
PySpark 初學者教程 [附示例]
已發表: 2020-10-07PySpark 是一個基於雲的平台,用作服務架構。 該平台提供了計算大數據文件的環境。 PySpark 是指 Python 編程語言與 Spark 集群相關聯的應用。 它與大數據密切相關。 讓我們先簡要了解大數據處理的內容,並大致了解PySpark 教程。
目錄
PySpark 有什麼用途?
作為 Apache Spark 社區發布的用於 Spark 的 Python API,它支持 Python 和 Spark。 繼續閱讀有關Spark 教程 Python的這篇文章,以了解更多關於其用途的信息。
- 通過使用 PySpark,可以在 Python 中集成彈性分佈式數據集 (RDD) 並有效地工作。
- 眾多功能使 PySpark 成為一個出色的框架,因為它有助於處理大量數據集。
- PySpark 提供了廣泛的庫,在 PySpark 的幫助下,機器學習和實時流分析變得更加容易。
- PySpark 利用 Python 的簡單性和用於馴服大數據的 Apache Spark 的強大功能。
- 隨著大數據的出現,Apache Spark 和 Hadoop 等技術的力量得到了發展。
- 數據科學家可以有效地處理大型數據集,因為任何 Python 開發人員都可以做到。
閱讀: Apache PySpark 中的數據框
Python 中的大數據概念
Python 是一種高級編程語言,它還公開了許多編程範式,例如面向對象編程 (OOP)、異步和函數式編程。
在處理大數據時,函數式編程是一個重要的範例。 它遵循並行代碼,這意味著您可以在多個 CPU 以及完全不同的機器上運行您的代碼。 PySpark 生態系統允許您使用功能代碼並將其分佈在計算機集群中。
程序員的函數式編程核心思想可在 Python 的標準庫和內置函數中找到。
通過函數進行數據操作,無需任何外部狀態維護,是函數式編程的核心思想體現。 這代表您的代碼繞過全局變量並且不會就地操作數據但總是返回新數據的事實。 Python 使用 lambda 關鍵字來公開匿名函數。
學習世界頂尖大學的數據科學認證課程。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。
PySpark 的一些關鍵特性
- Polyglot:PySpark 是通過海量數據集進行計算的最受好評的框架之一。 它也與多種語言兼容。
- 磁盤持久性和緩存:PySpark 框架提供了令人印象深刻的磁盤持久性和強大的緩存。
- 快速處理:與其他用於大數據處理的傳統框架相比,PySpark 框架非常快。
- 適用於 RDD:Python 是一種動態類型的編程語言,有助於使用彈性分佈式數據集。
什麼是 PySpark?
本Pyspark 教程將讓您了解 PySpark 是什麼。 PySpark 是一個 Python 應用程序編程接口 (API)。 API 是用 Python 編寫的,用於與 Apache Spark 建立連接。 如您所知,Apache Spark 處理大數據分析。 編程語言 Scala 用於創建 Apache Spark。 它可以被其他編程語言集成,即 Python、Java、SQL、R 和 Scala 本身。
PySpark 基於兩組確證:
- PySpark API:它有很多示例。
- Spark Scala API:對於 PySpark 程序,它將本身是一種非常易讀且基於工作的編程語言的 Scala 代碼轉換為 python 代碼並使其易於理解。
Py4J 使 Python 程序可以自由地通過基於 JVM 的代碼進行通信。 它幫助 PySpark 插入基於 Spark Scala 的應用程序編程接口。
如何設置 PySpark 環境
現在讓我們討論 PySpark 入門和應用的不同環境。 按照這個Spark教程 Python設置 PySpark:
- 自託管:在這種情況下,您可以自己設置集合或集群。 在這種環境中,您可以考慮使用金屬或虛擬集群。 有一些提議的項目,即適用於此目的的 Apache Ambari。 然而,這個過程還不夠快。
- 雲提供商:在這種情況下,通常會使用 Spark 集群。 這種環境比自託管更快。 Amazon Web 服務 (AWS) 具有電子 MapReduce (EMR),而良好臨床實踐 (GCP) 具有 Dataproc。
- 供應商解決方案:Databricks 和 Cloudera 提供 Spark 解決方案。 這是運行 PySpark 的最快方法之一。
PySpark 編程
眾所周知,Python 是一種具有多個庫的高級語言。 它在機器學習和數據分析中起著非常關鍵的作用。 因此,PySpark 是用 Python 編寫的 spark 的 API。 Spark 具有高速、易於訪問和適用於流式分析的一些優良特性。 除此之外,Spark 和 Python 的框架幫助 PySpark 輕鬆訪問和處理大數據。
Spark教程Python的要點將在下面討論。
彈性分佈式數據集 (RDD):彈性分佈式數據集或 RDD 是 PySpark 編程架構的主要構建基石之一。 這個集合是不變的並且經歷了微弱的轉換。 這個縮寫的每個單詞都有一個意義。 它具有彈性,因為它可以允許錯誤並且可以重新發現數據。 它是分佈式的,因為它在一個叢中擴展到各種其他節點。 數據集代表值數據的存儲。
另請閱讀:最常見的 PySpark 面試問題

RDD 主要支持以下類型的操作
1) 轉換:遵循惰性求值原則的轉換,允許您隨時通過對數據調用操作來操作執行。 很少有轉換是 RDD 提供的 Map、Flat Map、Filter、Distinct、Reduce By Key、Map Partitions,排序依據。
2) 動作: RDD 操作允許 PySpark 應用計算,將結果傳遞回驅動程序,這稱為動作。
將大寫轉換為小寫並拆分字符串的步驟
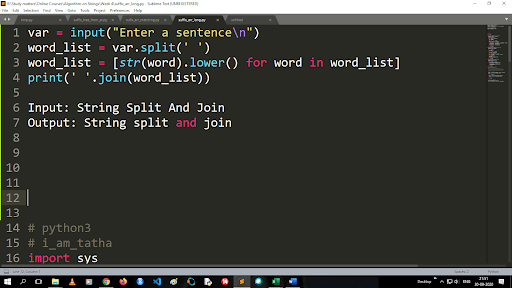
split 函數的輸出是列表類型。 使用join函數,格式為“.join(sequence data type)” 上面的代碼:
輸入:字符串拆分和連接
輸出:字符串拆分和連接
如何讀取文件?
通過以“讀取模式”(r) 調用 .txt 文件來讀取 Python 中的文件。
步驟 1) 以讀取模式打開文件
f=open(“sample.txt”, “r”)
步驟 2) 我們在代碼中使用 mode 函數來檢查文件是否處於打開模式。
f.mode == 'r':
步驟 3) 使用 f.read 讀取文件數據並將其存儲在變量內容中
內容 = f.read()
預測分析的步驟:
- 數據探索:您必須收集數據、上傳數據,並確定數據類型、種類和價值。
- 數據清理:您必須找到可能阻礙程序的空值、缺失值和其他冗餘。
- 建模:您必須選擇一個預測模型。
- 評估:您必須檢查分析的準確性。
PySpark 流式傳輸
PySpark Streaming 只不過是一個可擴展的、無錯誤的系統。 它遵守從 500ms 到更高間隔槽的 RDD 批處理間隔。 根據spark tutorial Python ,Spark Streaming 被賦予了一些流數據作為輸入。
根據 RDD 批處理間隔的數量,這些流式數據被分成許多批處理並發送到 Spark 引擎。 接收流式數據的一些來源是 Kinesis、Kafka、Apache Flume 等。通過使用數據結構和算法,Spark 引擎可以檢索數據。 之後,檢索到的數據被轉發到各種文件系統和數據庫。
如前所述,PySpark 是一個高級 API。 儘管發生任何故障,流操作將只執行一次。 PySpark Streaming 的主要干擾之一是離散流。 這些流組件也是在 RDD 批處理的幫助下構建的。 MLib、SQL、Dataframes 用於擴展 Spark Streaming 的廣泛操作。
在本PySpark 教程中,您將了解 Spark Stream 從各種來源檢索大量數據。 這是可能的,因為它使用了複雜的算法,其中包括功能強大的組件——Map、Reduce、Join 和 Window。
這些是對 PySpark Streaming 的總結。 現在在這個Spark 教程 python中,讓我們談談 PySpark 的一些優點。
PySpark 的優勢
這一段可以分為兩部分。 首先,您將了解在 PySpark 中使用 Python 的優勢,其次,PySpark 本身的優勢。
- 作為一種高級且對編碼人員友好的語言,它易於學習和執行。
- 可以使用簡單而包容的 API。
- Python 為讀者提供了可視化數據的絕佳機會。
- Python 具有廣泛的庫。 其中一些例子是 Matplotlib、Pandas、Seaborn、NumPy 等。
現在,以下是PySpark 教程的功能:
- PySpark Streaming 可以輕鬆集成其他編程語言,如 Java、Scala 和 R。
- PySpark 幫助程序員使用彈性分佈式數據集 (RDD) 執行多項功能
- PySpark 比其他大數據解決方案更受歡迎,因為它具有高速、強大的捕獲和磁盤持久性機制來處理數據。
必讀:面向初學者的 Python 教程
PySpark 中包含數據科學和機器學習
作為一種功能強大的編程語言,Python 是數據科學和機器學習的支柱。 因此,數據科學和機器學習是 PySpark 系統的組成部分也就不足為奇了。 機器學習庫 (MLib) 是在 PySpark 中控制機器學習功能的運算符。
以下是在 PySpark 中使用機器學習的優勢:
- 它是高度可擴展的。
- 它在分佈式系統中仍然有效。
PySpark中機器學習的主要功能:
- 機器學習為正確處理數據準備了各種方法和技能。 這些是轉換,提取,散列,選擇等。
- 如前所述,它提供了一些複雜的算法。 這些用於處理來自各種來源的數據。
- 它使用一些數學解釋和統計數據。 它涉及線性代數和模型評估過程。
結論
在本教程中,我們討論了關鍵特性、設置環境、讀取文件等等。
如果您想了解數據科學,請查看 IIIT-B 和 upGrad 的數據科學執行 PG 計劃,該計劃是為在職專業人士創建的,提供 10 多個案例研究和項目、實用的實踐研討會、與行業專家的指導、1與行業導師一對一,400 多個小時的學習和頂級公司的工作協助。
什麼是 PySpark?
PySpark 的成立是為了促進 Apache Spark 與 Python 的協作。 此次合作為 Spark 提供了 Python API。 此外,PySpark 使用戶能夠與 Apache Spark 和 Python 中的彈性分佈式數據集 (RDD) 進行交互。 PySpark 允許用戶使用 Python 編程語言快速集成 RDD 並與之交互。 有幾個特點使 PySpark 成為處理大型數據集的出色工具。 數據工程師正在轉向這個工具來對龐大的數據集進行計算,或者只是為了研究它們。 這是通過使用 Py4j 庫來完成的。
PySpark 的實際用例有哪些?
PySpark 當前用於流式 ETL。 流式 ETL 在將數據交付到數據存儲之前不斷地清理和聚合數據。 PySpark 通過將實時數據與靜態數據集成來豐富實時數據,從而幫助數據豐富,使公司能夠執行更全面的實時數據分析。 Pyspark 也用於觸發檢測。 金融組織使用觸發器來檢測欺詐交易並阻止它們。 醫院還使用觸發器來識別潛在有害的健康變化,同時監測患者的生命體徵,向相關護理人員發送自動通知,然後他們可能會採取迅速和必要的行動。
Python 和 PySpark 是否相關?
PySpark 是 Apache Spark 和 Python 合作的結果。 Python 是一種通用的高級編程語言,而 Apache Spark 是一個專注於速度、易用性和流分析的開源集群計算平台。 它提供了一組多樣化的庫,主要用於機器學習和實時流分析。 這意味著它是用於 Spark 的 Python API,使您能夠通過將 Python 的簡單性與 Apache Spark 的強大功能相結合來馴服大數據。