
Tutorial PySpark Untuk Pemula [Dengan Contoh]
Diterbitkan: 2020-10-07PySpark adalah platform berbasis cloud yang berfungsi sebagai arsitektur layanan. Platform ini menyediakan lingkungan untuk menghitung file Big Data. PySpark mengacu pada aplikasi bahasa pemrograman Python yang terkait dengan cluster Spark. Ini sangat terkait dengan Big Data. Beri tahu kami dulu apa yang ditangani Big Data secara singkat dan dapatkan ikhtisar tutorial PySpark .
Daftar isi
Untuk Apa PySpark Digunakan?
Sebagai API Python untuk Spark yang dirilis oleh komunitas Apache Spark, ini mendukung Python dengan Spark. Teruslah membaca artikel ini tentang tutorial percikan Python untuk mengetahui lebih banyak tentang kegunaannya.
- Dengan penggunaan PySpark, seseorang dapat mengintegrasikan dan bekerja secara efisien dengan Resilient Distributed Datasets (RDDs) dengan Python.
- Banyak fitur menjadikan PySpark kerangka kerja yang sangat baik karena memfasilitasi bekerja dengan kumpulan data besar.
- PySpark menyediakan berbagai perpustakaan, dan Pembelajaran Mesin dan Analisis Streaming Real-Time menjadi lebih mudah dengan bantuan PySpark.
- PySpark memanfaatkan kesederhanaan Python dan kekuatan Apache Spark yang digunakan untuk menjinakkan Big Data.
- Dengan munculnya Big Data, kekuatan teknologi seperti Apache Spark dan Hadoop telah dikembangkan.
- Seorang ilmuwan data dapat secara efisien menangani kumpulan data besar, karena berada dalam jangkauan pengembang Python mana pun.
Baca: Dataframe di Apache PySpark
Konsep Big Data dengan Python
Python adalah bahasa pemrograman tingkat tinggi yang juga memaparkan banyak paradigma pemrograman seperti pemrograman berorientasi objek (OOP), pemrograman asinkron dan fungsional.
Pemrograman fungsional adalah paradigma penting ketika berhadapan dengan Big Data. Ini mengikuti kode paralel, yang berarti Anda dapat menjalankan kode Anda pada beberapa CPU serta mesin yang sama sekali berbeda. Ekosistem PySpark memiliki kekuatan untuk memungkinkan Anda menggunakan kode fungsional dan mendistribusikannya ke sekelompok komputer.
Ide inti pemrograman fungsional untuk programmer tersedia di perpustakaan standar dan built-in Python.
Manipulasi data yang terjadi melalui fungsi tanpa pemeliharaan keadaan eksternal adalah perwujudan ide inti dari pemrograman fungsional. Ini berarti bahwa kode Anda menghindari variabel global dan tidak memanipulasi data di tempat tetapi selalu mengembalikan data baru. Python menggunakan kata kunci lambda untuk mengekspos fungsi anonim.
Pelajari kursus sertifikasi ilmu data dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karier Anda.
Beberapa Fitur Utama PySpark
- Polyglot: PySpark adalah salah satu kerangka kerja yang paling berharga untuk komputasi melalui kumpulan data yang sangat besar. Ini juga kompatibel dengan banyak bahasa.
- Persistensi dan caching disk: Kerangka kerja PySpark memberikan persistensi disk yang mengesankan dan caching yang kuat.
- Pemrosesan cepat: Dibandingkan dengan kerangka kerja tradisional lainnya yang digunakan untuk pemrosesan Big Data, kerangka kerja PySpark cukup cepat.
- Bekerja dengan baik dengan RDD: Python diketik secara dinamis untuk bahasa pemrograman, yang membantu bekerja dengan Kumpulan Data Terdistribusi yang Tangguh.
Apa itu PySpark?
Tutorial Pyspark ini akan membuat Anda memahami apa itu PySpark. PySpark adalah Antarmuka Pemrograman Aplikasi Python (API). API ditulis dengan Python untuk membentuk koneksi dengan Apache Spark. Seperti yang Anda ketahui, Apache Spark berurusan dengan analisis data besar. Bahasa pemrograman Scala digunakan untuk membuat Apache Spark. Dapat diintegrasikan dengan bahasa pemrograman lain yaitu Python, Java, SQL, R, dan Scala itu sendiri.
PySpark didasarkan pada dua set pembuktian:
- PySpark API: Ini memiliki banyak sampel.
- Spark Scala API: Untuk program PySpark, ini menerjemahkan kode Scala yang merupakan bahasa pemrograman yang sangat mudah dibaca dan berbasis kerja, ke dalam kode python dan membuatnya dapat dimengerti.
Py4J memberikan kebebasan kepada program Python untuk berkomunikasi melalui kode berbasis JVM. Ini membantu PySpark untuk terhubung dengan Antarmuka Pemrograman Aplikasi berbasis Spark Scala.
Cara Mengatur Lingkungan PySpark
Sekarang mari kita bahas lingkungan yang berbeda di mana PySpark dimulai dan diterapkan. Ikuti tutorial percikan Python ini untuk mengatur PySpark:
- Dihosting Sendiri: Dalam hal ini, Anda dapat mengatur koleksi atau menggumpal sendiri. Di lingkungan ini, Anda dapat melihat untuk menggunakan kluster logam atau virtual. Ada beberapa proyek yang diusulkan, yaitu Apache Ambari yang dapat diterapkan untuk tujuan ini. Namun, proses ini tidak cukup cepat.
- Penyedia Cloud: Dalam hal ini, lebih sering daripada tidak, cluster Spark digunakan. Lingkungan ini berfungsi lebih cepat daripada hosting sendiri. Amazon Web Services (AWS) memiliki Electronic MapReduce (EMR), sedangkan Good Clinical Practice (GCP) memiliki Dataproc.
- Solusi Vendor: Databricks dan Cloudera menghadirkan solusi Spark. Ini adalah salah satu cara tercepat untuk menjalankan PySpark.
Pemrograman PySpark
Seperti yang kita semua tahu, Python adalah bahasa tingkat tinggi yang memiliki beberapa perpustakaan. Ini memainkan peran yang sangat penting dalam Pembelajaran Mesin dan Analisis Data. Oleh karena itu, PySpark adalah API untuk percikan yang ditulis dengan Python. Spark memiliki beberapa atribut luar biasa yang menampilkan kecepatan tinggi, akses mudah, dan diterapkan untuk analitik streaming. Selain itu, kerangka kerja Spark dan Python membantu PySpark mengakses dan memproses data besar dengan mudah.
Hal-hal penting dari tutorial percikan Python dibahas berikut ini.
Resilient Distributed Datasets (RDDs): Resilient Distributed Datasets atau RDDs adalah salah satu batu bangunan utama arsitektur pemrograman PySpark. Koleksi ini tidak dapat diubah dan mengalami transformasi yang lemah. Setiap kata dari singkatan ini memiliki makna. Itu tangguh karena dapat mengizinkan kesalahan dan dapat menemukan kembali data. Ini didistribusikan karena meluas ke berbagai node lain dalam sebuah rumpun. Dataset adalah singkatan dari penyimpanan data nilai.
Baca Juga: Pertanyaan Wawancara PySpark Paling Umum
RDD Mendukung Terutama Jenis Operasi Berikut:
1) Transformasi: Transformasi mengikuti prinsip Evaluasi Malas, memungkinkan Anda untuk mengoperasikan eksekusi dengan memanggil tindakan pada data kapan saja. Beberapa dari transformasi tersebut adalah Map, Flat Map, Filter, Distinct, Reduce By Key, Map Partitions, sort by yang disediakan oleh RDD.

2) Tindakan: Operasi RDD memungkinkan PySpark untuk menerapkan perhitungan, meneruskan hasilnya kembali ke driver, yang disebut tindakan.
Langkah-langkah untuk Mengonversi Huruf Besar ke Huruf Kecil dan Membagi String
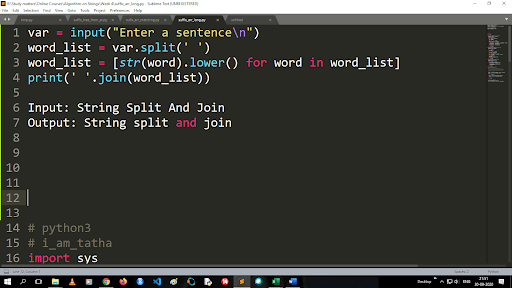
Output dari fungsi split adalah tipe daftar. Untuk menggunakan fungsi join formatnya adalah “.join (sequence data type)” Dengan kode di atas:
Masukan: Pemisahan String dan Gabung
Output: Pemisahan string dan gabung
Bagaimana Cara Membaca Berkas?
Baca file dengan Python dengan memanggil file .txt dalam "mode baca"(r).
Langkah 1) Buka file dalam mode Baca
f=buka(“contoh.txt”, ”r”)
Langkah 2) Kami menggunakan fungsi mode dalam kode untuk memeriksa apakah file dalam mode terbuka.
f.mode == 'r':
Langkah 3) Gunakan f.read untuk membaca data file dan menyimpannya dalam konten variabel
isi = f.read()
Langkah-langkah dalam Analisis Prediktif:
- Eksplorasi data: Anda harus mengumpulkan data, mengunggahnya, dan mencari tahu tipe data, jenisnya, dan nilainya.
- Pembersihan data: Anda harus menemukan nilai nol, nilai yang hilang, dan redundansi lain yang mungkin menghambat program.
- Pemodelan: Anda harus memilih model prediktif.
- Evaluasi: Anda harus memeriksa keakuratan analisis Anda.
Streaming PySpark
PySpark Streaming tidak lain adalah sistem yang dapat diperluas dan bebas kesalahan. Ini mematuhi interval batch RDD mulai dari 500ms hingga slot interval yang lebih tinggi. Menurut tutorial percikan Python , Spark Streaming diberikan beberapa data yang dialirkan sebagai input.
Bergantung pada jumlah interval batch RDD, data yang dialirkan ini dibagi menjadi banyak batch dan dikirim ke Spark Engine. Beberapa sumber dari mana aliran data diterima adalah Kinesis, Kafka, Apache Flume, dll. Dengan menggunakan Struktur Data dan algoritma, Spark Engine dapat mengambil data. Setelah itu, data yang diambil diteruskan ke berbagai sistem file dan database.
Seperti yang dinyatakan sebelumnya, PySpark adalah API tingkat tinggi. Meskipun terjadi kegagalan, operasi streaming hanya akan dijalankan sekali. Salah satu gangguan utama PySpark Streaming adalah Discretized Stream. Komponen aliran ini juga dibuat dengan bantuan kumpulan RDD. MLib, SQL, Dataframe digunakan untuk memperluas jangkauan operasi yang luas untuk Spark Streaming.
Dalam Tutorial PySpark ini , Anda mengetahui bahwa Spark Stream mengambil banyak data dari berbagai sumber. Ini dimungkinkan karena menggunakan algoritme kompleks yang mencakup komponen yang sangat fungsional — Petakan, Perkecil, Gabung, dan Jendela.
Ini adalah hal-hal yang meringkas apa itu PySpark Streaming. Sekarang dalam tutorial Spark python ini , mari kita bicara tentang beberapa keunggulan PySpark.
Keuntungan dari PySpark
Segmen ini dapat dibagi menjadi dua bagian. Pertama-tama, Anda akan mengetahui keuntungan menggunakan Python di PySpark dan, kedua, keuntungan dari PySpark itu sendiri.
- Menjadi bahasa tingkat tinggi dan ramah pembuat kode, bahasa ini mudah dipelajari dan dijalankan.
- API yang sederhana dan inklusif dapat digunakan.
- Python memberi pembaca peluang bagus untuk memvisualisasikan data.
- Python memiliki berbagai perpustakaan. Beberapa contohnya adalah Matplotlib, Pandas, Seaborn, NumPy, dll.
Nah, berikut ini fitur-fitur Tutorial PySpark :
- PySpark Streaming dengan mudah mengintegrasikan bahasa pemrograman lain seperti Java, Scala, dan R.
- PySpark memfasilitasi programmer untuk melakukan beberapa fungsi dengan Resilient Distributed Datasets (RDDs)
- PySpark lebih disukai daripada solusi Big Data lainnya karena kecepatan tinggi, penangkapan yang kuat, dan mekanisme persisten disk untuk memproses data.
Wajib Dibaca: Tutorial Python untuk Pemula
Penyertaan Ilmu Data dan Pembelajaran Mesin di PySpark
Menjadi bahasa pemrograman yang sangat fungsional, Python adalah tulang punggung Ilmu Data dan Pembelajaran Mesin. Oleh karena itu, tidak mengherankan jika Ilmu Data dan ML adalah bagian integral dari sistem PySpark. Machine Learning Library (MLib) adalah operator yang mengontrol fungsionalitas Machine Learning di PySpark.
Berikut keuntungan menggunakan Machine Learning di PySpark:
- Ini sangat dapat diperluas.
- Itu tetap berfungsi dalam sistem terdistribusi.
Fungsi utama Machine Learning di PySpark:
- Machine Learning mempersiapkan berbagai metode dan keterampilan untuk pemrosesan data yang tepat. Ini adalah transformasi, ekstraksi, hashing, seleksi, dll.
- Ini menyediakan beberapa algoritma yang kompleks, seperti yang disebutkan sebelumnya. Ini digunakan untuk memproses data dari berbagai sumber.
- Ini menggunakan beberapa interpretasi matematis dan data statistik. Ini melibatkan aljabar linier dan proses evaluasi model.
Kesimpulan
Dalam tutorial ini, kami membahas fitur utama, pengaturan lingkungan, membaca file dan banyak lagi.
Jika Anda penasaran untuk belajar tentang ilmu data, lihat Program PG Eksekutif IIIT-B & upGrad dalam Ilmu Data yang dibuat untuk para profesional yang bekerja dan menawarkan 10+ studi kasus & proyek, lokakarya praktis, bimbingan dengan pakar industri, 1 -on-1 dengan mentor industri, 400+ jam pembelajaran dan bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa itu PySpark?
PySpark dibentuk untuk mempromosikan kolaborasi Apache Spark dengan Python. Kolaborasi ini menyediakan API Python untuk Spark. Selanjutnya, PySpark memungkinkan pengguna untuk berinteraksi dengan Resilient Distributed Datasets (RDDs) di Apache Spark dan Python. PySpark memungkinkan pengguna untuk dengan cepat mengintegrasikan dan berinteraksi dengan RDD dalam bahasa pemrograman Python. Ada beberapa karakteristik yang membuat PySpark menjadi alat yang sangat baik untuk bekerja dengan kumpulan data besar. Insinyur Data beralih ke alat ini untuk melakukan perhitungan pada kumpulan data besar atau hanya untuk mempelajarinya. Hal ini dicapai dengan memanfaatkan perpustakaan Py4j.
Apa kasus penggunaan nyata dari PySpark?
PySpark saat ini digunakan untuk Streaming ETL. Streaming ETL terus membersihkan dan mengumpulkan data sebelum dikirim ke penyimpanan data. PySpark membantu pengayaan data dengan memperkaya data langsung dengan mengintegrasikannya dengan data statis, memungkinkan perusahaan melakukan analisis data waktu nyata yang lebih komprehensif. Pyspark juga digunakan untuk Deteksi Pemicu. Pemicu digunakan oleh organisasi keuangan untuk mendeteksi transaksi penipuan dan menghentikannya. Pemicu juga digunakan di rumah sakit untuk mengidentifikasi perubahan kesehatan yang berpotensi membahayakan sambil memantau tanda-tanda vital pasien, memberikan pemberitahuan otomatis kepada perawat terkait yang kemudian dapat mengambil tindakan cepat dan diperlukan.
Apakah Python dan PySpark terkait?
PySpark adalah hasil dari kemitraan Apache Spark dan Python. Python adalah tujuan umum, bahasa pemrograman tingkat tinggi, sedangkan Apache Spark adalah platform komputasi cluster open-source yang berfokus pada kecepatan, kemudahan penggunaan, dan analitik streaming. Ini menawarkan serangkaian perpustakaan yang beragam dan sebagian besar digunakan untuk Pembelajaran Mesin dan Analisis Streaming Real-Time. Artinya, ini adalah API Python untuk Spark yang memungkinkan Anda menjinakkan Big Data dengan menggabungkan kesederhanaan Python dengan kekuatan Apache Spark.