
TensorFlow 시작하기: 기계 학습 튜토리얼
게시 됨: 2022-03-11TensorFlow는 기계 학습 및 딥 러닝 시스템을 구현하는 데 사용되는 Google에서 만든 오픈 소스 소프트웨어 라이브러리입니다. 이 두 이름에는 컴퓨터가 복잡한 패턴을 자동으로 발견하고 최상의 결정을 내리는 방법을 학습할 수 있도록 하는 공통 과제를 공유하는 일련의 강력한 알고리즘이 포함되어 있습니다.
이러한 시스템에 대한 세부 정보에 관심이 있는 경우 기계 학습 및 딥 러닝에 대한 Toptal 블로그 게시물에서 자세히 알아볼 수 있습니다.
TensorFlow의 핵심은 데이터 흐름 프로그래밍을 위한 라이브러리입니다. 다양한 최적화 기술을 활용하여 수학 표현식의 계산을 더 쉽고 더 효율적으로 만듭니다.
TensorFlow의 주요 기능 중 일부는 다음과 같습니다.
- 다차원 배열을 포함하는 수학적 표현식으로 효율적으로 작동
- 심층 신경망 및 기계 학습 개념에 대한 우수한 지원
- 두 아키텍처에서 동일한 코드를 실행할 수 있는 GPU/CPU 컴퓨팅
- 기계 및 방대한 데이터 세트 전반에 걸친 높은 계산 확장성
이러한 기능이 함께 TensorFlow를 생산 규모의 기계 지능을 위한 완벽한 프레임워크로 만듭니다.
이 TensorFlow 튜토리얼에서는 TensorFlow에서 간단하지만 강력한 기계 학습 방법을 사용하는 방법과 TensorFlow의 일부 보조 라이브러리를 사용하여 생성된 모델을 디버그, 시각화 및 조정하는 방법을 배웁니다.
텐서플로우 설치
Python 2.7 및 Python 3.3 이상에서 작동하는 TensorFlow Python API를 사용할 것입니다. GPU 버전(Linux 전용)에는 Cuda Toolkit 7.0+ 및 cuDNN v2+가 필요합니다.
TensorFlow를 설치하기 위해 Conda 패키지 종속성 관리 시스템을 사용할 것입니다. Conda를 사용하면 시스템에서 여러 환경을 분리할 수 있습니다. 여기에서 Conda 설치 방법을 배울 수 있습니다.
Conda를 설치한 후 TensorFlow 설치 및 사용에 사용할 환경을 만들 수 있습니다. 다음 명령은 NumPy와 같은 몇 가지 추가 라이브러리로 환경을 생성합니다. 이는 TensorFlow를 사용하기 시작하면 매우 유용합니다.
이 환경에 설치된 Python 버전은 2.7이며 이 문서에서는 이 버전을 사용합니다.
conda create --name TensorflowEnv biopython 일을 쉽게 하기 위해 NumPy 대신 biopython을 여기에 설치합니다. 여기에는 NumPy와 우리가 필요로 하는 몇 가지 다른 패키지가 포함됩니다. conda install 또는 pip install 명령을 사용하여 필요할 때마다 패키지를 설치할 수 있습니다.
다음 명령은 생성된 Conda 환경을 활성화합니다. 전 세계적으로 또는 일부 다른 환경에 설치된 패키지와 혼합하지 않고 그 안에 설치된 패키지를 사용할 수 있습니다.
source activate TensorFlowEnvpip 설치 도구는 Conda 환경의 표준 부분입니다. TensorFlow 라이브러리를 설치하는 데 사용할 것입니다. 이를 수행하기 전에 좋은 첫 번째 단계는 다음 명령을 사용하여 pip를 최신 버전으로 업데이트하는 것입니다.
pip install --upgrade pip이제 다음을 실행하여 TensorFlow를 설치할 준비가 되었습니다.
pip install tensorflowTensorFlow의 다운로드 및 빌드에는 몇 분이 소요될 수 있습니다. 작성 시점에서 이것은 TensorFlow 1.1.0을 설치합니다.
데이터 흐름 그래프
TensorFlow에서 계산은 데이터 흐름 그래프를 사용하여 설명됩니다. 그래프의 각 노드는 수학 연산(예: 더하기, 나누기 또는 곱하기)의 인스턴스를 나타내고 각 간선은 연산이 수행되는 다차원 데이터 세트(텐서)입니다.
TensorFlow는 계산 그래프와 함께 작동하므로 각 작업에 0개 이상의 입력과 0개 이상의 출력이 있는 작업의 인스턴스화를 나타내는 각 노드에서 관리됩니다.
TensorFlow의 에지는 두 가지 범주로 그룹화할 수 있습니다. 한 작업의 출력이 다른 작업의 입력이 될 수 있는 일반 에지 전송 데이터 구조(텐서)와 설정을 위해 두 노드 간의 종속성을 제어하는 데 사용되는 특수 에지 한 노드가 다른 노드가 완료될 때까지 기다리는 작업 순서입니다.
간단한 표현
TensorFlow의 요소에 대해 논의하기 전에 먼저 TensorFlow 프로그램이 어떻게 생겼는지 알아보기 위해 TensorFlow 작업 세션을 수행할 것입니다.
간단한 표현식으로 시작하여 어떤 이유로 TensorFlow 방식으로 y = 5*x + 13 함수를 평가하려고 한다고 가정하겠습니다.
간단한 Python 코드에서는 다음과 같습니다.
x = -2.0 y = 5*x + 13 print y이 경우 3.0의 결과를 제공합니다.
이제 위의 표현식을 TensorFlow 용어로 변환합니다.
상수
TensorFlow에서 상수는 constant(value, dtype=None, shape=None, name='Const', verify_shape=False) 시그니처가 있는 함수 상수를 사용하여 생성됩니다. 여기서 value 는 다음에서 사용될 실제 상수 값입니다. 추가 계산, dtype 은 데이터 유형 매개변수(예: float32/64, int8/16 등), shape 는 선택적 차원, name 은 텐서의 선택적 이름, 마지막 매개변수는 검증을 나타내는 부울 가치의 형태.
훈련 모델 내부에 특정 값이 있는 상수가 필요한 경우 다음 예제와 같이 constant 객체를 사용할 수 있습니다.
z = tf.constant(5.2, name="x", dtype=tf.float32)변수
TensorFlow의 변수는 명시적으로 초기화되어야 하는 텐서를 포함하는 메모리 내 버퍼이며 세션 전체에서 상태를 유지하기 위해 그래프 내에서 사용됩니다. 생성자를 호출하기만 하면 변수가 계산 그래프에 추가됩니다.
변수는 훈련 모델을 시작할 때 특히 유용하며 매개변수를 유지하고 업데이트하는 데 사용됩니다. 생성자의 인수로 전달된 초기 값은 텐서로 변환하거나 반환할 수 있는 텐서 또는 객체를 나타냅니다. 즉, 교육 프로세스에서 나중에 사용하고 반복을 통해 업데이트할 미리 정의된 값이나 임의의 값으로 변수를 채우려면 다음과 같이 정의할 수 있습니다.
k = tf.Variable(tf.zeros([1]), name="k")TensorFlow에서 변수를 사용하는 또 다른 방법은 해당 변수를 학습할 수 없고 다음과 같은 방식으로 정의할 수 있는 계산에 있습니다.
k = tf.Variable(tf.add(a, b), trainable=False)세션
실제로 노드를 평가하려면 세션 내에서 계산 그래프를 실행해야 합니다.
세션은 TensorFlow 런타임의 제어 및 상태를 캡슐화합니다. 매개변수가 없는 세션은 현재 세션에서 생성된 기본 그래프를 사용합니다. 그렇지 않으면 세션 클래스는 실행할 해당 세션에서 사용되는 그래프 매개변수를 수락합니다.
아래는 위에서 정의한 용어를 TensorFlow에서 사용하여 간단한 선형 함수를 계산하는 방법을 보여주는 간단한 코드 조각입니다.
import tensorflow as tf x = tf.constant(-2.0, name="x", dtype=tf.float32) a = tf.constant(5.0, name="a", dtype=tf.float32) b = tf.constant(13.0, name="b", dtype=tf.float32) y = tf.Variable(tf.add(tf.multiply(a, x), b)) init = tf.global_variables_initializer() with tf.Session() as session: session.run(init) print session.run(y)TensorFlow 사용: 계산 그래프 정의
데이터 흐름 그래프로 작업할 때 좋은 점은 실행 모델이 실행(CPU, GPU 또는 일부 조합에서)과 분리된다는 것입니다. 여기에서 일단 구현되면 TensorFlow의 소프트웨어는 코드와 관련된 모든 복잡성이 있는 CPU 또는 GPU에서 사용할 수 있습니다. 실행이 숨겨져 있습니다.
Graph 객체를 명시적으로 인스턴스화할 필요 없이 TensorFlow 라이브러리를 사용하는 과정에서 계산 그래프를 작성할 수 있습니다.
TensorFlow의 Graph 객체는 c = tf.add(a, b) 와 같은 간단한 코드 줄의 결과로 생성할 수 있습니다. 이것은 출력으로 합 c 를 생성 a 두 개의 텐서와 b 를 취하는 연산 노드를 생성합니다.
연산 그래프는 그래프 객체를 직접 호출할 필요 없이 라이브러리를 사용하는 내장 프로세스입니다. 일련의 작업과 텐서를 데이터 단위로 포함하는 TensorFlow의 그래프 개체는 동일한 프로세스를 허용하고 각 그래프가 다른 세션에 할당되는 둘 이상의 그래프를 포함하는 작업 사이에 사용됩니다. 예를 들어, 코드 c = tf.add(a, b) 의 간단한 라인은 두 개의 텐서 a 와 b 를 입력으로 사용하고 그 합 c 를 출력으로 생성하는 연산 노드를 생성합니다.
TensorFlow는 또한 그래프의 모든 작업에 텐서를 패치하기 위한 피드 메커니즘을 제공합니다. 여기서 피드는 작업의 출력을 텐서 값으로 대체합니다. 피드 데이터는 run() 함수 호출에서 인수로 전달됩니다.
자리 표시자는 개발자가 일부 표현식 내부에 바인딩된 자리 표시자를 통해 계산 그래프에 데이터를 삽입할 수 있도록 하는 TensorFlow의 방법입니다. 자리 표시자의 서명은 다음과 같습니다.
placeholder(dtype, shape=None, name=None)여기서 dtype은 텐서의 요소 유형이며 공급할 텐서의 모양과 작업 이름을 모두 제공할 수 있습니다.
셰이프가 전달되지 않으면 이 텐서에 모든 셰이프가 제공될 수 있습니다. 중요한 점은 자리 표시자 텐서에 데이터가 제공되어야 하며 그렇지 않으면 세션 실행 시 해당 부분이 누락된 경우 자리 표시자가 다음 구조로 오류를 생성한다는 것입니다.
InvalidArgumentError (see above for traceback): You must feed a value for placeholder tensor 'y' with dtype float자리 표시자의 장점은 개발자가 사전에 데이터를 제공할 필요 없이 연산 및 일반적으로 계산 그래프를 생성할 수 있고 외부 소스에서 런타임에 데이터를 추가할 수 있다는 것입니다.
두 개의 정수 x 와 y 를 TensorFlow 방식으로 곱하는 간단한 문제를 살펴보겠습니다. 여기서 자리 표시자는 세션 run 방법을 통해 피드 메커니즘과 함께 사용됩니다.
import tensorflow as tf x = tf.placeholder(tf.float32, name="x") y = tf.placeholder(tf.float32, name="y") z = tf.multiply(x, y, name="z") with tf.Session() as session: print session.run(z, feed_dict={x: 2.1, y: 3.0})TensorBoard로 계산 그래프 시각화하기
TensorBoard는 데이터 흐름 그래프를 분석하기 위한 시각화 도구입니다. 이는 기계 학습 모델을 더 잘 이해하는 데 유용할 수 있습니다.
TensorBoard를 사용하면 매개변수에 대한 다양한 유형의 통계와 일반적으로 계산 그래프의 부분에 대한 세부 정보를 얻을 수 있습니다. 심층 신경망에 많은 수의 노드가 있는 것은 드문 일이 아닙니다. TensorBoard를 사용하면 개발자가 각 노드와 TensorFlow 런타임에서 계산이 실행되는 방식에 대한 통찰력을 얻을 수 있습니다.
이제 y = a*x + b 형식으로 선형 함수를 정의한 이 TensorFlow 자습서의 시작 부분에 있는 예제로 돌아가 보겠습니다.
나중에 TensorBoard에서 사용할 수 있는 세션의 이벤트를 기록하기 위해 TensorFlow는 FileWriter 클래스를 제공합니다. 생성자가 6개의 매개변수를 수락하고 다음과 같은 요약을 저장하기 위한 이벤트 파일을 만드는 데 사용할 수 있습니다.
__init__(logdir, graph=None, max_queue=10, flush_secs=120, graph_def=None, filename_suffix=None)여기서 logdir 매개변수는 필수이고 다른 매개변수에는 기본값이 있습니다. 그래프 매개변수는 훈련 프로그램에서 생성된 세션 객체에서 전달됩니다. 전체 예제 코드는 다음과 같습니다.
import tensorflow as tf x = tf.constant(-2.0, name="x", dtype=tf.float32) a = tf.constant(5.0, name="a", dtype=tf.float32) b = tf.constant(13.0, name="b", dtype=tf.float32) y = tf.Variable(tf.add(tf.multiply(a, x), b)) init = tf.global_variables_initializer() with tf.Session() as session: merged = tf.summary.merge_all() // new writer = tf.summary.FileWriter("logs", session.graph) // new session.run(init) print session.run(y) 두 줄만 추가했습니다. 기본 그래프에 수집된 모든 요약을 병합하고 위에서 설명한 대로 FileWriter 를 사용하여 이벤트를 파일에 각각 덤프합니다.
프로그램을 실행한 후 디렉토리 로그에 파일이 있고 마지막 단계는 tensorboard 를 실행하는 것입니다.
tensorboard --logdir logs/ 이제 TensorBoard가 시작되어 기본 포트 6006에서 실행됩니다. http://localhost:6006 을 열고 그래프 메뉴 항목(페이지 상단에 있음)을 클릭하면 다음과 같은 그래프를 볼 수 있습니다. 아래 그림에서:
TensorBoard는 아래에 설명된 상수와 요약 노드 특정 기호를 표시합니다.
TensorFlow를 사용한 수학
Tensor는 TensorFlow의 기본 데이터 구조이며 데이터 흐름 그래프의 연결 가장자리를 나타냅니다.
텐서는 단순히 다차원 배열이나 목록을 식별합니다. 텐서 구조는 순위, 모양 및 유형의 세 가지 매개변수로 식별할 수 있습니다.
- 순위: 텐서의 차원 수를 식별합니다. 순위는 텐서의 차수 또는 n차원으로 알려져 있으며, 예를 들어 순위 1 텐서는 벡터이거나 순위 2 텐서는 행렬입니다.
- 모양: 텐서의 모양은 텐서의 행과 열 수입니다.
- 유형: 텐서 요소에 할당된 데이터 유형입니다.
TensorFlow에서 텐서를 구축하기 위해 n차원 배열을 구축할 수 있습니다. 이것은 NumPy 라이브러리를 사용하거나 Python n차원 배열을 TensorFlow 텐서로 변환하여 쉽게 수행할 수 있습니다.
1차원 텐서를 빌드하기 위해 NumPy 배열을 사용합니다. NumPy 배열은 내장 Python 목록을 전달하여 구성합니다.
import numpy as np tensor_1d = np.array([1.45, -1, 0.2, 102.1])이러한 종류의 배열로 작업하는 것은 내장 Python 목록으로 작업하는 것과 유사합니다. 주요 차이점은 NumPy 배열에는 차원, 모양 및 유형과 같은 몇 가지 추가 속성도 포함되어 있다는 것입니다.
> > print tensor1d [ 1.45 -1. 0.2 102.1 ] > > print tensor1d[0] 1.45 > > print tensor1d[2] 0.2 > > print tensor1d.ndim 1 > > print tensor1d.shape (4,) > > print tensor1d.dtype float64NumPy 배열은 개발자가 Python 객체를 텐서 객체로 변환하는 데 도움이 되는 보조 함수 convert_to_tensor를 사용하여 TensorFlow 텐서로 쉽게 변환할 수 있습니다. 이 함수는 텐서 객체, NumPy 배열, Python 목록 및 Python 스칼라를 허용합니다.
tensor = tf.convert_to_tensor(tensor_1d, dtype=tf.float64)이제 텐서를 TensorFlow 세션에 바인딩하면 변환 결과를 볼 수 있습니다.
tensor = tf.convert_to_tensor(tensor_1d, dtype=tf.float64) with tf.Session() as session: print session.run(tensor) print session.run(tensor[0]) print session.run(tensor[1])산출:
[ 1.45 -1. 0.2 102.1 ] 1.45 -1.0비슷한 방식으로 2차원 텐서 또는 행렬을 만들 수 있습니다.
tensor_2d = np.array(np.random.rand(4, 4), dtype='float32') tensor_2d_1 = np.array(np.random.rand(4, 4), dtype='float32') tensor_2d_2 = np.array(np.random.rand(4, 4), dtype='float32') m1 = tf.convert_to_tensor(tensor_2d) m2 = tf.convert_to_tensor(tensor_2d_1) m3 = tf.convert_to_tensor(tensor_2d_2) mat_product = tf.matmul(m1, m2) mat_sum = tf.add(m2, m3) mat_det = tf.matrix_determinant(m3) with tf.Session() as session: print session.run(mat_product) print session.run(mat_sum) print session.run(mat_det)텐서 작업
위의 예에서는 벡터와 행렬에 대한 몇 가지 TensorFlow 작업을 소개합니다. 연산은 텐서에 대해 특정 계산을 수행합니다. 어떤 계산이 아래 표에 나와 있습니다.
| 텐서플로우 연산자 | 설명 |
|---|---|
| tf.add | x+y |
| tf.빼기 | xy |
| tf.곱하기 | x*y |
| tf.div | x/y |
| tf.mod | x % y |
| tf.abs | |x| |
| tf.네거티브 | -엑스 |
| tf.sign | 기호(x) |
| tf.square | 더블 엑스 |
| tf.round | 라운드(x) |
| tf.sqrt | 제곱미터(x) |
| tf.pow | x^y |
| tf.exp | e^x |
| tf.log | 로그(x) |
| tf.maximum | 최대(x, y) |
| tf.minimum | 최소(x, y) |
| tf.cos | 코스(x) |
| tf.sin | 죄(x) |
위 표에 나열된 TensorFlow 작업은 텐서 개체와 함께 작동하며 요소별로 수행됩니다. 따라서 벡터 x에 대한 코사인을 계산하려는 경우 TensorFlow 작업은 전달된 텐서의 각 요소에 대해 계산을 수행합니다.
tensor_1d = np.array([0, 0, 0]) tensor = tf.convert_to_tensor(tensor_1d, dtype=tf.float64) with tf.Session() as session: print session.run(tf.cos(tensor))산출:
[ 1. 1. 1.]행렬 연산
행렬 연산은 선형 회귀와 같은 기계 학습 모델에서 자주 사용되기 때문에 매우 중요합니다. TensorFlow는 곱셈, 전치, 역전, 행렬식 계산, 선형 방정식 풀기 등과 같은 가장 일반적인 모든 행렬 연산을 지원합니다.
다음으로 몇 가지 행렬 연산에 대해 설명합니다. 선형 회귀와 같이 기계 학습 모델과 관련하여 중요한 경향이 있습니다. 곱하기, 전치하기, 행렬식 가져오기, 곱하기, 솔 등과 같은 기본 행렬 연산을 수행하는 코드를 작성해 보겠습니다.

다음은 이러한 작업을 호출하는 기본 예입니다.
import tensorflow as tf import numpy as np def convert(v, t=tf.float32): return tf.convert_to_tensor(v, dtype=t) m1 = convert(np.array(np.random.rand(4, 4), dtype='float32')) m2 = convert(np.array(np.random.rand(4, 4), dtype='float32')) m3 = convert(np.array(np.random.rand(4, 4), dtype='float32')) m4 = convert(np.array(np.random.rand(4, 4), dtype='float32')) m5 = convert(np.array(np.random.rand(4, 4), dtype='float32')) m_tranpose = tf.transpose(m1) m_mul = tf.matmul(m1, m2) m_det = tf.matrix_determinant(m3) m_inv = tf.matrix_inverse(m4) m_solve = tf.matrix_solve(m5, [[1], [1], [1], [1]]) with tf.Session() as session: print session.run(m_tranpose) print session.run(m_mul) print session.run(m_inv) print session.run(m_det) print session.run(m_solve)데이터 변환
절감
TensorFlow는 다양한 종류의 축소를 지원합니다. 축소는 해당 차원에 대해 특정 작업을 수행하여 텐서에서 하나 이상의 차원을 제거하는 작업입니다. 현재 버전의 TensorFlow에 대해 지원되는 축소 목록은 여기에서 찾을 수 있습니다. 아래 예에서 그 중 몇 가지를 제시합니다.
import tensorflow as tf import numpy as np def convert(v, t=tf.float32): return tf.convert_to_tensor(v, dtype=t) x = convert( np.array( [ (1, 2, 3), (4, 5, 6), (7, 8, 9) ]), tf.int32) bool_tensor = convert([(True, False, True), (False, False, True), (True, False, False)], tf.bool) red_sum_0 = tf.reduce_sum(x) red_sum = tf.reduce_sum(x, axis=1) red_prod_0 = tf.reduce_prod(x) red_prod = tf.reduce_prod(x, axis=1) red_min_0 = tf.reduce_min(x) red_min = tf.reduce_min(x, axis=1) red_max_0 = tf.reduce_max(x) red_max = tf.reduce_max(x, axis=1) red_mean_0 = tf.reduce_mean(x) red_mean = tf.reduce_mean(x, axis=1) red_bool_all_0 = tf.reduce_all(bool_tensor) red_bool_all = tf.reduce_all(bool_tensor, axis=1) red_bool_any_0 = tf.reduce_any(bool_tensor) red_bool_any = tf.reduce_any(bool_tensor, axis=1) with tf.Session() as session: print "Reduce sum without passed axis parameter: ", session.run(red_sum_0) print "Reduce sum with passed axis=1: ", session.run(red_sum) print "Reduce product without passed axis parameter: ", session.run(red_prod_0) print "Reduce product with passed axis=1: ", session.run(red_prod) print "Reduce min without passed axis parameter: ", session.run(red_min_0) print "Reduce min with passed axis=1: ", session.run(red_min) print "Reduce max without passed axis parameter: ", session.run(red_max_0) print "Reduce max with passed axis=1: ", session.run(red_max) print "Reduce mean without passed axis parameter: ", session.run(red_mean_0) print "Reduce mean with passed axis=1: ", session.run(red_mean) print "Reduce bool all without passed axis parameter: ", session.run(red_bool_all_0) print "Reduce bool all with passed axis=1: ", session.run(red_bool_all) print "Reduce bool any without passed axis parameter: ", session.run(red_bool_any_0) print "Reduce bool any with passed axis=1: ", session.run(red_bool_any)산출:
Reduce sum without passed axis parameter: 45 Reduce sum with passed axis=1: [ 6 15 24] Reduce product without passed axis parameter: 362880 Reduce product with passed axis=1: [ 6 120 504] Reduce min without passed axis parameter: 1 Reduce min with passed axis=1: [1 4 7] Reduce max without passed axis parameter: 9 Reduce max with passed axis=1: [3 6 9] Reduce mean without passed axis parameter: 5 Reduce mean with passed axis=1: [2 5 8] Reduce bool all without passed axis parameter: False Reduce bool all with passed axis=1: [False False False] Reduce bool any without passed axis parameter: True Reduce bool any with passed axis=1: [ True True True]감소 연산자의 첫 번째 매개변수는 줄이고자 하는 텐서입니다. 두 번째 매개변수는 축소를 수행하려는 차원의 인덱스입니다. 해당 매개변수는 선택 사항이며 전달되지 않으면 모든 차원에 대해 축소가 수행됩니다.
reduce_sum 연산을 살펴볼 수 있습니다. 2차원 텐서를 전달하고 차원 1을 따라 축소하려고 합니다.
우리의 경우 결과 합계는 다음과 같습니다.
[1 + 2 + 3 = 6, 4 + 5 + 6 = 15, 7 + 8 + 9 = 24]차원 0을 전달하면 결과는 다음과 같습니다.
[1 + 4 + 7 = 12, 2 + 5 + 8 = 15, 3 + 6 + 9 = 18]축을 전달하지 않으면 결과는 다음의 전체 합계입니다.
1 + 4 + 7 = 12, 2 + 5 + 8 = 15, 3 + 6 + 9 = 45모든 축소 기능은 유사한 인터페이스를 가지고 있으며 TensorFlow 축소 문서에 나열되어 있습니다.
분할
세분화는 차원 중 하나가 차원을 제공된 세그먼트 인덱스에 매핑하는 프로세스이고 결과 요소는 인덱스 행에 의해 결정되는 프로세스입니다.
분할은 실제로 반복된 인덱스 아래에 있는 요소를 그룹화하는 것이므로 예를 들어 우리의 경우 텐서 tens1 에 적용된 분할 ID [0, 0, 1, 2, 2] 가 있습니다. 연산(이 경우 합산)을 수행하고 (2, 8, 1, 0) = (2+0, 5+3, 3-2, -5+5) 와 같은 새 배열을 얻습니다. tensor tens1 의 세 번째 요소는 반복되는 인덱스로 그룹화되지 않기 때문에 그대로 유지되고 마지막 두 배열은 첫 번째 그룹의 경우와 같은 방식으로 합산됩니다. 합산 외에도 TensorFlow는 곱, 평균, 최대 및 최소를 지원합니다.
import tensorflow as tf import numpy as np def convert(v, t=tf.float32): return tf.convert_to_tensor(v, dtype=t) seg_ids = tf.constant([0, 0, 1, 2, 2]) tens1 = convert(np.array([(2, 5, 3, -5), (0, 3, -2, 5), (4, 3, 5, 3), (6, 1, 4, 0), (6, 1, 4, 0)]), tf.int32) tens2 = convert(np.array([1, 2, 3, 4, 5]), tf.int32) seg_sum = tf.segment_sum(tens1, seg_ids) seg_sum_1 = tf.segment_sum(tens2, seg_ids) with tf.Session() as session: print "Segmentation sum tens1: ", session.run(seg_sum) print "Segmentation sum tens2: ", session.run(seg_sum_1) Segmentation sum tens1: [[ 2 8 1 0] [ 4 3 5 3] [12 2 8 0]] Segmentation sum tens2: [3 3 9]시퀀스 유틸리티
시퀀스 유틸리티에는 다음과 같은 방법이 포함됩니다.
- 입력 텐서의 축에 걸쳐 최소값이 있는 인덱스를 반환하는 argmin 함수,
- argmax 함수는 입력 텐서의 축에 걸쳐 최대 값을 가진 인덱스를 반환합니다.
- 두 개의 숫자 또는 문자열 목록 간의 차이를 계산하는 setdiff,
- 여기서 함수는 전달된 조건에 따라 전달된 두 요소 x 또는 y에서 요소를 반환하거나
- 1차원 텐서에서 고유한 요소를 반환하는 고유 함수입니다.
아래에서 몇 가지 실행 예를 보여줍니다.
import numpy as np import tensorflow as tf def convert(v, t=tf.float32): return tf.convert_to_tensor(v, dtype=t) x = convert(np.array([ [2, 2, 1, 3], [4, 5, 6, -1], [0, 1, 1, -2], [6, 2, 3, 0] ])) y = convert(np.array([1, 2, 5, 3, 7])) z = convert(np.array([1, 0, 4, 6, 2])) arg_min = tf.argmin(x, 1) arg_max = tf.argmax(x, 1) unique = tf.unique(y) diff = tf.setdiff1d(y, z) with tf.Session() as session: print "Argmin = ", session.run(arg_min) print "Argmax = ", session.run(arg_max) print "Unique_values = ", session.run(unique)[0] print "Unique_idx = ", session.run(unique)[1] print "Setdiff_values = ", session.run(diff)[0] print "Setdiff_idx = ", session.run(diff)[1] print session.run(diff)[1]산출:
Argmin = [2 3 3 3] Argmax = [3 2 1 0] Unique_values = [ 1. 2. 5. 3. 7.] Unique_idx = [0 1 2 3 4] Setdiff_values = [ 5. 3. 7.] Setdiff_idx = [2 3 4]TensorFlow를 사용한 머신 러닝
이 섹션에서는 TensorFlow를 사용한 기계 학습 사용 사례를 제시합니다. 첫 번째 예제는 kNN 방식으로 데이터를 분류하는 알고리즘이고 두 번째 예제는 선형 회귀 알고리즘을 사용합니다.
kNN
첫 번째 알고리즘은 k-최근접 이웃(kNN)입니다. 이는 거리 측정법(예: 유클리드 거리)을 사용하여 데이터를 훈련에 대해 분류하는 지도 학습 알고리즘입니다. 가장 간단한 알고리즘 중 하나이지만 여전히 데이터 분류에 매우 강력합니다. 이 알고리즘의 장점:
- 훈련 모델이 충분히 클 때 높은 정확도를 제공하고,
- 일반적으로 이상값에 민감하지 않으며 데이터에 대해 가정할 필요가 없습니다.
이 알고리즘의 단점:
- 계산적으로 비싸고,
- 모든 초기 훈련 인스턴스에 새로운 분류 데이터를 추가해야 하는 경우 많은 메모리가 필요합니다.
이 코드 샘플에서 사용할 거리는 다음과 같이 두 점 사이의 거리를 정의하는 유클리드입니다.
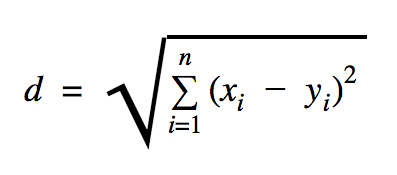
이 공식에서 n 은 공간의 차원 수, x 는 훈련 데이터의 벡터, y 는 분류하려는 새 데이터 포인트입니다.
import os import numpy as np import tensorflow as tf ccf_train_data = "train_dataset.csv" ccf_test_data = "test_dataset.csv" dataset_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), '../datasets')) ccf_train_filepath = os.path.join(dataset_dir, ccf_train_data) ccf_test_filepath = os.path.join(dataset_dir, ccf_test_data) def load_data(filepath): from numpy import genfromtxt csv_data = genfromtxt(filepath, delimiter=",", skip_header=1) data = [] labels = [] for d in csv_data: data.append(d[:-1]) labels.append(d[-1]) return np.array(data), np.array(labels) train_dataset, train_labels = load_data(ccf_train_filepath) test_dataset, test_labels = load_data(ccf_test_filepath) train_pl = tf.placeholder("float", [None, 28]) test_pl = tf.placeholder("float", [28]) knn_prediction = tf.reduce_sum(tf.abs(tf.add(train_pl, tf.negative(test_pl))), axis=1) pred = tf.argmin(knn_prediction, 0) with tf.Session() as tf_session: missed = 0 for i in xrange(len(test_dataset)): knn_index = tf_session.run(pred, feed_dict={train_pl: train_dataset, test_pl: test_dataset[i]}) print "Predicted class {} -- True class {}".format(train_labels[knn_index], test_labels[i]) if train_labels[knn_index] != test_labels[i]: missed += 1 tf.summary.FileWriter("../samples/article/logs", tf_session.graph) print "Missed: {} -- Total: {}".format(missed, len(test_dataset))위의 예에서 사용한 데이터세트는 Kaggle 데이터세트 섹션에서 찾을 수 있는 데이터세트입니다. 우리는 유럽 카드 소지자의 신용 카드 거래가 포함된 것을 사용했습니다. 우리는 정리나 필터링 없이 데이터를 사용하고 있으며 이 데이터 세트에 대한 Kaggle의 설명에 따르면 매우 불균형합니다. 데이터 세트에는 시간, V1, …, V28, 금액 및 클래스의 31개 변수가 있습니다. 이 코드 샘플에서는 V1, …, V28 및 Class만 사용합니다. 클래스는 사기성 거래를 1로 표시하고 그렇지 않은 거래를 0으로 표시합니다.
코드 샘플에는 데이터 세트를 로드하는 기능을 도입한 경우를 제외하고 이전 섹션에서 설명한 대부분의 내용이 포함되어 있습니다. load_data(filepath) 함수는 CSV 파일을 인수로 사용하고 CSV에 정의된 데이터와 레이블이 있는 튜플을 반환합니다.
해당 함수 바로 아래에 테스트 및 훈련된 데이터에 대한 자리 표시자를 정의했습니다. 훈련된 데이터는 분류해야 하는 입력 데이터의 레이블을 해결하기 위해 예측 모델에서 사용됩니다. 우리의 경우 kNN은 가장 가까운 레이블을 얻기 위해 유클리드 거리를 사용합니다.
오류율은 이 데이터 세트에 대한 우리의 경우 0.2인 총 예제 수로 분류기가 놓친 경우 숫자로 간단한 나누기로 계산할 수 있습니다(즉, 분류기가 테스트 데이터의 20%에 대해 잘못된 데이터 레이블을 제공함).
선형 회귀
선형 회귀 알고리즘은 두 변수 간의 선형 관계를 찾습니다. 종속 변수를 y로, 독립 변수를 x로 레이블을 지정하면 함수 y = Wx + b 의 매개변수를 추정하려고 합니다.
선형 회귀는 응용 과학 분야에서 널리 사용되는 알고리즘입니다. 이 알고리즘을 사용하면 기계 학습의 두 가지 중요한 개념인 비용 함수와 함수의 최소값을 찾기 위한 경사 하강법을 구현에 추가할 수 있습니다.
이 방법을 사용하여 구현된 기계 학습 알고리즘은 y 값을 x 의 함수로 예측해야 하며 여기서 선형 회귀 알고리즘은 실제로 알려지지 않은 값 W 및 b 를 결정하며 이 값은 훈련 프로세스 전반에 걸쳐 결정됩니다. 비용 함수가 선택되고 일반적으로 평균 제곱 오차가 사용되며 여기서 경사 하강법은 비용 함수의 로컬 최소값을 찾는 데 사용되는 최적화 알고리즘입니다.
경사하강법은 국소적 최소값에 불과하지만, 일단 국소적 최소값을 찾은 새 시작점을 무작위로 선택하고 이 과정을 여러 번 반복하여 전역 최소값 검색에 사용할 수 있습니다. 함수의 최소값 수가 제한되어 있고 시도 횟수가 매우 높으면 어느 시점에서 전역 최소값이 발견될 가능성이 큽니다. 이 기술에 대한 몇 가지 자세한 내용은 소개 섹션에서 언급한 기사로 남길 것입니다.
import tensorflow as tf import numpy as np test_data_size = 2000 iterations = 10000 learn_rate = 0.005 def generate_test_values(): train_x = [] train_y = [] for _ in xrange(test_data_size): x1 = np.random.rand() x2 = np.random.rand() x3 = np.random.rand() y_f = 2 * x1 + 3 * x2 + 7 * x3 + 4 train_x.append([x1, x2, x3]) train_y.append(y_f) return np.array(train_x), np.transpose([train_y]) x = tf.placeholder(tf.float32, [None, 3], name="x") W = tf.Variable(tf.zeros([3, 1]), name="W") b = tf.Variable(tf.zeros([1]), name="b") y = tf.placeholder(tf.float32, [None, 1]) model = tf.add(tf.matmul(x, W), b) cost = tf.reduce_mean(tf.square(y - model)) train = tf.train.GradientDescentOptimizer(learn_rate).minimize(cost) train_dataset, train_values = generate_test_values() init = tf.global_variables_initializer() with tf.Session() as session: session.run(init) for _ in xrange(iterations): session.run(train, feed_dict={ x: train_dataset, y: train_values }) print "cost = {}".format(session.run(cost, feed_dict={ x: train_dataset, y: train_values })) print "W = {}".format(session.run(W)) print "b = {}".format(session.run(b))산출:
cost = 3.1083032809e-05 W = [[ 1.99049103] [ 2.9887135 ] [ 6.98754263]] b = [ 4.01742554] 위의 예에는 cost 와 train 이라는 두 개의 새로운 변수가 있습니다. 이 두 변수를 사용하여 훈련 모델에서 사용하려는 옵티마이저와 최소화하려는 함수를 정의했습니다.
결국 W 와 b 의 출력 매개변수는 generate_test_values 함수에 정의된 것과 동일해야 합니다. 17행에서 실제로 w1=2 , w2=3 , w3=7 및 b=4 에서 학습할 선형 데이터 포인트를 생성하는 데 사용한 함수를 정의했습니다. 위의 예에서 선형 회귀는 둘 이상의 독립 변수가 사용되는 다변수입니다.
결론
이 TensorFlow 튜토리얼에서 볼 수 있듯이, TensorFlow는 수학적 표현식과 다차원 배열 작업을 쉽게 만드는 강력한 프레임워크입니다. 이는 머신 러닝에 기본적으로 필요한 것입니다. 또한 데이터 그래프 실행 및 확장의 복잡성을 추상화합니다.
시간이 지남에 따라 TensorFlow는 인기를 얻었으며 현재 이미지 인식, 비디오 감지, 감정 분석과 같은 텍스트 처리 등을 위한 딥 러닝 방법을 사용하여 문제를 해결하기 위해 개발자가 사용하고 있습니다. 다른 라이브러리와 마찬가지로 익숙해지는 데 시간이 필요할 수 있습니다. TensorFlow가 구축된 개념에 대해 설명합니다. 그리고 일단 문서화 및 커뮤니티 지원의 도움으로 문제를 데이터 그래프로 표시하고 TensorFlow로 문제를 해결하면 대규모 머신 러닝을 덜 지루한 프로세스로 만들 수 있습니다.