
Tutorial PySpark pentru începători [cu exemple]
Publicat: 2020-10-07PySpark este o platformă bazată pe cloud care funcționează ca arhitectură de servicii. Platforma oferă un mediu pentru a calcula fișiere Big Data. PySpark se referă la aplicarea limbajului de programare Python în asociere cu clusterele Spark. Este profund asociat cu Big Data. Spuneți-ne mai întâi despre ce se ocupă Big Data și obțineți o prezentare generală a tutorialului PySpark .
Cuprins
Pentru ce este folosit PySpark?
Ca API Python pentru Spark lansat de comunitatea Apache Spark, acceptă Python cu Spark. Continuați să citiți acest articol despre spark tutorial Python pentru a afla mai multe despre utilizări.
- Cu utilizarea PySpark, se poate integra și lucra eficient cu Resilient Distributed Datasets (RDD) în Python.
- Numeroase caracteristici fac din PySpark un cadru excelent, deoarece facilitează lucrul cu seturi de date masive.
- PySpark oferă biblioteci dintr-o gamă largă, iar învățarea automată și Analytics în flux în timp real sunt simplificate cu ajutorul PySpark.
- PySpark valorifică simplitatea lui Python și puterea Apache Spark folosită pentru îmblânzirea Big Data.
- Odată cu apariția Big Data, puterea tehnologiilor precum Apache Spark și Hadoop a fost dezvoltată.
- Un cercetător de date poate gestiona eficient seturi mari de date, fiind la îndemâna oricărui dezvoltator Python.
Citiți: Dataframe în Apache PySpark
Concepte de date mari în Python
Python este un limbaj de programare de nivel înalt care expune, de asemenea, multe paradigme de programare, cum ar fi programarea orientată pe obiecte (OOP), programarea asincronă și funcțională.
Programarea funcțională este o paradigmă importantă atunci când aveți de-a face cu Big Data. Urmează un cod paralel, ceea ce înseamnă că puteți rula codul pe mai multe procesoare, precum și pe mașini complet diferite. Ecosistemul PySpark are puterea de a vă permite să utilizați cod funcțional și să-l distribuiți pe un cluster de computere.
Ideile de bază de programare funcțională pentru programatori sunt disponibile în biblioteca standard și în built-in-urile Python.
Manipularea datelor care are loc prin funcții fără menținerea stării externe este întruchiparea ideii de bază a programării funcționale. Acest lucru reprezintă faptul că codul dvs. ocolește variabilele globale și nu manipulează datele în loc, ci returnează întotdeauna date noi. Python folosește cuvântul cheie lambda pentru a expune funcții anonime.
Învață curs de certificare în știința datelor de la cele mai bune universități din lume. Câștigă programe Executive PG, programe avansate de certificat sau programe de master pentru a-ți accelera cariera.
Câteva caracteristici cheie ale PySpark
- Polyglot: PySpark este unul dintre cele mai apreciate cadre de calcul prin seturi de date masive. Este compatibil și cu mai multe limbi.
- Persistența discului și stocarea în cache: cadrul PySpark oferă o persistență impresionantă a discului și un cache puternic.
- Procesare rapidă: în comparație cu celelalte cadre tradiționale utilizate pentru procesarea Big Data, cadrul PySpark este destul de rapid.
- Funcționează bine cu RDD-uri: Python este tastat dinamic pentru un limbaj de programare, ceea ce ajută la lucrul cu seturi de date distribuite rezistente.
Ce este PySpark?
Acest tutorial Pyspark vă va permite să înțelegeți ce este PySpark. PySpark este o interfață de programare a aplicațiilor (API) Python. API-ul este scris în Python pentru a forma o conexiune cu Apache Spark. După cum știți, Apache Spark se ocupă de analiza datelor mari. Limbajul de programare Scala este folosit pentru a crea Apache Spark. Poate fi integrat de alte limbaje de programare, și anume Python, Java, SQL, R și Scala în sine.
PySpark se bazează pe două seturi de coroborare:
- PySpark API: Are o mulțime de mostre.
- Spark Scala API: pentru programele PySpark, traduce codul Scala, care este în sine un limbaj de programare foarte lizibil și bazat pe lucru, în cod python și îl face ușor de înțeles.
Py4J oferă unui program Python libertatea de a comunica prin cod bazat pe JVM. Ajută PySpark să se conecteze cu interfața de programare a aplicațiilor bazată pe Spark Scala.
Cum să setați mediul PySpark
Acum să discutăm despre diferite medii în care PySpark începe și pentru care este aplicat. Urmați acest tutorial Spark Python pentru a seta PySpark:
- Self Hosted: În acest caz, puteți configura o colecție sau un grup. În acest mediu, puteți căuta să utilizați clustere metalice sau virtuale. Sunt câteva proiecte propuse și anume Apache Ambari care sunt aplicabile în acest scop. Cu toate acestea, acest proces nu este suficient de rapid.
- Furnizori de cloud: În acest caz, de cele mai multe ori, sunt utilizate clustere Spark. Acest mediu servește mai rapid decât auto-găzduirea. Amazon Web Services (AWS) are Electronic MapReduce (EMR), în timp ce Good Clinical Practice (GCP) are Dataproc.
- Soluții pentru furnizori: Databricks și Cloudera oferă soluții Spark. Este una dintre cele mai rapide moduri de a rula PySpark.
Programare PySpark
După cum știm cu toții, Python este un limbaj de nivel înalt care are mai multe biblioteci. Joacă un rol foarte important în Machine Learning și Data Analytics. Prin urmare, PySpark este un API pentru scânteia care este scrisă în Python. Spark are câteva atribute excelente, cu viteză mare, acces ușor și aplicate pentru analize de streaming. În plus, cadrul Spark și Python îl ajută pe PySpark să acceseze și să proceseze cu ușurință datele mari.
Elementele esențiale ale tutorialului spark Python sunt discutate în cele ce urmează.
Seturi de date distribuite rezistente (RDD): Seturile de date distribuite rezistente sau RDD-urile sunt una dintre pietrele principale ale arhitecturii de programare PySpark. Această colecție este neschimbată și suferă transformări slabe. Fiecare cuvânt al acestei abrevieri are o semnificație. Este rezistent deoarece poate permite greșeli și poate redescoperi datele. Este distribuit deoarece se extinde peste diferite alte noduri dintr-un pâlc. Setul de date înseamnă stocarea datelor de valori.
Citiți și: Cele mai frecvente întrebări la interviu PySpark
RDD acceptă în primul rând următoarele tipuri de operații
1) Transformări: Transformări după principiul Evaluărilor Leneșe, vă permite să operați execuții prin apelarea unei acțiuni asupra datelor în orice moment. Câteva dintre transformări sunt Hartă, Hartă plată, Filtru, Distinct, Reducere după cheie, Partiții hărți, sortate după care sunt furnizate de RDD-uri.

2) Acțiuni: Operațiile RDD permit PySpark să aplice calcule, trecând rezultatul înapoi driverului, ceea ce se numește acțiuni.
Pași pentru a converti majuscule în minuscule și a împărți un șir
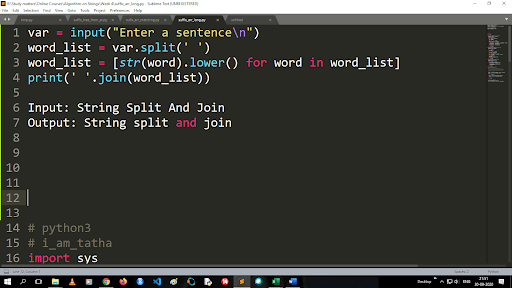
Ieșirea funcției split este de tip listă. Pentru a utiliza funcția de unire, formatul este „.join (tip de date secvență)” Cu codul de mai sus:
Intrare: String Split and Join
Ieșire: Împărțirea și unirea șirurilor
Cum să citești un fișier?
Citiți un fișier în Python apelând fișierul .txt într-un „mod de citire” (r).
Pasul 1) Deschideți fișierul în modul Citire
f=open(„sample.txt”, ”r”)
Pasul 2) Folosim funcția de mod din cod pentru a verifica dacă fișierul este în modul deschis.
f.mode == 'r':
Pasul 3) Utilizați f.read pentru a citi datele fișierului și a le stoca în conținut variabil
conținut = f.read()
Pași în analiza predictivă:
- Explorarea datelor: trebuie să adunați datele, să le încărcați și să aflați tipul de date, tipul și valoarea acestora.
- Curățarea datelor: trebuie să găsiți valorile nule, valorile lipsă și alte redundanțe care ar putea împiedica programul.
- Modelare: trebuie să selectați un model predictiv.
- Evaluare: trebuie să verificați acuratețea analizei dvs.
PySpark Streaming
PySpark Streaming nu este altceva decât un sistem extensibil, fără erori. Respectă intervalele de loturi RDD care variază de la 500 ms la intervale mai mari. Conform tutorialului Spark Python , Spark Streaming primește câteva date transmise ca intrare.
În funcție de numărul de intervale de loturi RDD, aceste date transmise în flux sunt împărțite în numeroase loturi și sunt trimise la Spark Engine. Unele dintre sursele de unde sunt primite datele transmise în flux sunt Kinesis, Kafka, Apache Flume etc. Prin utilizarea structurilor de date și a algoritmilor, Spark Engines poate prelua date. După aceea, datele preluate sunt redirecționate către diferite sisteme de fișiere și baze de date.
După cum am menționat mai devreme, PySpark este un API de nivel înalt. În ciuda oricărei erori, operațiunea de streaming va fi executată o singură dată. Una dintre principalele distragere a atenției PySpark Streaming este Discretized Stream. Aceste componente de flux sunt, de asemenea, construite cu ajutorul loturilor RDD. MLib, SQL, Dataframes sunt folosite pentru a extinde gama largă de operațiuni pentru Spark Streaming.
În acest Tutorial PySpark , veți afla că Spark Stream preia o mulțime de date din diverse surse. Acest lucru este posibil deoarece utilizează algoritmi complecși care includ componente extrem de funcționale - Hartă, Reducere, Unire și Fereastră.
Acestea sunt lucrurile care rezumă ce este PySpark Streaming. Acum, în acest tutorial Spark python , să vorbim despre câteva dintre avantajele PySpark.
Avantajele PySpark
Acest segment poate fi împărțit în două părți. În primul rând, veți cunoaște avantajele utilizării Python în PySpark și, în al doilea rând, avantajele PySpark în sine.
- Fiind un limbaj de nivel înalt și prietenos cu codificatorii, este ușor de învățat și executat.
- Se poate folosi un API simplu și cuprinzător.
- Python oferă cititorului o oportunitate excelentă de a vizualiza datele.
- Python are o gamă largă de biblioteci. Unele dintre exemple sunt Matplotlib, Pandas, Seaborn, NumPy etc.
Acum, următoarele sunt caracteristicile Tutorialului PySpark :
- PySpark Streaming integrează cu ușurință alte limbaje de programare precum Java, Scala și R.
- PySpark facilitează programatorilor să îndeplinească mai multe funcții cu Resilient Distributed Datasets (RDD-uri)
- PySpark este preferat față de alte soluții de Big Data datorită vitezei mari, a mecanismelor puternice de capturare și persistente pe disc pentru procesarea datelor.
Trebuie citit: Tutorial Python pentru începători
Includerea științei datelor și a învățării automate în PySpark
Fiind un limbaj de programare extrem de funcțional, Python este coloana vertebrală a științei datelor și a învățării automate. Prin urmare, nu este o surpriză faptul că Data Science și ML sunt părțile integrante ale sistemului PySpark. Machine Learning Library (MLib) este operatorul care controlează funcționalitatea Machine Learning în PySpark.
Următoarele sunt avantajele utilizării Machine Learning în PySpark:
- Este foarte extensibil.
- Rămâne funcțional în sistemele distribuite.
Principalele funcții ale Machine Learning în PySpark:
- Machine Learning pregătește diverse metode și abilități pentru prelucrarea corectă a datelor. Acestea sunt transformarea, extracția, hashingul, selecția etc.
- Acesta oferă niște algoritmi complexi, așa cum am menționat mai devreme. Acestea sunt folosite pentru a prelucra date din diverse surse.
- Utilizează unele interpretări matematice și date statistice. Acesta implică algebră liniară și procese de evaluare a modelului.
Concluzie
În acest tutorial, am discutat despre caracteristicile cheie, setarea mediului, citirea unui fișier și multe altele.
Dacă sunteți curios să aflați despre știința datelor, consultați programul Executive PG în știința datelor de la IIIT-B și upGrad, care este creat pentru profesioniști care lucrează și oferă peste 10 studii de caz și proiecte, ateliere practice practice, mentorat cu experți din industrie, 1 -on-1 cu mentori din industrie, peste 400 de ore de învățare și asistență profesională cu firme de top.
Ce este PySpark?
PySpark a fost creat pentru a promova colaborarea Apache Spark cu Python. Această colaborare oferă un API Python pentru Spark. În plus, PySpark permite utilizatorilor să interacționeze cu Resilient Distributed Datasets (RDD) în Apache Spark și Python. PySpark permite utilizatorilor să integreze și să interacționeze rapid cu RDD-urile în limbajul de programare Python. Există mai multe caracteristici care fac din PySpark un instrument atât de excelent pentru lucrul cu seturi mari de date. Inginerii de date apelează la acest instrument pentru a face calcule pe seturi de date uriașe sau doar pentru a le studia. Acest lucru se realizează prin utilizarea bibliotecii Py4j.
Care sunt cazurile reale de utilizare ale PySpark?
PySpark este utilizat în prezent pentru Streaming ETL. Streaming ETL curăță și agregează în mod continuu datele înainte de a fi livrate în stocarea datelor. PySpark ajută la îmbogățirea datelor prin îmbogățirea datelor în direct prin integrarea acestora cu date statice, permițând companiilor să efectueze o analiză mai cuprinzătoare a datelor în timp real. Pyspark este folosit și pentru Detectarea declanșatorului. Declanșatorii sunt folosiți de organizațiile financiare pentru a detecta tranzacțiile frauduloase și pentru a le opri pe drum. Declanșatorii sunt, de asemenea, utilizați în spitale pentru a identifica modificările potențial dăunătoare ale sănătății în timp ce monitorizează semnele vitale ale pacientului, oferind notificări automate îngrijitorilor relevanți care pot lua apoi măsurile prompte și necesare.
Python și PySpark sunt legate?
PySpark este rezultatul parteneriatului Apache Spark și Python. Python este un limbaj de programare de uz general, la nivel înalt, în timp ce Apache Spark este o platformă open-source de calcul în cluster, axată pe viteză, ușurință în utilizare și analiză în flux. Oferă un set divers de biblioteci și este utilizat în principal pentru învățare automată și analiză de streaming în timp real. Înseamnă că este un API Python pentru Spark care vă permite să îmblânziți Big Data combinând simplitatea Python cu puterea Apache Spark.