
PySpark 初学者教程 [附示例]
已发表: 2020-10-07PySpark 是一个基于云的平台,用作服务架构。 该平台提供了计算大数据文件的环境。 PySpark 是指 Python 编程语言与 Spark 集群相关联的应用。 它与大数据密切相关。 让我们先简要了解大数据处理的内容,并大致了解PySpark 教程。
目录
PySpark 有什么用途?
作为 Apache Spark 社区发布的用于 Spark 的 Python API,它支持 Python 和 Spark。 继续阅读有关Spark 教程 Python的这篇文章,以了解更多关于其用途的信息。
- 通过使用 PySpark,可以在 Python 中集成弹性分布式数据集 (RDD) 并有效地工作。
- 众多功能使 PySpark 成为一个出色的框架,因为它有助于处理大量数据集。
- PySpark 提供了广泛的库,在 PySpark 的帮助下,机器学习和实时流分析变得更加容易。
- PySpark 利用 Python 的简单性和用于驯服大数据的 Apache Spark 的强大功能。
- 随着大数据的出现,Apache Spark 和 Hadoop 等技术的力量得到了发展。
- 数据科学家可以有效地处理大型数据集,因为任何 Python 开发人员都可以做到。
阅读: Apache PySpark 中的数据框
Python 中的大数据概念
Python 是一种高级编程语言,它还公开了许多编程范式,例如面向对象编程 (OOP)、异步和函数式编程。
在处理大数据时,函数式编程是一个重要的范例。 它遵循并行代码,这意味着您可以在多个 CPU 以及完全不同的机器上运行您的代码。 PySpark 生态系统允许您使用功能代码并将其分布在计算机集群中。
程序员的函数式编程核心思想可在 Python 的标准库和内置函数中找到。
通过函数进行数据操作,无需任何外部状态维护,是函数式编程的核心思想体现。 这代表您的代码绕过全局变量并且不会就地操作数据但总是返回新数据的事实。 Python 使用 lambda 关键字来公开匿名函数。
学习世界顶尖大学的数据科学认证课程。 获得行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。
PySpark 的一些关键特性
- Polyglot:PySpark 是通过海量数据集进行计算的最受好评的框架之一。 它也与多种语言兼容。
- 磁盘持久性和缓存:PySpark 框架提供了令人印象深刻的磁盘持久性和强大的缓存。
- 快速处理:与其他用于大数据处理的传统框架相比,PySpark 框架非常快。
- 适用于 RDD:Python 是一种动态类型的编程语言,有助于使用弹性分布式数据集。
什么是 PySpark?
本Pyspark 教程将让您了解 PySpark 是什么。 PySpark 是一个 Python 应用程序编程接口 (API)。 API 是用 Python 编写的,用于与 Apache Spark 建立连接。 如您所知,Apache Spark 处理大数据分析。 编程语言 Scala 用于创建 Apache Spark。 它可以被其他编程语言集成,即 Python、Java、SQL、R 和 Scala 本身。
PySpark 基于两组确证:
- PySpark API:它有很多示例。
- Spark Scala API:对于 PySpark 程序,它将本身是一种非常易读且基于工作的编程语言的 Scala 代码转换为 python 代码并使其易于理解。
Py4J 使 Python 程序可以自由地通过基于 JVM 的代码进行通信。 它帮助 PySpark 插入基于 Spark Scala 的应用程序编程接口。
如何设置 PySpark 环境
现在让我们讨论 PySpark 入门和应用的不同环境。 按照这个Spark教程 Python设置 PySpark:
- 自托管:在这种情况下,您可以自己设置集合或集群。 在这种环境中,您可以考虑使用金属或虚拟集群。 有一些提议的项目,即适用于此目的的 Apache Ambari。 然而,这个过程还不够快。
- 云提供商:在这种情况下,通常会使用 Spark 集群。 这种环境比自托管更快。 Amazon Web 服务 (AWS) 具有电子 MapReduce (EMR),而良好临床实践 (GCP) 具有 Dataproc。
- 供应商解决方案:Databricks 和 Cloudera 提供 Spark 解决方案。 这是运行 PySpark 的最快方法之一。
PySpark 编程
众所周知,Python 是一种具有多个库的高级语言。 它在机器学习和数据分析中起着非常关键的作用。 因此,PySpark 是用 Python 编写的 spark 的 API。 Spark 具有高速、易于访问和适用于流式分析的一些优良特性。 除此之外,Spark 和 Python 的框架帮助 PySpark 轻松访问和处理大数据。
Spark教程Python的要点将在下面讨论。
弹性分布式数据集 (RDD):弹性分布式数据集或 RDD 是 PySpark 编程架构的主要构建基石之一。 这个集合是不变的并且经历了微弱的转换。 这个缩写的每个单词都有一个意义。 它具有弹性,因为它可以允许错误并且可以重新发现数据。 它是分布式的,因为它在一个丛中扩展到各种其他节点。 数据集代表值数据的存储。
另请阅读:最常见的 PySpark 面试问题

RDD 主要支持以下类型的操作
1) 转换:遵循惰性求值原则的转换,允许您随时通过对数据调用操作来操作执行。 很少有转换是 RDD 提供的 Map、Flat Map、Filter、Distinct、Reduce By Key、Map Partitions,排序依据。
2) 动作: RDD 操作允许 PySpark 应用计算,将结果传递回驱动程序,这称为动作。
将大写转换为小写并拆分字符串的步骤
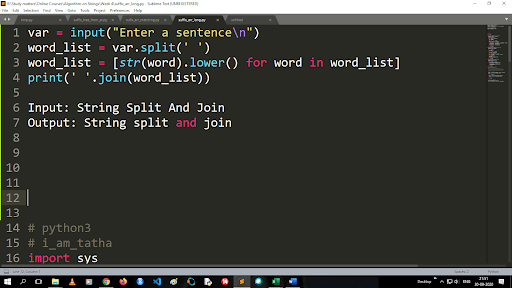
split 函数的输出是列表类型。 使用join函数,格式为“.join(sequence data type)” 上面的代码:
输入:字符串拆分和连接
输出:字符串拆分和连接
如何读取文件?
通过以“读取模式”(r) 调用 .txt 文件来读取 Python 中的文件。
步骤 1) 以读取模式打开文件
f=open(“sample.txt”, “r”)
步骤 2) 我们在代码中使用 mode 函数来检查文件是否处于打开模式。
f.mode == 'r':
步骤 3) 使用 f.read 读取文件数据并将其存储在变量内容中
内容 = f.read()
预测分析的步骤:
- 数据探索:您必须收集数据、上传数据,并确定数据类型、种类和价值。
- 数据清理:您必须找到可能阻碍程序的空值、缺失值和其他冗余。
- 建模:您必须选择一个预测模型。
- 评估:您必须检查分析的准确性。
PySpark 流式传输
PySpark Streaming 只不过是一个可扩展的、无错误的系统。 它遵守从 500ms 到更高间隔槽的 RDD 批处理间隔。 根据spark tutorial Python ,Spark Streaming 被赋予了一些流数据作为输入。
根据 RDD 批处理间隔的数量,这些流式数据被分成许多批处理并发送到 Spark 引擎。 接收流式数据的一些来源是 Kinesis、Kafka、Apache Flume 等。通过使用数据结构和算法,Spark 引擎可以检索数据。 之后,检索到的数据被转发到各种文件系统和数据库。
如前所述,PySpark 是一个高级 API。 尽管发生任何故障,流操作将只执行一次。 PySpark Streaming 的主要干扰之一是离散流。 这些流组件也是在 RDD 批处理的帮助下构建的。 MLib、SQL、Dataframes 用于扩展 Spark Streaming 的广泛操作。
在本PySpark 教程中,您将了解 Spark Stream 从各种来源检索大量数据。 这是可能的,因为它使用了复杂的算法,其中包括功能强大的组件——Map、Reduce、Join 和 Window。
这些是对 PySpark Streaming 的总结。 现在在这个Spark 教程 python中,让我们谈谈 PySpark 的一些优点。
PySpark 的优点
这一段可以分为两部分。 首先,您将了解在 PySpark 中使用 Python 的优势,其次,PySpark 本身的优势。
- 作为一种高级且对编码人员友好的语言,它易于学习和执行。
- 可以使用简单而包容的 API。
- Python 为读者提供了可视化数据的绝佳机会。
- Python 具有广泛的库。 其中一些例子是 Matplotlib、Pandas、Seaborn、NumPy 等。
现在,以下是PySpark 教程的功能:
- PySpark Streaming 可以轻松集成其他编程语言,如 Java、Scala 和 R。
- PySpark 帮助程序员使用弹性分布式数据集 (RDD) 执行多项功能
- PySpark 比其他大数据解决方案更受欢迎,因为它具有高速、强大的捕获和磁盘持久性机制来处理数据。
必读:面向初学者的 Python 教程
PySpark 中包含数据科学和机器学习
作为一种功能强大的编程语言,Python 是数据科学和机器学习的支柱。 因此,数据科学和机器学习是 PySpark 系统的组成部分也就不足为奇了。 机器学习库 (MLib) 是在 PySpark 中控制机器学习功能的运算符。
以下是在 PySpark 中使用机器学习的优势:
- 它是高度可扩展的。
- 它在分布式系统中仍然有效。
PySpark中机器学习的主要功能:
- 机器学习为正确处理数据准备了各种方法和技能。 这些是转换,提取,散列,选择等。
- 如前所述,它提供了一些复杂的算法。 这些用于处理来自各种来源的数据。
- 它使用一些数学解释和统计数据。 它涉及线性代数和模型评估过程。
结论
在本教程中,我们讨论了关键特性、设置环境、读取文件等等。
如果您想了解数据科学,请查看 IIIT-B 和 upGrad 的数据科学执行 PG 计划,该计划是为在职专业人士创建的,提供 10 多个案例研究和项目、实用的实践研讨会、行业专家的指导、1与行业导师一对一,400 多个小时的学习和顶级公司的工作协助。
什么是 PySpark?
PySpark 的成立是为了促进 Apache Spark 与 Python 的协作。 此次合作为 Spark 提供了 Python API。 此外,PySpark 使用户能够与 Apache Spark 和 Python 中的弹性分布式数据集 (RDD) 进行交互。 PySpark 允许用户使用 Python 编程语言快速集成 RDD 并与之交互。 有几个特点使 PySpark 成为处理大型数据集的出色工具。 数据工程师正在转向这个工具来对庞大的数据集进行计算,或者只是为了研究它们。 这是通过使用 Py4j 库来完成的。
PySpark 的实际用例有哪些?
PySpark 当前用于流式 ETL。 流式 ETL 在将数据交付到数据存储之前不断地清理和聚合数据。 PySpark 通过将实时数据与静态数据集成来丰富实时数据,从而帮助数据丰富,使公司能够执行更全面的实时数据分析。 Pyspark 也用于触发检测。 金融组织使用触发器来检测欺诈交易并阻止它们。 医院还使用触发器来识别潜在有害的健康变化,同时监测患者的生命体征,向相关护理人员发送自动通知,然后他们可能会采取迅速和必要的行动。
Python 和 PySpark 是否相关?
PySpark 是 Apache Spark 和 Python 合作的结果。 Python 是一种通用的高级编程语言,而 Apache Spark 是一个专注于速度、易用性和流分析的开源集群计算平台。 它提供了一组多样化的库,主要用于机器学习和实时流分析。 这意味着它是用于 Spark 的 Python API,使您能够通过将 Python 的简单性与 Apache Spark 的强大功能相结合来驯服大数据。