
Учебное пособие по PySpark для начинающих [с примерами]
Опубликовано: 2020-10-07PySpark — это облачная платформа, функционирующая как сервисная архитектура. Платформа предоставляет среду для вычисления файлов больших данных. PySpark относится к применению языка программирования Python в сочетании с кластерами Spark. Он тесно связан с большими данными. Дайте нам сначала кратко узнать, с чем имеют дело большие данные, и получить обзор учебника PySpark .
Оглавление
Для чего используется PySpark?
Как API Python для Spark, выпущенный сообществом Apache Spark, он поддерживает Python с Spark. Продолжайте читать эту статью об учебном пособии по искровому Python , чтобы узнать больше об использовании.
- С помощью PySpark можно интегрировать и эффективно работать с устойчивыми распределенными наборами данных (RDD) в Python.
- Многочисленные функции делают PySpark отличным фреймворком, поскольку он облегчает работу с массивными наборами данных.
- PySpark предоставляет широкий спектр библиотек, а машинное обучение и потоковая аналитика в реальном времени упрощаются с помощью PySpark.
- PySpark сочетает в себе простоту Python и мощь Apache Spark, используемых для обработки больших данных.
- С появлением больших данных были развиты возможности таких технологий, как Apache Spark и Hadoop.
- Специалист по обработке и анализу данных может эффективно обрабатывать большие наборы данных, так как это доступно любому разработчику Python.
Читать: Dataframe в Apache PySpark
Концепции больших данных в Python
Python — это язык программирования высокого уровня, который также предоставляет множество парадигм программирования, таких как объектно-ориентированное программирование (ООП), асинхронное и функциональное программирование.
Функциональное программирование — важная парадигма при работе с большими данными. Он следует параллельному коду, что означает, что вы можете запускать свой код на нескольких процессорах, а также на совершенно разных машинах. Экосистема PySpark позволяет вам использовать функциональный код и распределять его по кластеру компьютеров.
Основные идеи функционального программирования для программистов доступны в стандартной библиотеке и встроенных модулях Python.
Манипуляции с данными, происходящие через функции без какого-либо внешнего обслуживания состояния, являются воплощением основной идеи функционального программирования. Это означает, что ваш код обходит глобальные переменные и не манипулирует данными на месте, а всегда возвращает новые данные. Python использует ключевое слово lambda для предоставления анонимных функций.
Пройдите сертификационный курс по науке о данных в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.
Некоторые ключевые особенности PySpark
- Polyglot: PySpark — одна из самых популярных платформ для вычислений с использованием массивных наборов данных. Он также совместим с несколькими языками.
- Сохранение данных на диске и кэширование. Платформа PySpark обеспечивает впечатляющее сохранение данных на диске и мощное кэширование.
- Быстрая обработка. По сравнению с другими традиционными платформами, используемыми для обработки больших данных, платформа PySpark работает довольно быстро.
- Хорошо работает с RDD: Python динамически типизирован для языка программирования, что помогает работать с устойчивыми распределенными наборами данных.
Что такое ПиСпарк?
Этот учебник по Pyspark позволит вам понять, что такое PySpark. PySpark — это интерфейс прикладного программирования Python (API). API написан на Python для установления соединения с Apache Spark. Как вы знаете, Apache Spark занимается анализом больших данных. Язык программирования Scala используется для создания Apache Spark. Его можно интегрировать с другими языками программирования, а именно с Python, Java, SQL, R и самим Scala.
PySpark основан на двух наборах подтверждений:
- PySpark API: у него много примеров.
- Spark Scala API: для программ PySpark он переводит код Scala, который сам по себе является очень читаемым и рабочим языком программирования, в код Python и делает его понятным.
Py4J дает программе Python возможность общаться через код на основе JVM. Это помогает PySpark подключаться к интерфейсу прикладного программирования на основе Spark Scala.
Как установить среду PySpark
Теперь давайте обсудим различные среды, в которых PySpark начинает работу и для которых применяется. Следуйте этому руководству по искрам Python , чтобы установить PySpark:
- Самостоятельное размещение: в этом случае вы можете создать коллекцию или собрать себя. В этой среде вы можете использовать металлические или виртуальные кластеры. Есть несколько предлагаемых проектов, а именно Apache Ambari, которые применимы для этой цели. Однако этот процесс недостаточно быстрый.
- Облачные провайдеры: в этом случае чаще всего используются кластеры Spark. Эта среда обслуживает быстрее, чем самостоятельный хостинг. Amazon Web Services (AWS) использует Electronic MapReduce (EMR), а Good Clinical Practice (GCP) — Dataproc.
- Решения поставщиков: Databricks и Cloudera предоставляют решения Spark. Это один из самых быстрых способов запуска PySpark.
PySpark Программирование
Как мы все знаем, Python — это язык высокого уровня, имеющий несколько библиотек. Он играет очень важную роль в машинном обучении и анализе данных. Поэтому PySpark — это API для искры, написанный на Python. У Spark есть несколько отличных характеристик, включая высокую скорость, легкий доступ и применение для потоковой аналитики. В дополнение к этому, структура Spark и Python помогает PySpark легко получать доступ к большим данным и обрабатывать их.
Основы искрового учебника Python обсуждаются ниже.
Устойчивые распределенные наборы данных (RDD). Устойчивые распределенные наборы данных или RDD являются одной из основных составляющих архитектуры программирования PySpark. Этот набор неизменен и претерпевает слабые преобразования. Каждое слово этой аббревиатуры имеет значение. Он устойчив, потому что может допускать ошибки и заново обнаруживать данные. Он распределен, потому что он расширяется по различным другим узлам в группе. Набор данных означает хранилище данных значений.
Читайте также: Наиболее распространенные вопросы на собеседовании в PySpark
RDD поддерживает в первую очередь следующие типы операций
1) Преобразования: преобразования, следующие принципу ленивых вычислений, позволяют вам управлять выполнением, вызывая действие над данными в любое время. Немногие из преобразований — «Карта», «Плоская карта», «Фильтр», «Отличение», «Уменьшить по ключу», «Разделы карты», сортировка по которым обеспечивается RDD.

2) Действия: операции RDD позволяют PySpark применять вычисления, передавая результат обратно драйверу, что называется действиями.
Шаги для преобразования верхнего регистра в нижний регистр и разделения строки
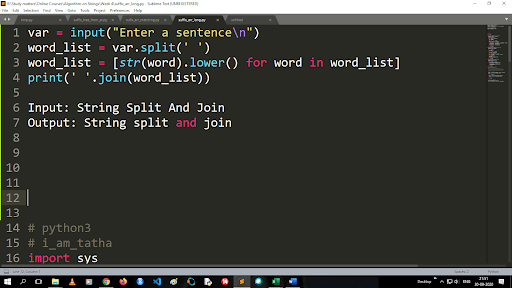
Вывод функции разделения имеет тип списка. Для использования функции объединения используется формат «.join (тип данных последовательности)». С приведенным выше кодом:
Ввод: Разделение и объединение строк
Вывод: разделить строку и присоединиться
Как прочитать файл?
Прочитайте файл в Python, вызвав файл .txt в «режиме чтения» (r).
Шаг 1) Откройте файл в режиме чтения
f=открыть("sample.txt", "r")
Шаг 2) Мы используем функцию режима в коде, чтобы проверить, что файл находится в открытом режиме.
f.mode == 'r':
Шаг 3) Используйте f.read для чтения данных файла и сохранения их в переменном содержимом.
содержимое = f.read()
Этапы прогнозного анализа:
- Исследование данных: вам нужно собрать данные, загрузить их и выяснить тип данных, их тип и значение.
- Очистка данных: вам нужно найти нулевые значения, отсутствующие значения и другие избыточные значения, которые могут помешать работе программы.
- Моделирование: вам нужно выбрать прогнозную модель.
- Оценка: Вы должны проверить точность своего анализа.
Потоковая передача PySpark
PySpark Streaming — это не что иное, как расширяемая безошибочная система. Он соблюдает интервалы пакетов RDD в диапазоне от 500 мс до интервалов с более высокими интервалами. Согласно учебному пособию по искрам Python , Spark Streaming получает в качестве входных данных некоторые потоковые данные.
В зависимости от количества интервалов пакетов RDD эти потоковые данные делятся на несколько пакетов и отправляются в Spark Engine. Некоторыми источниками, из которых получаются потоковые данные, являются Kinesis, Kafka, Apache Flume и т. д. Используя структуры данных и алгоритмы, Spark Engines может извлекать данные. После этого полученные данные пересылаются в различные файловые системы и базы данных.
Как указывалось ранее, PySpark — это высокоуровневый API. Несмотря на любой сбой, потоковая операция будет выполнена только один раз. Одним из основных отвлекающих факторов потоковой передачи PySpark является дискретизированный поток. Эти потоковые компоненты также создаются с помощью пакетов RDD. MLib, SQL, Dataframes используются для расширения широкого спектра операций для Spark Streaming.
В этом учебном пособии по PySpark вы узнаете, что Spark Stream извлекает множество данных из различных источников. Это возможно благодаря тому, что в нем используются сложные алгоритмы, включающие высокофункциональные компоненты — Map, Reduce, Join и Window.
Это вещи, которые подводят итог тому, что такое PySpark Streaming. Теперь в этом учебнике по Spark python давайте поговорим о некоторых преимуществах PySpark.
Преимущества PySpark
Этот сегмент можно разделить на две части. Во-первых, вы познакомитесь с преимуществами использования Python в PySpark и, во-вторых, с преимуществами самого PySpark.
- Будучи высокоуровневым и дружественным к кодировщику языком, его легко изучать и выполнять.
- Можно использовать простой и всеобъемлющий API.
- Python дает читателю прекрасную возможность визуализировать данные.
- Python имеет широкий спектр библиотек. Некоторые из примеров — Matplotlib, Pandas, Seaborn, NumPy и т. д.
Ниже перечислены функции PySpark Tutorial :
- PySpark Streaming легко интегрируется с другими языками программирования, такими как Java, Scala и R.
- PySpark помогает программистам выполнять несколько функций с помощью устойчивых распределенных наборов данных (RDD).
- PySpark предпочтительнее других решений для работы с большими данными из-за его высокой скорости, мощных механизмов перехвата и сохранения данных на диске для обработки данных.
Обязательно к прочтению: учебник по Python для начинающих
Включение науки о данных и машинного обучения в PySpark
Будучи высокофункциональным языком программирования, Python является основой науки о данных и машинного обучения. Поэтому неудивительно, что Data Science и ML являются неотъемлемыми частями системы PySpark. Библиотека машинного обучения (MLib) — это оператор, управляющий функциями машинного обучения в PySpark.
Ниже приведены преимущества использования машинного обучения в PySpark:
- Он очень расширяемый.
- Он остается функциональным в распределенных системах.
Основные функции машинного обучения в PySpark:
- Машинное обучение готовит различные методы и навыки для правильной обработки данных. Это преобразование, извлечение, хэширование, отбор и т. д.
- Он предоставляет некоторые сложные алгоритмы, как упоминалось ранее. Они используются для обработки данных из различных источников.
- Он использует некоторую математическую интерпретацию и статистические данные. Он включает линейную алгебру и процессы оценки моделей.
Заключение
В этом уроке мы обсудили ключевые функции, настройку среды, чтение файла и многое другое.
Если вам интересно узнать о науке о данных, ознакомьтесь с программой IIIT-B & upGrad Executive PG по науке о данных, которая создана для работающих профессионалов и предлагает более 10 тематических исследований и проектов, практические семинары, наставничество с отраслевыми экспертами, 1 -на-1 с отраслевыми наставниками, более 400 часов обучения и помощи в трудоустройстве в ведущих фирмах.
Что такое ПиСпарк?
PySpark был создан для продвижения сотрудничества Apache Spark с Python. Это сотрудничество предоставляет Python API для Spark. Кроме того, PySpark позволяет пользователям взаимодействовать с устойчивыми распределенными наборами данных (RDD) в Apache Spark и Python. PySpark позволяет пользователям быстро интегрировать и взаимодействовать с RDD на языке программирования Python. Есть несколько характеристик, которые делают PySpark таким отличным инструментом для работы с большими наборами данных. Инженеры данных обращаются к этому инструменту, чтобы выполнять вычисления с огромными наборами данных или просто изучать их. Это достигается за счет использования библиотеки Py4j.
Каковы реальные варианты использования PySpark?
PySpark в настоящее время используется для Streaming ETL. Streaming ETL постоянно очищает и агрегирует данные, прежде чем они будут доставлены в хранилище данных. PySpark помогает обогащать данные, обогащая оперативные данные путем их интеграции со статическими данными, что позволяет компаниям выполнять более полный анализ данных в реальном времени. Pyspark также используется для обнаружения триггеров. Триггеры используются финансовыми организациями для обнаружения мошеннических транзакций и их предотвращения. Триггеры также используются в больницах для выявления потенциально опасных изменений состояния здоровья при мониторинге основных показателей жизнедеятельности пациента, доставляя автоматические уведомления соответствующим лицам, осуществляющим уход, которые затем могут принять незамедлительные и необходимые меры.
Связаны ли Python и PySpark?
PySpark — результат партнерства Apache Spark и Python. Python — это язык программирования высокого уровня общего назначения, тогда как Apache Spark — это платформа кластерных вычислений с открытым исходным кодом, ориентированная на скорость, простоту использования и потоковую аналитику. Он предлагает разнообразный набор библиотек и в основном используется для машинного обучения и потоковой аналитики в реальном времени. Это означает, что это API Python для Spark, который позволяет вам управлять большими данными, сочетая простоту Python с мощью Apache Spark.