
初心者向けのPySparkチュートリアル[例付き]
公開: 2020-10-07PySparkは、サービスアーキテクチャとして機能するクラウドベースのプラットフォームです。 このプラットフォームは、ビッグデータファイルを計算するための環境を提供します。 PySparkは、Sparkクラスターに関連するPythonプログラミング言語のアプリケーションを指します。 ビッグデータと深く関わっています。 まず、ビッグデータが何を扱っているかを簡単に説明し、 PySparkチュートリアルの概要を説明します。
目次
PySparkは何に使用されますか?
ApacheSparkコミュニティによってリリースされたSpark用のPythonAPIとして、SparkでPythonをサポートします。 使用法についてもっと知るために、 sparkチュートリアルPythonに関するこの記事を読み続けてください。
- PySparkを使用すると、PythonのResilient Distributed Datasets(RDD)と統合して効率的に作業できます。
- 多数の機能により、PySparkは大規模なデータセットの操作を容易にするため、優れたフレームワークになっています。
- PySparkは幅広いライブラリを提供し、機械学習とリアルタイムストリーミング分析はPySparkの助けを借りて簡単になります。
- PySparkは、Pythonのシンプルさと、ビッグデータの管理に使用されるApacheSparkのパワーを活用しています。
- ビッグデータの出現により、ApacheSparkやHadoopなどのテクノロジーの力が開発されました。
- データサイエンティストは、Python開発者の手の届く範囲にあるため、大規模なデータセットを効率的に処理できます。
読む: ApachePySparkのデータフレーム
Pythonのビッグデータの概念
Pythonは高水準プログラミング言語であり、オブジェクト指向プログラミング(OOP)、非同期プログラミング、関数型プログラミングなどの多くのプログラミングパラダイムも公開しています。
関数型プログラミングは、ビッグデータを扱う際の重要なパラダイムです。 これは並列コードに従います。つまり、コードを複数のCPUだけでなく、まったく異なるマシンでも実行できます。 PySparkエコシステムには、関数型コードを使用して、それをコンピューターのクラスター全体に分散させる能力があります。
プログラマー向けの関数型プログラミングのコアアイデアは、Pythonの標準ライブラリと組み込みで利用できます。
外部状態を維持せずに関数を介して発生するデータ操作は、関数型プログラミングの中心的なアイデアの実施形態です。 これは、コードがグローバル変数を回避し、データをインプレースで操作せず、常に新しいデータを返すという事実を表しています。 Pythonはlambdaキーワードを使用して、無名関数を公開します。
世界のトップ大学からデータサイエンス認定コースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。
PySparkのいくつかの重要な機能
- Polyglot:PySparkは、大規模なデータセットを介した計算のための最も評価の高いフレームワークの1つです。 複数の言語とも互換性があります。
- ディスクの永続性とキャッシュ:PySparkフレームワークは、印象的なディスクの永続性と強力なキャッシュを提供します。
- 高速処理:ビッグデータ処理に使用される他の従来のフレームワークと比較して、PySparkフレームワークはかなり高速です。
- RDDでうまく機能:Pythonはプログラミング言語用に動的に型付けされており、復元力のある分散データセットでの作業に役立ちます。
PySparkとは何ですか?
このPysparkチュートリアルでは、PySparkとは何かを理解できます。 PySparkは、Pythonアプリケーションプログラミングインターフェイス(API)です。 APIは、ApacheSparkとの接続を形成するためにPythonで記述されています。 ご存知のように、ApacheSparkはビッグデータ分析を扱います。 プログラミング言語Scalaは、ApacheSparkの作成に使用されます。 他のプログラミング言語、つまりPython、Java、SQL、R、Scala自体と統合できます。
PySparkは、2セットの確証に基づいています。
- PySpark API:サンプルがたくさんあります。
- Spark Scala API:PySparkプログラムの場合、それ自体が非常に読みやすく、作業ベースのプログラミング言語であるScalaコードをPythonコードに変換し、理解しやすくします。
Py4Jは、PythonプログラムにJVMベースのコードを介して通信する自由を与えます。 これは、PySparkがSparkScalaベースのアプリケーションプログラミングインターフェイスにプラグインするのに役立ちます。
PySpark環境を設定する方法
それでは、PySparkが開始され、適用されるさまざまな環境について説明しましょう。 このsparkチュートリアルPythonに従って、 PySparkを設定します。
- セルフホスト:この場合、コレクションを設定するか、自分でまとめることができます。 この環境では、金属クラスターまたは仮想クラスターの使用を検討できます。 この目的に適用できるいくつかの提案されたプロジェクト、すなわちApacheAmbariがあります。 ただし、このプロセスは十分に迅速ではありません。
- クラウドプロバイダー:この場合、多くの場合、Sparkクラスターが使用されます。 この環境は、セルフホスティングよりも迅速に機能します。 アマゾンウェブサービス(AWS)にはElectronic MapReduce(EMR)がありますが、Good Clinical Practice(GCP)にはDataprocがあります。
- ベンダーソリューション:DatabricksとClouderaはSparkソリューションを提供します。 これは、PySparkを実行するための最速の方法の1つです。
PySparkプログラミング
ご存知のとおり、Pythonはいくつかのライブラリを持つ高級言語です。 機械学習とデータ分析で非常に重要な役割を果たします。 したがって、PySparkはPythonで記述されたsparkのAPIです。 Sparkには、高速で簡単にアクセスできる優れた属性がいくつかあり、ストリーミング分析に適用されます。 これに加えて、SparkとPythonのフレームワークは、PySparkがビッグデータに簡単にアクセスして処理するのに役立ちます。
SparkチュートリアルPythonの基本については、以下で説明します。
復元力のある分散データセット(RDD):復元力のある分散データセットまたはRDDは、PySparkプログラミングアーキテクチャの主要な構成要素の1つです。 このコレクションは変更できず、弱い変換が行われます。 この略語の各単語には意味があります。 間違いを許し、データを再発見できるため、回復力があります。 凝集塊内の他のさまざまなノードに拡張されるため、分散されます。 データセットは、値データのストレージを表します。
また読む:最も一般的なPySparkインタビューの質問

RDDは主に次のタイプの操作をサポートします
1)変換:遅延評価の原則に従った変換により、いつでもデータに対してアクションを呼び出すことで実行を操作できます。 変換のいくつかは、マップ、フラットマップ、フィルター、個別、キーによる削減、マップパーティションであり、RDDによって提供される並べ替えです。
2)アクション: RDD操作により、PySparkは計算を適用し、結果をドライバーに返します。これはアクションと呼ばれます。
大文字を小文字に変換して文字列を分割する手順
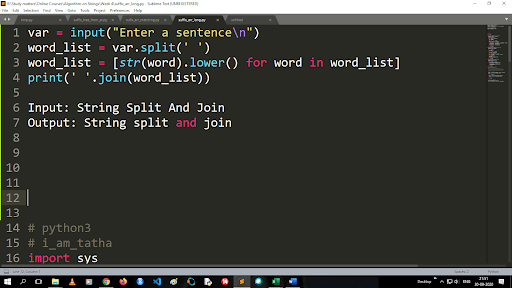
分割関数の出力はリストタイプです。 結合関数を使用する場合、形式は「.join(シーケンスデータ型)」です。上記のコードを使用します。
入力:文字列の分割と結合
出力:文字列の分割と結合
ファイルの読み方は?
「読み取りモード」(r)で.txtファイルを呼び出して、Pythonでファイルを読み取ります。
ステップ1)ファイルを読み取りモードで開きます
f = open(“ sample.txt”、” r”)
ステップ2)コードのmode関数を使用して、ファイルがオープンモードになっていることを確認します。
f.mode =='r':
ステップ3)f.readを使用してファイルデータを読み取り、可変コンテンツに保存します
内容=f.read()
予測分析のステップ:
- データ探索:データを収集してアップロードし、データタイプ、その種類、および値を把握する必要があります。
- データクリーニング:プログラムを妨げる可能性のあるnull値、欠落値、およびその他の冗長性を見つける必要があります。
- モデリング:予測モデルを選択する必要があります。
- 評価:分析の正確さを確認する必要があります。
PySparkストリーミング
PySpark Streamingは、拡張可能でエラーのないシステムに他なりません。 500msからより高いインターバルスロットまでのRDDバッチインターバルを順守します。 SparkチュートリアルPythonによると、SparkStreamingにはいくつかのストリーミングデータが入力として与えられます。
RDDバッチ間隔の数に応じて、これらのストリーミングデータは多数のバッチに分割され、Sparkエンジンに送信されます。 ストリーミングされたデータを受信するソースには、Kinesis、Kafka、Apache Flumeなどがあります。データ構造とアルゴリズムを使用することで、SparkEngineはデータを取得できます。 その後、取得したデータはさまざまなファイルシステムやデータベースに転送されます。
前述のように、PySparkは高レベルのAPIです。 障害が発生しても、ストリーミング操作は1回だけ実行されます。 PySparkストリーミングの主な気晴らしの1つは、離散化ストリームです。 これらのストリームコンポーネントも、RDDバッチを使用して構築されています。 MLib、SQL、Dataframesは、SparkStreamingの幅広い操作を拡張するために使用されます。
このPySparkチュートリアルでは、SparkStreamがさまざまなソースから多くのデータを取得することを理解します。 これが可能なのは、Map、Reduce、Join、Windowなどの高機能コンポーネントを含む複雑なアルゴリズムを使用しているためです。
これらは、PySparkストリーミングとは何かを要約したものです。 ここで、このSparkチュートリアルpythonで、PySparkのいくつかの利点について説明しましょう。
PySparkの利点
このセグメントは2つの部分に分けることができます。 まず、PySparkでPythonを使用する利点、次にPySpark自体の利点を理解します。
- 高レベルでコーダーに優しい言語であるため、習得と実行が簡単です。
- シンプルで包括的なAPIを使用できます。
- Pythonは、読者にデータを視覚化する絶好の機会を提供します。
- Pythonには幅広いライブラリがあります。 例としては、Matplotlib、Pandas、Seaborn、NumPyなどがあります。
さて、以下はPySparkチュートリアルの機能です:
- PySpark Streamingは、Java、Scala、Rなどの他のプログラミング言語を簡単に統合します。
- PySparkは、プログラマーが復元力のある分散データセット(RDD)を使用していくつかの機能を実行するのを容易にします。
- PySparkは、データを処理するための高速で強力なキャッチおよびディスク永続メカニズムのため、他のビッグデータソリューションよりも好まれています。
必読:初心者のためのPythonチュートリアル
PySparkにデータサイエンスと機械学習を含める
非常に機能的なプログラミング言語であるPythonは、データサイエンスと機械学習のバックボーンです。 したがって、データサイエンスとMLがPySparkシステムの不可欠な部分であることは驚くことではありません。 機械学習ライブラリ(MLib)は、PySparkの機械学習の機能を制御するオペレーターです。
PySparkで機械学習を使用する利点は次のとおりです。
- それは非常に拡張可能です。
- 分散システムでも機能し続けます。
PySparkでの機械学習の主な機能:
- 機械学習は、データを適切に処理するためのさまざまな方法とスキルを準備します。 これらは、変換、抽出、ハッシュ、選択などです。
- 前述のように、いくつかの複雑なアルゴリズムを提供します。 これらは、さまざまなソースからのデータを処理するために使用されます。
- それはいくつかの数学的解釈と統計データを使用します。 これには、線形代数とモデル評価プロセスが含まれます。
結論
このチュートリアルでは、主要な機能、環境の設定、ファイルの読み取りなどについて説明しました。
データサイエンスについて知りたい場合は、IIIT-B&upGradのデータサイエンスのエグゼクティブPGプログラムをチェックしてください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界の専門家とのメンターシップを提供します。1業界のメンターとの1対1、400時間以上の学習、トップ企業との仕事の支援。
PySparkとは何ですか?
PySparkは、ApacheSparkとPythonのコラボレーションを促進するために設立されました。 このコラボレーションは、Spark用のPythonAPIを提供します。 さらに、PySparkを使用すると、ユーザーはApache SparkおよびPythonで復元力のある分散データセット(RDD)を操作できます。 PySparkを使用すると、ユーザーはPythonプログラミング言語でRDDをすばやく統合して操作できます。 PySparkを大規模なデータセットを操作するための優れたツールにするいくつかの特徴があります。 データエンジニアは、このツールを使用して、巨大なデータセットの計算を行ったり、単にそれらを研究したりしています。 これは、Py4jライブラリを利用することで実現されます。
PySparkの実際のユースケースは何ですか?
PySparkは現在、ストリーミングETLに使用されています。 ストリーミングETLは、データがデータストレージに配信される前に、データを継続的にクリーンアップおよび集約します。 PySparkは、ライブデータを静的データと統合することでデータを強化し、企業がより包括的なリアルタイムデータ分析を実行できるようにすることで、データの強化を支援します。 Pysparkは、トリガー検出にも使用されます。 トリガーは、金融機関が不正な取引を検出し、それらを追跡するために使用します。 トリガーは病院でも使用され、患者のバイタルサインを監視しながら潜在的に有害な健康の変化を識別し、関連する介護者に自動通知を配信します。介護者は迅速かつ必要な措置を講じることができます。
PythonとPySparkは関連していますか?
PySparkは、ApacheSparkとPythonのパートナーシップの結果です。 Pythonは汎用の高級プログラミング言語ですが、Apache Sparkは、速度、使いやすさ、ストリーミング分析に重点を置いたオープンソースのクラスターコンピューティングプラットフォームです。 多様なライブラリセットを提供し、主に機械学習とリアルタイムストリーミング分析に使用されます。 これは、PythonのシンプルさとApache Sparkのパワーを組み合わせることで、ビッグデータを使いこなすことができるSpark用のPythonAPIであることを意味します。