
PySpark-Tutorial für Anfänger [mit Beispielen]
Veröffentlicht: 2020-10-07PySpark ist eine Cloud-basierte Plattform, die als Servicearchitektur fungiert. Die Plattform bietet eine Umgebung zur Berechnung von Big-Data-Dateien. PySpark bezieht sich auf die Anwendung der Programmiersprache Python in Verbindung mit Spark-Clustern. Es ist eng mit Big Data verbunden. Lassen Sie uns zunächst kurz wissen, womit sich Big Data beschäftigt und verschaffen Sie sich einen Überblick über das PySpark-Tutorial .
Inhaltsverzeichnis
Wofür wird PySpark verwendet?
Als Python-API für Spark, das von der Apache Spark-Community veröffentlicht wurde, unterstützt es Python mit Spark. Lesen Sie diesen Artikel zum Spark-Tutorial Python weiter, um mehr über die Verwendung zu erfahren.
- Mit der Verwendung von PySpark kann man Resilient Distributed Datasets (RDDs) in Python integrieren und effizient damit arbeiten.
- Zahlreiche Funktionen machen PySpark zu einem hervorragenden Framework, da es die Arbeit mit riesigen Datensätzen erleichtert.
- PySpark bietet eine breite Palette von Bibliotheken, und maschinelles Lernen und Echtzeit-Streaming-Analysen werden mit Hilfe von PySpark vereinfacht.
- PySpark nutzt die Einfachheit von Python und die Leistungsfähigkeit von Apache Spark, das zum Zähmen von Big Data verwendet wird.
- Mit dem Aufkommen von Big Data wurde die Leistungsfähigkeit von Technologien wie Apache Spark und Hadoop entwickelt.
- Ein Datenwissenschaftler kann große Datensätze effizient handhaben, da sie für jeden Python-Entwickler gut erreichbar sind.
Lesen Sie: Dataframe in Apache PySpark
Big-Data-Konzepte in Python
Python ist eine höhere Programmiersprache, die auch viele Programmierparadigmen wie objektorientierte Programmierung (OOPs), asynchrone und funktionale Programmierung offenlegt.
Funktionale Programmierung ist ein wichtiges Paradigma im Umgang mit Big Data. Es folgt einem parallelen Code, was bedeutet, dass Sie Ihren Code auf mehreren CPUs sowie auf völlig unterschiedlichen Computern ausführen können. Das PySpark-Ökosystem bietet Ihnen die Möglichkeit, funktionalen Code zu verwenden und ihn über einen Cluster von Computern zu verteilen.
Kernideen der funktionalen Programmierung für Programmierer sind in der Standardbibliothek und in Python integriert.
Die Datenmanipulation, die durch Funktionen ohne externe Zustandspflege erfolgt, ist die Kernideenverkörperung der funktionalen Programmierung. Dies steht dafür, dass Ihr Code globale Variablen umgeht und die Daten nicht direkt manipuliert, sondern immer neue Daten zurückgibt. Python verwendet das Lambda-Schlüsselwort, um anonyme Funktionen verfügbar zu machen.
Lernen Sie den Data Science-Zertifizierungskurs von den besten Universitäten der Welt kennen. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.
Einige Schlüsselfunktionen von PySpark
- Polyglott: PySpark ist eines der wertvollsten Frameworks für die Berechnung durch riesige Datensätze. Es ist auch mit mehreren Sprachen kompatibel.
- Festplattenpersistenz und Caching: Das PySpark-Framework bietet beeindruckende Festplattenpersistenz und leistungsstarkes Caching.
- Schnelle Verarbeitung: Im Vergleich zu den anderen traditionellen Frameworks, die für die Verarbeitung von Big Data verwendet werden, ist das PySpark-Framework ziemlich schnell.
- Funktioniert gut mit RDDs: Python ist dynamisch typisiert für eine Programmiersprache, die bei der Arbeit mit Resilient Distributed Datasets hilft.
Was ist PySpark?
In diesem Pyspark-Tutorial erfahren Sie, was PySpark ist. PySpark ist eine Python-Anwendungsprogrammierschnittstelle (API). Die API ist in Python geschrieben, um eine Verbindung mit Apache Spark herzustellen. Wie Sie wissen, befasst sich Apache Spark mit Big-Data-Analysen. Zur Erstellung von Apache Spark wird die Programmiersprache Scala verwendet. Es kann von anderen Programmiersprachen integriert werden, nämlich von Python, Java, SQL, R und Scala selbst.
PySpark basiert auf zwei Bestätigungen:
- PySpark-API: Es hat viele Beispiele.
- Spark Scala API: Für PySpark-Programme übersetzt es den Scala-Code, der selbst eine sehr gut lesbare und arbeitsbasierte Programmiersprache ist, in Python-Code und macht ihn verständlich.
Py4J gibt einem Python-Programm die Freiheit, über JVM-basierten Code zu kommunizieren. Es hilft PySpark, sich mit der Scala-basierten Anwendungsprogrammierschnittstelle von Spark zu verbinden.
So legen Sie die PySpark-Umgebung fest
Lassen Sie uns nun verschiedene Umgebungen besprechen, in denen PySpark beginnt und für die es beantragt wird. Befolgen Sie dieses Spark-Tutorial Python , um PySpark festzulegen:
- Selbst gehostet: In diesem Fall können Sie eine Sammlung einrichten oder selbst gruppieren. In dieser Umgebung können Sie Metall- oder virtuelle Cluster verwenden. Es gibt einige vorgeschlagene Projekte, nämlich Apache Ambari, die für diesen Zweck geeignet sind. Dieser Prozess ist jedoch nicht schnell genug.
- Cloud-Anbieter: In diesem Fall werden meistens Spark-Cluster verwendet. Diese Umgebung ist schneller als das Selbsthosten. Amazon Web Services (AWS) verfügt über Electronic MapReduce (EMR), während Good Clinical Practice (GCP) über Dataproc verfügt.
- Anbieterlösungen: Databricks und Cloudera liefern Spark-Lösungen. Dies ist eine der schnellsten Möglichkeiten, PySpark auszuführen.
PySpark-Programmierung
Wie wir alle wissen, ist Python eine Hochsprache mit mehreren Bibliotheken. Es spielt eine sehr entscheidende Rolle beim maschinellen Lernen und bei der Datenanalyse. Daher ist PySpark eine in Python geschriebene API für Spark. Spark hat einige hervorragende Eigenschaften, die sich durch hohe Geschwindigkeit, einfachen Zugriff und Anwendung für Streaming-Analysen auszeichnen. Darüber hinaus hilft das Framework von Spark und Python PySpark, auf Big Data zuzugreifen und es einfach zu verarbeiten.
Die Grundlagen des Spark-Tutorials Python werden im Folgenden besprochen.
Resilient Distributed Datasets (RDDs): Resilient Distributed Datasets oder die RDDs sind einer der wichtigsten Bausteine der PySpark-Programmierarchitektur. Diese Sammlung ist unveränderlich und unterliegt schwachen Transformationen. Jedes Wort dieser Abkürzung hat eine Bedeutung. Es ist belastbar, weil es Fehler zulassen und Daten wiederentdecken kann. Es wird verteilt, weil es sich über verschiedene andere Knoten in einem Klumpen ausdehnt. Dataset steht für die Speicherung von Wertdaten.
Lesen Sie auch: Die häufigsten PySpark-Interviewfragen
RDD unterstützt hauptsächlich die folgenden Arten von Operationen
1) Transformationen: Transformationen, die dem Prinzip der Lazy Evaluations folgen, ermöglichen es Ihnen, jederzeit Ausführungen auszuführen, indem Sie eine Aktion für die Daten aufrufen. Einige der Transformationen sind Map, Flat Map, Filter, Distinct, Reduce By Key, Map Partitions, sort by, die von RDDs bereitgestellt werden.

2) Aktionen: Die RDD-Operationen ermöglichen es PySpark, Berechnungen anzuwenden und das Ergebnis an den Treiber zurückzugeben, der als Aktionen bezeichnet wird.
Schritte zum Konvertieren von Großbuchstaben in Kleinbuchstaben und Teilen einer Zeichenfolge
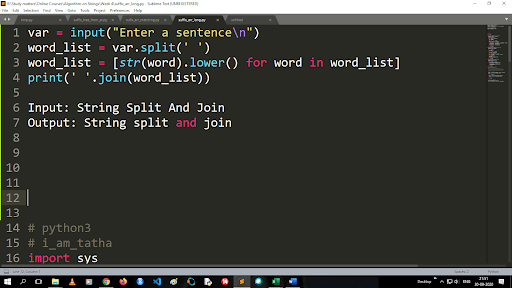
Die Ausgabe der Split-Funktion ist vom Listentyp. Um die Join-Funktion zu verwenden, ist das Format „.join (sequence data type)“ Mit dem obigen Code:
Eingabe: Zeichenfolge teilen und verbinden
Ausgabe: String teilen und verbinden
Wie liest man eine Datei?
Lesen Sie eine Datei in Python, indem Sie die .txt-Datei in einem „Lesemodus“ (r) aufrufen.
Schritt 1) Öffnen Sie die Datei im Lesemodus
f=open(“sample.txt”, ”r”)
Schritt 2) Wir verwenden die Modusfunktion im Code, um zu überprüfen, ob sich die Datei im offenen Modus befindet.
f.mode == 'r':
Schritt 3) Verwenden Sie f.read, um Dateidaten zu lesen und in variablem Inhalt zu speichern
Inhalt = f.read()
Schritte in der prädiktiven Analyse:
- Datenexploration: Sie müssen die Daten sammeln, hochladen und den Datentyp, seine Art und den Wert herausfinden.
- Datenbereinigung: Sie müssen Nullwerte, fehlende Werte und andere Redundanzen finden, die das Programm behindern könnten.
- Modellierung: Sie müssen ein Vorhersagemodell auswählen.
- Bewertung: Sie müssen die Genauigkeit Ihrer Analyse überprüfen.
PySpark-Streaming
PySpark Streaming ist nichts anderes als ein erweiterbares, fehlerfreies System. Es hält sich an die RDD-Batch-Intervalle, die von 500 ms bis zu höheren Intervall-Slots reichen. Gemäß dem Spark-Tutorial Python erhält Spark Streaming einige gestreamte Daten als Eingabe.
Abhängig von der Anzahl der RDD-Batch-Intervalle werden diese gestreamten Daten in zahlreiche Batches aufgeteilt und an die Spark Engine gesendet. Einige der Quellen, aus denen die gestreamten Daten empfangen werden, sind Kinesis, Kafka, Apache Flume usw. Durch die Verwendung von Datenstrukturen und Algorithmen können Spark Engines Daten abrufen. Danach werden die abgerufenen Daten an verschiedene Dateisysteme und Datenbanken weitergeleitet.
Wie bereits erwähnt, ist PySpark eine High-Level-API. Auch wenn ein Fehler auftritt, wird der Streaming-Vorgang nur einmal ausgeführt. Eine der Hauptablenkungen des PySpark-Streamings ist Discretized Stream. Diese Stream-Komponenten werden ebenfalls mit Hilfe von RDD-Batches erstellt. MLib, SQL, Dataframes werden verwendet, um das breite Spektrum an Operationen für Spark Streaming zu erweitern.
In diesem PySpark-Tutorial erfahren Sie, dass Spark Stream viele Daten aus verschiedenen Quellen abruft. Dies ist möglich, weil es komplexe Algorithmen verwendet, die hochfunktionale Komponenten enthalten – Map, Reduce, Join und Window.
Dies sind die Dinge, die zusammenfassen, was PySpark Streaming ist. Lassen Sie uns nun in diesem Spark-Tutorial python über einige der Vorteile von PySpark sprechen.
Vorteile von PySpark
Dieses Segment kann in zwei Teile unterteilt werden. Erstens lernen Sie die Vorteile der Verwendung von Python in PySpark und zweitens die Vorteile von PySpark selbst kennen.
- Da es sich um eine hochrangige und codiererfreundliche Sprache handelt, ist sie leicht zu erlernen und auszuführen.
- Eine einfache und umfassende API kann verwendet werden.
- Python bietet dem Leser eine hervorragende Möglichkeit, Daten zu visualisieren.
- Python verfügt über eine breite Palette von Bibliotheken. Einige der Beispiele sind Matplotlib, Pandas, Seaborn, NumPy usw.
Im Folgenden sind nun die Funktionen von PySpark Tutorial aufgeführt :
- PySpark Streaming integriert problemlos andere Programmiersprachen wie Java, Scala und R.
- PySpark erleichtert Programmierern die Ausführung mehrerer Funktionen mit Resilient Distributed Datasets (RDDs)
- PySpark wird gegenüber anderen Big-Data-Lösungen aufgrund seiner hohen Geschwindigkeit, seines leistungsstarken Catch- und Disk-Persistent-Mechanismen für die Datenverarbeitung bevorzugt.
Muss gelesen werden: Python-Tutorial für Anfänger
Einbeziehung von Data Science und maschinellem Lernen in PySpark
Als hochfunktionale Programmiersprache ist Python das Rückgrat von Data Science und maschinellem Lernen. Daher ist es nicht verwunderlich, dass Data Science und ML die integralen Bestandteile des PySpark-Systems sind. Machine Learning Library (MLib) ist der Operator, der die Funktionalität von Machine Learning in PySpark steuert.
Im Folgenden sind die Vorteile der Verwendung von maschinellem Lernen in PySpark aufgeführt:
- Es ist sehr erweiterbar.
- Es bleibt in verteilten Systemen funktionsfähig.
Die Hauptfunktionen des maschinellen Lernens in PySpark:
- Machine Learning bereitet verschiedene Methoden und Fähigkeiten für die richtige Verarbeitung von Daten vor. Dies sind Transformation, Extraktion, Hashing, Auswahl usw.
- Wie bereits erwähnt, bietet es einige komplexe Algorithmen. Diese werden verwendet, um Daten aus verschiedenen Quellen zu verarbeiten.
- Es verwendet einige mathematische Interpretationen und statistische Daten. Es beinhaltet lineare Algebra und Modellevaluierungsprozesse.
Fazit
In diesem Tutorial haben wir die wichtigsten Funktionen besprochen, die Umgebung festgelegt, eine Datei gelesen und vieles mehr.
Wenn Sie neugierig sind, etwas über Data Science zu lernen, schauen Sie sich das Executive PG Program in Data Science von IIIT-B & upGrad an, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische Workshops, Mentoring mit Branchenexperten, 1 -on-1 mit Branchenmentoren, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Was ist PySpark?
PySpark wurde gegründet, um die Zusammenarbeit von Apache Spark mit Python zu fördern. Diese Zusammenarbeit stellt eine Python-API für Spark bereit. Darüber hinaus ermöglicht PySpark Benutzern die Interaktion mit Resilient Distributed Datasets (RDDs) in Apache Spark und Python. PySpark ermöglicht Benutzern die schnelle Integration und Interaktion mit RDDs in der Programmiersprache Python. Es gibt mehrere Eigenschaften, die PySpark zu einem so hervorragenden Werkzeug für die Arbeit mit großen Datensätzen machen. Data Engineers wenden sich an dieses Tool, um Berechnungen an riesigen Datensätzen durchzuführen oder sie einfach zu studieren. Dies wird durch die Verwendung der Py4j-Bibliothek erreicht.
Was sind die realen Anwendungsfälle von PySpark?
PySpark wird derzeit für Streaming ETL verwendet. Streaming ETL bereinigt und aggregiert Daten kontinuierlich, bevor sie in den Datenspeicher übertragen werden. PySpark hilft bei der Datenanreicherung, indem Live-Daten durch die Integration mit statischen Daten angereichert werden, sodass Unternehmen eine umfassendere Datenanalyse in Echtzeit durchführen können. Pyspark wird auch für die Triggererkennung verwendet. Auslöser werden von Finanzorganisationen verwendet, um betrügerische Transaktionen zu erkennen und sie zu stoppen. Auslöser werden auch in Krankenhäusern verwendet, um potenziell schädliche Gesundheitsveränderungen zu identifizieren, während die Vitalfunktionen des Patienten überwacht werden, und automatische Benachrichtigungen an die zuständigen Pflegekräfte zu senden, die dann umgehend die erforderlichen Maßnahmen ergreifen können.
Sind Python und PySpark verwandt?
PySpark ist das Ergebnis der Partnerschaft zwischen Apache Spark und Python. Python ist eine allgemeine Programmiersprache auf hoher Ebene, während Apache Spark eine Open-Source-Cluster-Computing-Plattform ist, die sich auf Geschwindigkeit, Benutzerfreundlichkeit und Streaming-Analysen konzentriert. Es bietet eine Vielzahl von Bibliotheken und wird hauptsächlich für maschinelles Lernen und Echtzeit-Streaming-Analysen verwendet. Es bedeutet, dass es sich um eine Python-API für Spark handelt, mit der Sie Big Data zähmen können, indem Sie die Einfachheit von Python mit der Leistungsfähigkeit von Apache Spark kombinieren.