtype='float32') tensor_2d_1 = np.array(np.random.rand(4, 4), dtype='float32') tensor_2d_2 = np.array(np.random.rand(4, 4), dtype='float32') m1 = tf.convert_to_tensor(tensor_2d) m2 = tf.convert_to_tensor(tensor_2d_1) m3 = tf.convert_to_tensor(tensor_2d_2) mat_product = tf.matmul(m1, m2) mat_sum = tf.add(m2, m3) mat_det = tf.matrix_determinant(m3) with tf.Session() as session: print session.run(mat_product) print session.run(mat_sum) print session.run(mat_det)張量運算
在上面的例子中,我們介紹了一些 TensorFlow 對向量和矩陣的操作。 這些操作對張量執行某些計算。 下表顯示了這些計算。
| TensorFlow 算子 | 描述 |
|---|---|
| tf.add | x+y |
| tf.減法 | xy |
| tf.multiply | x*y |
| tf.div | x/y |
| tf.mod | x % y |
| tf.abs | |x| |
| tf.negative | -X |
| tf.sign | 符號(x) |
| 方陣 | x*x |
| tf.round | 回合(x) |
| tf.sqrt | 平方(x) |
| tf.pow | x^y |
| tf.exp | e^x |
| tf.log | 日誌(x) |
| tf.最大值 | 最大值(x,y) |
| tf.minimum | 最小值(x, y) |
| tf.cos | 餘弦(x) |
| tf.sin | 罪(x) |
上表中列出的 TensorFlow 操作適用於張量對象,並且是按元素執行的。 因此,如果您想計算向量 x 的餘弦,TensorFlow 操作將對傳遞的張量中的每個元素進行計算。
tensor_1d = np.array([0, 0, 0]) tensor = tf.convert_to_tensor(tensor_1d, dtype=tf.float64) with tf.Session() as session: print session.run(tf.cos(tensor))輸出:
[ 1. 1. 1.]矩陣運算
矩陣運算對於機器學習模型非常重要,例如線性回歸,因為它們經常在其中使用。 TensorFlow 支持所有最常見的矩陣運算,例如乘法、轉置、求逆、計算行列式、求解線性方程等等。
接下來,我們將解釋一些矩陣運算。 當涉及機器學習模型時,它們往往很重要,例如線性回歸。 讓我們編寫一些代碼來執行基本的矩陣運算,例如乘法、獲得轉置、獲得行列式、乘法、sol 等等。
下面是調用這些操作的基本示例。
import tensorflow as tf import numpy as np def convert(v, t=tf.float32): return tf.convert_to_tensor(v, dtype=t) m1 = convert(np.array(np.random.rand(4, 4), dtype='float32')) m2 = convert(np.array(np.random.rand(4, 4), dtype='float32')) m3 = convert(np.array(np.random.rand(4, 4), dtype='float32')) m4 = convert(np.array(np.random.rand(4, 4), dtype='float32')) m5 = convert(np.array(np.random.rand(4, 4), dtype='float32')) m_tranpose = tf.transpose(m1) m_mul = tf.matmul(m1, m2) m_det = tf.matrix_determinant(m3) m_inv = tf.matrix_inverse(m4) m_solve = tf.matrix_solve(m5, [[1], [1], [1], [1]]) with tf.Session() as session: print session.run(m_tranpose) print session.run(m_mul) print session.run(m_inv) print session.run(m_det) print session.run(m_solve)轉換數據
減少
TensorFlow 支持不同類型的歸約。 歸約是一種通過在這些維度上執行某些操作來從張量中刪除一個或多個維度的操作。 可以在此處找到當前版本的 TensorFlow 支持的縮減列表。 我們將在下面的示例中介紹其中的一些。

import tensorflow as tf import numpy as np def convert(v, t=tf.float32): return tf.convert_to_tensor(v, dtype=t) x = convert( np.array( [ (1, 2, 3), (4, 5, 6), (7, 8, 9) ]), tf.int32) bool_tensor = convert([(True, False, True), (False, False, True), (True, False, False)], tf.bool) red_sum_0 = tf.reduce_sum(x) red_sum = tf.reduce_sum(x, axis=1) red_prod_0 = tf.reduce_prod(x) red_prod = tf.reduce_prod(x, axis=1) red_min_0 = tf.reduce_min(x) red_min = tf.reduce_min(x, axis=1) red_max_0 = tf.reduce_max(x) red_max = tf.reduce_max(x, axis=1) red_mean_0 = tf.reduce_mean(x) red_mean = tf.reduce_mean(x, axis=1) red_bool_all_0 = tf.reduce_all(bool_tensor) red_bool_all = tf.reduce_all(bool_tensor, axis=1) red_bool_any_0 = tf.reduce_any(bool_tensor) red_bool_any = tf.reduce_any(bool_tensor, axis=1) with tf.Session() as session: print "Reduce sum without passed axis parameter: ", session.run(red_sum_0) print "Reduce sum with passed axis=1: ", session.run(red_sum) print "Reduce product without passed axis parameter: ", session.run(red_prod_0) print "Reduce product with passed axis=1: ", session.run(red_prod) print "Reduce min without passed axis parameter: ", session.run(red_min_0) print "Reduce min with passed axis=1: ", session.run(red_min) print "Reduce max without passed axis parameter: ", session.run(red_max_0) print "Reduce max with passed axis=1: ", session.run(red_max) print "Reduce mean without passed axis parameter: ", session.run(red_mean_0) print "Reduce mean with passed axis=1: ", session.run(red_mean) print "Reduce bool all without passed axis parameter: ", session.run(red_bool_all_0) print "Reduce bool all with passed axis=1: ", session.run(red_bool_all) print "Reduce bool any without passed axis parameter: ", session.run(red_bool_any_0) print "Reduce bool any with passed axis=1: ", session.run(red_bool_any)輸出:
Reduce sum without passed axis parameter: 45 Reduce sum with passed axis=1: [ 6 15 24] Reduce product without passed axis parameter: 362880 Reduce product with passed axis=1: [ 6 120 504] Reduce min without passed axis parameter: 1 Reduce min with passed axis=1: [1 4 7] Reduce max without passed axis parameter: 9 Reduce max with passed axis=1: [3 6 9] Reduce mean without passed axis parameter: 5 Reduce mean with passed axis=1: [2 5 8] Reduce bool all without passed axis parameter: False Reduce bool all with passed axis=1: [False False False] Reduce bool any without passed axis parameter: True Reduce bool any with passed axis=1: [ True True True]約簡算子的第一個參數是我們要約簡的張量。 第二個參數是我們想要執行縮減的維度的索引。 該參數是可選的,如果未傳遞,則將沿所有維度執行歸約。
我們可以看一下reduce_sum操作。 我們傳遞一個二維張量,並希望沿維度 1 減少它。
在我們的例子中,結果總和將是:
[1 + 2 + 3 = 6, 4 + 5 + 6 = 15, 7 + 8 + 9 = 24]如果我們傳遞維度 0,結果將是:
[1 + 4 + 7 = 12, 2 + 5 + 8 = 15, 3 + 6 + 9 = 18]如果我們不通過任何軸,則結果只是以下各項的總和:
1 + 4 + 7 = 12, 2 + 5 + 8 = 15, 3 + 6 + 9 = 45所有歸約函數都有類似的接口,並在 TensorFlow 歸約文檔中列出。
分割
分段是一個過程,其中一個維度是將維度映射到提供的分段索引的過程,結果元素由索引行確定。
分割實際上是對重複索引下的元素進行分組,例如,在我們的例子中,我們在張量tens1上應用了分段 id [0, 0, 1, 2, 2] ,這意味著第一個和第二個數組將在分割後進行轉換運算(在我們的例子中求和),將得到一個新數組,它看起來像(2, 8, 1, 0) = (2+0, 5+3, 3-2, -5+5) 。 張量tens1中的第三個元素保持不變,因為它沒有分組在任何重複的索引中,並且最後兩個數組的求和方式與第一組的情況相同。 除了求和,TensorFlow 還支持乘積、均值、最大值和最小值。
import tensorflow as tf import numpy as np def convert(v, t=tf.float32): return tf.convert_to_tensor(v, dtype=t) seg_ids = tf.constant([0, 0, 1, 2, 2]) tens1 = convert(np.array([(2, 5, 3, -5), (0, 3, -2, 5), (4, 3, 5, 3), (6, 1, 4, 0), (6, 1, 4, 0)]), tf.int32) tens2 = convert(np.array([1, 2, 3, 4, 5]), tf.int32) seg_sum = tf.segment_sum(tens1, seg_ids) seg_sum_1 = tf.segment_sum(tens2, seg_ids) with tf.Session() as session: print "Segmentation sum tens1: ", session.run(seg_sum) print "Segmentation sum tens2: ", session.run(seg_sum_1) Segmentation sum tens1: [[ 2 8 1 0] [ 4 3 5 3] [12 2 8 0]] Segmentation sum tens2: [3 3 9]序列實用程序
序列實用程序包括以下方法:
- argmin 函數,它返回輸入張量軸上具有最小值的索引,
- argmax 函數,它返回輸入張量軸上具有最大值的索引,
- setdiff,計算兩個數字或字符串列表之間的差異,
- where 函數,它將從兩個傳遞的元素 x 或 y 返回元素,這取決於傳遞的條件,或者
- unique 函數,它將返回一維張量中的唯一元素。
我們在下面展示了幾個執行示例:
import numpy as np import tensorflow as tf def convert(v, t=tf.float32): return tf.convert_to_tensor(v, dtype=t) x = convert(np.array([ [2, 2, 1, 3], [4, 5, 6, -1], [0, 1, 1, -2], [6, 2, 3, 0] ])) y = convert(np.array([1, 2, 5, 3, 7])) z = convert(np.array([1, 0, 4, 6, 2])) arg_min = tf.argmin(x, 1) arg_max = tf.argmax(x, 1) unique = tf.unique(y) diff = tf.setdiff1d(y, z) with tf.Session() as session: print "Argmin = ", session.run(arg_min) print "Argmax = ", session.run(arg_max) print "Unique_values = ", session.run(unique)[0] print "Unique_idx = ", session.run(unique)[1] print "Setdiff_values = ", session.run(diff)[0] print "Setdiff_idx = ", session.run(diff)[1] print session.run(diff)[1]輸出:
Argmin = [2 3 3 3] Argmax = [3 2 1 0] Unique_values = [ 1. 2. 5. 3. 7.] Unique_idx = [0 1 2 3 4] Setdiff_values = [ 5. 3. 7.] Setdiff_idx = [2 3 4]使用 TensorFlow 進行機器學習
在本節中,我們將展示一個使用 TensorFlow 的機器學習用例。 第一個示例是使用 kNN 方法對數據進行分類的算法,第二個示例將使用線性回歸算法。
神經網絡
第一個算法是k-最近鄰(kNN)。 它是一種監督學習算法,使用距離度量(例如歐幾里得距離)對訓練數據進行分類。 它是最簡單的算法之一,但對於數據分類仍然非常強大。 該算法的優點:
- 當訓練模型足夠大時,準確率很高,並且
- 通常對異常值不敏感,我們不需要對數據進行任何假設。
該算法的缺點:
- 計算成本高,並且
- 需要大量內存,其中需要將新的分類數據添加到所有初始訓練實例中。
我們將在此代碼示例中使用的距離是歐幾里得,它定義了兩點之間的距離,如下所示:
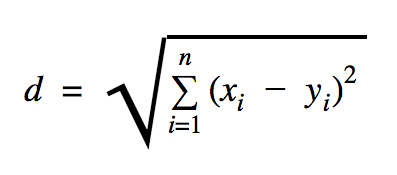
在這個公式中, n是空間的維數, x是訓練數據的向量, y是我們要分類的新數據點。
import os import numpy as np import tensorflow as tf ccf_train_data = "train_dataset.csv" ccf_test_data = "test_dataset.csv" dataset_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), '../datasets')) ccf_train_filepath = os.path.join(dataset_dir, ccf_train_data) ccf_test_filepath = os.path.join(dataset_dir, ccf_test_data) def load_data(filepath): from numpy import genfromtxt csv_data = genfromtxt(filepath, delimiter=",", skip_header=1) data = [] labels = [] for d in csv_data: data.append(d[:-1]) labels.append(d[-1]) return np.array(data), np.array(labels) train_dataset, train_labels = load_data(ccf_train_filepath) test_dataset, test_labels = load_data(ccf_test_filepath) train_pl = tf.placeholder("float", [None, 28]) test_pl = tf.placeholder("float", [28]) knn_prediction = tf.reduce_sum(tf.abs(tf.add(train_pl, tf.negative(test_pl))), axis=1) pred = tf.argmin(knn_prediction, 0) with tf.Session() as tf_session: missed = 0 for i in xrange(len(test_dataset)): knn_index = tf_session.run(pred, feed_dict={train_pl: train_dataset, test_pl: test_dataset[i]}) print "Predicted class {} -- True class {}".format(train_labels[knn_index], test_labels[i]) if train_labels[knn_index] != test_labels[i]: missed += 1 tf.summary.FileWriter("../samples/article/logs", tf_session.graph) print "Missed: {} -- Total: {}".format(missed, len(test_dataset))我們在上面示例中使用的數據集是可以在 Kaggle 數據集部分找到的數據集。 我們使用了包含歐洲持卡人信用卡進行的交易的那個。 我們在沒有任何清理或過濾的情況下使用數據,並且根據 Kaggle 中對該數據集的描述,它是高度不平衡的。 該數據集包含 31 個變量:時間、V1、...、V28、數量和類別。 在此代碼示例中,我們僅使用 V1、...、V28 和 Class。 用 1 標記欺詐性交易,用 0 標記非欺詐性交易。
代碼示例主要包含我們在前面部分中描述的內容,但我們介紹了加載數據集的函數。 函數load_data(filepath)將 CSV 文件作為參數,並將返回一個元組,其中包含在 CSV 中定義的數據和標籤。
在該函數下方,我們為測試和訓練數據定義了佔位符。 在預測模型中使用訓練數據來解析需要分類的輸入數據的標籤。 在我們的例子中,kNN 使用歐幾里得距離來獲得最近的標籤。
錯誤率可以通過簡單除以分類器遺漏的樣本總數除以該數據集的樣本總數(在我們的例子中為 0.2)來計算(即,分類器為我們提供了 20% 測試數據的錯誤數據標籤)。
線性回歸
線性回歸算法尋找兩個變量之間的線性關係。 如果我們將因變量標記為 y,將自變量標記為 x,那麼我們正在嘗試估計函數y = Wx + b的參數。
線性回歸是應用科學領域廣泛使用的算法。 該算法允許在實現中添加機器學習的兩個重要概念:成本函數和用於找到函數最小值的梯度下降法。
使用此方法實現的機器學習算法必須預測y的值作為x的函數,其中線性回歸算法將確定值W和b ,它們實際上是未知數,並且在整個訓練過程中確定。 選擇成本函數,通常使用均方誤差,其中梯度下降是用於找到成本函數的局部最小值的優化算法。
梯度下降法只是一個局部函數最小值,但它可以通過在找到局部最小值後隨機選擇一個新起點並重複該過程多次來用於搜索全局最小值。 如果函數的最小值數量有限並且嘗試次數非常多,那麼很有可能在某個時候發現全局最小值。 關於這項技術的更多細節,我們將留給我們在介紹部分提到的文章。
import tensorflow as tf import numpy as np test_data_size = 2000 iterations = 10000 learn_rate = 0.005 def generate_test_values(): train_x = [] train_y = [] for _ in xrange(test_data_size): x1 = np.random.rand() x2 = np.random.rand() x3 = np.random.rand() y_f = 2 * x1 + 3 * x2 + 7 * x3 + 4 train_x.append([x1, x2, x3]) train_y.append(y_f) return np.array(train_x), np.transpose([train_y]) x = tf.placeholder(tf.float32, [None, 3], name="x") W = tf.Variable(tf.zeros([3, 1]), name="W") b = tf.Variable(tf.zeros([1]), name="b") y = tf.placeholder(tf.float32, [None, 1]) model = tf.add(tf.matmul(x, W), b) cost = tf.reduce_mean(tf.square(y - model)) train = tf.train.GradientDescentOptimizer(learn_rate).minimize(cost) train_dataset, train_values = generate_test_values() init = tf.global_variables_initializer() with tf.Session() as session: session.run(init) for _ in xrange(iterations): session.run(train, feed_dict={ x: train_dataset, y: train_values }) print "cost = {}".format(session.run(cost, feed_dict={ x: train_dataset, y: train_values })) print "W = {}".format(session.run(W)) print "b = {}".format(session.run(b))輸出:
cost = 3.1083032809e-05 W = [[ 1.99049103] [ 2.9887135 ] [ 6.98754263]] b = [ 4.01742554] 在上面的示例中,我們有兩個新變量,我們稱之為cost和train 。 使用這兩個變量,我們定義了一個我們想要在訓練模型中使用的優化器和我們想要最小化的函數。
最後, W和b的輸出參數應該與generate_test_values函數中定義的相同。 在第 17 行,我們實際上定義了一個函數,用於生成線性數據點以訓練w1=2 、 w2=3 、 w3=7和b=4 。 上述示例的線性回歸是多元的,其中使用了多個自變量。
結論
正如您在本 TensorFlow 教程中所見,TensorFlow 是一個強大的框架,它使處理數學表達式和多維數組變得輕而易舉——這在機器學習中是必不可少的。 它還抽像出執行數據圖和縮放的複雜性。
隨著時間的推移,TensorFlow 越來越受歡迎,現在被開發人員使用深度學習方法解決問題,用於圖像識別、視頻檢測、文本處理(如情感分析等)。與任何其他庫一樣,您可能需要一些時間才能使用TensorFlow 所基於的概念。 而且,一旦你這樣做了,在文檔和社區支持的幫助下,將問題表示為數據圖並使用 TensorFlow 解決它們可以使大規模機器學習變得不那麼乏味。