
Tutorial de PySpark para principiantes [con ejemplos]
Publicado: 2020-10-07PySpark es una plataforma basada en la nube que funciona como una arquitectura de servicio. La plataforma proporciona un entorno para calcular archivos de Big Data. PySpark se refiere a la aplicación del lenguaje de programación Python en asociación con los clústeres de Spark. Está profundamente asociado con Big Data. Háganos saber primero qué trata Big Data brevemente y obtenga una descripción general del tutorial de PySpark .
Tabla de contenido
¿Para qué se utiliza PySpark?
Como una API de Python para Spark lanzada por la comunidad de Apache Spark, es compatible con Python con Spark. Sigue leyendo este artículo sobre el tutorial de Spark Python para saber más sobre los usos.
- Con el uso de PySpark, se puede integrar y trabajar de manera eficiente con conjuntos de datos distribuidos resistentes (RDD) en Python.
- Numerosas funciones hacen de PySpark un marco excelente, ya que facilita el trabajo con conjuntos de datos masivos.
- PySpark proporciona bibliotecas de una amplia gama, y el aprendizaje automático y el análisis de transmisión en tiempo real se facilitan con la ayuda de PySpark.
- PySpark aprovecha la simplicidad de Python y el poder de Apache Spark utilizado para controlar Big Data.
- Con la llegada de Big Data, se ha desarrollado el poder de tecnologías como Apache Spark y Hadoop.
- Un científico de datos puede manejar grandes conjuntos de datos de manera eficiente, ya que está al alcance de cualquier desarrollador de Python.
Leer: Marco de datos en Apache PySpark
Conceptos de Big Data en Python
Python es un lenguaje de programación de alto nivel que también expone muchos paradigmas de programación, como la programación orientada a objetos (OOP), la programación asincrónica y funcional.
La programación funcional es un paradigma importante cuando se trata de Big Data. Sigue un código paralelo, lo que significa que puede ejecutar su código en varias CPU, así como en máquinas completamente diferentes. El ecosistema PySpark tiene el poder de permitirle usar código funcional y distribuirlo en un grupo de computadoras.
Las ideas básicas de programación funcional para programadores están disponibles en la biblioteca estándar y las funciones integradas de Python.
La manipulación de datos que se produce a través de funciones sin ningún mantenimiento de estado externo es la encarnación de la idea central de la programación funcional. Esto representa el hecho de que su código elude las variables globales y no manipula los datos en el lugar, sino que siempre devuelve datos nuevos. Python usa la palabra clave lambda para exponer funciones anónimas.
Aprenda el curso de certificación de ciencia de datos de las mejores universidades del mundo. Obtenga programas Executive PG, programas de certificados avanzados o programas de maestría para acelerar su carrera.
Algunas características clave de PySpark
- Polyglot: PySpark es uno de los marcos más apreciables para el cálculo a través de conjuntos de datos masivos. También es compatible con varios idiomas.
- Persistencia de disco y almacenamiento en caché: el marco PySpark proporciona una persistencia de disco impresionante y un potente almacenamiento en caché.
- Procesamiento rápido: en comparación con otros marcos tradicionales utilizados para el procesamiento de Big Data, el marco PySpark es bastante rápido.
- Funciona bien con RDD: Python se escribe dinámicamente para un lenguaje de programación, lo que ayuda a trabajar con conjuntos de datos distribuidos resistentes.
¿Qué es PySpark?
Este tutorial de Pyspark le permitirá comprender qué es PySpark. PySpark es una interfaz de programación de aplicaciones (API) de Python. La API está escrita en Python para formar una conexión con Apache Spark. Como sabes, Apache Spark se ocupa del análisis de big data. El lenguaje de programación Scala se utiliza para crear Apache Spark. Puede integrarse con otros lenguajes de programación, a saber, Python, Java, SQL, R y Scala.
PySpark se basa en dos conjuntos de corroboración:
- API de PySpark: tiene muchas muestras.
- Spark Scala API: para los programas PySpark, traduce el código Scala, que es en sí mismo un lenguaje de programación muy legible y basado en el trabajo, a código python y lo hace comprensible.
Py4J da la libertad a un programa de Python para comunicarse a través de código basado en JVM. Ayuda a PySpark a conectarse con la interfaz de programación de aplicaciones basada en Spark Scala.
Cómo configurar el entorno PySpark
Ahora hablemos de diferentes entornos en los que PySpark se inicia y se aplica. Siga este tutorial de Spark Python para configurar PySpark:
- Autohospedado: en este caso, puede configurar una colección o agruparse usted mismo. En este entorno, puede buscar usar clústeres metálicos o virtuales. Hay algunos proyectos propuestos, a saber, Apache Ambari, que son aplicables para este propósito. Sin embargo, este proceso no es lo suficientemente rápido.
- Proveedores de la nube: en este caso, la mayoría de las veces se utilizan clústeres de Spark. Este entorno sirve más rápido que el alojamiento propio. Amazon Web Services (AWS) tiene Electronic MapReduce (EMR), mientras que Good Clinical Practice (GCP) tiene Dataproc.
- Soluciones de proveedores: Databricks y Cloudera ofrecen soluciones Spark. Es una de las formas más rápidas de ejecutar PySpark.
Programación PySpark
Como todos sabemos, Python es un lenguaje de alto nivel que tiene varias bibliotecas. Desempeña un papel muy importante en el aprendizaje automático y el análisis de datos. Por lo tanto, PySpark es una API para Spark que está escrita en Python. Spark tiene algunos atributos excelentes que incluyen alta velocidad, fácil acceso y se aplica para análisis de transmisión. Además de esto, el marco de Spark y Python ayuda a PySpark a acceder y procesar big data fácilmente.
Los elementos esenciales del tutorial Python de Spark se analizan a continuación.
Conjuntos de datos distribuidos resistentes (RDD): los conjuntos de datos distribuidos resistentes o los RDD son uno de los principales pilares de la arquitectura de programación PySpark. Esta colección es inmutable y sufre transformaciones débiles. Cada palabra de esta abreviatura tiene un significado. Es resistente porque puede permitir errores y redescubrir datos. Se distribuye porque se expande sobre varios otros nodos en un grupo. Conjunto de datos significa el almacenamiento de datos de valores.
Lea también: Preguntas de entrevista PySpark más comunes
RDD admite principalmente los siguientes tipos de operaciones
1) Transformaciones: las transformaciones que siguen el principio de las evaluaciones perezosas le permiten operar ejecuciones llamando a una acción sobre los datos en cualquier momento. Algunas de las transformaciones son Map, Flat Map, Filter, Distinct, Reduce By Key, Map Partitions, ordenadas por RDD.

2) Acciones: las operaciones RDD permiten que PySpark aplique el cálculo, devolviendo el resultado al controlador, lo que se denomina acciones.
Pasos para convertir mayúsculas a minúsculas y dividir una cadena
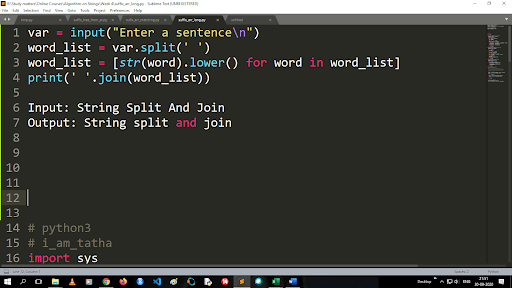
La salida de la función de división es de tipo lista. Para usar la función de unión, el formato es ".join (tipo de datos de secuencia)" Con el código anterior:
Entrada: cadena dividida y unida
Salida: cadena dividida y unida
¿Cómo leer un archivo?
Lea un archivo en Python llamando al archivo .txt en un "modo de lectura" (r).
Paso 1) Abra el archivo en modo Lectura
f=abrir(“muestra.txt”, ”r”)
Paso 2) Usamos la función de modo en el código para comprobar que el archivo está en modo abierto.
modo f == 'r':
Paso 3) Use f.read para leer datos de archivos y almacenarlos en contenido variable
contenido = f.leer()
Pasos en el análisis predictivo:
- Exploración de datos: debe recopilar los datos, cargarlos y determinar el tipo de datos, su tipo y valor.
- Limpieza de datos: debe encontrar los valores nulos, los valores faltantes y otras redundancias que puedan dificultar el programa.
- Modelado: Tienes que seleccionar un modelo predictivo.
- Evaluación: Tienes que comprobar la precisión de tu análisis.
Transmisión PySpark
PySpark Streaming no es más que un sistema extensible y sin errores. Cumple con los intervalos de lote RDD que van desde 500 ms hasta intervalos de intervalo más altos. De acuerdo con el tutorial de Spark Python , Spark Streaming recibe algunos datos transmitidos como entrada.
Según la cantidad de intervalos de lotes de RDD, estos datos transmitidos se dividen en numerosos lotes y se envían a Spark Engine. Algunas de las fuentes desde donde se reciben los datos transmitidos son Kinesis, Kafka, Apache Flume, etc. Mediante el uso de estructuras de datos y algoritmos, los motores Spark pueden recuperar datos. Después de eso, los datos recuperados se envían a varios sistemas de archivos y bases de datos.
Como se indicó anteriormente, PySpark es una API de alto nivel. A pesar de que ocurra cualquier falla, la operación de transmisión se ejecutará solo una vez. Una de las principales distracciones de PySpark Streaming es Discretized Stream. Estos componentes de flujo también se construyen con la ayuda de lotes RDD. MLib, SQL, Dataframes se utilizan para ampliar la amplia gama de operaciones para Spark Streaming.
En este tutorial de PySpark , sabrá que Spark Stream recupera una gran cantidad de datos de varias fuentes. Esto es posible porque utiliza algoritmos complejos que incluyen componentes altamente funcionales: Mapa, Reducir, Unir y Ventana.
Estas son las cosas que resumen lo que es PySpark Streaming. Ahora, en este Python tutorial de Spark , hablemos de algunas de las ventajas de PySpark.
Ventajas de PySpark
Este segmento se puede dividir en dos partes. En primer lugar, conocerás las ventajas de usar Python en PySpark y, en segundo lugar, las ventajas del propio PySpark.
- Al ser un lenguaje de alto nivel y fácil de codificar, es fácil de aprender y ejecutar.
- Se puede utilizar una API simple e inclusiva.
- Python le brinda al lector una excelente oportunidad para visualizar datos.
- Python tiene una amplia gama de bibliotecas. Algunos de los ejemplos son Matplotlib, Pandas, Seaborn, NumPy, etc.
Ahora, las siguientes son las características de PySpark Tutorial :
- PySpark Streaming integra fácilmente otros lenguajes de programación como Java, Scala y R.
- PySpark facilita a los programadores realizar varias funciones con conjuntos de datos distribuidos resistentes (RDD)
- PySpark es preferible a otras soluciones de Big Data debido a su alta velocidad, su potente captura y sus mecanismos persistentes en disco para el procesamiento de datos.
Debe leer: Tutorial de Python para principiantes
Inclusión de ciencia de datos y aprendizaje automático en PySpark
Al ser un lenguaje de programación altamente funcional, Python es la columna vertebral de la ciencia de datos y el aprendizaje automático. Por lo tanto, no sorprende que Data Science y ML sean partes integrales del sistema PySpark. Machine Learning Library (MLib) es el operador que controla la funcionalidad de Machine Learning en PySpark.
Las siguientes son las ventajas de usar Machine Learning en PySpark:
- Es altamente extensible.
- Sigue siendo funcional en sistemas distribuidos.
Las principales funciones de Machine Learning en PySpark:
- Machine Learning prepara varios métodos y habilidades para el correcto procesamiento de datos. Estos son transformación, extracción, hashing, selección, etc.
- Proporciona algunos algoritmos complejos, como se mencionó anteriormente. Estos se utilizan para procesar datos de varias fuentes.
- Utiliza alguna interpretación matemática y datos estadísticos. Implica álgebra lineal y procesos de evaluación de modelos.
Conclusión
En este tutorial, discutimos las características clave, la configuración del entorno, la lectura de un archivo y más.
Si tiene curiosidad por aprender sobre ciencia de datos, consulte el Programa ejecutivo PG en ciencia de datos de IIIT-B y upGrad, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos, tutoría con expertos de la industria, 1 -on-1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¿Qué es PySpark?
PySpark se formó para promover la colaboración de Apache Spark con Python. Esta colaboración proporciona una API de Python para Spark. Además, PySpark permite a los usuarios interactuar con conjuntos de datos distribuidos resistentes (RDD) en Apache Spark y Python. PySpark permite a los usuarios integrar e interactuar rápidamente con RDD en el lenguaje de programación Python. Hay varias características que hacen de PySpark una excelente herramienta para trabajar con grandes conjuntos de datos. Los ingenieros de datos recurren a esta herramienta para realizar cálculos en grandes conjuntos de datos o simplemente para estudiarlos. Esto se logra utilizando la biblioteca Py4j.
¿Cuáles son los casos de uso de la vida real de PySpark?
PySpark se usa actualmente para Streaming ETL. Streaming ETL continuamente limpia y agrega datos antes de que se entreguen en el almacenamiento de datos. PySpark ayuda en el enriquecimiento de datos al enriquecer los datos en vivo integrándolos con datos estáticos, lo que permite a las empresas realizar análisis de datos en tiempo real más completos. Pyspark también se utiliza para la detección de disparadores. Las organizaciones financieras utilizan disparadores para detectar transacciones fraudulentas y detenerlas en seco. Los disparadores también se utilizan en los hospitales para identificar cambios de salud potencialmente dañinos mientras se monitorean los signos vitales del paciente y se envían notificaciones automáticas a los cuidadores relevantes que luego pueden tomar las medidas oportunas y necesarias.
¿Están relacionados Python y PySpark?
PySpark es el resultado de la asociación Apache Spark y Python. Python es un lenguaje de programación de alto nivel y propósito general, mientras que Apache Spark es una plataforma de computación en clúster de código abierto centrada en la velocidad, la facilidad de uso y el análisis de transmisión. Ofrece un conjunto diverso de bibliotecas y se usa principalmente para Machine Learning y Real-Time Streaming Analytics. Significa que es una API de Python para Spark que le permite dominar Big Data al combinar la simplicidad de Python con el poder de Apache Spark.